 Exactly Once 语义在 Flink 中的实现| 青训营笔记
Exactly Once 语义在 Flink 中的实现| 青训营笔记
# Exactly Once 语义在 Flink 中的实现| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第 3 天
# 数据流和动态表
| 特征 | SQL | 流处理 |
|---|---|---|
| 处理数据的有界性 | 处理的表是有界的 | 流是一个无限元组序列 |
| 处理数据的完整性 | 执行查询可以访问完整的数据 | 执行查询无法访问所有的数据 |
| 查询终止条件 | 批处理查询产生固定大小结果后终止 | 查询不断更新结果,永不终止 |
# 动态表
- 动态表
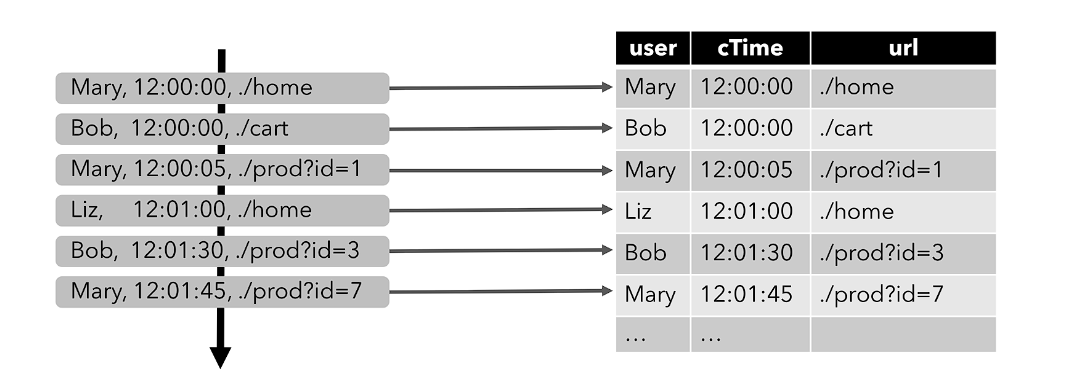
- 与批处理数据的静态表不同,动态表是随时间不断变化的表,在任意时刻,动态表可以像静态的批处理表一样进行查询,查询一个动态表会产生持续查询(Continuous Query)
- 持续查询(Continuous Query)
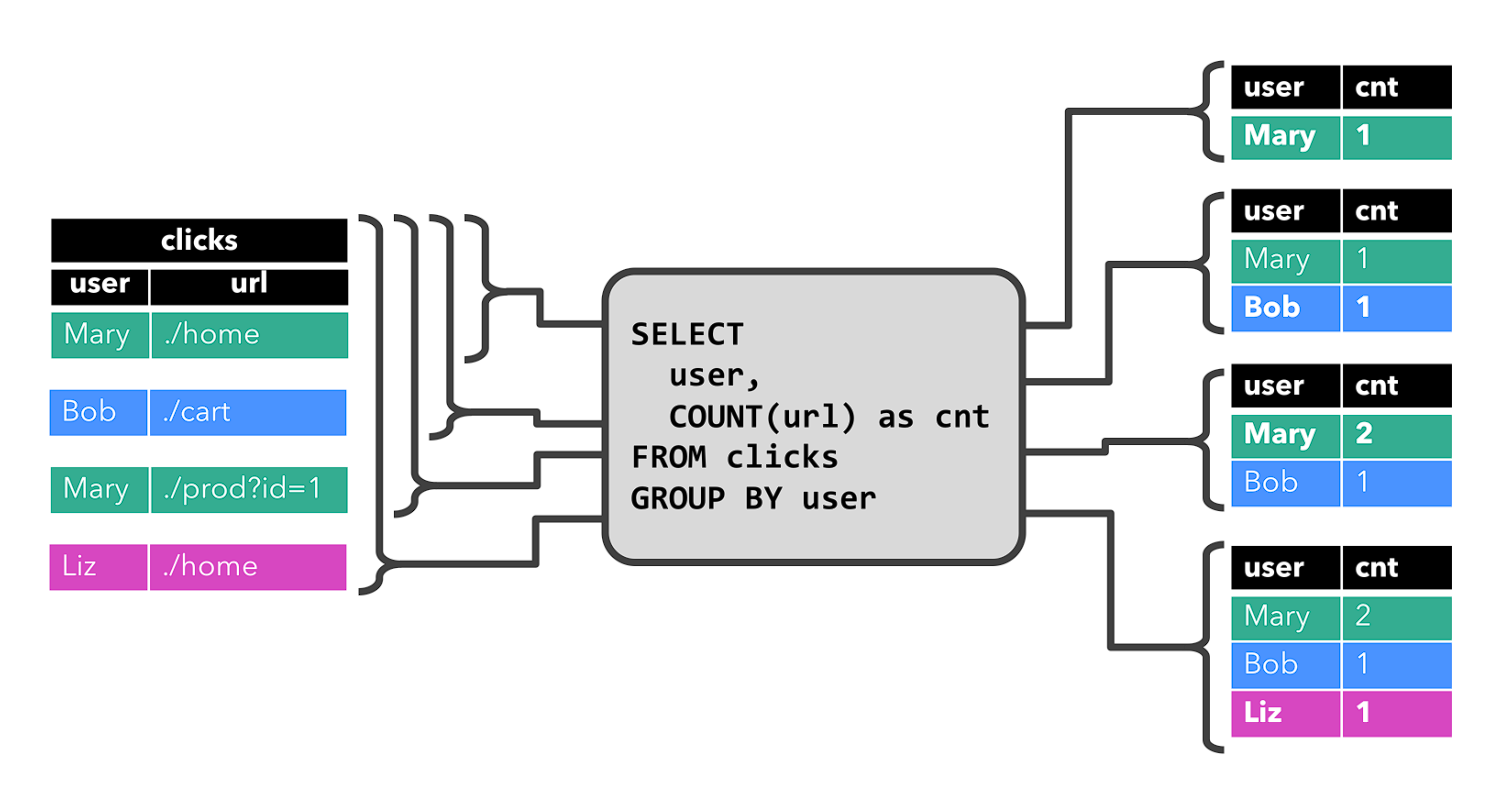
- 连续查询从不终止
- 查询结果会不断更新其动态表,并且会产生一个新的动态表
- 结果的动态表也可转换成输出的实时流
# 动态表和持续查询

流式表查询的处理过程:
- 流被转换为动态表
- 对动态表计算连续查询,生成新的动态表
- 生成的动态表被转换回流
# 将动态表转换成 DataStream
仅追加(Append-only)流
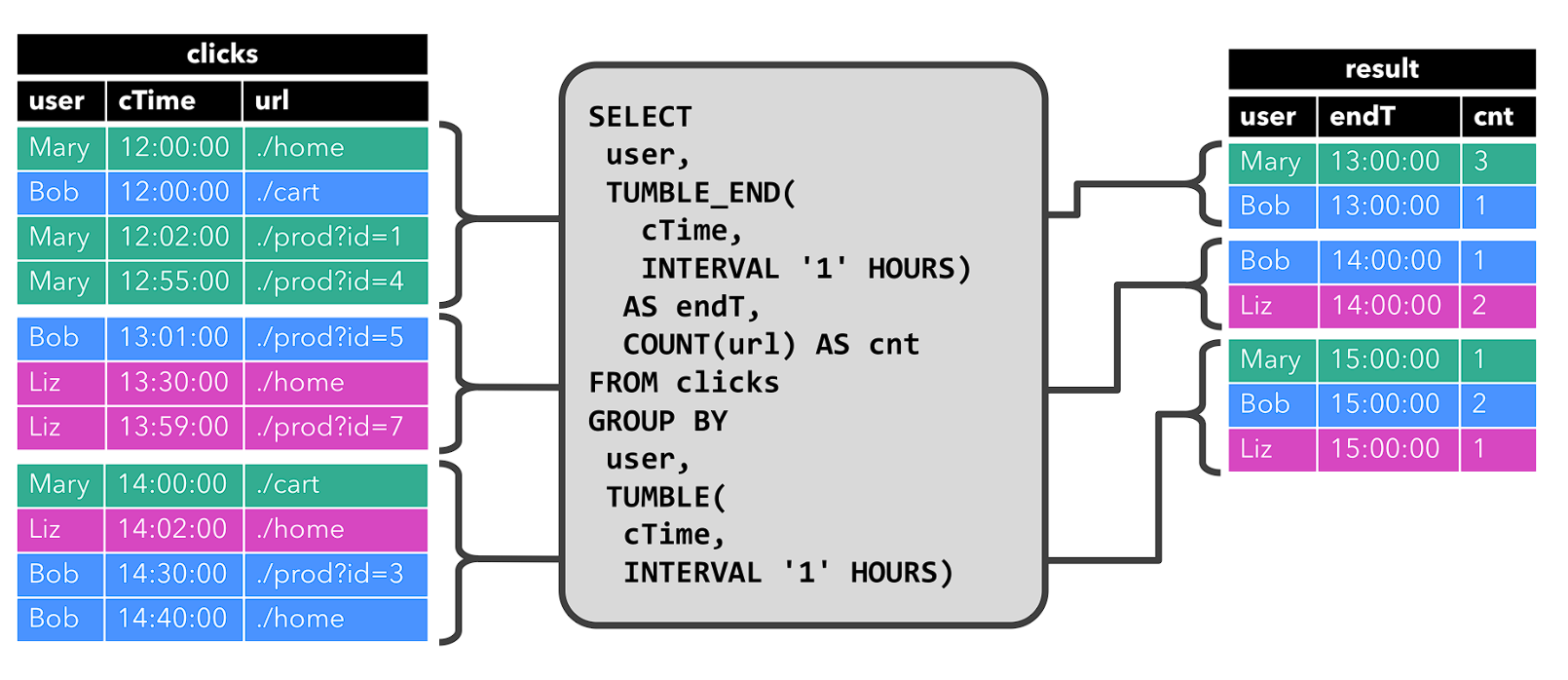
- 仅通过插入(Insert)更改来修改的动态表,可以直接转换为仅追加流
- 即结果表的 changelog 流只包含 INSERT 操作
撤回(Retract)流
