 Flink 时间语义与 Wartermark
Flink 时间语义与 Wartermark
# Flink 时间语义与 Wartermark
# Flink 中的时间语义
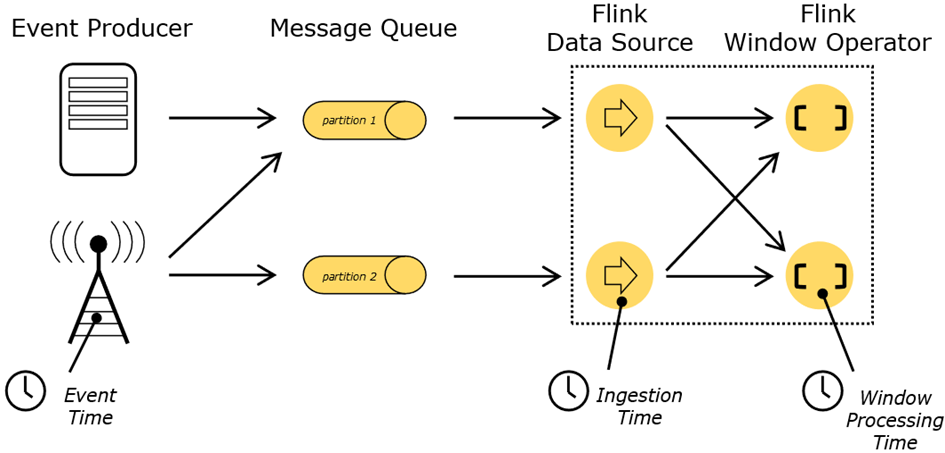
- Event Time**(事件时间)**:事件创建的时间(必须包含在数据源中的元素里面)。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
- Ingestion Time**(摄入时间)**:数据进入 Flink 的 source 算子的时间,与机器相关
- Processing Time**(处理时间)**:执行操作算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time。
# 哪种时间语义更重要
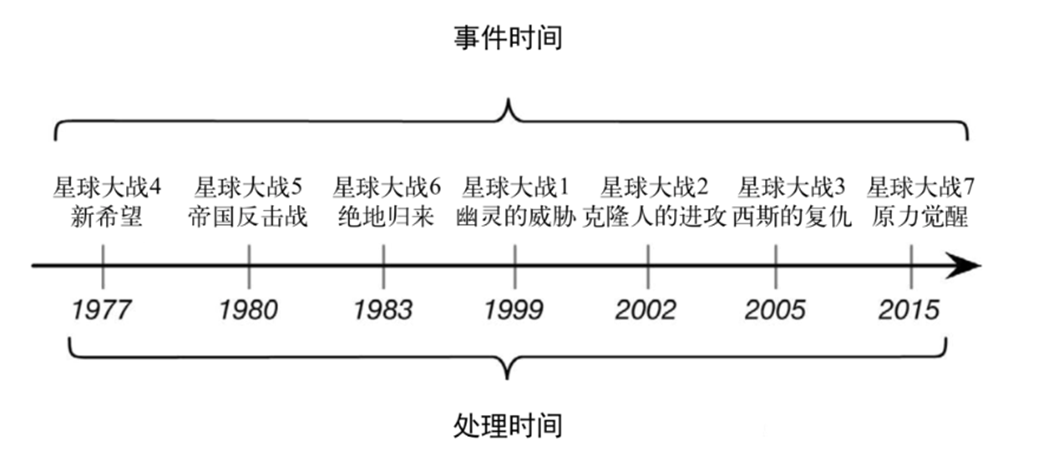
- 不同的时间语义有不同的应用场合
- 我们往往更关心事件时间(Event Time)
我们设想一个这样的场景,Alice 当她的手机连上网时,开始弹泡泡,然后游戏会将数据发送到我们编写的应用程序中,这时地铁突然进入了隧道,她的手机也断网了。Alice 还在玩这个游戏,而产生的事件将会缓存在手机中。当地铁离开隧道,Alice 的手机又在线了,而手机中缓存的游戏事件将发送到应用程序。我们的应用程序应该如何处理这些数据?
