 Java 集合
Java 集合
# Java 集合
# 集合有哪些类
tag:
哈啰、软通、税友、快手、用友、大象慧云、途虎、苏小研、4399、招行、神州出行、亚信、小米count:32
as:Java 中有哪些数据结构?
了解集合吗?说一下 map 和 list 下面的集合
Java 中常用的集合及其具体实现
java 中的集合类的继承体系 从不同的方面分类说各种特点
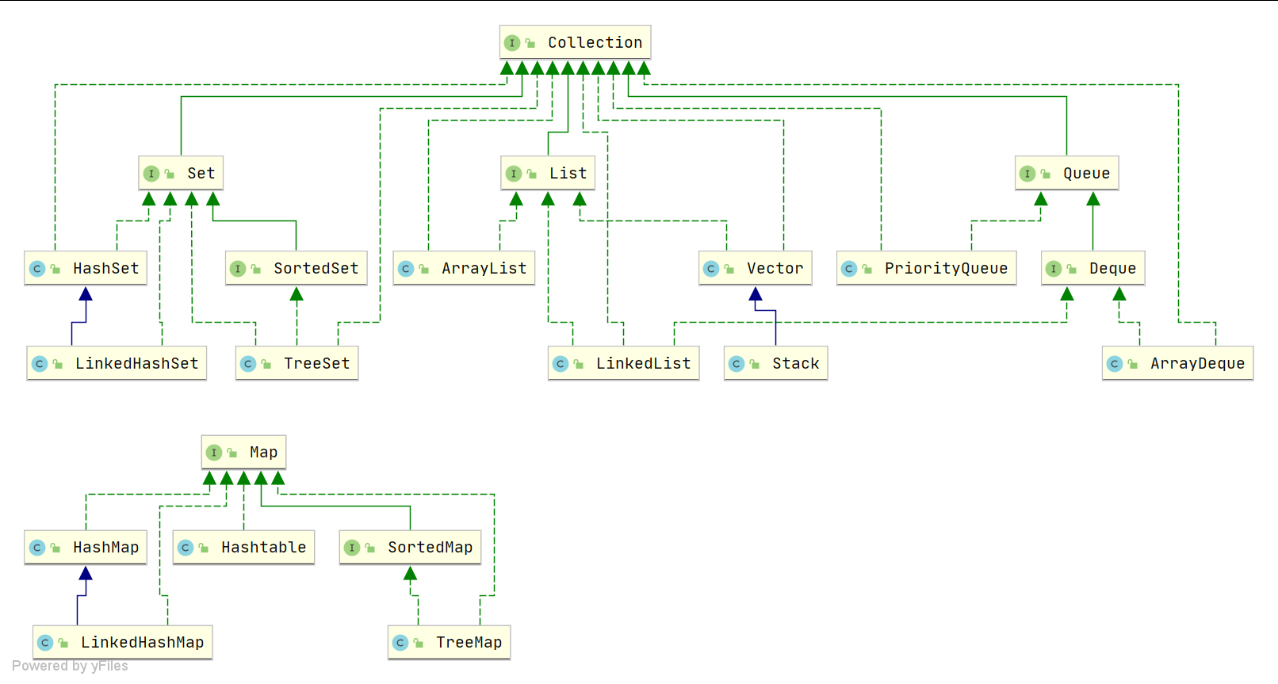
Set
TreeSet 基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O (1),TreeSet 则为 O (logN)。
HashSet 基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
LinkedHashSet 具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
List
ArrayList 基于动态数组实现,支持随机访问。
Vector 和 ArrayList 类似,但 Vector 它是线程安全的。
LinkedList 基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
Queue
LinkedList 可以用它来实现双向队列。
PriorityQueue 基于堆结构实现,可以用它来实现优先队列。
ArrayDeque 可扩容动态双向数组。
Map
HashMap:基于哈希表实现,提供快速查找、添加和删除操作。LinkedHashMap:保持插入顺序的HashMap。TreeMap:基于红黑树实现,按键的自然顺序或自定义排序。Hashtable:类似于HashMap,但线程安全(已过时,推荐使用ConcurrentHashMap和显式同步)。
# ArrayList
tag:
Meta App、数字马力、同余、得物、小米、快手、字节、贝壳、深信服、卓望、竞技世界、大智慧、大华、招行、淘天、哔哩哔哩、阿里、用友、饿了么、百度、大象慧云、一嗨租车、货拉拉、浩鲸、咪咕、理想count:51
as:ArrayList 的实现
arrayList 的扩容机制
扩容?为什么是 1.5 倍?
分别适用于场景?
如果容量为 1,addAll 一个容量为 100000 的数组,怎么扩容?