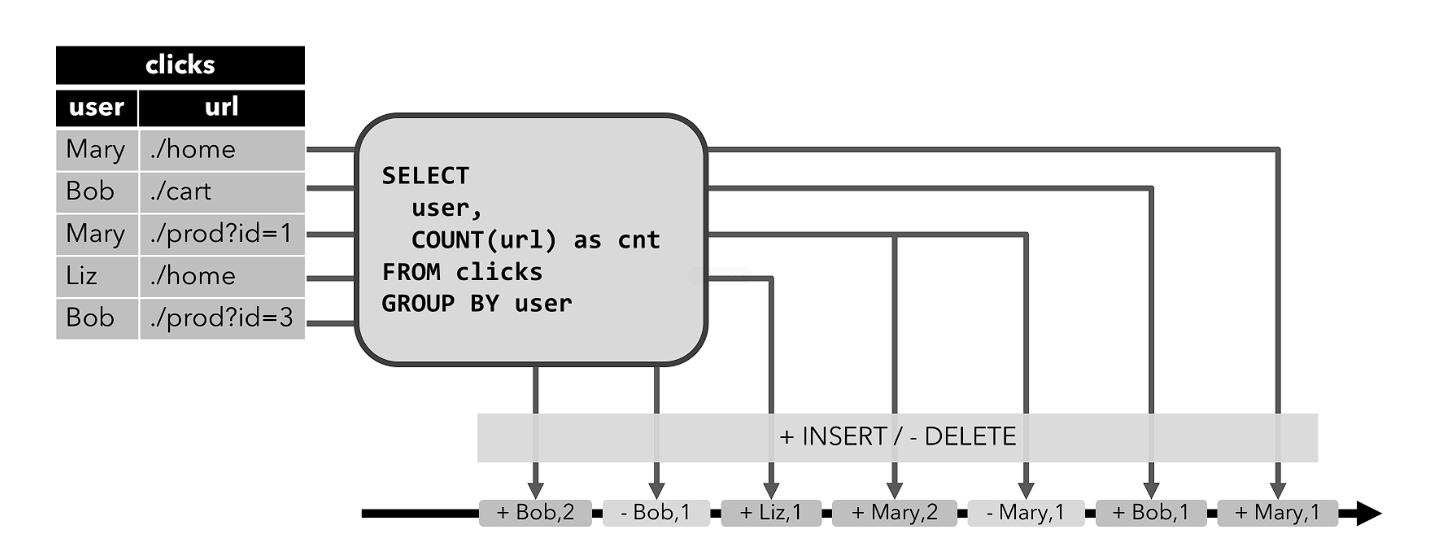
- 撤回流是包含两类消息的流:添加(Add)消息和撤回(Retract)消息
Upsert(更新插入)流
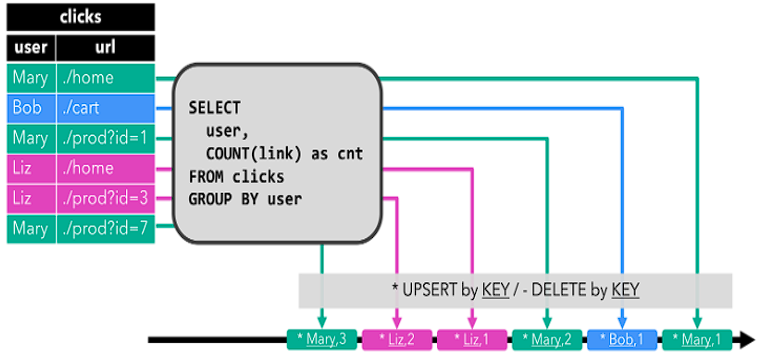
- Upsert 流也包含两种类型的消息:Upsert 消息和删除(Delete)消息
# 不同数据处理保证的语义
- At-most-once:出现故障不作处理,每条数据消费至多一次,处理延迟低。这其实是没有正确性保障的委婉说法 —— 故障发生之后,计数结果可能丢失。同样的还有 udp。
- At-least-once:每条数据消费至少一次,一条数据可能存在重复消费。这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
- Exactly-once:每条数据都被消费且仅被消费一次,仿佛故障从未发生。这指的是系统保证在发生故障后得到的计数结果与正确值一致。
# Exactly-Once 和 Checkpoint
Flink 检查点算法的正式名称是异步分界线快照 (asynchronous barrier snapshotting)。该算法大致基于 Chandy-Lamport 分布式快照算法。 检查点是 Flink 最有价值的创新之一,因为它使 Flink 可以保证 exactly-once,并且不需要牺牲性能。
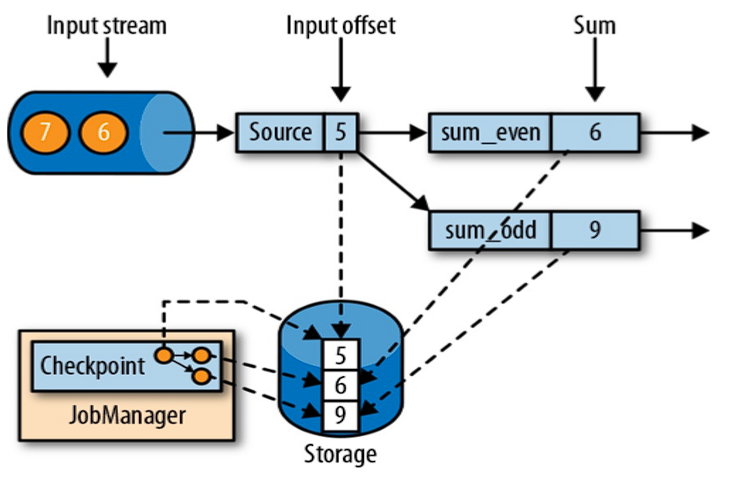
# 制作快照的时间点
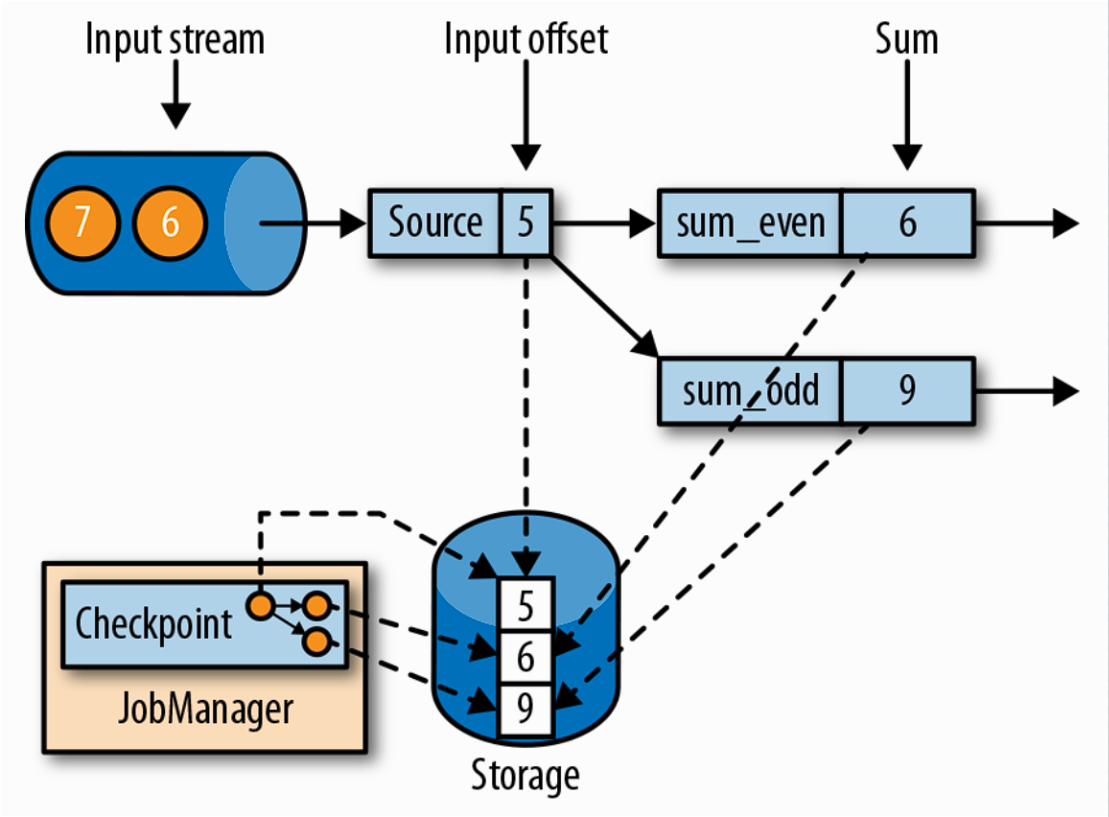
- 状态恢复的时间点:需要等待所有处理逻辑消费完成 source 保留状态及之前的数据。
- 一个简单的快照制作算法:
- 暂停处理输入的数据
- 等待后续所有处理算子消费当前已经输入的数据
- 待 2 处理完后,作业所有算子复制自己的状态并保存到远端可靠存储