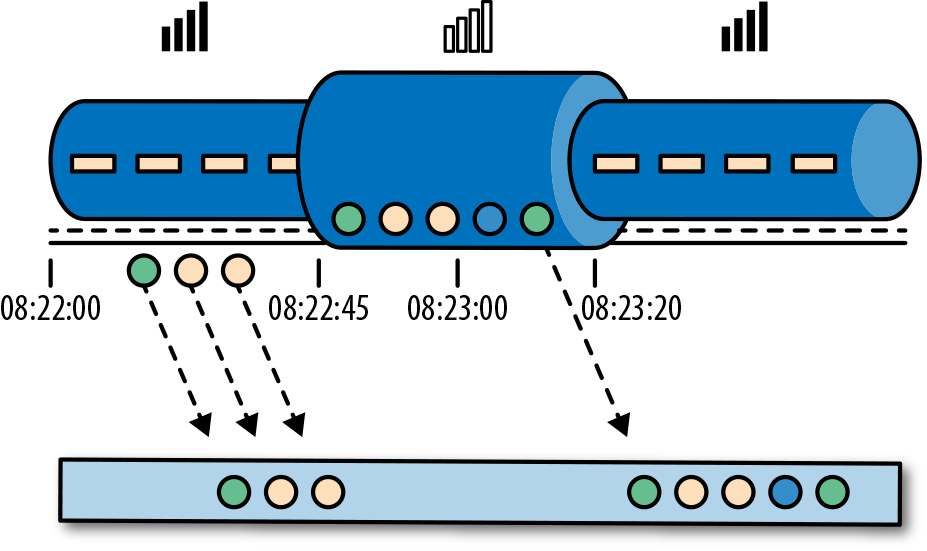
在 Alice 的这个例子中,流处理程序可能会碰到两个不同的时间概念:处理时间和事件时间。我们将在接下来的部分,讨论这两个概念。
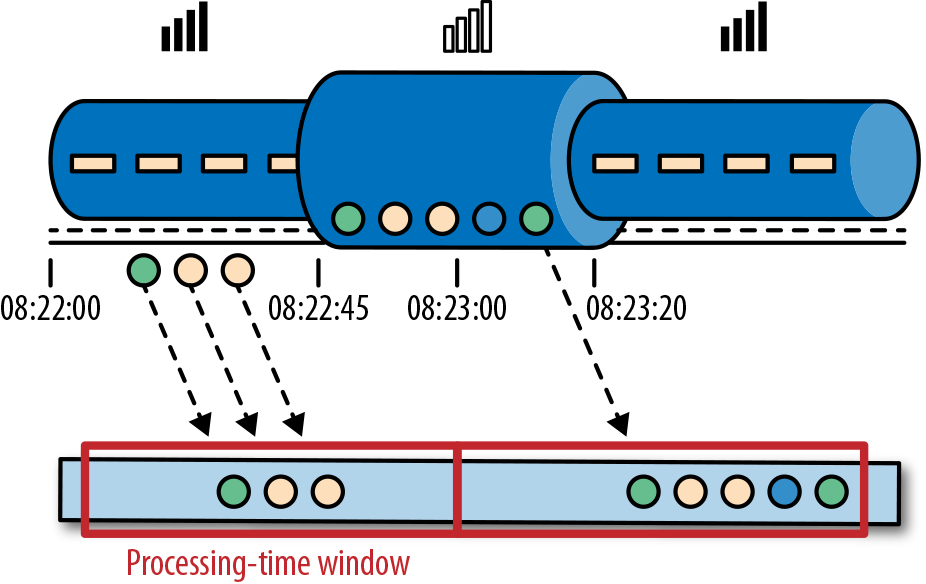
# 处理时间
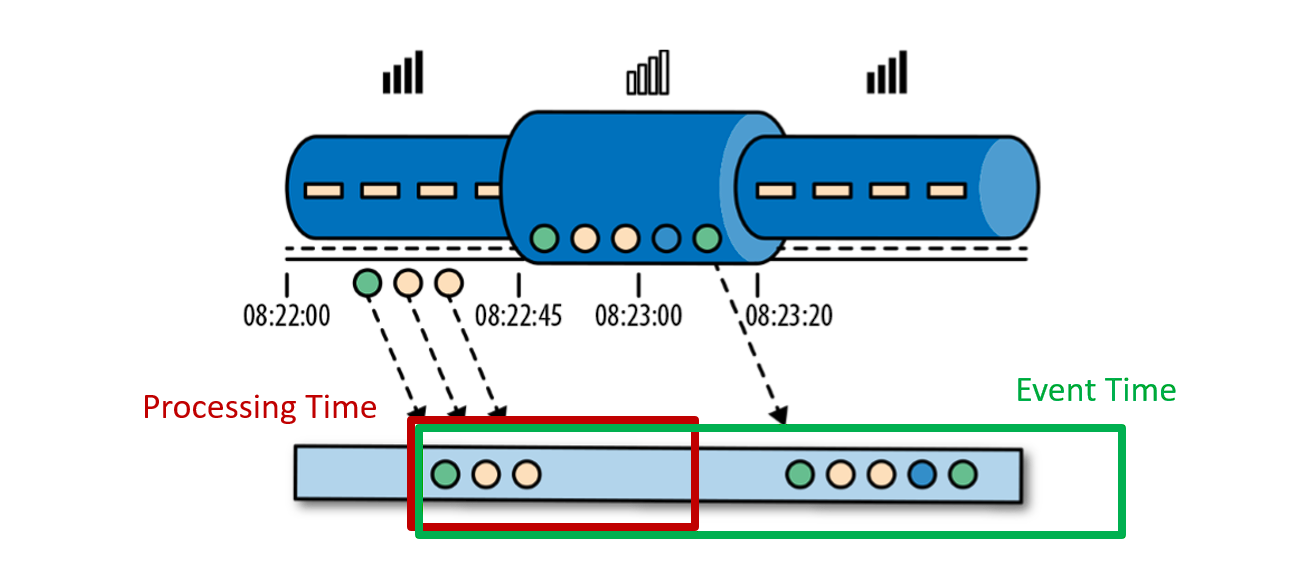
处理时间是处理流的应用程序的机器的本地时钟的时间(墙上时钟)。处理时间的窗口包含了一个时间段内来到机器的所有事件。这个时间段指的是机器的墙上时钟。如下图所示,在 Alice 的这个例子中,处理时间窗口在 Alice 的手机离线的情况下,时间将会继续行走。但这个处理时间窗口将不会收集 Alice 的手机离线时产生的事件。
# 事件时间
事件时间是流中的事件实际发生的时间。事件时间基于流中的事件所包含的时间戳。通常情况下,在事件进入流处理程序前,事件数据就已经包含了时间戳。下图展示了事件时间窗口将会正确的将事件分发到窗口中去。可以如实反应事情是怎么发生的。即使事件可能存在延迟。
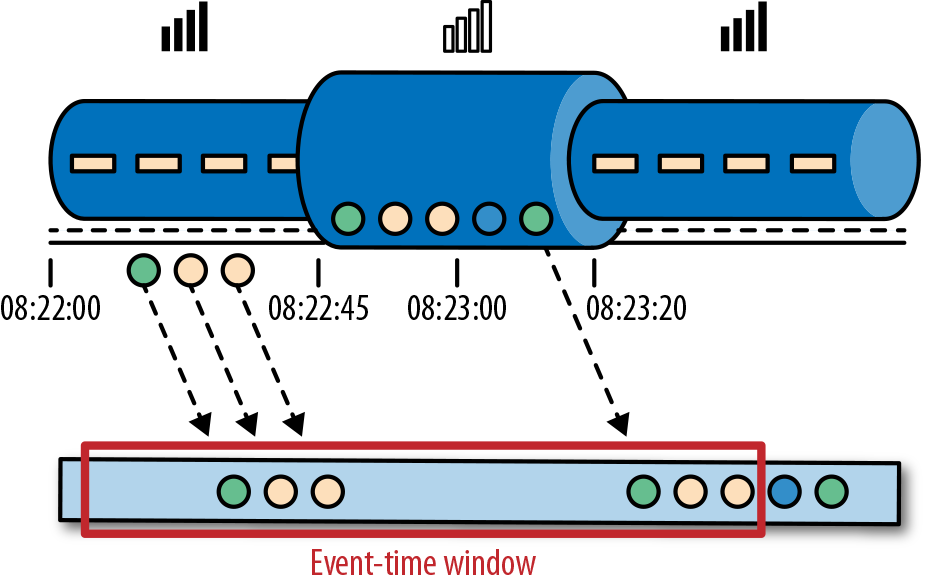
事件时间使得计算结果的过程不需要依赖处理数据的速度。基于事件时间的操作是可以预测的,而计算结果也是确定的。无论流处理程序处理流数据的速度快或是慢,无论事件到达流处理程序的速度快或是慢,事件时间窗口的计算结果都是一样的。
如果使用事件时间,即使碰到了事件乱序到达的情况,我们也可以保证结果的正确性。还有,当我们在处理可以重播的流数据时,由于时间戳的确定性,我们可以快进过去。也就是说,我们可以重播一条流,然后分析历史数据,就好像流中的事件是实时发生一样。另外,我们可以快进历史数据来使我们的应用程序追上现在的事件,然后应用程序仍然是一个实时处理程序,而且业务逻辑不需要改变。
# 如何选择
某些应用场合,不应该使用 Processing Time
Event Time 可以从日志数据的时间戳(timestamp)中提取
2017-11-02 18:37:15.624 INFO Fail over to rm1