Array 和 ArrayList 的区别
用 java 实现 arraylist

List : 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。
RandomAccess :这是一个标志接口,表明实现这个接口的 List 集合是支持 快速随机访问 的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
Cloneable :表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。
Serializable : 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
- 底层:ArrayList 实现了 List 接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入
null元素,底层通过数组实现。 - 自动扩容:
- 数组扩容通过
ensureCapacity(int minCapacity)方法来实现 - 也可以使用 ensureCapacity 来手动增加 ArrayList 实例的容量
- 数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的 1.5 倍
- 数组扩容通过
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右
# 源码分析
以 JDK1.8 为例,分析一下 ArrayList 的底层源码。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 空数组(用于空实例)。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
//用于默认大小空实例的共享空数组实例。
//我们把它从EMPTY_ELEMENTDATA数组中区分出来,以知道在添加第一个元素时容量需要增加多少。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 保存ArrayList数据的数组
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 所包含的元素个数
*/
private int size;
/**
* 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//如果传入的参数大于0,创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果传入的参数等于0,创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
//其他情况,抛出异常
throw new IllegalArgumentException("Illegal Capacity: " +
initialCapacity);
}
}
/**
* 默认无参构造函数
* DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection<? extends E> c) {
//将指定集合转换为数组
elementData = c.toArray();
//如果elementData数组的长度不为0
if ((size = elementData.length) != 0) {
// 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
if (elementData.getClass() != Object[].class)
//将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 其他情况,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
* 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
//下面是ArrayList的扩容机制
//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
/**
* 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
*
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
//如果是true,minExpand的值为0,如果是false,minExpand的值为10
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
//如果最小容量大于已有的最大容量
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
// 根据给定的最小容量和当前数组元素来计算所需容量。
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 如果当前数组元素为空数组(初始情况),返回默认容量和最小容量中的较大值作为所需容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 否则直接返回最小容量
return minCapacity;
}
// 确保内部容量达到指定的最小容量。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//比较minCapacity和 MAX_ARRAY_SIZE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
* 返回此列表中的元素数。
*/
public int size() {
return size;
}
/**
* 如果此列表不包含元素,则返回 true 。
*/
public boolean isEmpty() {
//注意=和==的区别
return size == 0;
}
/**
* 如果此列表包含指定的元素,则返回true 。
*/
public boolean contains(Object o) {
//indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
return indexOf(o) >= 0;
}
/**
* 返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i] == null)
return i;
} else {
for (int i = 0; i < size; i++)
//equals()方法比较
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。.
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size - 1; i >= 0; i--)
if (elementData[i] == null)
return i;
} else {
for (int i = size - 1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
//Arrays.copyOf功能是实现数组的复制,返回复制后的数组。参数是被复制的数组和复制的长度
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// 这不应该发生,因为我们是可以克隆的
throw new InternalError(e);
}
}
/**
* 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
* 返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
* 因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
*/
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
/**
* 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
* 返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
* 否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
* 如果列表适用于指定的数组,其余空间(即数组的列表数量多于此元素),则紧跟在集合结束后的数组中的元素设置为null 。
* (这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// 新建一个运行时类型的数组,但是ArrayList数组的内容
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
//调用System提供的arraycopy()方法实现数组之间的复制
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* 返回此列表中指定位置的元素。
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
/**
* 用指定的元素替换此列表中指定位置的元素。
*/
public E set(int index, E element) {
//对index进行界限检查
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
//返回原来在这个位置的元素
return oldValue;
}
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
//这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
/**
* 在此列表中的指定位置插入指定的元素。
* 先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
* 再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()这个实现数组之间复制的方法一定要看一下,下面就用到了arraycopy()方法实现数组自己复制自己
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
/**
* 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
//从列表中删除的元素
return oldValue;
}
/**
* 从列表中删除指定元素的第一个出现(如果存在)。 如果列表不包含该元素,则它不会更改。
* 返回true,如果此列表包含指定的元素
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
/**
* 从列表中删除所有元素。
*/
public void clear() {
modCount++;
// 把数组中所有的元素的值设为null
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
/**
* 按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
/**
* 将指定集合中的所有元素插入到此列表中,从指定的位置开始。
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
/**
* 从此列表中删除所有索引为fromIndex (含)和toIndex之间的元素。
* 将任何后续元素移动到左侧(减少其索引)。
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex - fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 检查给定的索引是否在范围内。
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* add和addAll使用的rangeCheck的一个版本
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 返回IndexOutOfBoundsException细节信息
*/
private String outOfBoundsMsg(int index) {
return "Index: " + index + ", Size: " + size;
}
/**
* 从此列表中删除指定集合中包含的所有元素。
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
//如果此列表被修改则返回true
return batchRemove(c, false);
}
/**
* 仅保留此列表中包含在指定集合中的元素。
* 换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
/**
* 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
* 指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
* 返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: " + index);
return new ListItr(index);
}
/**
* 返回列表中的列表迭代器(按适当的顺序)。
* 返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator() {
return new ListItr(0);
}
/**
* 以正确的顺序返回该列表中的元素的迭代器。
* 返回的迭代器是fail-fast 。
*/
public Iterator<E> iterator() {
return new Itr();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
补充:JDK6 new 无参构造的
ArrayList对象时,直接创建了长度是 10 的Object[]数组elementData。
add 方法
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
// 加元素之前,先调用ensureCapacityInternal方法
ensureCapacityInternal(size + 1); // Increments modCount!!