- 恢复对输入数据的处理
# 一致性检查点(Checkpoints)
- Flink 故障恢复机制的核心,就是应用状态的一致性检查点
- 有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候
# 从检查点恢复状态
在执行流应用程序期间,Flink 会定期保存状态的一致检查点。如果发生故障, Flink 将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程。
遇到故障之后,第一步就是重启应用
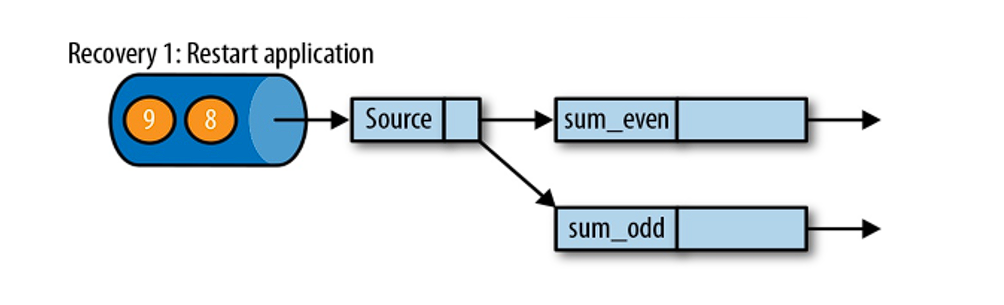
第二步是从 checkpoint 中读取状态,将状态重置。从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
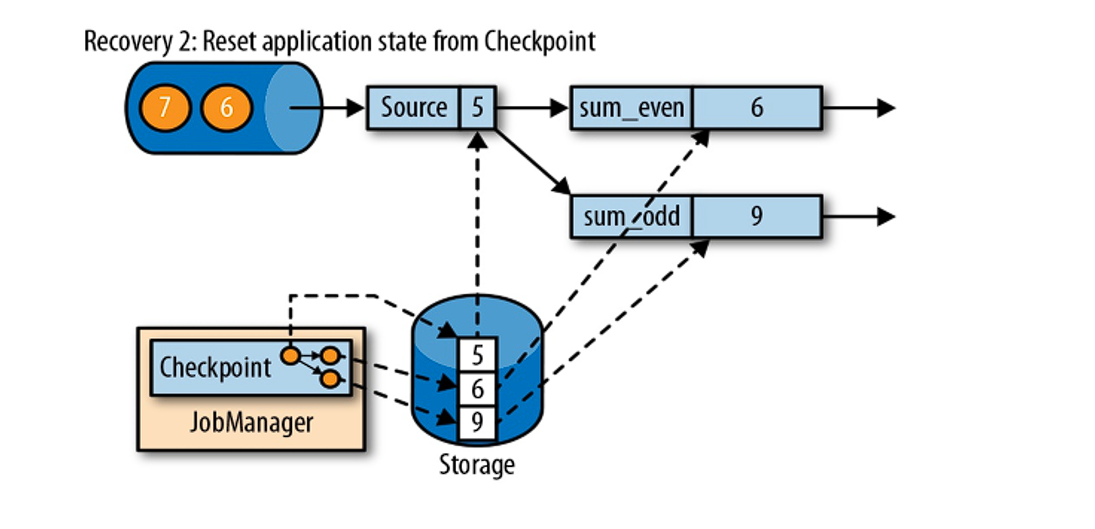
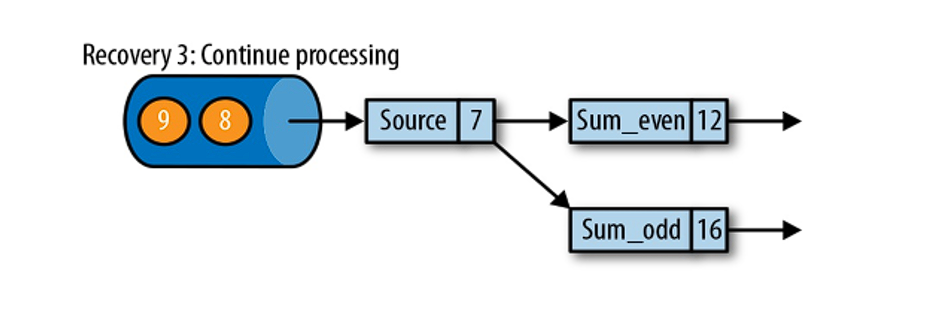
第三步:开始消费并处理检查点到发生故障之间的所有数据。这种检查点的保存和恢复机制可以为应用程序状态提供 “精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置。
# Chandy-Lamport 算法
下图是程序的初始状态。注意,a、b、c 三组的初始计数状态都是 0,即三个圆柱上的值。ckpt 表示检查点分割线(checkpoint barriers)。每条记录在处理顺序上严格地遵守在检查点之前或之后的规定,例如 ["b",2] 在检查点之前被处理,["a",2] 则在检查点之后被处理。
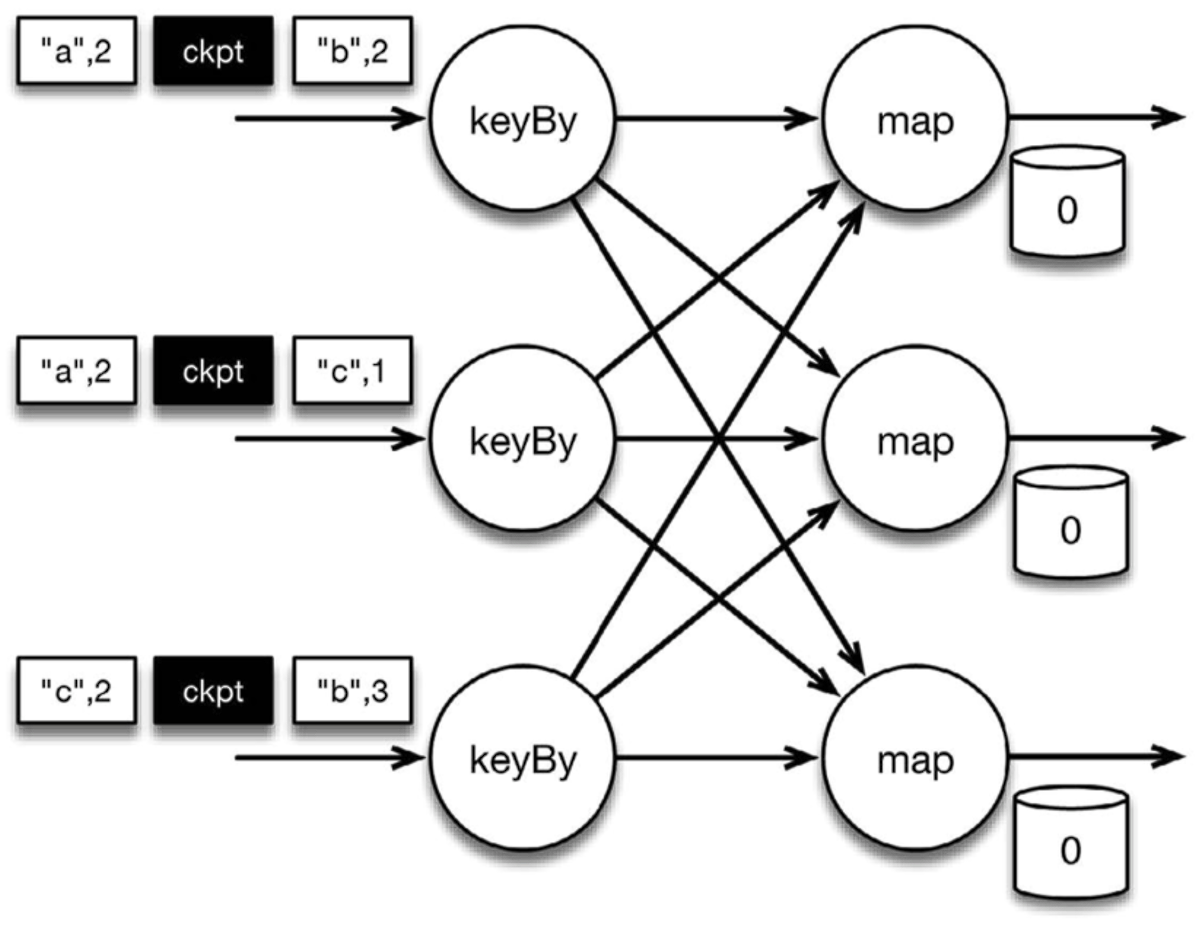
检查点分割线和普通数据记录类似。它们由算子处理,但并不参与计算,而是会触发与检查点相关的行为。