# EventTime 的引入
在 Flink 的流式处理中,绝大部分的业务都会使用 eventTime,一般只在 eventTime 无法使用时,才会被迫使用 ProcessingTime 或者 IngestionTime。 如果要使用 EventTime,那么需要引入 EventTime 的时间属性,引入方式如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
2
3
# Watermark
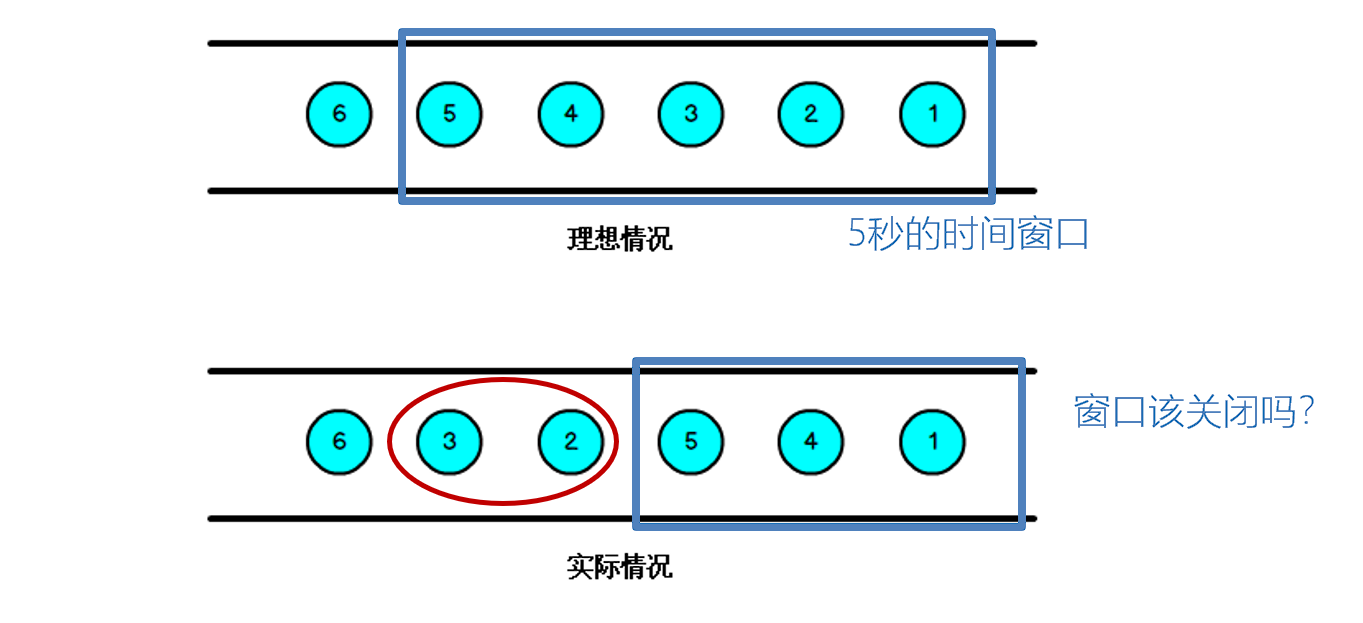
我们知道,流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的,虽然大部分情况下,流到 operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指 Flink 接收到的事件的先后顺序不是严格按照事件的 Event Time 顺序排列的。
- 当 Flink 以 Event Time 模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子
- 由于网络、分布式等原因,会导致乱序数据的产生
- 乱序数据会让窗口计算不准确
那么此时出现一个问题,一旦出现乱序,如果只根据 eventTime 决定 window 的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了,这个特别的机制,就是 Watermark。
- Watermark 是一种衡量 Event Time 进展的机制。
- Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用 Watermark 机制结合 window 来实现。
- 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,window 的执行也是由 Watermark 触发的。
- Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 eventTime 小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间等于 maxEventTime – t,那么这个窗口被触发执行。
# 几个重要的时间概念
- Flink 默认每隔 200msr (机器时间)向数据流中插入一次 Watermark