// 这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
2
3
4
5
6
7
8
9
10
注意:JDK11 移除了 ensureCapacityInternal() 和 ensureExplicitCapacity() 方法
ensureCapacityInternal 方法的源码如下:
// 根据给定的最小容量和当前数组元素来计算所需容量。
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 如果当前数组元素为空数组(初始情况),返回默认容量和最小容量中的较大值作为所需容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 否则直接返回最小容量
return minCapacity;
}
// 确保内部容量达到指定的最小容量。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
ensureCapacityInternal 方法非常简单,内部直接调用了 ensureExplicitCapacity 方法:
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//判断当前数组容量是否足以存储minCapacity个元素
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容
grow(minCapacity);
}
2
3
4
5
6
7
8
# 可以添加 null 吗
tag:
Meta Appcount:1
as:
ArrayList 中可以存储任何类型的对象,包括 null 值。不过,不建议向 ArrayList 中添加 null 值, null 值无意义,会让代码难以维护比如忘记做判空处理就会导致空指针异常。
ArrayList<String> listOfStrings = new ArrayList<>();
listOfStrings.add(null);
listOfStrings.add("java");
System.out.println(listOfStrings);
2
3
4
[null, java]
# list 去重应该怎么去重
tag:
美的count:1
as:arraylist 去重应该怎么去重,有哪些可以的方法
《阿里巴巴 Java 开发手册》的描述如下:
可以利用
Set元素唯一的特性,可以快速对一个集合进行去重操作,避免使用List的contains()进行遍历去重或者判断包含操作。
这里我们以 HashSet 和 ArrayList 为例说明。
// Set 去重代码示例
public static <T> Set<T> removeDuplicateBySet(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new HashSet<>();
}
return new HashSet<>(data);
}
// List 去重代码示例
public static <T> List<T> removeDuplicateByList(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new ArrayList<>();
}
List<T> result = new ArrayList<>(data.size());
for (T current : data) {
if (!result.contains(current)) {
result.add(current);
}
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
两者的核心差别在于 contains() 方法的实现。
HashSet 的 contains() 方法底部依赖的 HashMap 的 containsKey() 方法,时间复杂度接近于 O(1)(没有出现哈希冲突的时候为 O(1))。
private transient HashMap<E,Object> map;
public boolean contains(Object o) {
return map.containsKey(o);
}
2
3
4
我们有 N 个元素插入进 Set 中,那时间复杂度就接近是 O (n)。
ArrayList 的 contains() 方法是通过遍历所有元素的方法来做的,时间复杂度接近是 O (n)。
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# List 集合中有什么线程安全的集合,以及如何实现线程安全的?
tag:
快手count:3
as:多线程下会发生什么问题?在扩容的时候多线程下会发生什么问题?
# 遍历集合
tag:
同余count:1
as:循环集合的遍历用什么方法,forEach 循环时进行 remove 或者 add,为什么报错,有什么解决办法
《阿里巴巴 Java 开发手册》的描述如下:
不要在 foreach 循环里进行元素的
remove/add操作。remove 元素请使用Iterator方式,如果并发操作,需要对Iterator对象加锁。
通过反编译你会发现 foreach 语法底层其实还是依赖 Iterator 。不过, remove/add 操作直接调用的是集合自己的方法,而不是 Iterator 的 remove/add 方法
这就导致 Iterator 莫名其妙地发现自己有元素被 remove/add ,然后,它就会抛出一个 ConcurrentModificationException 来提示用户发生了并发修改异常。这就是单线程状态下产生的 fail-fast 机制。
fail-fast 机制:多个线程对 fail-fast 集合进行修改的时候,可能会抛出
ConcurrentModificationException。 即使是单线程下也有可能会出现这种情况,上面已经提到过。
Java8 开始,可以使用 Collection#removeIf() 方法删除满足特定条件的元素,如
List<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; ++i) {
list.add(i);
}
list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
System.out.println(list); /* [1, 3, 5, 7, 9] */
2
3
4
5
6
除了上面介绍的直接使用 Iterator 进行遍历操作之外,你还可以:
- 使用普通的 for 循环
- 使用 fail-safe 的集合类。
java.util包下面的所有的集合类都是 fail-fast 的,而java.util.concurrent包下面的所有的类都是 fail-safe 的。 - ……
# String 转 list,list 转 String 的方法?
tag:
count:1
as:
# 自定义排序
tag:
用友count:1
as:自定义排序怎么实现
Comparable 接口和 Comparator 接口都是 Java 中用于排序的接口,它们在实现类对象之间比较大小、排序等方面发挥了重要作用:
Comparable接口实际上是出自java.lang包 它有一个compareTo(Object obj)方法用来排序Comparator接口实际上是出自java.util包它有一个compare(Object obj1, Object obj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写 compareTo() 方法或 compare() 方法,当我们需要对某一个集合实现两种排序方式,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写 compareTo() 方法和使用自制的 Comparator 方法或者以两个 Comparator 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 Collections.sort() .
