 数仓分层概念
数仓分层概念
# 数仓分层概念
# 数仓分层
# 为什么要分层
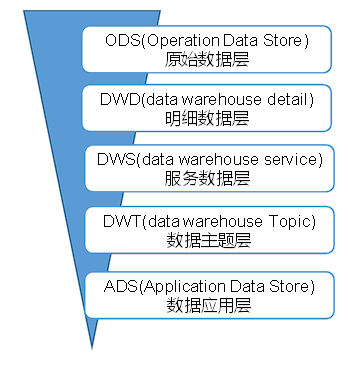
- ODS (Operation Data Store) 原始数据层:ODS 层,原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
- DWD (data warehouse detail) 明细数据层:DWD 层,对 ODS 层数据进行清洗(去除空值,脏数据,超过极限范围的数据)、维度退化、脱敏等
- DWS (data warehouse service) 服务数据层:以 DWD 为基础,按天进行轻度汇总。
- DWT (data warehouse Topic) 数据主题层:以 DWS 为基础,按主题进行汇总。
- ADS (Application Data Store) 数据应用层:ADS 层,为各种统计报表提供数据
数据仓库为什么要分层?
- 把复杂问题简单化:将复杂的任务分解成多层来完成,每一层只处理简单的任务,方便定位问题。
- 减少重复开发:规范数据,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
- 隔离原始数据:不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
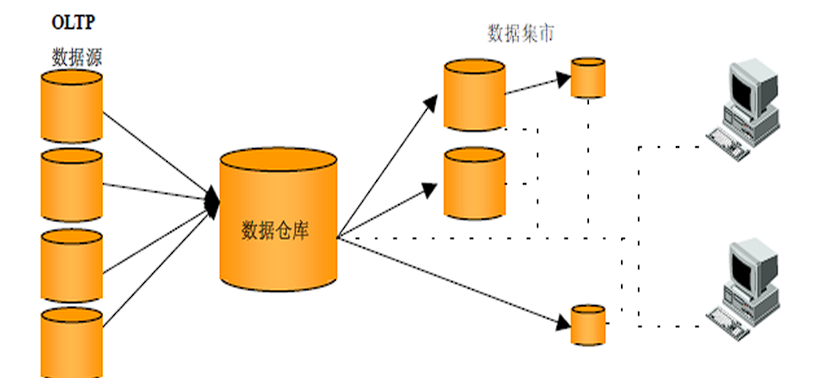
# 数据集市与数据仓库概念
- 数据集市(Data Market),现在市面上的公司和书籍都对数据集市有不同的概念。 数据集市则是一种微型的数据仓库,它通常有更少的数据,更少的主题区域,以及更少的历史数据,因此是部门级的,一般只能为某个局部范围内的管理人员服务。
- 数据仓库是企业级的,能为整个企业各个部门的运行提供决策支持手段。
# 数仓命名规范
# 表命名
- ODS 层命名为 ods_表名
- DWD 层命名为 dwd_dim/fact_表名
- DWS 层命名为 dws_表名
- DWT 层命名为 dwt_购物车
- ADS 层命名为 ads_表名
- 临时表命名为 xxx_tmp
- 用户行为表,以 log 为后缀。
# 脚本命名
- 数据源_to_目标_db/log.sh
- 用户行为脚本以 log 为后缀;业务数据脚本以 db 为后缀。
# 数仓理论
# 范式理论
# 范式概念
- 定义:范式可以理解为设计一张数据表的表结构,符合的标准级别。 规范和要求
- 优点:关系型数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性。
为什么要降低数据冗余性?