- 窗口结束时间
- 只有事件时间需要水位线
- 水位线产生的公式:水位线 = 系统观察到的最大事件时间戳 - 最大延迟时间(自定义设置的延时时间)
通常情况下,当水位线超过窗口结束时间时,窗口将不再接收事件,然后触发计算,计算完毕,窗口就被销毁了。
# 水位线
在基于事件时间的应用中,水位线用于生成每个任务的当前事件时间。基于时间的算子使用这个 “当前事件时间” 来触发计算和处理操作。例如,一个时间窗口任务(time-window task)会在任务的事件时间超出窗口的关闭边界时,完成窗口计算,并输出计算结果。
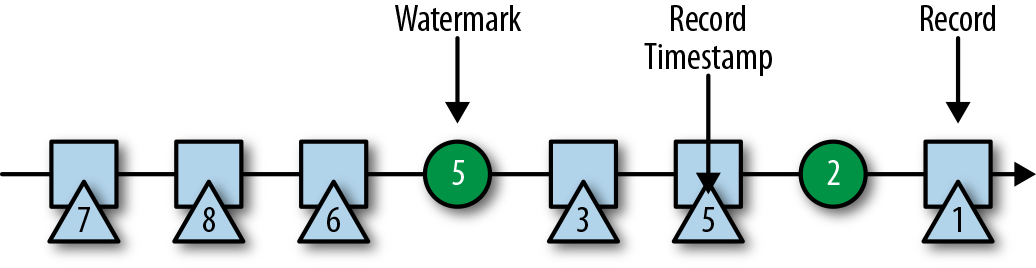
在 Flink 中,水位线被实现为一条特殊的数据记录,它里面以长整型值保存了一个时间戳。水位线在带有时间戳的数据流中,跟随着其它数据一起流动,如下图所示。
- watermark 是一条特殊的数据记录
- watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
- watermark 与数据的时间戳相关。带有时间戳 T 的水位线表示,所有后续数据的时间戳都应该大于 T。
上面的第二个属性用于处理带有乱序时间戳的数据流,比如上图中时间戳 3 和 5 的数据。基于时间的算子任务会收集和处理数据(这些数据可能具有乱序的时间戳),并在事件时间时钟到达某个时刻时完成计算。这个时刻就表示数据收集的截止,具有之前时间戳的数据应该都已经到达、不再需要了;而其中的事件时间时钟,正是由当前接收到的水位线来指示的。
如果任务再接收到的数据违反了 watermark 的这一属性,也就是时间戳小于以前接收到的水位线时,它所属的那部分计算可能已经完成了。这种数据被称为延迟数据(late records)。Flink 提供了处理延迟数据的不同方式,我们会在 “处理延迟数据” 一节中讨论。
# Watermark 的传递和事件时间
Flink 将数据流拆分为多个分区,并通过单独的算子任务并行地处理每个分区。每个分区都是一个流,里面包含了带着时间戳的数据和 watermark。一个算子与它前置或后续算子的连接方式有多种情况,所以它对应的任务可以从一个或多个 “输入分区” 接收数据和 watermark,同时也可以将数据和 watermark 发送到一个或多个 “输出分区”。接下来,我们将详细描述一个任务如何向多个输出任务发送 watermark,以及如何通过接收到的 watermark 来驱动事件时间时钟前进。