Comparator 定制排序
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
System.out.println("原始数组:");
System.out.println(arrayList);
// void reverse(List list):反转
Collections.reverse(arrayList);
System.out.println("Collections.reverse(arrayList):");
System.out.println(arrayList);
// void sort(List list),按自然排序的升序排序
Collections.sort(arrayList);
System.out.println("Collections.sort(arrayList):");
System.out.println(arrayList);
// 定制排序的用法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
System.out.println("定制排序后:");
System.out.println(arrayList);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
原始数组:
[-1, 3, 3, -5, 7, 4, -9, -7]
Collections.reverse(arrayList):
[-7, -9, 4, 7, -5, 3, 3, -1]
Collections.sort(arrayList):
[-9, -7, -5, -1, 3, 3, 4, 7]
定制排序后:
[7, 4, 3, 3, -1, -5, -7, -9]
2
3
4
5
6
7
8
重写 compareTo 方法实现按年龄来排序
// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列
// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他
// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* T重写compareTo方法实现按年龄来排序
*/
@Override
public int compareTo(Person o) {
if (this.age > o.getAge()) {
return 1;
}
if (this.age < o.getAge()) {
return -1;
}
return 0;
}
}
public static void main(String[] args) {
TreeMap<Person, String> pdata = new TreeMap<Person, String>();
pdata.put(new Person("张三", 30), "zhangsan");
pdata.put(new Person("李四", 20), "lisi");
pdata.put(new Person("王五", 10), "wangwu");
pdata.put(new Person("小红", 5), "xiaohong");
// 得到key的值的同时得到key所对应的值
Set<Person> keys = pdata.keySet();
for (Person key : keys) {
System.out.println(key.getAge() + "-" + key.getName());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
5-小红
10-王五
20-李四
30-张三
2
3
4
# LinkedList
tag:
同余、数字马力、得物、快手、字节、贝壳、卓望、竞技世界、大华、招行、淘天、快手、阿里、饿了么、大象慧云、货拉拉、浩鲸、咪咕、携程count:35
as:arrayList 和 LinkedList 区别,内存占用情况,新增时间复杂度
LinkedList 有容量限制吗
分别适用于场景?
linkedlist 特点
LinkedList 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O (1),其他情况增删元素的平均时间复杂度都是 O (n) 。
- 头部插入 / 删除:只需要修改头结点的指针即可完成插入 / 删除操作,因此时间复杂度为 O (1)。
- 尾部插入 / 删除:只需要修改尾结点的指针即可完成插入 / 删除操作,因此时间复杂度为 O (1)。
- 指定位置插入 / 删除:需要先移动到指定位置,再修改指定节点的指针完成插入 / 删除,因此需要移动平均 n/2 个元素,时间复杂度为 O (n)。
# Vector
tag:
贝壳、深信服、大华、京东count:5
as:ArrayList 线程安全版本的容器
concurrenthashmap 等以 cas+syn 混合的方式,和以 vector 等以全局 syn 的区别
# CopyOnWriteArrayList
tag:
贝壳、大华、招行、快手count:6
as:ArrayList 线程安全版本的容器
在 JDK1.5 之前,如果想要使用并发安全的 List 只能选择 Vector 。而 Vector 是一种老旧的集合,已经被淘汰。 Vector 对于增删改查等方法基本都加了 synchronized ,这种方式虽然能够保证同步,但这相当于对整个 Vector 加上了一把大锁,使得每个方法执行的时候都要去获得锁,导致性能非常低下。
JDK1.5 引入了 Java.util.concurrent (JUC)包,其中提供了很多线程安全且并发性能良好的容器,其中唯一的线程安全 List 实现就是 CopyOnWriteArrayList 。
CopyOnWriteArrayList 中的读取操作是完全无需加锁的。写入操作也不会阻塞读取操作,只有写写才会互斥。这样一来,读操作的性能就可以大幅度提升。
CopyOnWriteArrayList 线程安全的核心在于其采用了 写时复制(Copy-On-Write) 的策略,从 CopyOnWriteArrayList 的名字就能看出了。
当需要修改( add , set 、 remove 等操作) CopyOnWriteArrayList 的内容时,不会直接修改原数组,而是会先创建底层数组的副本,对副本数组进行修改,修改完之后再将修改后的数组赋值回去,这样就可以保证写操作不会影响读操作了。
可以看出,写时复制机制非常适合读多写少的并发场景,能够极大地提高系统的并发性能。
不过,写时复制机制并不是优点,其依然存在一些缺点,下面列举几点:
- 内存占用:每次写操作都需要复制一份原始数据,会占用额外的内存空间,在数据量比较大的情况下,可能会导致内存资源不足。
- 写操作开销:每一次写操作都需要复制一份原始数据,然后再进行修改和替换,所以写操作的开销相对较大,在写入比较频繁的场景下,性能可能会受到影响。
- 数据一致性问题:修改操作不会立即反映到最终结果中,还需要等待复制完成,这可能会导致一定的数据一致性问题。
- …
# HashMap
tag:
小米、万得、用友、阿里、软通、数字马力、同余、快手、税友、字节、贝壳、得物、淘天、快手、用友、百度、一嗨租车、浩鲸、腾讯、京东、途牛、咪咕、金山、超聚变、富途、北森、邦盛、boss、神策数据、小红书、美团、苏小研、4399、招行、饿了么、神州出行、作业帮、亚信、tp-linktp-link、平安count:115
as:Hash map 的底层原理,转换和扩容机制
HashMap1.7 和 1.8 的区别
hashmap1.8 以前链表采用头插,1.8 以后是什么?为什么?
Hash 因子和 Hash 冲突
为什么会产生哈希冲突,哈希值和输入数值为什么不能 1:1,常见的哈希函数
为什么用红黑树,红黑树的调整,相比平衡二叉树为什么实际应用优秀
hashmap 扩容时如何进行挪移的?
get 方法,如果发生 Hash 冲突,怎么找到想要的 key,用什么方法比较的
负载因子为什么是 0.75?
为什么需要重写 hashcode
什么时候会出现重复
如果一定要用 hashmap,怎么让它线程安全(collections)
hashMap 在 1.7 和 1.8 计算 hashcode 上有什么区别
hashmap put() 的 key 是 null 的情况
hashmap 遍历并打印有哪些方式 HashMap 的 Key 或者 value 可以为 null 值吗? 自定义类做 HashMap 的 key 可以吗
为什么不用头插法,用了尾插法就线程安全了吗
hashmap 循环问题
为什么数组是采取 2 的幂次方?