- 十几年前,磁盘很贵,为了减少磁盘存储。
- 以前没有分布式系统,都是单机,只能增加磁盘,磁盘个数也是有限的
- 一次修改,需要修改多个表,很难保证数据一致性
- 缺点:范式的缺点是获取数据时,需要通过 Join 拼接出最后的数据。
- 分类:目前业界范式有:第一范式 (1NF)、第二范式 (2NF)、第三范式 (3NF)、巴斯 - 科德范式 (BCNF)、第四范式 (4NF)、第五范式 (5NF)。
# 函数依赖

# 三范式区分
# 第一范式
第一范式 1NF 核心原则就是:属性不可切割

很明显上图所示的表格设计是不符合第一范式的,商品列中的数据不是原子数据项,是可以进行分割的,因此对表格进行修改,让表格符合第一范式的要求,修改结果如下图所示:

实际上,1NF 是所有关系型据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如 SOL Server, Oracle, MySOL 中创建数据表的时候,如果数据表的设计不符合这个最其木的要求,那么操作一定是不能成功的。也就是说,只要在 RDBMS 中已经存在的数据表,一定是符合 1NF 的。
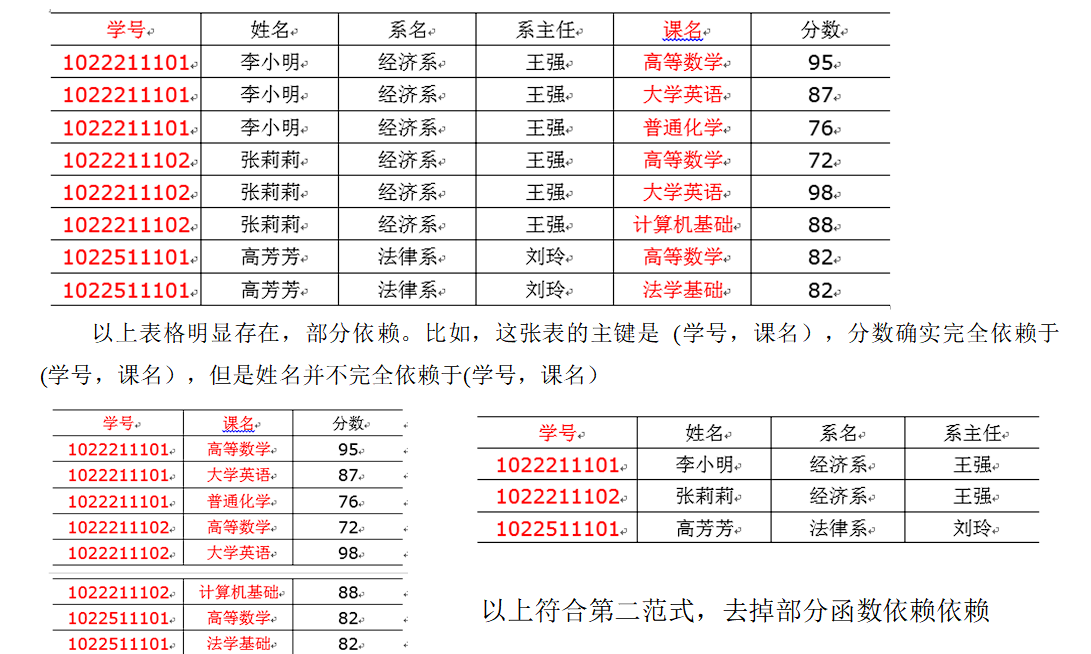
# 第二范式
第二范式 2NF 核心原则:不能存在 **“部分函数依赖 "**
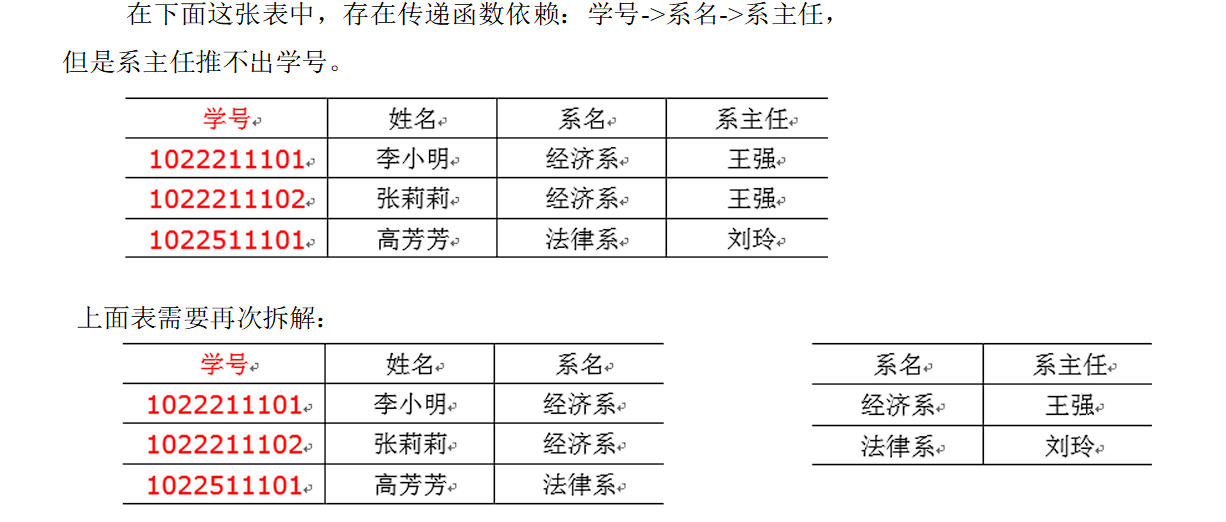
# 第三范式
第三范式 3NF 核心原则:不能存在传递函数依赖