任务为每个输入分区维护一个分区水位线(watermark)。当从一个分区接收到 watermark 时,它会比较新接收到的值和当前水位值,然后将相应的分区 watermark 更新为两者的最大值。然后,任务会比较所有分区 watermark 的大小,将其事件时钟更新为所有分区 watermark 的最小值。如果事件时间时钟前进了,任务就将处理所有被触发的定时器操作,并向所有连接的输出分区发送出相应的 watermark,最终将新的事件时间广播给所有下游任务。
下图显示了具有四个输入分区和三个输出分区的任务如何接收 watermark、更新分区 watermark 和事件时间时钟,以及向下游发出 watermark。
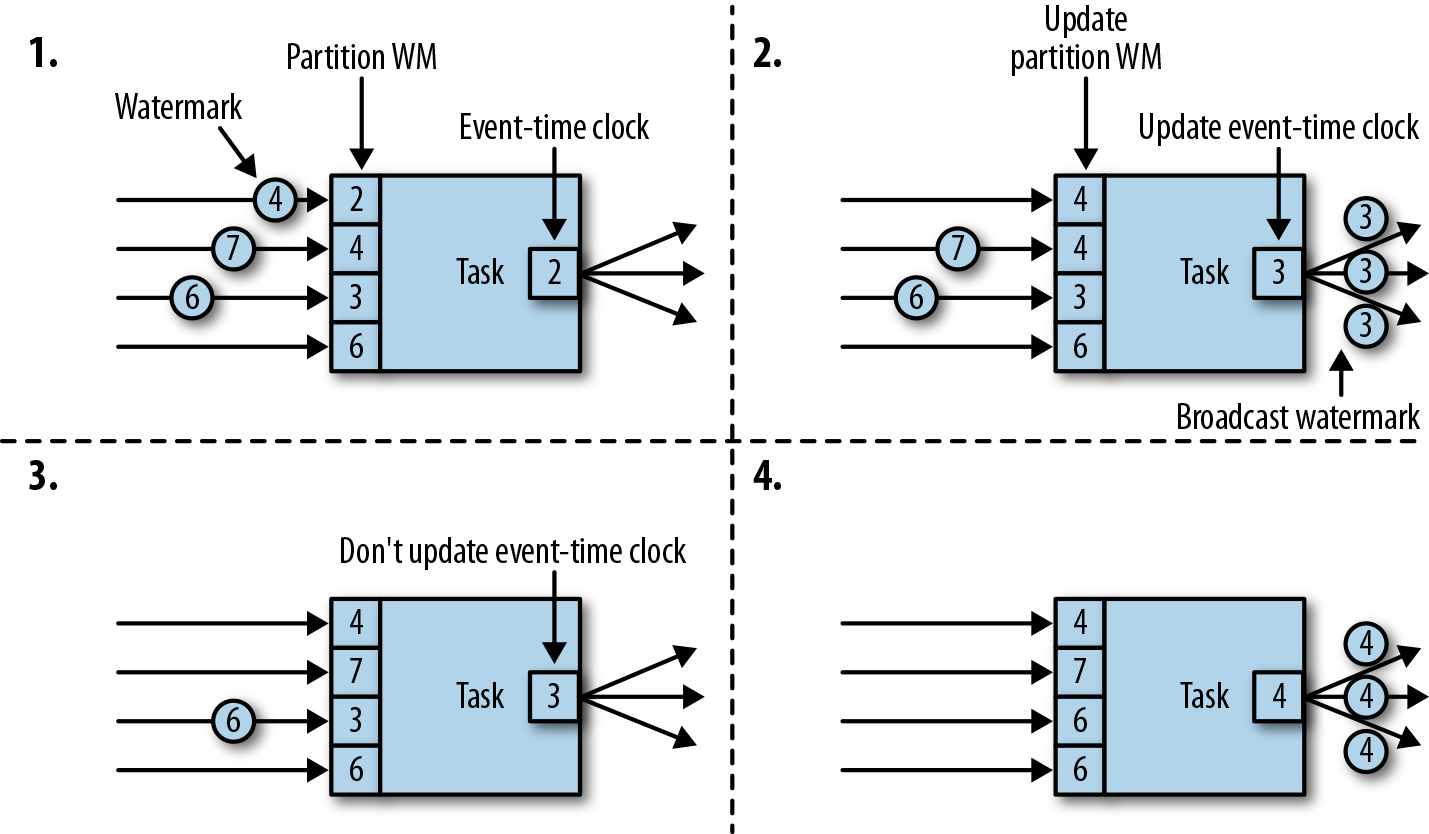
具有两个或多个输入流(如 Union 或 CoFlatMap)的算子任务(参见 “多流转换” 一节)也会以所有分区 watermark 的最小值作为事件时间时钟。它们并不区分不同输入流的分区 watermark,所以两个输入流的数据都是基于相同的事件时间时钟进行处理的。当然我们可以想到,如果应用程序的各个输入流的事件时间不一致,那么这种处理方式可能会导致问题。
Flink 的水位处理和传递算法,确保了算子任务发出的时间戳和 watermark 是 “对齐” 的。不过它依赖一个条件,那就是所有分区都会提供不断增长的 watermark。一旦一个分区不再推进水位线的上升,或者完全处于空闲状态、不再发送任何数据和 watermark,任务的事件时间时钟就将停滞不前,任务的定时器也就无法触发了。对于基于时间的算子来说,它们需要依赖时钟的推进来执行计算和清除状态,这种情况显然就会有问题。如果任务没有定期从所有输入任务接收到新的 watermark,那么基于时间的算子的处理延迟和状态空间的大小都会显著增加。
# Watermark 的引入
Event Time 的使用一定要指定数据源中的时间戳,调用 assignTimestampAndWatermarks 方法,传入一个 BoundedOutOfOrdernessTimestampExtractor,就可以指定 watermark。