他是怎么解决哈新冲突的?什么情况会退化为链表?
哈希表有两种实现方式,一种开放地址方式 (Open addressing),另一种是冲突链表方式 (Separate chaining with linked lists)。
- Java7 HashMap 采用的是冲突链表方式
- 底层为哈希表,由数组 + 链表实现
- 创建一个默认长度 16, 默认加载因 0.75 的数组
- 加载因:当数组存了 16*0.75=12 个元素时,数组会扩容为原先的两倍。
- 并且,
HashMap总是使用 2 的幂作为哈希表的大小。
- 在 JDK8 中,当 HashMap 中链表的元素达到了 8 个时,会将链表转换为红黑树。如果当前数组(当前 HashMap 大小)的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。
# JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。
HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^:按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2
3
4
5
6
7
JDK1.7 的 HashMap 的 hash 方法源码
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
2
3
4
5
6
7
8
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
# JDK1.8 之后
JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
putVal 方法中执行链表转红黑树的判断逻辑。
链表的长度大于 8 的时候,就执行 treeifyBin (转换红黑树)的逻辑。
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 遍历到链表最后一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表元素个数大于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 红黑树转换(并不会直接转换成红黑树)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
treeifyBin 方法中判断是否真的转换为红黑树。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 判断当前数组的长度是否小于 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 如果当前数组的长度小于 64,那么会选择先进行数组扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 否则才将列表转换为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树。
# 长度为什么是 2 的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值 - 2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。
这个算法应该如何设计呢?
我们首先可能会想到采用 % 取余的操作来实现。但是,重点来了:“取余 (%) 操作中如果除数是 2 的幂次则等价于与其除数减一的与 (&) 操作(也就是说 hash% length==hash&(length-1) 的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 & 相对于 % 能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
# HashMap 的扩容机制
tag:
哈啰count:1
as:HashMap 的扩容机制?为什么要把阈值设置为 0.75?为什么 HashMap 的初始容量要设置为 16?
loadFactor 负载因子
loadFactor 负载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据 (entry) 也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据 (entry) 也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量超过了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
# hashmap 是如何通过 key 快速 getput value 的
tag:
携程count:1
# 为什么不用头插法,用了尾插法就线程安全了吗
JDK1.7 及之前版本的 HashMap 在多线程环境下扩容操作可能存在死循环问题,这是由于当一个桶位中有多个元素需要进行扩容时,多个线程同时对链表进行操作,头插法可能会导致链表中的节点指向错误的位置,从而形成一个环形链表,进而使得查询元素的操作陷入死循环无法结束。
为了解决这个问题,JDK1.8 版本的 HashMap 采用了尾插法而不是头插法来避免链表倒置,使得插入的节点永远都是放在链表的末尾,避免了链表中的环形结构。但是还是不建议在多线程下使用 HashMap ,因为多线程下使用 HashMap 还是会存在数据覆盖的问题。并发环境下,推荐使用 ConcurrentHashMap 。
# hashmap 的线程不安全场景?
tag:
美团、小米、得物、字节、淘天、百度、超聚变、北森、boss、快手、小红书、满帮、数字马力count:25
hashmap 多线程为什么不安全?
HashMap 怎么实现线程安全
HashMap 在多线程场景下使用,jdk7/8 有都什么问题?问题有什么区别?
HashMap 在多线程情况下会产生哪些问题?会产生死锁吗?
JDK1.7 及之前版本,在多线程环境下, HashMap 扩容时会造成死循环和数据丢失的问题。
数据丢失这个在 JDK1.7 和 JDK 1.8 中都存在,这里以 JDK 1.8 为例进行介绍。
JDK 1.8 后,在 HashMap 中,多个键值对可能会被分配到同一个桶(bucket),并以链表或红黑树的形式存储。多个线程对 HashMap 的 put 操作会导致线程不安全,具体来说会有数据覆盖的风险。
举个例子:
- 两个线程 1,2 同时进行 put 操作,并且发生了哈希冲突(hash 函数计算出的插入下标是相同的)。
- 不同的线程可能在不同的时间片获得 CPU 执行的机会,当前线程 1 执行完哈希冲突判断后,由于时间片耗尽挂起。线程 2 先完成了插入操作。
- 随后,线程 1 获得时间片,由于之前已经进行过 hash 碰撞的判断,所有此时会直接进行插入,这就导致线程 2 插入的数据被线程 1 覆盖了。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// ...
// 判断是否出现 hash 碰撞
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素(处理hash冲突)
else {
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
还有一种情况是这两个线程同时 put 操作导致 size 的值不正确,进而导致数据覆盖的问题:
- 线程 1 执行
if(++size > threshold)判断时,假设获得size的值为 10,由于时间片耗尽挂起。 - 线程 2 也执行
if(++size > threshold)判断,获得size的值也为 10,并将元素插入到该桶位中,并将size的值更新为 11。 - 随后,线程 1 获得时间片,它也将元素放入桶位中,并将 size 的值更新为 11。
- 线程 1、2 都执行了一次
put操作,但是size的值只增加了 1,也就导致实际上只有一个元素被添加到了HashMap中。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// ...