Flink 的存储机制是插件化的,持久化存储可以是分布式文件系统,如 HDFS。
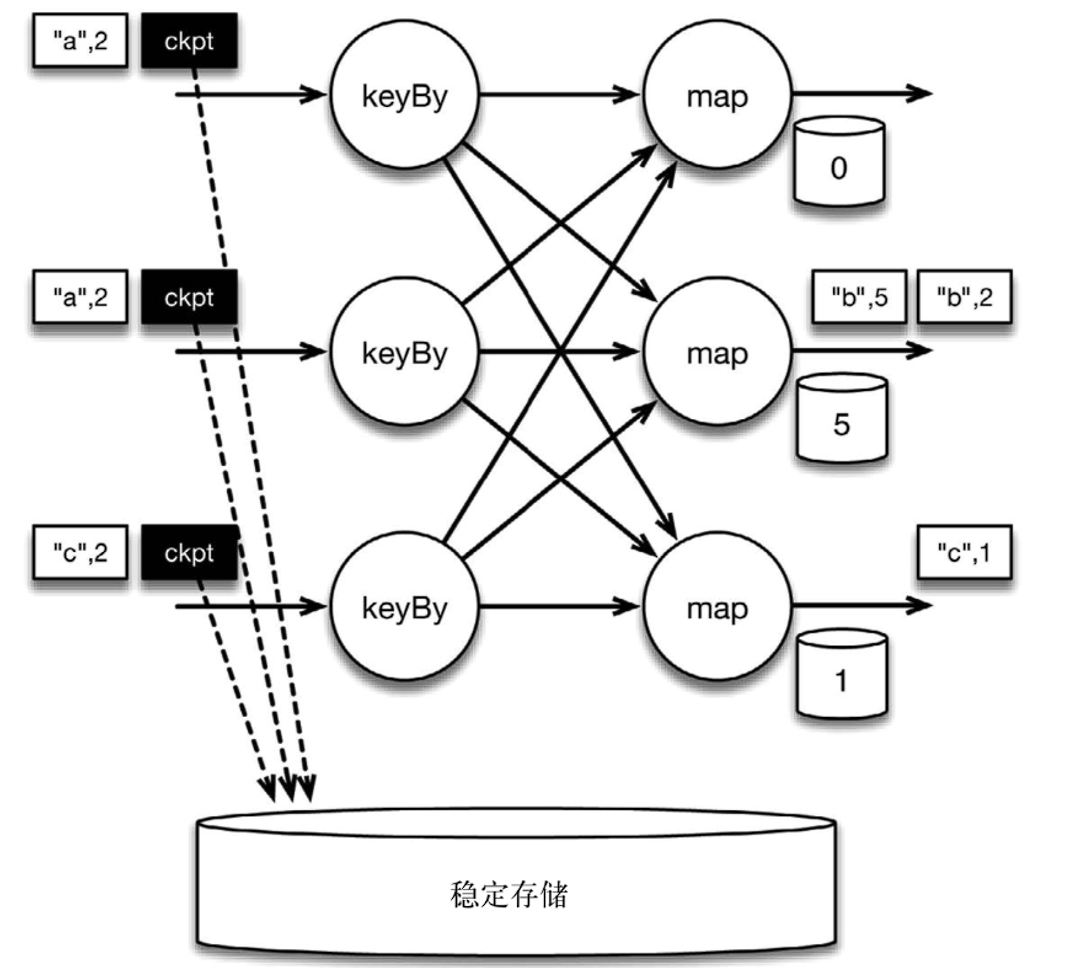
** 当 Flink 数据源 (在本例中与 keyBy 算子内联) 遇到检查点分界线(barrier)时,它会将其在输入流中的位置保存到持久化存储中。** 这让 Flink 可以根据该位置重启。
下图是遇到 checkpoint barrier 时,保存其在输入流中的位置。
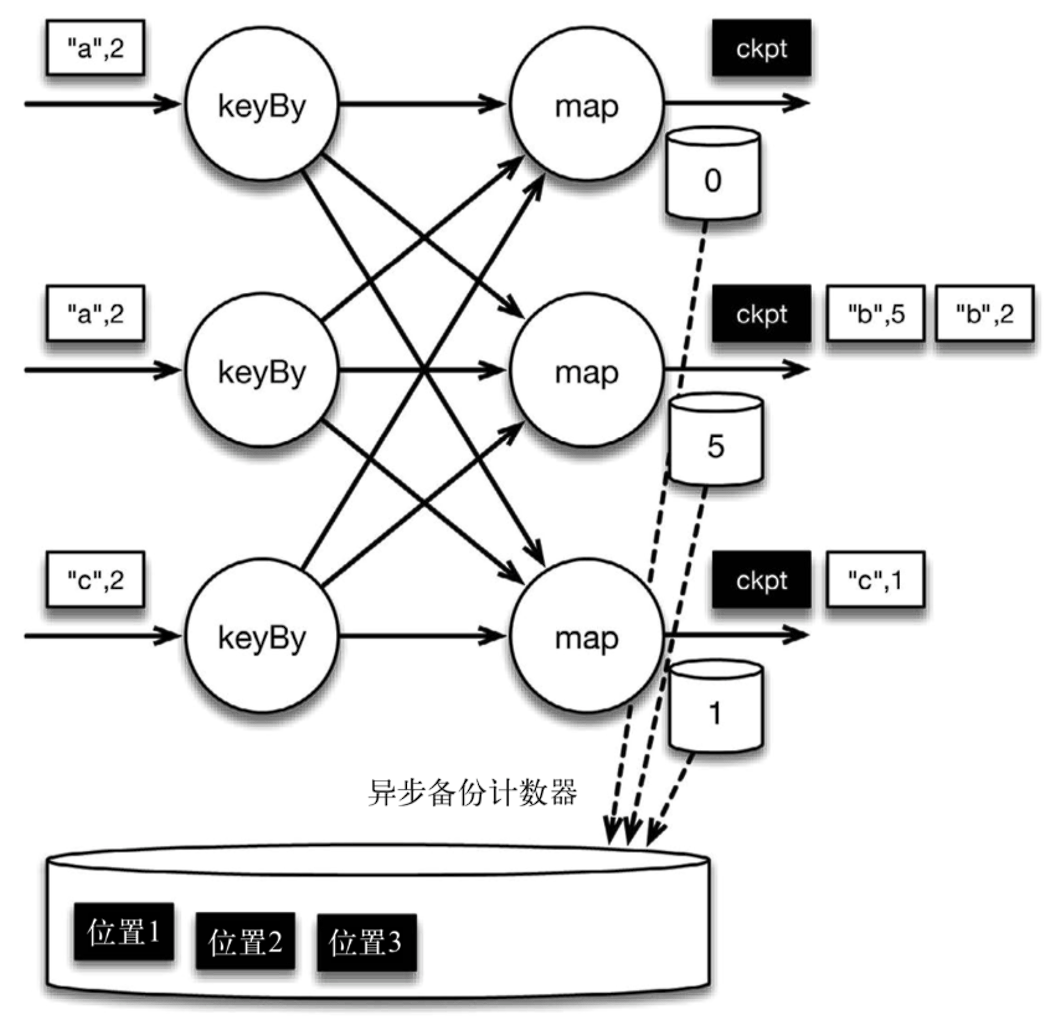
检查点像普通数据记录一样在算子之间流动。当 map 算子处理完前 3 条数据并收到检查点分界线时,它们会将状态以异步的方式写入持久化存储,如下图所示 保存的是 map 算子状态,也就是当前各个 key 的计数值。
当 map 算子的状态备份和检查点分界线的位置备份被确认之后,该检查点操作就可以被标记为完成,如下图所示检查点操作完成,继续处理数据。我们在无须停止或者阻断计算的条件下,在一个逻辑时间点 (对应检查点屏障在输入流中的位置) 为计算状态拍了快照。
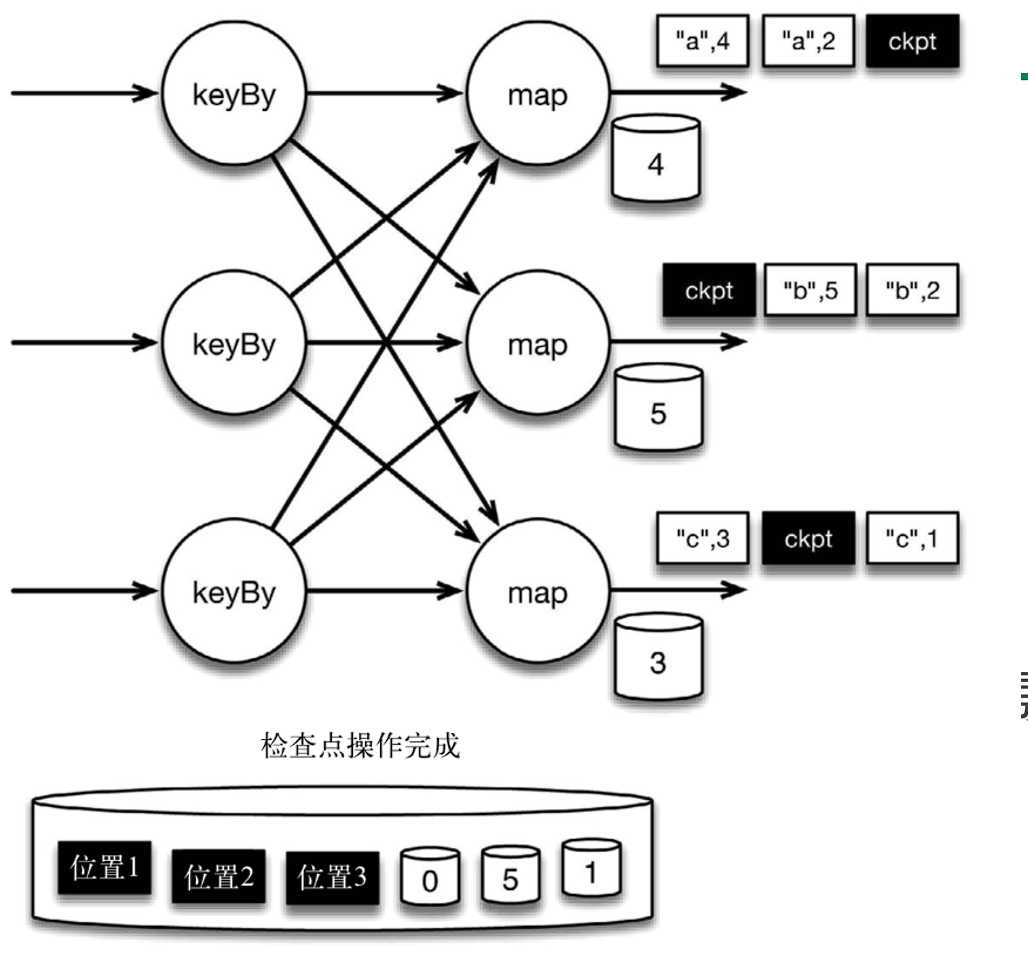
检查点操作完成,状态和位置均已备份到稳定存储中。值得注意的是,备份的状态值与实际的状态值是不同的。备份反映的是检查点的状态。
如果检查点操作失败,Flink 可以丢弃该检查点并继续正常执行,因为之后的某一个检查点可能会成功。
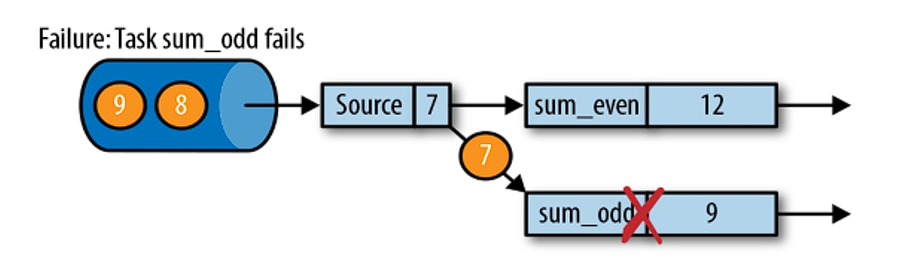
现在来看看下图所示的情况:检查点操作已经完成,但故障紧随其后。
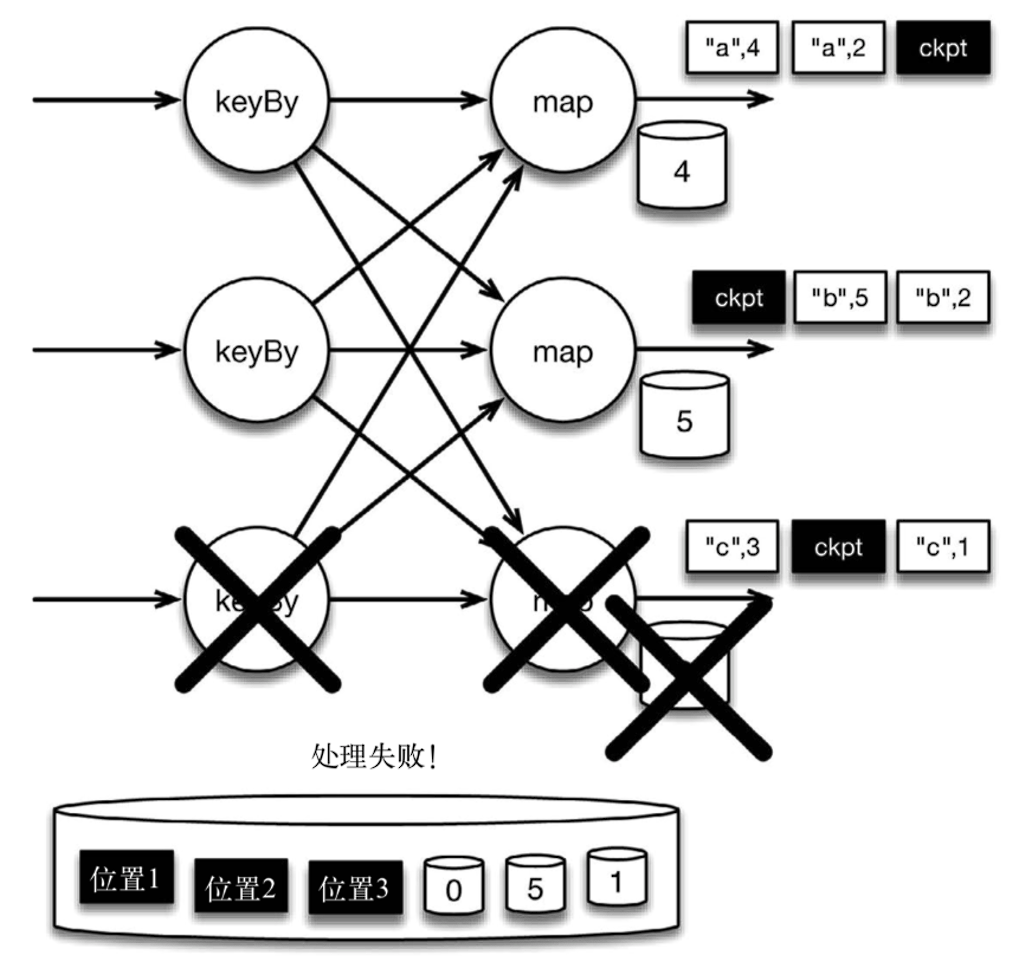
在这种情况下,Flink 会重新拓扑 (可能会获取新的执行资源),将输入流倒回到上一个检查点,然后恢复状态值并从该处开始继续计算。在本例中,["a",2]、["a",2] 和 ["c",2] 这几条记录将被重播。