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//设置时间语义为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env
.socketTextStream("localhost", 9999, '\n')
.map(line => {
val arr = line.split(" ")
// 事件时间的单位必须为毫秒
(arr(0), arr(1).toLong * 1000L)
})
// 分配时间戳和水位线一定要keyBy之前进行
// 水位线 = 系统观察到的最大事件时间 - 最大延迟时间(自定义设置的延时时间)
.assignTimestampsAndWatermarks(
// 设置事件的最大延迟时间是5s
new BoundedOutOfOrdernessTimestampExtractor[(String, Long)](Time.seconds(5)) {
override def extractTimestamp(t: (String, Long)) = {
// 告诉系统,时间戳是元组的第二个字段
t._2
}
}
)
.keyBy(_._1)
.timeWindow(Time.seconds(10))
.process(new WindowResult)
env.execute()
}
class WindowResult extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
out.collect(new Timestamp(context.window.getStart) + " ~ " + new Timestamp(context.window.getEnd) + " 的窗口中有 " + elements.size + " 个元素")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
发送数据
nc -lk 9999
a 1
a 1
a 1
a 4
a 8
a 15
a 1
a 1
a 1
2
3
4
5
6
7
8
9
10
输出结果
1970-01-01 08:00:00.0 ~ 1970-01-01 08:00:10.0 的窗口中有 5 个元素!