# 关系建模与维度建模
当今的数据处理大致可以分成两大类:联机事务处理 OLTP(on-line transaction processing)、联机分析处理 OLAP(On-Line Analytical Processing)。OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。二者的主要区别对比如下表所示。
| 对比属性 | OLTP | OLAP |
|---|---|---|
| 读特性 | 每次查询只返回少量记录 | 对大量记录进行汇总 |
| 写特性 | 随机、低延时写入用户的输入 | 批量导入 |
| 使用场景 | 用户,Java EE 项目 | 内部分析师,为决策提供支持 |
| 数据表征 | 最新数据状态 | 随时间变化的历史状态 |
| 数据规模 | GB | TB 到 PB |
# 关系建模
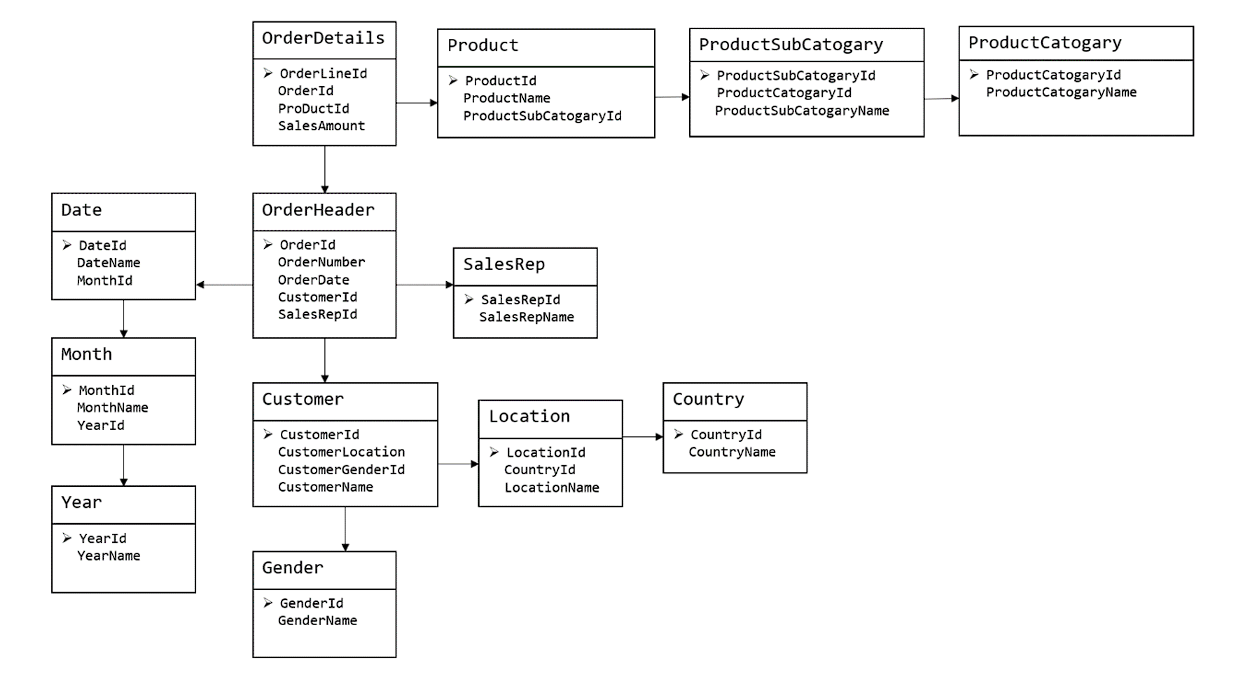
关系模型如图所示,严格遵循第三范式(3NF),从图中可以看出,较为松散、零碎,物理表数量多,而数据冗余程度低。由于数据分布于众多的表中,这些数据可以更为灵活地被应用,功能性较强。关系模型主要应用与 OLTP 系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
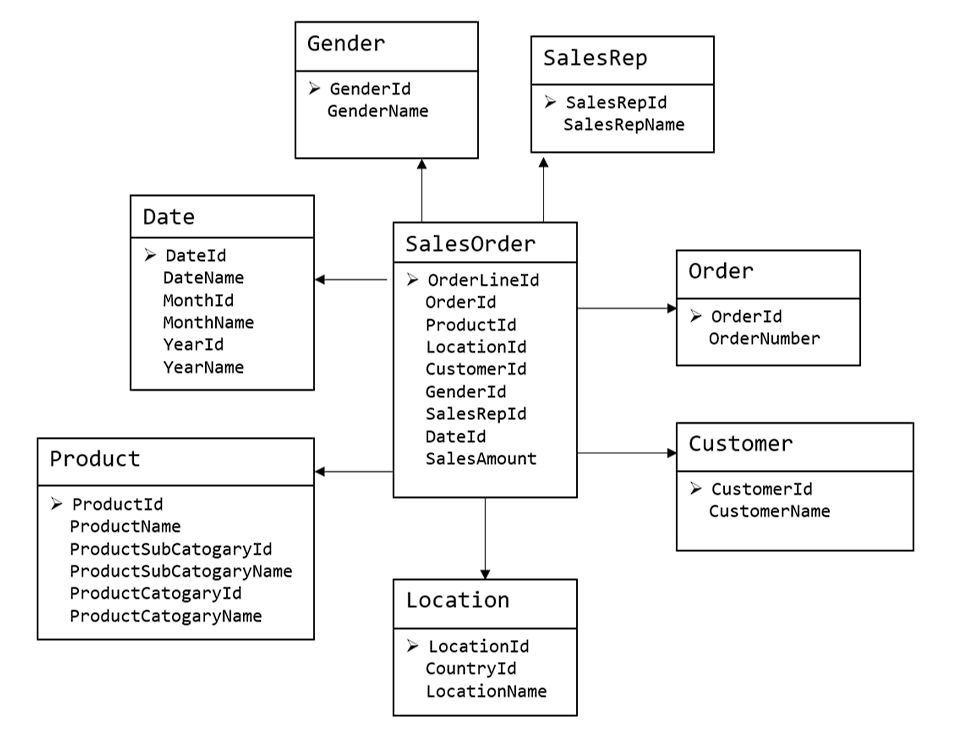
维度模型如图所示,主要应用于 OLAP 系统中,通常以某一个事实表为中心进行表的组织,主要面向业务,特征是可能存在数据的冗余,但是能方便的得到数据。
