 函数
函数
# 函数
一个 C 程序由一个主函数和若干其他函数构成。一个较大的程序可分为若干程序模块,每个模块实现一个特定的功能。在高级语言中用子程序实现模块的功能,而子程序由函数来实现。
# 函数的声明、定义与调用
# 函数的声明与定义
函数间的调用关系是,由主函数调用其他函数,其他函数也可以互相调用。同一个函数可以被一个或多个函数调用任意次,如下图所示:
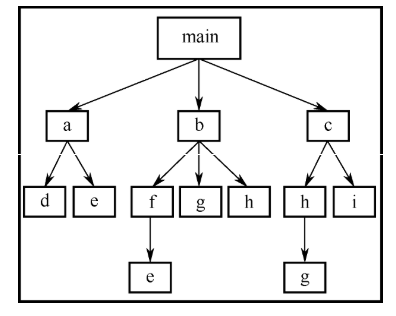
下面以具体例子来说明。
func.h 中存放的是标准头文件的声明和 main 函数中调用的两个子函数的声明,如果不在头文件中对使用的函数进行声明,那么在编译时会出现警告。
func.h
#include <stdio.h>
#include <stdlib.h>
int printstar(int i); //函数声明 作用是编译时对函数进行形参和返回值的类型检查,形参名字可以省略只写类型
void print_message();
2
3
4
5
func.c 是子函数 printstar 和 print_message 的实现,也称定义;
func.c
#include "func.h" //""比<>优先级高
int printstar(int i) // i 即为形式参数
{
printf("**********************\n");
printf("printstar %d\n", i);
return i + 3;
}
void print_message() //可以调用 printstar
{
printf("how do you do\n");
printstar(3);
}
2
3
4
5
6
7
8
9
10
11
12
13
main.c 是 main 函数
main.c
#include "func.h"
int main()
{
int a = 10;
a = printstar(a);
print_message();
printstar(a);
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
C 语言的编译和执行具有以下特点:
- 一个 C 程序由一个或多个程序模块组成,每个程序模块作为一个源程序文件。对于较大的程序,通常将程序内容分别放在若干源文件中,再由若干源程序文件组成一个 C 程序。这样 处理便于分别编写、分别编译,进而提高调试效率。一个源程序文件可以为多个 C 程序共用。
- 一个源程序文件由一个或多个函数及其他有关内容(如命令行、数据定义等)组成。一个源程序文件是一个编译单位,在程序编译时是以源程序文件为单位而不是以函数为单位进行编 译的。main.c 和 func.c 分别单独编译,在链接成为可执行文件时,main 中调用的函数 printstar 和 print_message 才会通过链接去找到函数定义的位置。
- C 程序的执行是从 main 函数开始的,如果在 main 函数中调用其他函数,那么在调用后会返回到 main 函数中,在 main 函数中结束整个程序的运行。
- 所有函数都是平行的,即在定义函数时是分别进行的,并且是互相独立的。一个函数并不从属于另一函数,即函数不能嵌套定义。函数间可以互相调用,但不能调用 main 函数。main 函数是由系统调用的,例如上面代码块中 的 main 函数中调用 print_message 函数,而 print_message 函数 中又调用 printstar 函数,我们把这种调用称为嵌套调用。
函数的声明与定义的差异如下:
- 函数的定义是指对函数功能的确立,包括指定函数名、函数值类型、形参及其类型、函数体等,它是一个完整的、独立的函数单位。
- 函数的声明的作用是把函数的名字、函数类型及形参的类型、个数和顺序通知编译系统,以便在调用该函数时编译系统能正确识别函数并检查调用是否合法。
隐式声明:C 语言中有几种声明的类型名可以省略。例如,函数如果不显式地声明返回值的类型,那么它默认返回整型;使用旧风格声明函数的形式参数时,如果省略参数的类型,那么编译器默认它们为整型。然而,依赖隐式声明并不是好的习惯,因为隐式声明容易让代码的读者产生疑问:编写者是否是有意遗漏了类型名?还是不小心忘记了?显式声明能够清楚地表达意图!
# 函数的分类与调用
从用户角度来看,函数分为如下两种:
标准函数:即库函数,这是由系统提供的,用户不必自己定义的函数,可以直接使用它们,如 printf 函数、scanf 函数。不同的 C 系统提供的库函数的数量和功能会有一些不同,但 许多基本的函数是相同的。
用户自己定义的函数:用以解决用户的专门需要。 从函数的形式看,函数分为如下两类。
无参函数:一般用来执行指定的一组操作。在调用无参函数时,主调函数不向被调用函数传递数据。 无参函数的定义形式如下:
类型标识符 函数名() { 声明部分 语句部分 }1
2
3
4
5有参函数:主调函数在调用被调用函数时,通过参数向被调用函数传递数据。 有参函数的定义形式如下:
类型标识符 函数名(形式参数表列) { 声明部分 语句部分 }1
2
3
4
5
在不同的函数之间传递数据时,可以使用的方法如下:
- 参数:通过形式参数和实际参数。
- 返回值:用 return 语句返回计算结果。
- 全局变量:外部变量。
全局变量的使用:
#include <stdio.h>
#include <stdlib.h>
int i = 10; //全局变量
void print(int a)
{
printf("print i=%d\n", i);
}
int main()
{
printf("main i=%d\n", i);
i = 5;
print(i);
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
全局变量 i 存储在数据段,所以 main 函数和 print 函数都是可见的。全局变量不会因为某个函数执行结束而消失,在整个进程的执行过程中始终有效,因此工作中应尽量避免使用全局变量!
我们在函数内定义的变量都称为局部变量,局部变量存储在自己的函数对应的栈空间内,函数执行结束后,函数内的局部变量所分配的空间将会得到释放。如果局部变量与全局变量重名,那么将采取就近原则,即实际获取和修改的值是局部变量的值。
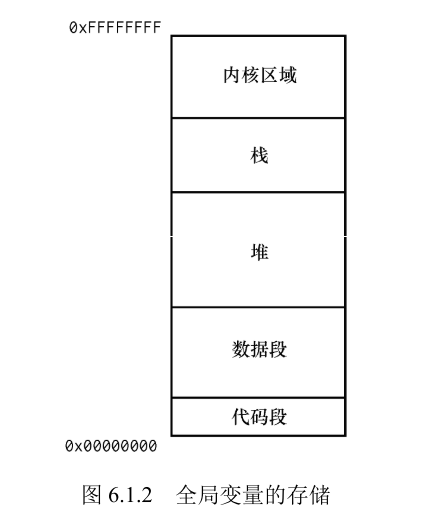
关于形参与实参的一些说明:
- 定义函数中指定的形参,如果没有函数调用,那么它们并不占用内存中的存储单元。只有在发生函数调用时,函数 print 中的形参才被分配内存单元。在调用结束后,形参所占的内存单元也会被释放。
- 实参可以是常量、变量或表达式,但要求它们有确定的值,例如,print (i+3) 在调用时将实参的值赋给形参。假如 print 函数有两个形参,如 print (int a,int b),那么实际调用 print 函数时,使用 print (i,i++) 是不合适的,因为 C 标准未规定函数调用是从左到右计算还是从右 到左计算,因此不同的编译会有不同的标准,造成代码在移植过程中发生非预期错误。
- 在被定义的函数中,必须指定形参的类型。如果实参列表中包含多个实参,那么各参数间用逗号隔开。实参与形参的个数应相等,类型应匹配,且实参与形参应按顺序对应,一一传递 数据。
- 实参与形参的类型应相同或赋值应兼容。
- 实参向形参的数据传递是单向 “值传递”,只能由实参传给形参,而不能由形参传回给实参。在调用函数时,给形参分配存储单元,并将实参对应的值传递给形参,调用结束后,形参 单元被释放,实参单元仍保留并维持原值。
- 形参相当于局部变量,因此不能再定义局部变量与形参同名,否则会造成编译不通。
# 嵌套调用
在上面函数的声明和定义的代码中,可以看到 print_message 函数调用 printstar 函数时,必须等 printstar 函 数执行结束并返回 print_message 后,再从 print_message 函数返回到 main 函数。那么是否可以从 printstar 函数直接到达 main 函数呢?可以使用 goto 语句吗?答案显然是不行的,前面讲过 goto 语句只能在函数内使用。下面我们 setjmp 与 longjmp 实现函数间的跳转。
#include <stdio.h>
#include <stdlib.h>
#include <setjmp.h>
jmp_buf envbuf;
void b()
{
printf("I am b func\n");
longjmp(envbuf, 5); //回到 setjmp 位置 第二个参数为返回值 返回5给上文
}
void a()
{
printf("before b(),I am a func\n");
b();
printf("after b(),I am a func\n");
}
void main()
{
int i;
i = setjmp(envbuf); //保存进程执行的上下文
if (i == 0)
{
a();
}
system("pause");
return;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
原理为程序运行起来 后称之为进程,启动 Windows 的任务管理器我们可以看到很多进程,我们的进程执行到 setjmp 位置时,通过 setjmp 函数保存了进程的上下文(处理器运行进程期间,运行进程的信息被存储 在处理器的寄存器和高速缓存中,执行的进程被加载到寄存器的数据集被称为上下文),所以当 执行到函数 b 时,可以通过 longjmp 恢复 envbuf 的操作。
# 递归调用
假设现在要求读者写一个程序来求数字 n 的阶乘。读者可能会觉得这很简单,写个 for 循环就可以实现。然而,使用递归来实现更好一些,因为使用递归在解决一些问题时,可以让问题变 得简单,降低编程的难度。
n 的阶乘的递归调用实现
#include <stdio.h>
#include <stdlib.h>
//求 n 的阶乘
int f(int n)
{
if (1 == n)
{
return 1;
}
return n * f(n - 1);
}
//走楼梯
int step(int n)
{
if (1 == n)
{
return 1;
}
if (2 == n)
{
return 2;
}
return step(n - 1) + step(n - 2);
}
int main()
{
int n;
int ret;
scanf("%d", &n); //请输入数字的大小
ret=f(n);
printf("%d\n", ret);
scanf("%d", &n); //请输入台阶数
ret=step(n);
printf("%d\n", ret);
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
汉诺塔问题:碟子都在 A 柱上,借助 B 柱, 把碟子都放到 C 柱上,一次只能移动一个碟子,同时要求只能是小碟子垒在大碟子上。
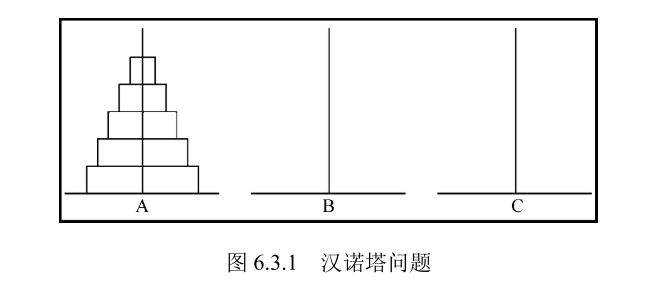
根据图示,我们可以把问题分解为以下三个步骤:
- 将 A 上的 n-1 个盘借助 C 柱先移到 B 柱上。
- 把 A 柱上剩下的 1 个盘移到 C 柱上。
- 将 n-1 个盘借助于 A 柱从 B 柱移到 C 柱上。
汉诺塔问题的递归实现
#include <stdio.h>
#include <stdlib.h>
/* 定义 hanoi 函数,将 n 个盘从第 one 柱借助第 two 柱,移到第 three 柱 */
void hanoi(int n, char one, char two, char three)
{
void move(char x, char y); /* 对 move 函数的声明 */
if (n == 1)
move(one, three);
else
{
hanoi(n - 1, one, three, two);
move(one, three);
hanoi(n - 1, two, one, three);
}
}
void move(char x, char y)
{
printf("%c-->%c\n", x, y);
}
void main()
{
void hanoi(int n, char one, char two, char three); /* 对 hanoi 函数的声明 */
int m;
printf("input the number of diskes:");
scanf("%d", &m);
printf("The step to moveing %d diskes:\n", m);
hanoi(m, 'A', 'B', 'C');
system("pause");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 变量及函数的作用域
# 局部变量与全局变量
内部变量
在一个函数内部定义的变量称为内部变量。它只在本函数范围内有效,即只有在本函数内才能使用这些变量,故也称局部变量。
关于局部变量需要注意如下几点:
- 主函数中定义的变量只在主函数中有效,而不因为在主函数中定义而在整个文件或程序中有效。主函数也不能使用其他函数中定义的变量。
- 不同函数中可以使用相同名字的变量,它们代表不同的对象,互不干扰。
- 形式参数也是局部变量。
- 在一个函数内部,可以在复合语句中定义变量,这些变量只在本复合语句中有效,这种复合语句也称 “分程序” 或 “程序块”。例下面代码块中的 int j=5 就是如此,只在离自己最近的花括 号内有效,若离开花括号,则在其下面使用该变量会造成编译不通。
外部变量
函数之外定义的变量称为外部变量。外部变量可以为本文件中的其他函数共用,它的有效范围是从定义变量的位置开始到本源文件结束,所以也称全程变量。
关于全局变量需要注意如下几点:
- 全局变量在程序的全部执行过程中都占用存储单元,而不是仅在需要时才开辟单元。
- 使用全局变量过多会降低程序的清晰性。在各个函数执行时都可能改变外部变量的值,程序容易出错,因此要有限制地使用全局变量。
- 因为函数在执行时依赖于其所在的外部变量,如果将一个函数移到另一个文件中,那么还要将有关的外部变量及其值一起移过去。然而,如果该外部变量与其他文件的变量同名,那么 就会出现问题,即会降低程序的可靠性和通用性。C 语言一般要求把程序中的函数做成一个封闭 体,除可以通过 “实参→形参” 的渠道与外界发生联系外,没有其他渠道。
func.h
#include <stdio.h>
#include <stdlib.h>
void print();
2
3
main.c
#include "func.h"
extern int k;
void print1()
{
printf("print1 k=%d\n", k);
}
int k = 10; // static 修饰全局变量,该变量不能被其他文件借用
int main()
{
int i = 10;
{
int j = 5;
}
//printf(j); //局部变量的有效范围是离自己最近的花括号
printf("i=%d,k=%d\n", i, k);
print();
print();
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
func.c
#include "func.h"
extern int k; //借用 main.c 文件中的全局变量 k
// static 修饰函数,函数只能在本函数、本文件内使用
void print()
{
static int t = 0; //只初始化一次 t++;
printf("print execute %d\n", t);
printf("print k=%d\n", k);
}
2
3
4
5
6
7
8
9
10
# 动态存储方式与静态存储方式
从变量的作用域(即从空间)角度来说,可以将变量划分为全局变量和局部变量;从变量值存在的时间角度来说,又可以将变量划分为静态变量和动态变量。
变量和函数有两个属性:数据类型和数据的存储类别。存储类别是指数据在内存中的存储方式。
存储方式分为两大类:静态存储类和动态存储类。
- 静态存储方式:指在程序运行期间由系统分配固定存储空间的方式。
- 动态存储方式:指在程序运行期间根据需要动态分配存储空间的方式。
C 语言支持 4 种变量存储类型:自动变量(auto)、静态变量(static)、寄存器变量(register)和外部变量(extern)。根据变量的存储类别,可以知道变量的作用域和生存期。
# 自动变量(auto)
函数中的局部变量如果没有专门声明为静态存储类别,那么都是动态分配存储空间的,数据存储在动态存储区中。在调用函数时,系统会给它们分配存储空间,在函数调用结束时会自动释 放这些存储空间,因此这类局部变量称为自动变量。函数中的形参和在函数中定义的变量(包括在复合语句中定义的变量)都属于此类。变量默认为 auto,即 auto 可以省略。
# 静态变量(static)
静态局部变量属于静态存储类别,在静态存储区内分配存储单元,并且在程序的整个运行期间都不释放。自动变量(即动态局部变量)属于动态存储类别,占用动态存储区的空间而不占用静态存储区的空间,函数调用结束后释放。
静态局部变量是在编译时赋初值的,且只赋初值一次,即在程序运行时它已有初值。以后每次调用函数时,不再重新赋初值,而只是保留上次函数调用结束时的值。
如局部变量与全局变量中的 static int t=0,利用它我们可以统计 print 函数被调用的次数。如果在定义局部变量时不赋初值,那 么对静态局部变量来说,编译时会自动赋初值 0(对数值型变量)或空字符(对字符变量)。而对自动变量来说,如果不赋初值,那么它的值是一个不确定的值。虽然静态局部变量在函数调用 结束后仍然存在,但其他函数不能引用它。
如果用 static 修饰全局变量,那么该全局变量将不能被其他文件引用,例如在 main.c 中的 int k; 前加入 static,将语句改为 static int k;,那么 func.c 使用 extern int k 将无法编译 通过。
如果用 static 修饰函数,那么该函数将不能被其他文件引用。
# 寄存器变量(register)
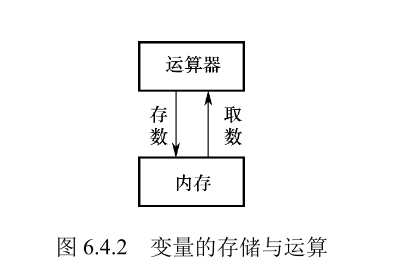
如上图所示变量的值是存储在内存中的,当程序中用到某个变量的值时,由控制器发出指令将内存中该变量的值送到运算器中并进行运算,如果需要存储数据,那么再从运算器中将 数据送到内存存储。
如果有些变量使用频繁,那么存取变量的值要花费不少时间。为提高执行效率,C 语言允许将局部变量的值放在 CPU 的寄存器中,需要用时直接从寄存器中取出参与运算,而不必再到内 存中去存取。由于寄存器的存取速度远高于内存的存取速度,因此这样做可以提高执行效率。这种变量称为寄存器变量,用关键字 register 进行声明。由于寄存器的数量是有限的,因此用 C 语言进行服务器编程时,采用 register 提升性能的非常少,但嵌入式编程可能会用到。
# 外部变量(extern)
外部变量是在函数外部定义的全局变量,它的作用域是从变量的定义处开始,到本程序文件的末尾。在此作用域内,全局变量可以为程序中的各个函数引用。编译时将外部变量分配到静态存储区,用 extern 来声明外部变量,以扩展外部变量的作用域。
例如,在局部变量与全局变量的 func.c 中,我们通过 extern int k; 借用 main.c 的全局变量 k,从而可以获取值并进行打印。当然,也可以对其进行修改。所有函数默认都是 extern 类型的,因此任何一个文件的函数都可以被其他文件调用。
# 函数调用原理详解
每个函数使用的栈空间称为函数帧,也称栈帧。掌握函数在相互调用过程中栈帧的变化(前面在关于指针的章节中我们初步解析了函数调用),对于理解 C 语言中函数的调用原理是非常重要的。
# 关于栈
首先必须明确的一点是,栈是向下生长的。所谓向下生长,是指从内存高地址向低地址的路径延伸。于是,栈就有栈底和栈顶,栈顶的地址要比栈底的低。
对 x86 体系的 CPU 而言,寄存器 ebp 可称为帧指针或基址指针(base pointer),寄存器 esp 可称为栈指针(stack pointer)。
这里需要说明的几点如下。
ebp 在未改变之前始终指向栈帧的开始(也就是栈底),所以 ebp 的用途是在堆栈中寻址(寻址的作用会在下面详细介绍)。
esp 会随着数据的入栈和出栈而移动,即 esp 始终指向栈顶。
如图下图所示,假设函数 A 调用函数 B,称函数 A 为调用者,称函数 B 为被调用者,则函数调用过程可以描述如下:
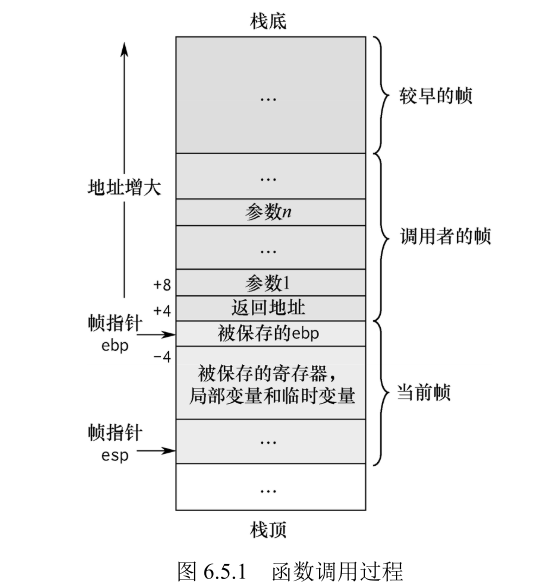
- 首先将调用者(A)的堆栈的基址(ebp)入栈,以保存之前任务的信息。
- 然后将调用者(A)的栈顶指针(esp)的值赋给 ebp,作为新的基址(即被调用者 B 的栈底)。
- 再后在这个基址(被调用者 B 的栈底)上开辟(一般用 sub 指令)相应的空间用作被调用者 B 的栈空间。
- 函数 B 返回后,当前栈帧的 ebp 恢复为调用者 A 的栈顶(esp),使栈顶恢复函数 B 被调用前的位置;然后调用者 A 从恢复后的栈顶弹出之前的 ebp 值(因为这个值在函数调用前一步被 压入堆栈)。
这样,ebp 和 esp 就都恢复了调用函数 B 前的位置,即栈恢复函数 B 调用前的状态。相当于
mov %ebp , %esp //把 ebp 内的内容复制到 esp 寄存器中
pop %ebp //弹出栈顶元素,放到 ebp 寄存器中
2
下面通过一个交换变量函数来分析具体过程
void swap(int *a, int *b)
{
int c;
c = *a;
*a = *b;
*b = c;
}
int main(void)
{
int a, b, ret;
a = 16;
b = 64;
ret = 0;
swap(&a, &b);
ret = a - b;
return ret;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
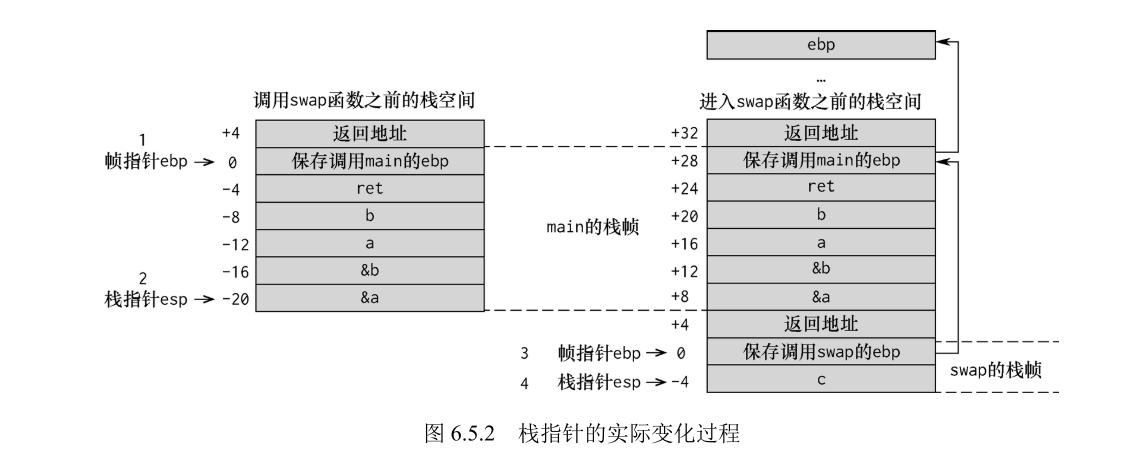
首先需要知道可执行程序并不是自动进入内存的,而是其他程序调用的,因此 main 函数虽然是入口函数,但是依然由其他函数调用,所以图 6.5.2 的左边部分是未调用 swap 函数时栈空间 的情况,这时帧指针 ebp 保存的是调用 main 的 ebp。有的读者可能不理解这是怎么回事,不过 不用担心,其原理与 main 调用 swap 的原理是相同的。接着当 main 函数调用 swap 函数时,我们 首先 push % ebp,即把 main 函数的帧指针 ebp(图 6.5.2 中标为 1 的位置)压栈,这时将 main 函 数的栈指针 esp(图 6.5.2 中标为 2 的位置)作为新函数 swap 的帧指针 ebp(图 6.5.2 中标为 3 的 位置),也就是 main 函数的栈顶指针作为新函数 swap 的基指针(也称帧指针),新函数 swap 的 栈顶指针 esp 会随着定义变量的数量依次增加(图 6.5.2 中标为 4 的位置)。