由于我们输入了 a 15 窗口关闭了,并且水位线是 200ms,a 15 后的 [0,10) 就算是迟到数据窗口不接受。
Event Time 的使用一定要指定数据源中的时间戳。否则程序无法知道事件的事件时间是什么 (数据源里的数据没有时间戳的话,就只能使用 Processing Time 了)。调用 assignTimestampAndWatermarks 方法,传入一个 BoundedOutOfOrdernessTimestampExtractor,就可以指定 watermark
- 对于排好序的数据,不需要延迟触发,可以只指定时间戳就行了
dataStream.assignTimestampsAndWatermarks(_.timestamp * 1000)
# 水位线插入时间
周期性的生成 watermark:系统会周期性的将 watermark 插入到流中 (水位线也是一种特殊的事件!)。默认周期是 200 毫秒。可以使用 ExecutionConfig.setAutoWatermarkInterval() 方法进行设置。
Flink 暴露了 TimestampAssigner 接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳和生成 watermark, assignTimestampsAndWatermarks() 支持两种类型
- AssignerWithPeriodicWatermarks
- AssignerWithPunctuatedWatermarks
以上两个接口都继承自 TimestampAssigner。
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//设置时间语义为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//系统默认每隔200ms插入一次水位线
//下面的语句设置为每间隔1分钟插入一次水位线
env.getConfig.setAutoWatermarkInterval(60000)
env
.socketTextStream("localhost", 9999, '\n')
.map(line => {
val arr = line.split(" ")
// 事件时间的单位必须为毫秒
(arr(0), arr(1).toLong * 1000L)
})
// 分配时间戳和水位线一定要keyBy之前进行
// 水位线 = 系统观察到的最大事件时间 - 最大延迟时间(自定义设置的延时时间)
.assignTimestampsAndWatermarks(
// 设置事件的最大延迟时间是5s
new BoundedOutOfOrdernessTimestampExtractor[(String, Long)](Time.seconds(5)) {
override def extractTimestamp(t: (String, Long)) = {
// 告诉系统,时间戳是元组的第二个字段
t._2
}
}
)
.keyBy(_._1)
.timeWindow(Time.seconds(10))
.process(new WindowResult)
env.execute()
}
class WindowResult extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
out.collect(new Timestamp(context.window.getStart) + " ~ " + new Timestamp(context.window.getEnd) + " 的窗口中有 " + elements.size + " 个元素")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
发送数据
nc -lk 9999
a 1
a 1
a 8
a 15
a 1
a 1
a 1
2
3
4
5
6
7
8
输出结果
1970-01-01 08:00:00.0 ~ 1970-01-01 08:00:10.0 的窗口中有 5 个元素!
# TimestampAssigner
定义了抽取时间戳,以及生成 watermark 的方法,有两种类型
# AssignerWithPeriodicWatermarks
- 周期性的生成 watermark:系统会周期性的将 watermark 插入到流中
- 默认周期是 200 毫秒,可以使用
ExecutionConfig.setAutoWatermarkInterval()方法进行设置 - 升序和前面乱序的处理 BoundedOutOfOrderness ,都是基于周期性 watermark 的。
例子,自定义一个周期性的时间戳抽取:
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//设置时间语义为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//系统默认每隔200ms插入一次水位线
//下面的语句设置为每间隔1分钟插入一次水位线
env.getConfig.setAutoWatermarkInterval(60000)
env
.socketTextStream("localhost", 9999, '\n')
.map(line => {
val arr = line.split(" ")
// 事件时间的单位必须为毫秒
(arr(0), arr(1).toLong * 1000L)
})
// 分配时间戳和水位线一定要keyBy之前进行
// 水位线 = 系统观察到的最大事件时间 - 最大延迟时间(自定义设置的延时时间)
.assignTimestampsAndWatermarks(
new MyAssigner
)
.keyBy(_._1)
.timeWindow(Time.seconds(10))
.process(new WindowResult)
env.execute()
// 周期性的插入水位线