关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以通常我们采用维度模型建模,把相关各种表整理成两种:事实表和维度表两种。
# 维度建模
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
- 规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性,得到的维度模型称为雪花模型。
- 反规范化是指将多张表的数据冗余到一张表,其目的是减少 join 操作,提高查询性能,得到的模型称为星型模型。
数据仓库系统的主要目的是用于数据分析和统计,所以是否方便用户进行统计分析决定了模型的优劣。采用雪花模型,用户在统计分析的过程中需要大量的关联操作,使用复杂度高,同时查询性能很差,而采用星型模型,则方便、易用且性能好。所以出于易用性和性能的考虑,维度表一般是很不规范化的。
# 星型模型
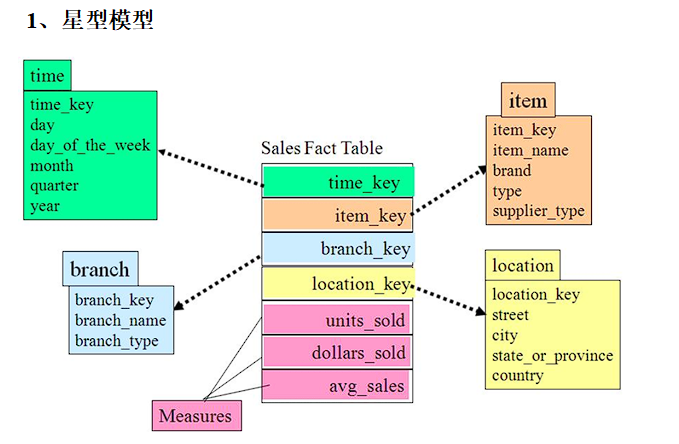
雪花模型与星型模型的区别主要在于维度的层级, 标准的星型模型维度只有一层 ,而雪花模型可能会涉及多级。
# 雪花模型
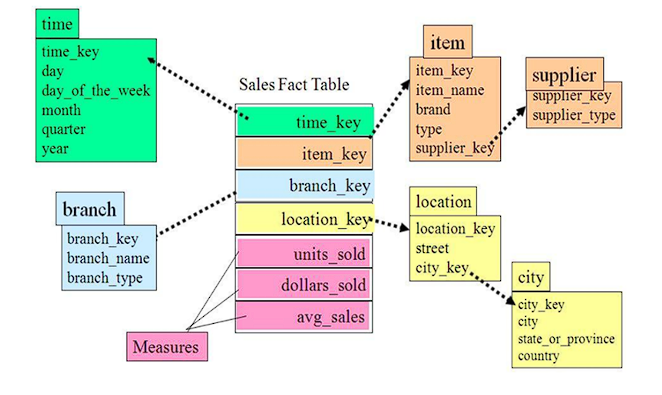
雪花模型,比较靠近 3NF,但是无法完全遵守,因为遵循 3NF 的性能成本太高。
# 星座模型
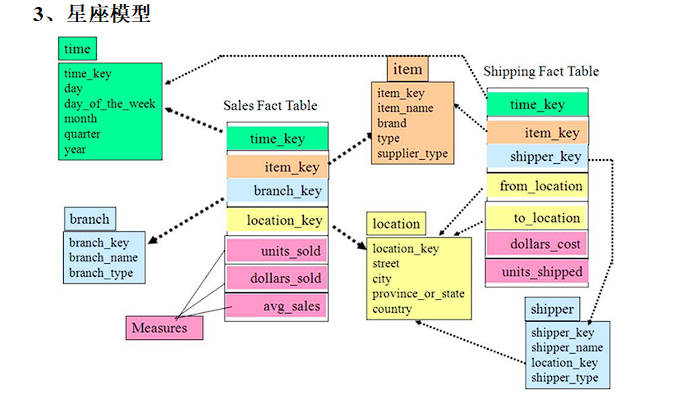
星座模型与前两种情况的区别是事实表的数量,星座模型是基于多个事实表。 基本上是很多数据仓库的常态,因为很多数据仓库都是多个事实表的。所以星座不星座只反映是否有多个事实表,他们之间是否共享一些维度表。
所以星座模型并不和前两个模型冲突。
# 模型的选择
首先就是星座不星座这个只跟数据和需求有关系,跟设计没关系,不用选择。
星型还是雪花,取决于性能优先,还是灵活更优先。
目前实际企业开发中,不会绝对选择一种,根据情况灵活组合,甚至并存(一层维度和多层维度都保存)但是整体来看,更倾向于维度更少的星型模型。尤其是 Hadoop 体系,减少 Join 就是减少 Shuffle,性能差距很大。(关系型数据可以依靠强大的主键索引)
# 维度变换
维度属性通常不是静态的,而是会随时间变化的,数据仓库的一个重要特点就是反映历史的变化,所以如何保存维度的历史状态是维度设计的重要工作之一。保存维度数据的历史状态,通常有以下两种做法,分别是全量快照表和拉链表。
# 全量快照表
离线数据仓库的计算周期通常为每天一次,所以可以每天保存一份全量的维度数据。这种方式的优点和缺点都很明显。
优点是简单而有效,开发和维护成本低,且方便理解和使用。
缺点是浪费存储空间,尤其是当数据的变化比例比较低时。
# 拉链表
拉链表的意义就在于能够更加高效的保存维度信息的历史状态。
[拉链表](09. 数仓搭建 - DWD 层.md ### 用户维度表(拉链表))
# 维度表和事实表
# 维度表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
维表的特征:
- 维表的范围很宽(具有多个属性、列比较多)
- 跟事实表相比,行数相对较小:通常 < 10 万条
- 内容相对固定:编码表
时间维度表:
| 日期 ID | day of week | day of year | 季度 | 节假日 |