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# HashTable
tag:
万得、用友、得物、快手、税友、淘天、百度、小米、金山、阿里count:22
as:对 HashMap 的理解,怎么解决线程不安全的问题
hashtable 和 hashmap 区别
hashTable 是线程安全的吗?和 concurrentHashMap 有什么区别?为什么有两个?
HashTable 线程安全是怎么实现的?
# HashMap 和 Hashtable 的区别
- 线程是否安全:
HashMap是非线程安全的,Hashtable是线程安全的,因为Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!); - 效率: 因为线程安全的问题,
HashMap要比Hashtable效率高一点。另外,Hashtable基本被淘汰,不要在代码中使用它; - 对 Null key 和 Null value 的支持:
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出NullPointerException。 - 初始容量大小和每次扩充容量大小的不同:
- 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。 - 创建时如果给定了容量初始值,那么
Hashtable会直接使用你给定的大小,而HashMap会将其扩充为 2 的幂次方大小(HashMap中的tableSizeFor()方法保证)。也就是说HashMap总是使用 2 的幂作为哈希表的大小,为什么是 2 的幂次方。
- 创建时如果不指定容量初始值,
- 底层数据结构: JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间。Hashtable没有这样的机制。 - 哈希函数的实现:
HashMap对哈希值进行了高位和低位的混合扰动处理以减少冲突,而Hashtable直接使用键的hashCode()值。
# ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的
ConcurrentHashMap底层采用 分段的数组 + 链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组 + 链表 / 红黑二叉树。Hashtable和 JDK1.8 之前的HashMap的底层数据结构类似都是采用 数组 + 链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的; - 实现线程安全的方式:
- 在 JDK1.7 的时候,
ConcurrentHashMap对整个桶数组进行了分割分段 (Segment,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 - 到了 JDK1.8 的时候,
ConcurrentHashMap已经摒弃了Segment的概念,而是直接用Node数组 + 链表 + 红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本; Hashtable(同一把锁) : 使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
- 在 JDK1.7 的时候,
下面,我们再来看看两者底层数据结构的对比图。
JDK1.7 的 ConcurrentHashMap:
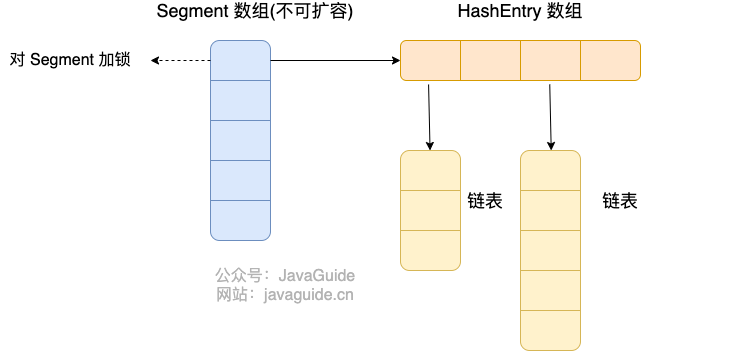
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 数组中的每个元素包含一个 HashEntry 数组,每个 HashEntry 数组属于链表结构。
JDK1.8 的 ConcurrentHashMap:
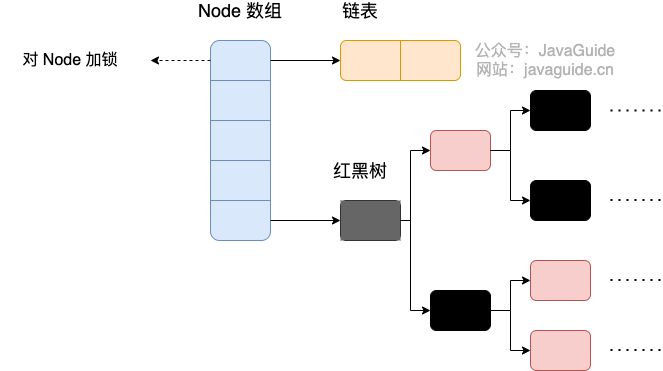
JDK1.8 的 ConcurrentHashMap 不再是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。
TreeNode 是存储红黑树节点,被 TreeBin 包装。 TreeBin 通过 root 属性维护红黑树的根结点,因为红黑树在旋转的时候,根结点可能会被它原来的子节点替换掉,在这个时间点,如果有其他线程要写这棵红黑树就会发生线程不安全问题,所以在 ConcurrentHashMap 中 TreeBin 通过 waiter 属性维护当前使用这棵红黑树的线程,来防止其他线程的进入。
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
...
}
2
3
4
5
6
7
8
9
10
11
# TreeMap
tag:
快手、金山、万得count:5
as:treemap 和 hashmap 区别
TreeMap 怎么保证是有序的?