class MyAssigner extends AssignerWithPeriodicWatermarks[(String, Long)] {
// 设置最大延迟时间
val bound: Long = 10 * 1000L
// 系统观察到的元素包含的最大时间戳
var maxTs: Long = Long.MaxValue + bound
//定义抽取时间戳的逻辑,每到一个事件就调用一次
override def extractTimestamp(t: (String, Long), l: Long) = {
maxTs = maxTs.max(t._2) // 更新观察到的最大时间戳
t._2 // 将抽取的时间戳返回
}
// 产生水位线的逻辑
// 默认每隔200ms调用一次,我们设置了每隔1分钟调用一次
override def getCurrentWatermark = {
// 观察到的最大时间 - 最大延迟时间
println("观察到的最大时间戳是:" + maxTs)
new Watermark(maxTs - bound)
}
}
}
class WindowResult extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[String]): Unit = {
out.collect(new Timestamp(context.window.getStart) + " ~ " + new Timestamp(context.window.getEnd) + " 的窗口中有 " + elements.size + " 个元素")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
产生 watermark 的逻辑:每隔 1 分钟,Flink 会调用 AssignerWithPeriodicWatermarks 的 getCurrentWatermark() 方法。如果方法返回一个时间戳大于之前水位的时间戳,新的 watermark 会被插入到流中。这个检查保证了水位线是单调递增的。如果方法返回的时间戳小于等于之前水位的时间戳,则不会产生新的 watermark。
# AssignerWithPunctuatedWatermarks
没有时间周期规律,可打断的生成 watermark。间断式地生成 watermark。和周期性生成的方式不同,这种方式不是固定时间的,而是可以根据需要对每条数据进行筛选和处理。
有时候输入流中会包含一些用于指示系统进度的特殊元组或标记。Flink 为此类情形以及可根据输入元素生成水位线的情形提供了 AssignerWithPunctuatedWatermarks 接口。该接口中的 checkAndGetNextWatermark() 方法会在针对每个事件的 extractTimestamp() 方法后立即调用。它可以决定是否生成一个新的水位线。如果该方法返回一个非空、且大于之前值的水位线,算子就会将这个新水位线发出。
直接上代码来举个例子,我们只给 sensor_1 的传感器的数据流插入 watermark:
// 间断式的插入水位线
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[(String, Long)] {
// 设置最大延迟时间
val bound: Long = 10 * 1000L
// 每来一条数据就调用一次数据
// 紧跟 extractTimestamp 函数调用
override def checkAndGetNextWatermark(t: (String, Long), l: Long) = {
if (t._1 == "sensor_1") {
// 抽取的时间戳 - 最大延迟时间
new Watermark(l - bound)
} else {
null
}
}
// 每来一条数据就调用一次数据
override def extractTimestamp(t: (String, Long), l: Long) = {
t._2
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 水位线的影响
水位线用来平衡延迟和计算结果的正确性。水位线告诉我们,在触发计算(例如关闭窗口并触发窗口计算)之前,我们需要等待事件多长时间。基于事件时间的操作符根据水位线来衡量系统的逻辑时间的进度。
完美的水位线永远不会错:时间戳小于水位线的事件不会再出现。在特殊情况下 (例如非乱序事件流),最近一次事件的时间戳就可能是完美的水位线。启发式水位线则相反,它只估计时间,因此有可能出错,即迟到的事件 (其时间戳小于水位线标记时间) 晚于水位线出现。针对启发式水位线,Flink 提供了处理迟到元素的机制。
设定水位线通常需要用到领域知识。举例来说,如果知道事件的迟到时间不会超过 5 秒,就可以将水位线标记时间设为收到的最大时间戳减去 5 秒。另一种做法是,采用一个 Flink 作业监控事件流,学习事件的迟到规律,并以此构建水位线生成模型。
如果最大延迟时间设置的很大,计算出的结果会更精确,但收到计算结果的速度会很慢,同时系统会缓存大量的数据,并对系统造成比较大的压力。如果最大延迟时间设置的很小,那么收到计算结果的速度会很快,但可能收到错误的计算结果。不过 Flink 处理迟到数据的机制可以解决这个问题。上述问题看起来很复杂,但是恰恰符合现实世界的规律:大部分真实的事件流都是乱序的,并且通常无法了解它们的乱序程度 (因为理论上不能预见未来)。水位线是唯一让我们直面乱序事件流并保证正确性的机制;否则只能选择忽视事实,假装错误的结果是正确的。
- 在 Flink 中,watermark 由应用程序开发人员生成,这通常需要对相应的领域有一定的了解
- 如果 watermark 设置的延迟太久,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果
- 而如果 watermark 到达得太早,则可能收到错误结果,不过 Flink 处理迟到数据的机制可以解决这个问题