下图展示了这一重新处理过程。从上一个检查点开始重新计算,可以保证在剩下的记录被处理之后,得到的 map 算子的状态值与没有发生故障时的状态值一致。
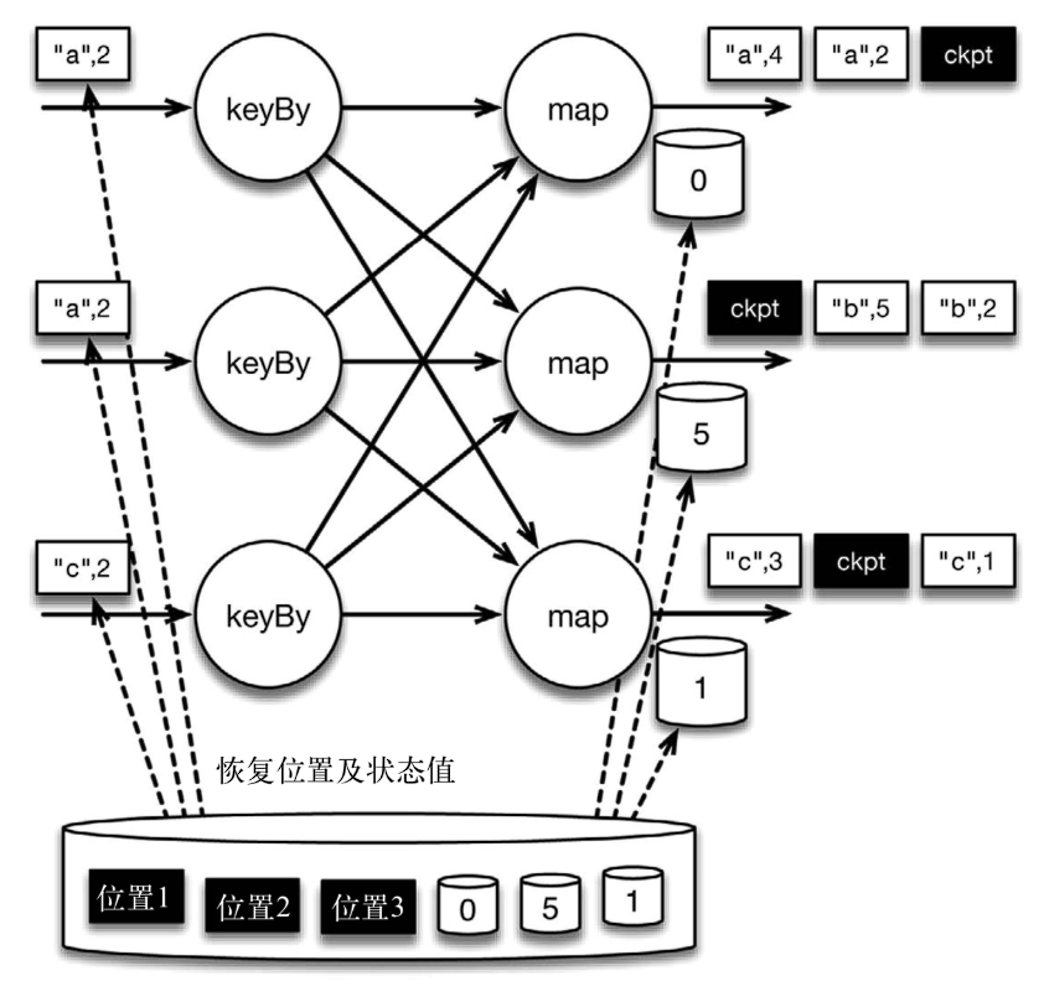
Flink 将输入流倒回到上一个检查点屏障的位置,同时恢复 map 算子的状态值。然后,Flink 从此处开始重新处理。这样做保证了在记录被处理之后,map 算子的状态值与没有发生故障时的一致。
Flink 检查点算法的正式名称是异步分界线快照 (asynchronous barrier snapshotting)。该算法大致基于 Chandy-Lamport 分布式快照算法。
检查点是 Flink 最有价值的创新之一,因为它使 Flink 可以保证 exactly-once,并且不需要牺牲性能。
# Flink 端到端的 Exactly-Once 语义
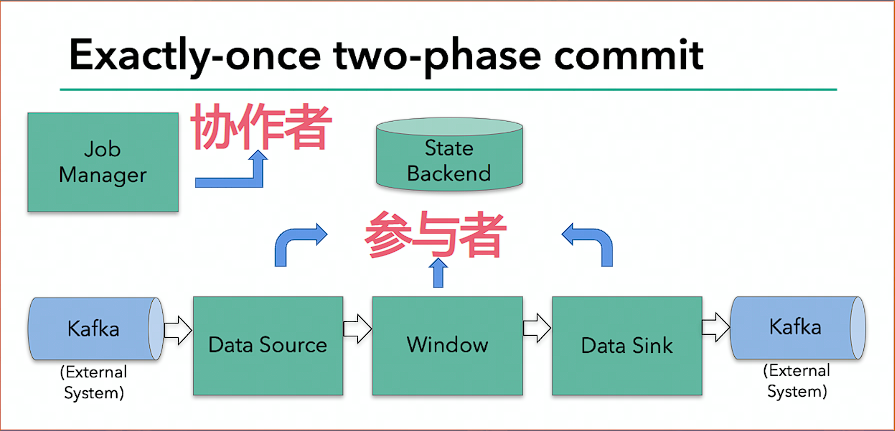
# 两阶段提交(Two-Phase-Commit)
在多个节点参与执行的分布式系统中,为了协调每个节点都能同时执行或者回漆某个事务性的操作引入了一个中心节点来统一处理所有节点的执行逻辑,这个中心节点叫做协作者(coordinator) ,被中心节点调度的其他业务节点叫做参与者 (participant) 。

- 对于每个 checkpoint,sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里
- 然后将这些数据写入外部 sink 系统,但不提交它们 —— 这时只是 “预提交”
- 当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入
- 这种方式真正实现了 exactly-once,它需要一个提供事务支持的外部 sink 系统。Flink 提供了 TwoPhaseCommitSinkFunction 接口。