# HashMap 和 TreeMap 区别
TreeMap 和 HashMap 都继承自 AbstractMap ,但是需要注意的是 TreeMap 它还实现了 NavigableMap 接口和 SortedMap 接口。
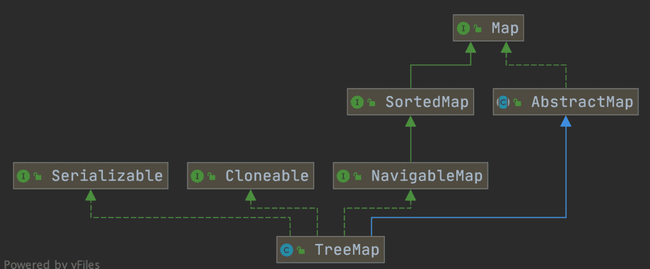
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
NavigableMap 接口提供了丰富的方法来探索和操作键值对:
- 定向搜索:
ceilingEntry(),floorEntry(),higherEntry()和lowerEntry()等方法可以用于定位大于、小于、大于等于、小于等于给定键的最接近的键值对。 - 子集操作:
subMap(),headMap()和tailMap()方法可以高效地创建原集合的子集视图,而无需复制整个集合。 - 逆序视图:
descendingMap()方法返回一个逆序的NavigableMap视图,使得可以反向迭代整个TreeMap。 - 边界操作:
firstEntry(),lastEntry(),pollFirstEntry()和pollLastEntry()等方法可以方便地访问和移除元素。
这些方法都是基于红黑树数据结构的属性实现的,红黑树保持平衡状态,从而保证了搜索操作的时间复杂度为 O (log n),这让 TreeMap 成为了处理有序集合搜索问题的强大工具。
综上,相比于 HashMap 来说, TreeMap 主要多了对集合中的元素根据键排序的能力以及对集合内元素的搜索的能力。
实现 SortedMap 接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。示例代码如下:
/**
* @author shuang.kou
* @createTime 2020年06月15日 17:02:00
*/
public class Person {
private Integer age;
public Person(Integer age) {
this.age = age;
}
public Integer getAge() {
return age;
}
public static void main(String[] args) {
TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person person1, Person person2) {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
}
});
treeMap.put(new Person(3), "person1");
treeMap.put(new Person(18), "person2");
treeMap.put(new Person(35), "person3");
treeMap.put(new Person(16), "person4");
treeMap.entrySet().stream().forEach(personStringEntry -> {
System.out.println(personStringEntry.getValue());
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
person1
person4
person2
person3
2
3
4
# WeakHashMap
Java 中内存是通过 GC 自动管理的,GC 会在程序运行过程中自动判断哪些对象是可以被回收的,并在合适的时机进行内存释放。 GC 判断某个对象是否可被回收的依据是,是否有有效的引用指向该对象。如果没有有效引用指向该对象 (基本意味着不存在访问该对象的方式),那么该对象就是可回收的。 这里的有效引用 并不包括弱引用。也就是说,虽然弱引用可以用来访问对象,但进行垃圾回收时弱引用并不会被考虑在内,仅有弱引用指向的对象仍然会被 GC 回收。
WeakHashMap 内部是通过弱引用来管理 entry 的,弱引用的特性对应到 WeakHashMap 上意味着什么呢?
WeakHashMap 里的 entry 可能会被 GC 自动删除,即使程序员没有调用 remove() 或者 clear() 方法。
WeakHashMap 的这个特点特别适用于需要缓存的场景。在缓存场景下,由于内存是有限的,不能缓存所有对象;对象缓存命中可以提高系统效率,但缓存 MISS 也不会造成错误,因为可以通过计算重新得到。
# ConcurrentHashMap
tag:
携程、快手、税友、字节、得物、理想、贝壳、淘天、阿里、百度、京东、人人网、小米、腾讯、途虎、boss、飞猪、小红书、满帮、美团、用友、美团、货拉拉、阿里、万得count:56
as:ashtable 能被 concurrenthashmap 完全取代吗
put 原理
说一下 ConcurrentHashMap 是如何实现的线程安全的?
除了 ConcurrentHashMap,还可以如何将 HashMap 变为线程安全的
ConcurrentHashMap 1.8 后怎么保证线程安全,key 可不可以为 null
ConcurrentHashMap 原理 jdk1.7 和 1.8,实现并发的原理
concurrenthashmap 等以 cas+syn 混合的方式,和以 vector 等以全局 syn 的区别
ConcurrentHashmap 锁是用的 reentrantlock 还是 synchronized
如果一个 ConcurrentHashMap 在被多个线程操作,在进行扩容操作时会有几个线程在处理
具体怎么实现的呢,用到什么方式实现更加细粒度的锁? 1.8 之前、之后。
ConcurrentHashMap 线程安全的具体实现方式 / 底层具体实现
JDK1.8 之前
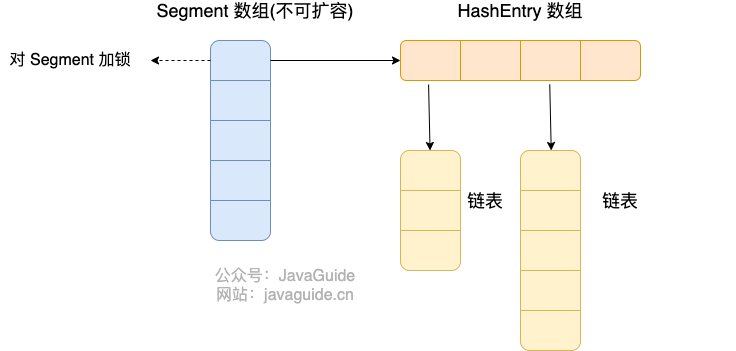
首先将数据分为一段一段(这个 “段” 就是 Segment )的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock , 所以 Segment 是一种可重入锁,扮演锁的角色。 HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
2
一个 ConcurrentHashMap 里包含一个 Segment 数组, Segment 的个数一旦初始化就不能改变。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的。
JDK1.8 之后
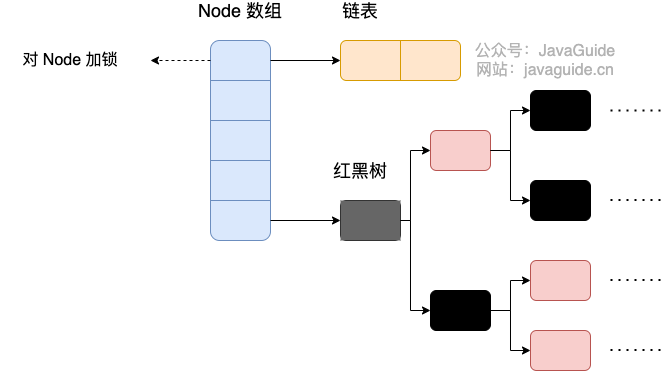 Java8 ConcurrentHashMap 存储结构
Java8 ConcurrentHashMap 存储结构
Java 8 几乎完全重写了 ConcurrentHashMap ,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行。
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组 + 链表 / 红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O (N))转换为红黑树(寻址时间复杂度为 O (log (N)))。
Java 8 中,锁粒度更细, synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
# JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
- 线程安全实现方式:JDK 1.7 采用
Segment分段锁来保证安全,Segment是继承自ReentrantLock。JDK1.8 放弃了Segment分段锁的设计,采用Node + CAS + synchronized保证线程安全,锁粒度更细,synchronized只锁定当前链表或红黑二叉树的首节点。 - Hash 碰撞解决方法 : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