|---|---|---|---|---|
| 2020-01-01 | 2 | 1 | 1 | 元旦 |
| 2020-01-02 | 3 | 2 | 1 | 无 |
| 2020-01-03 | 4 | 3 | 1 | 无 |
| 2020-01-04 | 5 | 4 | 1 | 无 |
| 2020-01-05 | 6 | 5 | 1 | 无 |
# 事实表
事实表中的每行数据代表一个 业务事件(下单、支付、退款、评价等)。“事实” 这个术语表示的是业务事件的度量值(可统计次数、个数、金额等),例如,订单事件中的下单金额。
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键、通常具有两个和两个以上的外键、外键之间表示维表之间多对多的关系。
事实表的特征:
- 非常的大
- 内容相对的窄:列数较少
- 经常发生变化,每天会新增加很多。
# 事务型事实表
以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量更新。
设计事务事实表时一般可遵循以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
# 周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。
# 累积型快照事实表
** 累计快照事实表用于跟踪业务事实的变化。** 例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。
| 订单 id | 用户 id | 下单时间 | 打包时间 | 发货时间 | 签收时间 | 订单金额 |
|---|---|---|---|---|---|---|
| 3-8 | 3-8 | 3-9 | 3-10 |
累积型快照事实表主要用于分析业务过程(里程碑)之间的时间间隔等需求。例如前文提到的用户下单到支付的平均时间间隔,使用累积型快照事实表进行统计,就能避免两个事务事实表的关联操作,从而变得十分简单高效。
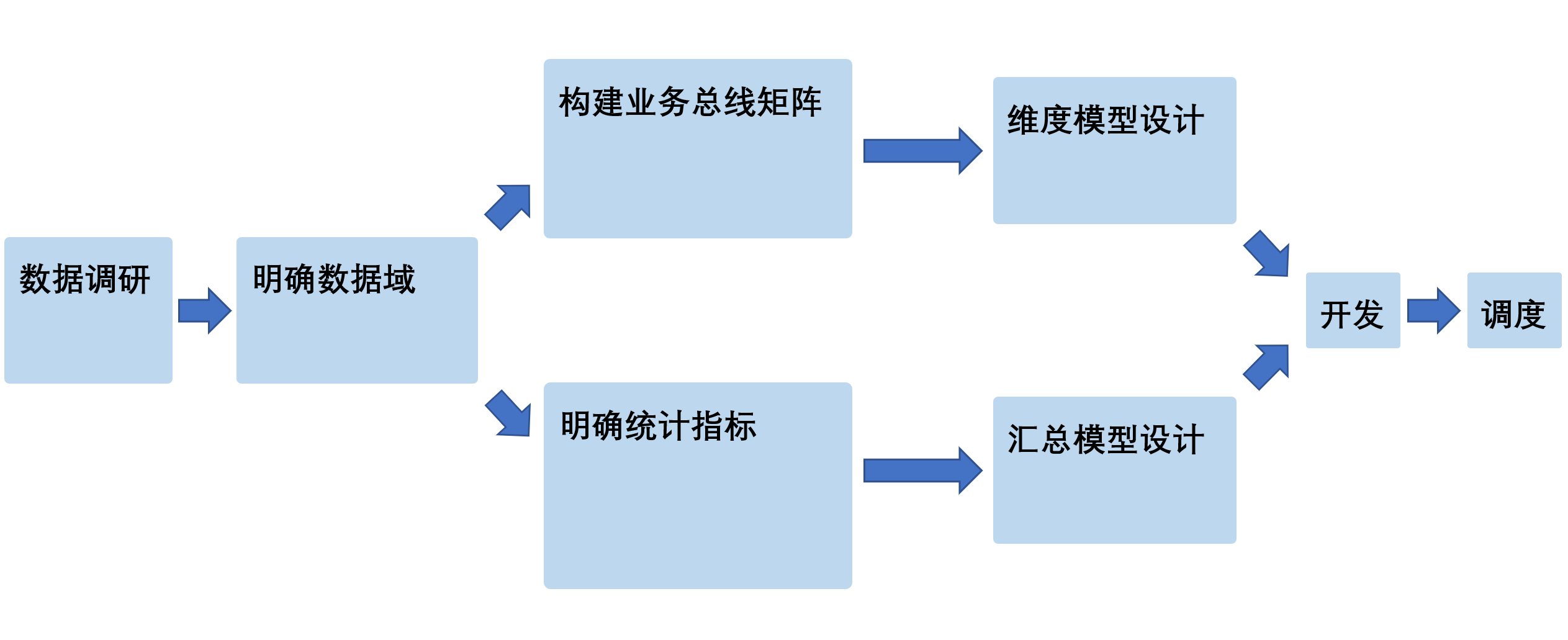
# 数据仓库建模

构建数据仓库的完整流程
# ODS 层
- 保持数据原貌不做任何修改,起到备份数据的作用。
- 数据采用压缩,减少磁盘存储空间(例如:原始数据 100G,可以压缩到 10G 左右)
- 创建分区表,防止后续的全表扫描
# DWD 层
DWD 层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
选择业务过程 在业务系统中,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。
声明粒度
数据粒度指数据仓库的表中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
典型的粒度声明如下: 订单中,每个商品项作为下单事实表中的一行,粒度为每次下单 每周的订单次数作为一行,粒度就是每周下单。 每月的订单次数作为一行,粒度就是每月下单
确定维度 维度的主要作用是描述业务是事实,主要表示的是 “谁,何处,何时” 等信息。
确定事实
此处的 “事实” 一词,指的是业务中的度量值,例如订单金额、下单次数等。
在 DWD 层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
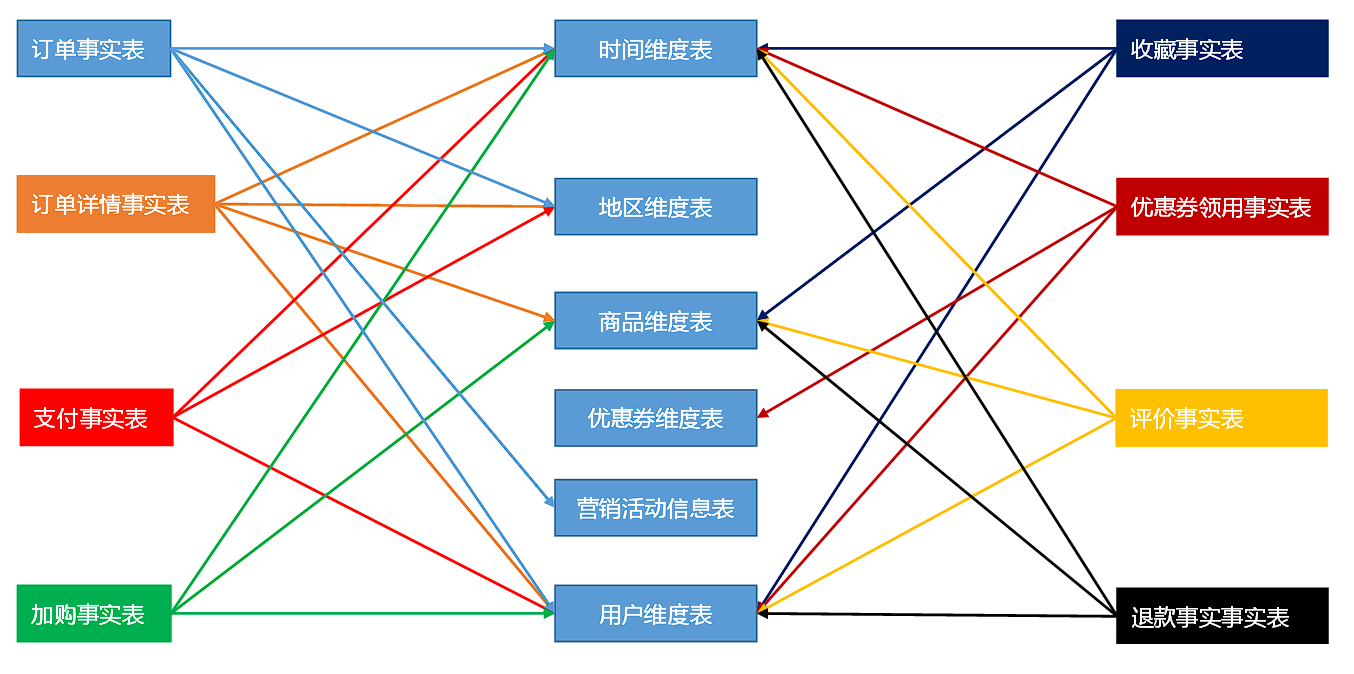
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 订单 | √ | √ | √ | √ | 件数 / 金额 | |||
| 订单详情 | √ | √ | √ | 件数 / 金额 | ||||
| 支付 | √ | √ | 金额 | |||||
| 加购 | √ | √ | √ | 件数 / 金额 | ||||
| 收藏 | √ | √ | √ | 个数 | ||||
| 评价 | √ | √ | √ | 个数 | ||||
| 退款 | √ | √ | √ | 件数 / 金额 | ||||
| 优惠券领用 | √ | √ | √ | 个数 |
至此,数仓的维度建模已经完毕,DWS、DWT 和 ADS 和维度建模已经没有关系了。
DWS 和 DWT 都是建宽表,宽表都是按照主题去建。主题相当于观察问题的角度。对应着维度表。
# DIM 层
基于维度建模理论进行构建,存放维度模型中的维度表保存一致性维度信息。
# DWS 层
统计各个主题对象的当天行为,服务于 DWT 层的主题宽表。
# DWT 层
以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建主题对象的全量宽表。
# ADS 层
对电商系统各大主题指标分别进行分析。