预提交阶段
- 协作者向所有参与者发送一个 commit 消息
- 每个参与的协作者收到消息后,执行事务,但是不真正提交
- 若事务成功执行完成,发送一个成功的消息 (vote yes) ;执行失败,则发送一个失败的消息 (vote no)
提交阶段
- 若协作者成功接收到所有的参与者 vote yes 的消息:
- 协作者向所有参与者发送一个 commit 消息
- 每个收到 commit 消息的参与者释放执行事务所需的资源,并结束这次事务的执行
- 完成步骤 2 后,参与者发送一个 ack 消息给协作者
- 协作者收到所有参与者的 ack 消息后,标识该事务执行完成
- 若协作者有收到参与者 vote no 的消息 (或者发生等待超时):
- 协作者向所有参与者发送一个 rollback 消息
- 每个收到 rollback 消息的参与者回滚事务的执行操作,并释放事务所占
- 完成步骤 2 后,参与者发送一个 ack 消息给协作者;
- 协作者收到所有参与者的 ack 消息后,标识该事务成功完成回滚。
- 若协作者成功接收到所有的参与者 vote yes 的消息:
# 2PC
2PC 对外部 sink 系统的要求:
- 外部 sink 系统必须提供事务支持,或者 sink 任务必须能够模拟外部系统上的事务
- 在 checkpoint 的间隔期间里,必须能够开启一个事务并接受数据写入
- 在收到 checkpoint 完成的通知之前,事务必须是 “等待提交” 的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候 sink 系统关闭事务(例如超时了),那么未提交的数据就会丢失
- sink 任务必须能够在进程失败后恢复事务
- 提交事务必须是幂等操作
# Flink+Kafka 如何实现端到端的 exactly-once 语义
- 内部 —— 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source —— kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer 作为 sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
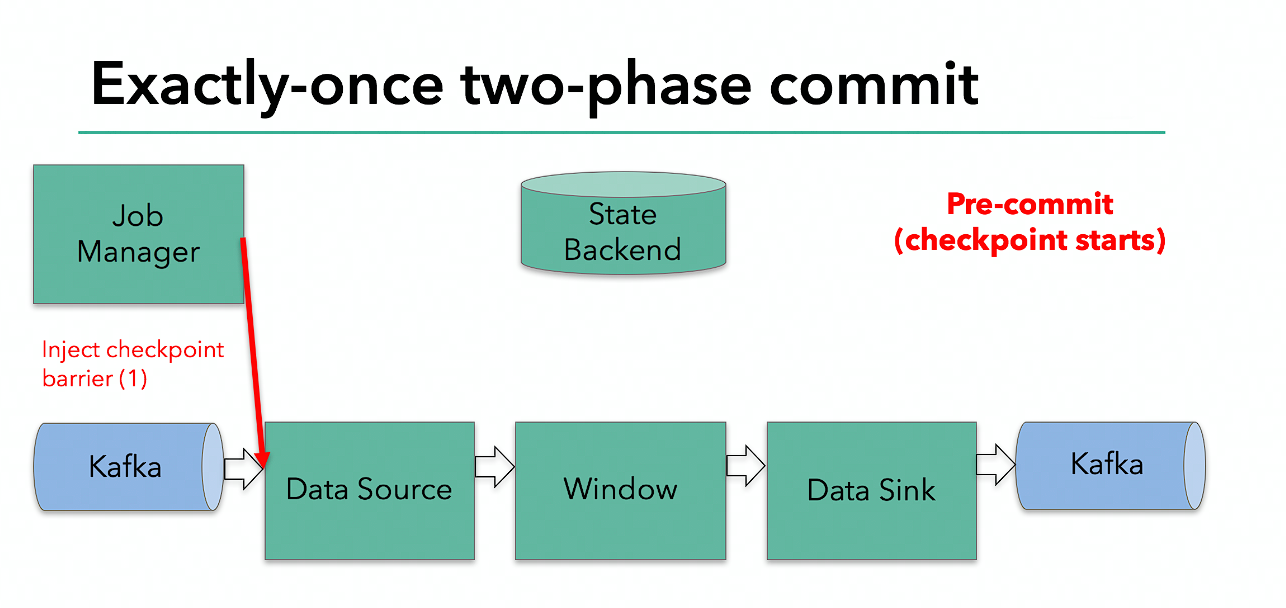
Flink 由 JobManager 协调各个 TaskManager 进行 checkpoint 存储,checkpoint 保存在 StateBackend 中,默认 StateBackend 是内存级的,也可以改为文件级的进行持久化保存。
当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流;barrier 会在算子间传递下去。
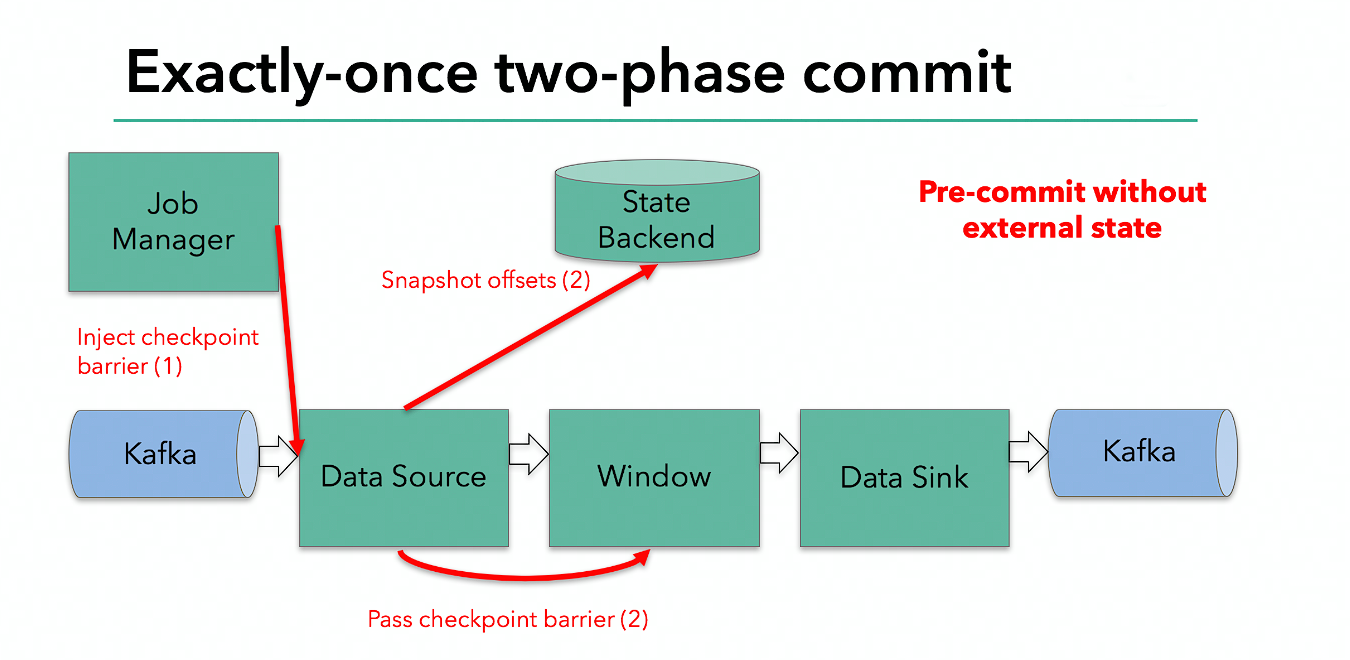
每个算子会对当前的状态做个快照,保存到状态后端。对于 source 任务而言,就会把当前的 offset 作为状态保存起来。下次从 checkpoint 恢复时,source 任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。
每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里。
sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务(还不能被消费);当遇到 barrier 时,把状态保存到状态后端,并开启新的预提交事务。
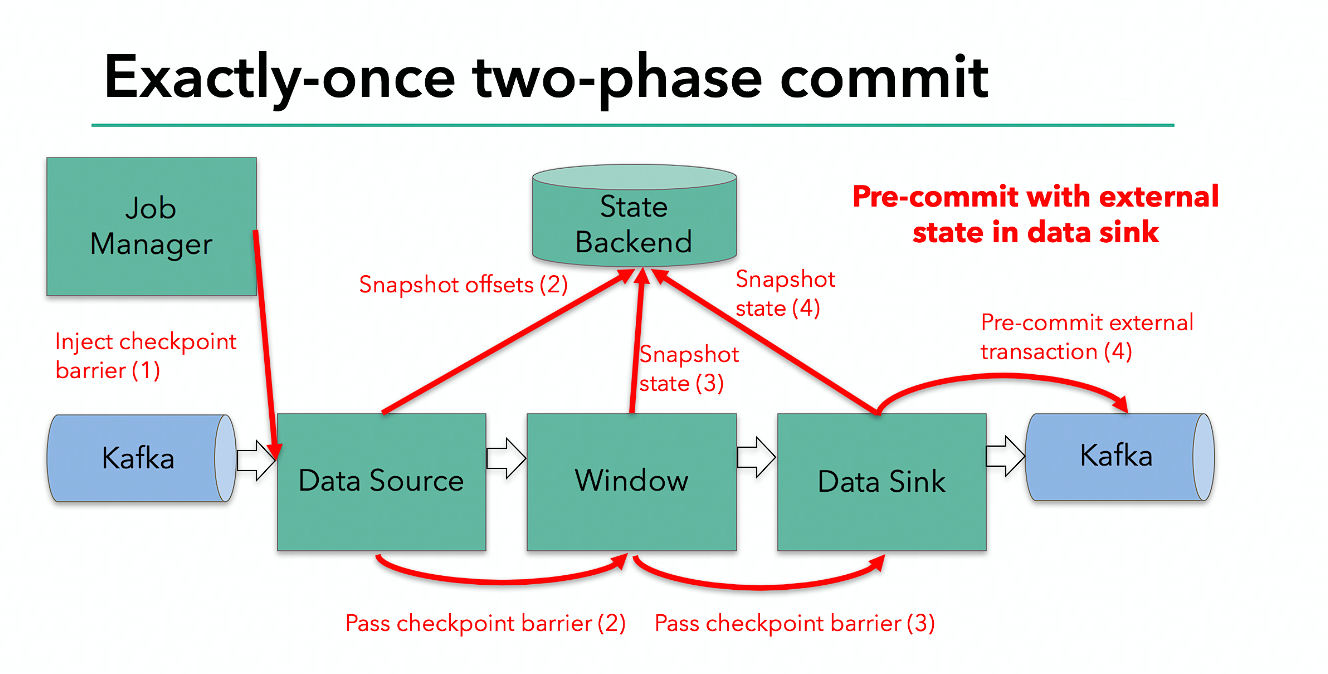
当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成。
当 sink 任务收到确认通知,就会正式提交之前的事务,kafka 中未确认的数据就改为 “已确认”,数据就真正可以被消费了。
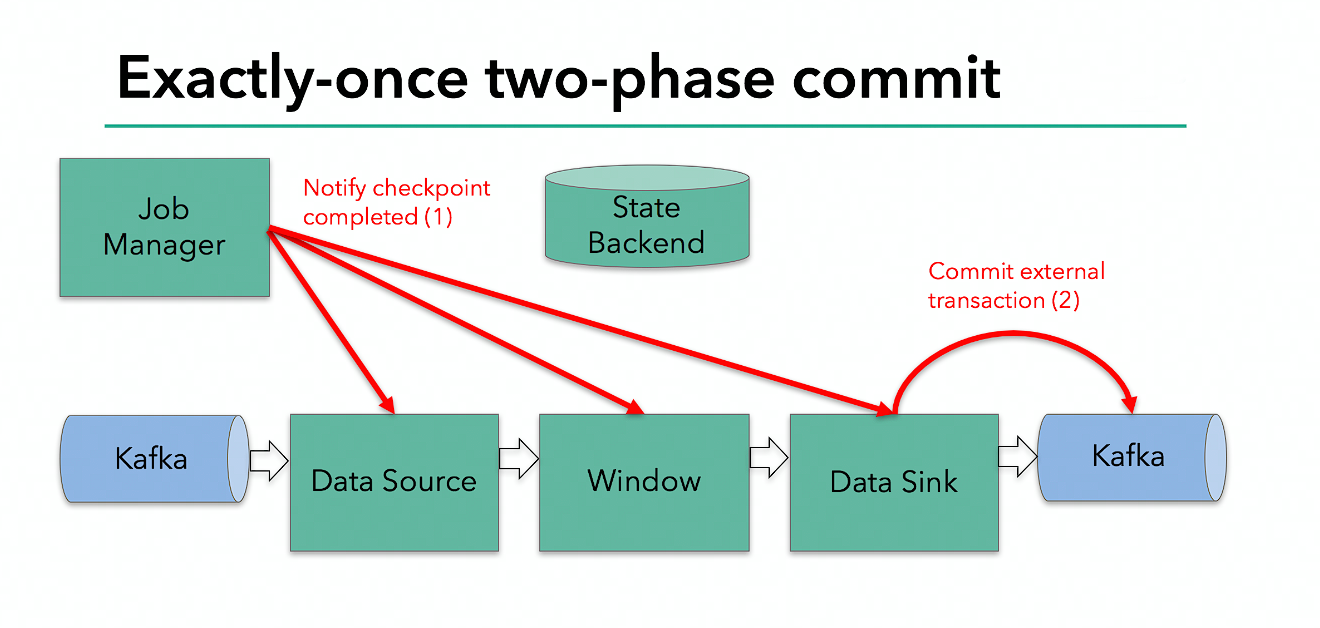
所以我们看到,执行过程实际上是一个两段式提交,每个算子执行完成,会进行 “预提交”,直到执行完 sink 操作,会发起 “确认提交”,如果执行失败,预提交会放弃掉。
具体的两阶段提交步骤总结如下:
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是 “预提交”
- jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
- 外部 kafka 关闭事务,提交的数据可以正常消费了。
所以我们也可以看到,如果宕机需要通过 StateBackend 进行恢复,只能恢复所有确认提交的操作。
# 总结
- 事务开启:在 sink task 向下游写数据之前,均会开启一个事务,后续所有写数据的操作均在这个事务中执行,事务未提交前,事务写入的数据下游不可读;
- 预提交阶段:JobManager 开始下发 Checkpoint Barrier,当各个处理逻辑接收到 barrier 后停止处理后续数据,对当前状态制作快照,此时 sink 也不在当前事务下继处理数据(处理后续的数据需要新打开下一个事务)。状态制作成功则向 JM 成功的消息,失败则发送失败的消息;
- 提交阶段:若 JM 收到所有预提交成功的消息,则向所有处理逻辑(包括 sink) 发送可以提交此次事务的消息,sink 接收到此消息后,则完成此次事务的提交,此时下游可以读到这次事务写入的数据;若 JM 有收到预提交失败的消息,则通知所有处理逻辑回滚这次事务的操作,此时 sink 则丢弃这次事务提交的数据下。