- 并发度:JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
# ConcurrentHashMap 为什么 key 和 value 不能为 null?
ConcurrentHashMap 的 key 和 value 不能为 null 主要是为了避免二义性。null 是一个特殊的值,表示没有对象或没有引用。如果你用 null 作为键,那么你就无法区分这个键是否存在于 ConcurrentHashMap 中,还是根本没有这个键。同样,如果你用 null 作为值,那么你就无法区分这个值是否是真正存储在 ConcurrentHashMap 中的,还是因为找不到对应的键而返回的。
拿 get 方法取值来说,返回的结果为 null 存在两种情况:
- 值没有在集合中 ;
- 值本身就是 null。
这也就是二义性的由来。
多线程环境下,存在一个线程操作该 ConcurrentHashMap 时,其他的线程将该 ConcurrentHashMap 修改的情况,所以无法通过 containsKey(key) 来判断否存在这个键值对,也就没办法解决二义性问题了。
与此形成对比的是, HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。如果传入 null 作为参数,就会返回 hash 值为 0 的位置的值。单线程环境下,不存在一个线程操作该 HashMap 时,其他的线程将该 HashMap 修改的情况,所以可以通过 contains(key) 来做判断是否存在这个键值对,从而做相应的处理,也就不存在二义性问题。
也就是说,多线程下无法正确判定键值对是否存在(存在其他线程修改的情况),单线程是可以的(不存在其他线程修改的情况)。
如果你确实需要在 ConcurrentHashMap 中使用 null 的话,可以使用一个特殊的静态空对象来代替 null。
public static final Object NULL = new Object();
# LinkedHashMap
tag:
快手count:1
as:hashmap 和 linkedhashmap 的区别
LinkedHashMap 和 HashMap 都是 Java 集合框架中的 Map 接口的实现类。它们的最大区别在于迭代元素的顺序。 HashMap 迭代元素的顺序是不确定的,而 LinkedHashMap 提供了按照插入顺序或访问顺序迭代元素的功能。
此外, LinkedHashMap 内部维护了一个双向链表,用于记录元素的插入顺序或访问顺序,而 HashMap 则没有这个链表。因此, LinkedHashMap 的插入性能可能会比 HashMap 略低,但它提供了更多的功能并且迭代效率相较于 HashMap 更加高效。
# HashSet
tag:
Meta App、税友、用友、百度、快手、浩鲸、邦盛、小米count:9
as:put 原理
HashSet 是对 HashMap 的简单包装,对 HashSet 的函数调用都会转换成合适的 HashMap 方法,简单的来说只使用 HashMap 的 key 进行存储而 value 不进行使用。
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet里面有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Set 去重的原理是什么?
tag:
哈啰、用友count:2
as:HashSet 处理重复数据(忽略还是报错)
《Head first java》第二版中提到:
当你把对象加入
HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
在 JDK1.8 中, HashSet 的 add() 方法只是简单的调用了 HashMap 的 put() 方法,并且判断了一下返回值以确保是否有重复元素。直接看一下 HashSet 中的源码:
// Returns: true if this set did not already contain the specified element
// 返回值:当 set 中没有包含 add 的元素时返回真
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
2
3
4
5
而在 HashMap 的 putVal() 方法中也能看到如下说明:
// Returns : previous value, or null if none
// 返回值:如果插入位置没有元素返回null,否则返回上一个元素
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
}
2
3
4
5
6
也就是说,在 JDK1.8 中,实际上无论 HashSet 中是否已经存在了某元素, HashSet 都会直接插入,只是会在 add() 方法的返回值处告诉我们插入前是否存在相同元素。
# List 和 Set 的区别?
tag:
哈啰count:1
as:
# 线程安全的 Set
tag:
用友count:1
as:多线程操作 Set, 线程安全怎么实现
# LinkedHashSet
tag:
邦盛count:1
as:
# TreeSet
tag:
邦盛count:1
as: