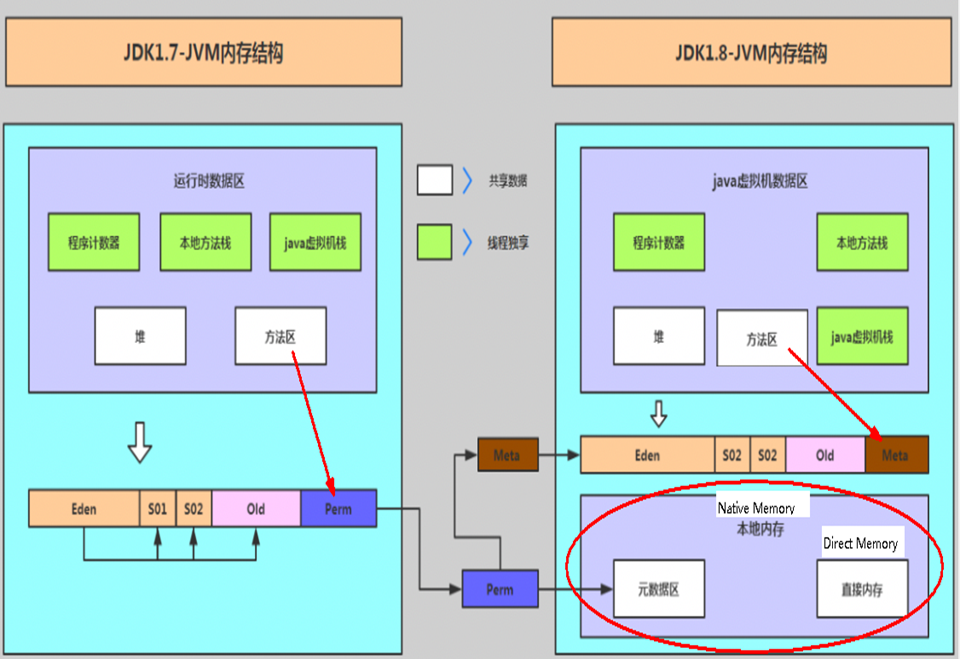
 内存结构
内存结构
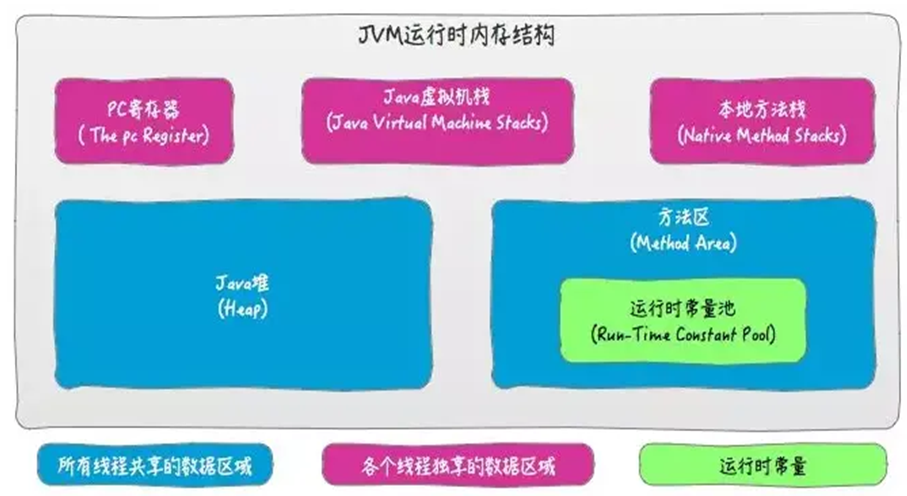
# 内存结构
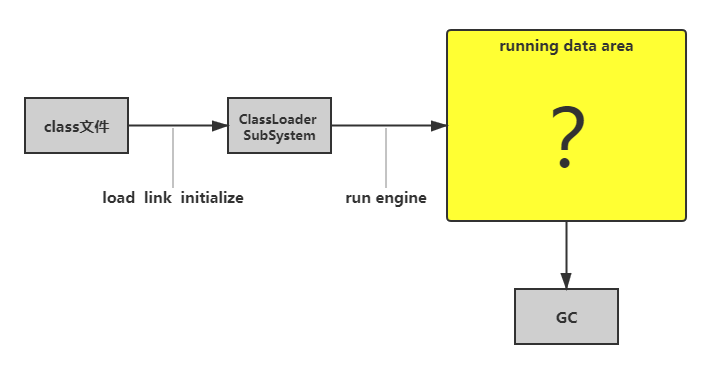
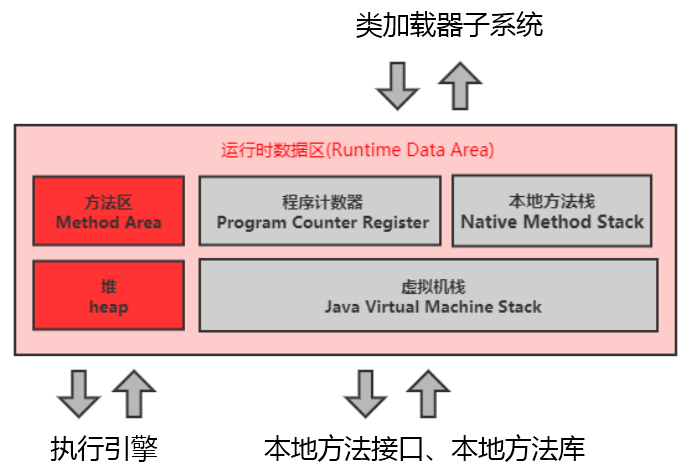
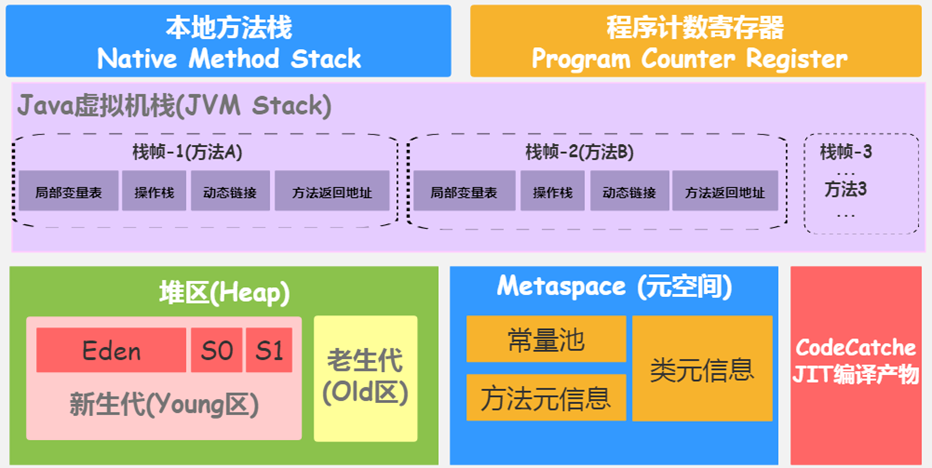
# 程序计数器
JVM 中的程序计数寄存器(Program Counter Register)中, Register 的命名源于 CPU 的寄存器,寄存器存储指令相关的现场信息。 CPU 只有把数据装载到寄存器才能够运行。
举例:
public int test() {
int x = 0;
int y = 1;
return x + y;
}
2
3
4
5
对应的字节码:
public int test();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: iconst_0
1: istore_1
2: iconst_1
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: ireturn
LineNumberTable:
line 7: 0
line 8: 2
line 9: 4
LocalVariableTable:
Start Length Slot Name Signature
0 8 0 this Lcom/alibaba/uc/TestClass;
2 6 1 x I
4 4 2 y I
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 虚拟机栈
有不少 Java 开发人员一提到 Java 内存结构,就会非常粗粒度地将 JVM 中的内存区理解为仅有 Java 堆 (heap) 和 Java 栈 (stack)?
# 栈的特点
- 基本操作

- 栈中存在垃圾回收吗?
- 栈中可能抛出的异常是什么?StackOverflowError?OutOfMemoryError?
- 如何设置栈内存的大小? -Xss size (即:-XX:ThreadStackSize) 一般默认为 512k-1024k,取决于操作系统。

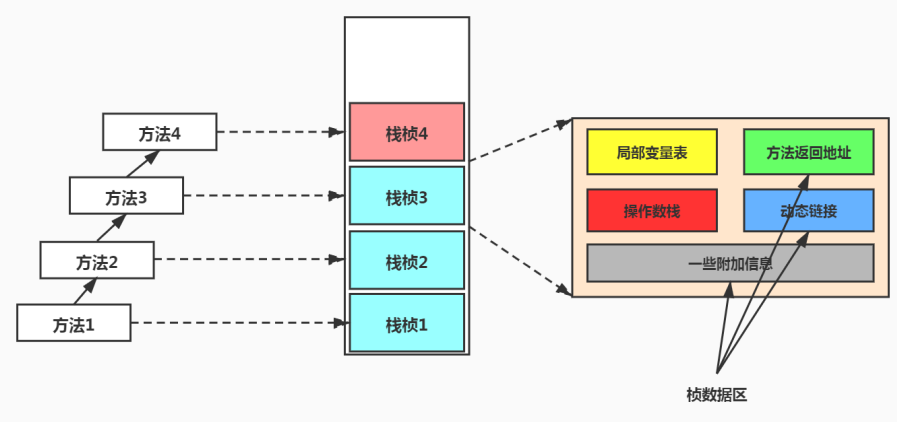
# 栈桢(Stack Frame)
方法和栈桢之间存在怎样的关系?
栈帧是一个内存区块,是一个数据集,维系着方法执行过程中的各种数据信息。
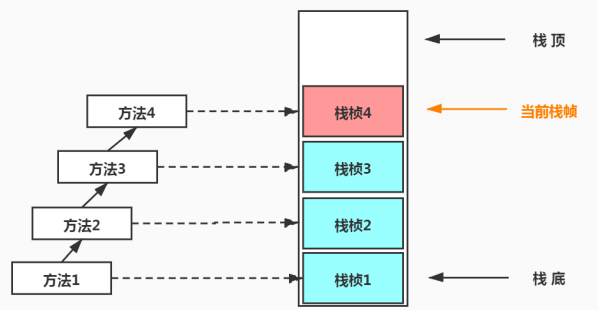
栈桢的内部结构
# 本地方法栈
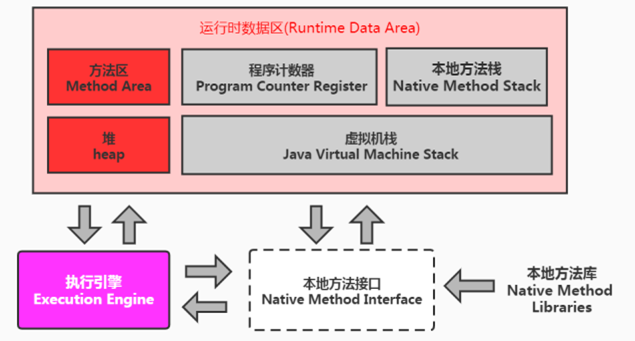
Java 虚拟机栈用于管理 Java 方法的调用,而本地方法栈用于管理本地方法的调用。本地方法是使用 C 语言实现的。它的具体做法是 Native Method Stack 中登记 native 方法,在 Execution Engine 执行时加载本地方法库。
# 堆
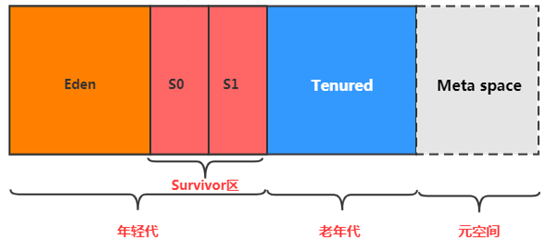
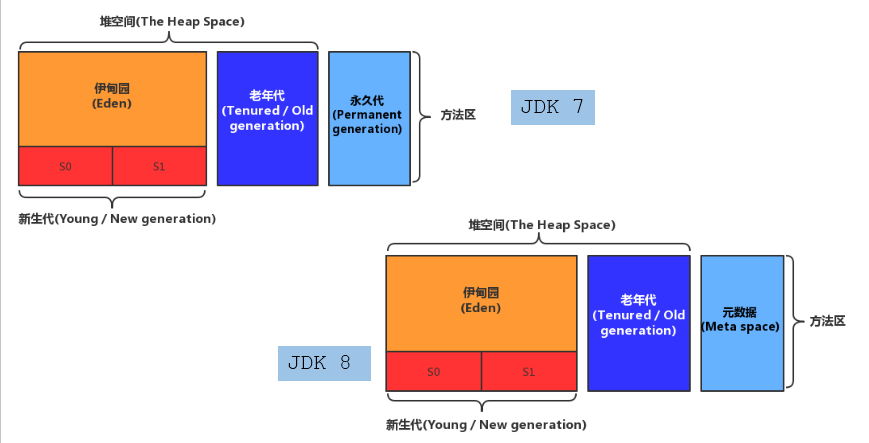
# 堆的内存结构
堆空间的细分结构:
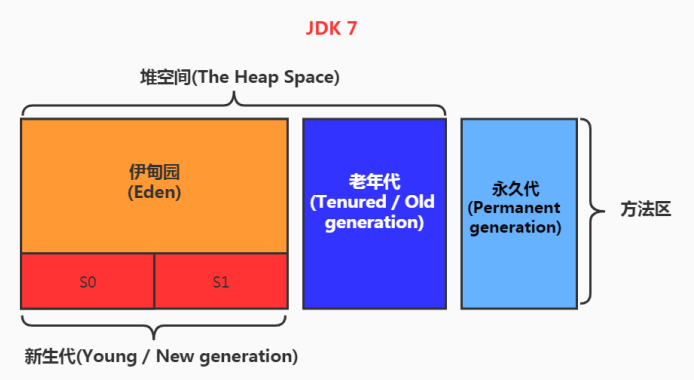
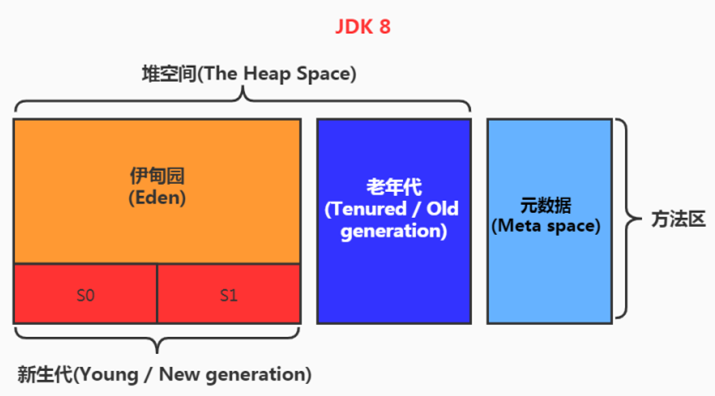
默认情况下:新生代、老年代的比例如何? 1:2
新生代的 Eden、S0、S1 的比例如何?8:1:1
所有的线程共享 Java 堆,在这里还可以划分线程私有的缓冲区(Thread Local Allocation Buffer, TLAB)。
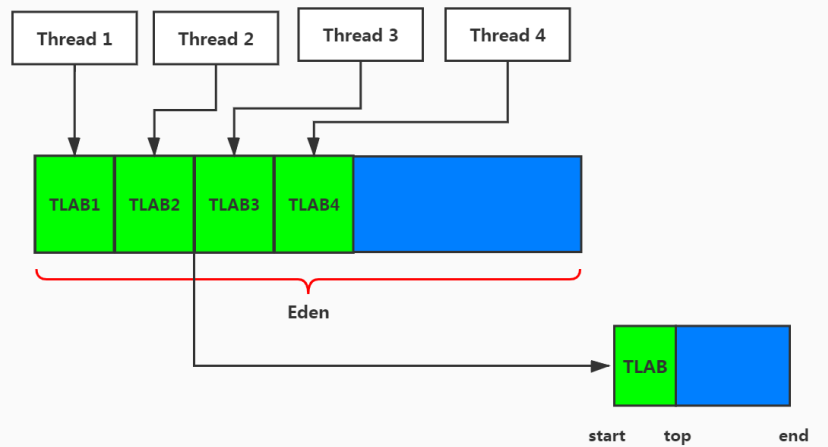
- 在程序中,开发人员可以通过选项
-XX:UseTLAB设置是否开启 TLAB 空间。 - 默认情况下,TLAB 空间的内存非常小,仅占有整个 Eden 空间的 1%,当然我们可以通过选项
-XX:TLABWasteTargetPercent设置 TLAB 空间所占用 Eden 空间的百分比大小。
# 对象分配过程
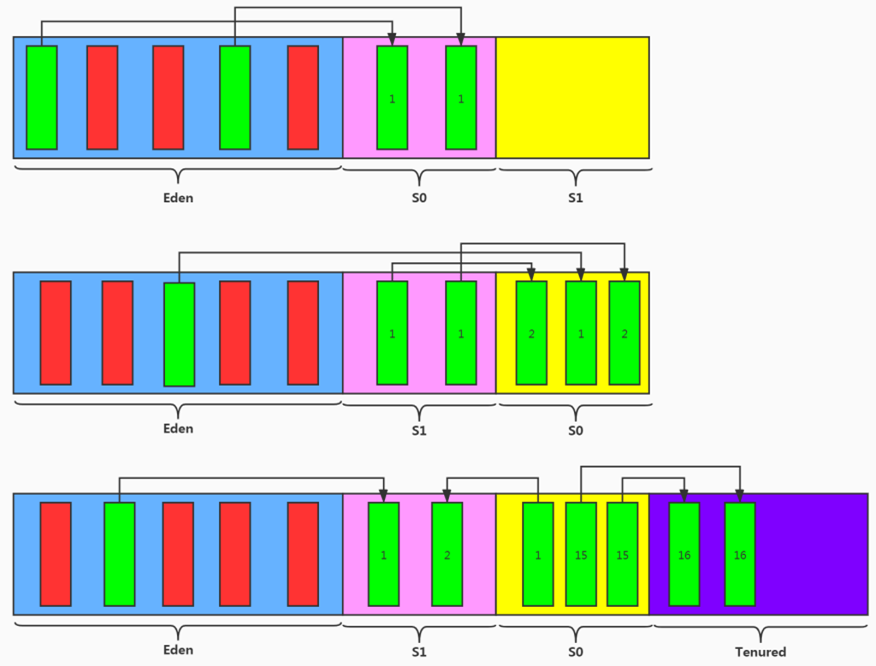
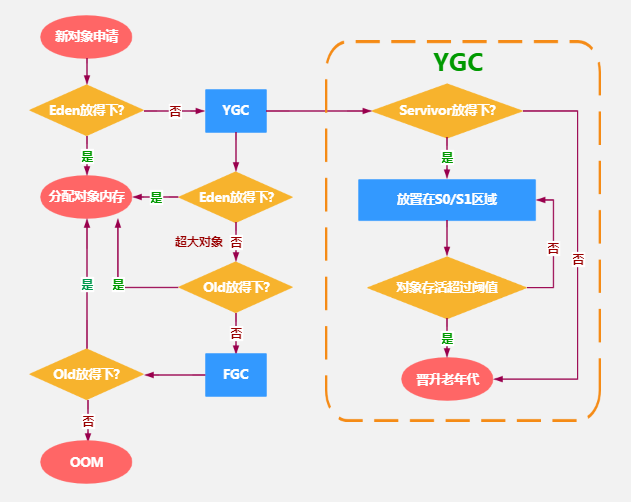
# 内存分配策略
针对不同年龄段的对象分配原则如下所示:
- 优先分配到 Eden
- 大对象直接分配到老年代
- 长期存活的对象分配到老年代
- 空间分配担保
- 动态对象年龄判断
堆空间分代思想
为什么需要把 Java 堆分代?不分代就不能正常工作了吗?
分代的唯一理由就是优化 GC 性能。
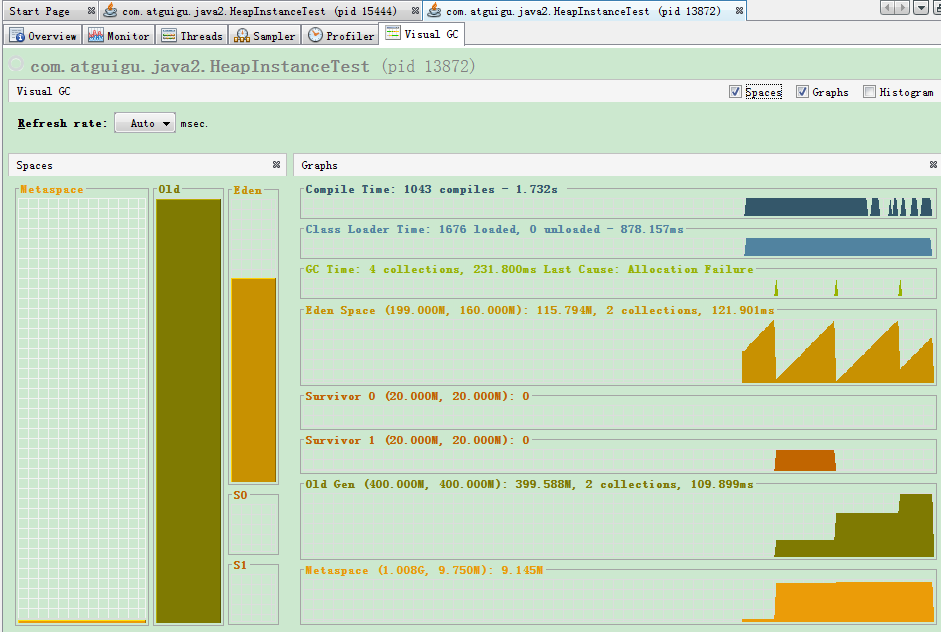
# jVisualVM 的使用
/**
* -Xms600m -Xmx600m -XX:SurvivorRatio=8
* @author shkstart
* @create 2020 下午 5:45
*/
public class HeapInstanceTest {
byte[] buffer = new byte[1024 * 100];//100KB
public static void main(String[] args) {
ArrayList<HeapInstanceTest> list = new ArrayList<>();
while(true){
list.add(new HeapInstanceTest());
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 堆的各种参数
# 堆空间大小
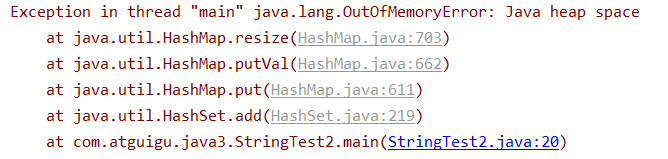
堆空间大小的设置:
-Xms: 初始内存 (默认为物理内存的 1/64);Xmx: 最大内存(默认为物理内存的 1/4);
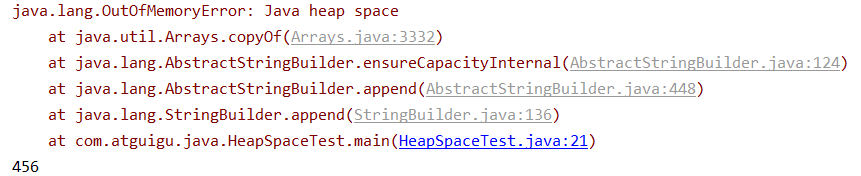
/**
* -Xms10m -Xmx10m
*
* @author shkstart
* @create 2020 上午 10:48
*/
public class HeapSpaceTest {
public static void main(String[] args) {
String str = "atguigu";
List<String> list = new ArrayList<>();
try {
while(true){
str += UUID.randomUUID().toString();
list.add(str);
}
} catch (Throwable e) {
e.printStackTrace();
System.out.println(list.size());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
堆空间溢出
# 新生代大小
-Xmn设置新生代的大小。(初始值及最大值)
通常默认即可。
# 新生代与老年代在堆结构的占比
-XX:NewRatio配置新生代与老年代在堆结构的占比。赋的值即为老年代的占比,剩下的 1 给新生代 默认 - XX:NewRatio=2,表示新生代占 1,老年代占 2,新生代占整个堆的 1/3 -XX:NewRatio=4,表示新生代占 1,老年代占 4,新生代占整个堆的 1/5
# 生还者占比
-XX:SurvivorRatio在 HotSpot 中,Eden 空间和另外两个 Survivor 空间,缺省所占的比例是 8:1
开发人员可以通过选项 “-XX:SurvivorRatio” 调整这个空间比例。比如 - XX:SurvivorRatio=8
# 新生代垃圾最大年龄
-XX:MaxTenuringThreshold设置新生代垃圾的最大年龄。超过此值,仍未被回收的话,则进入老年代。默认值为 15-XX:MaxTenuringThreshold=0:表示年轻代对象不经过 Survivor 区,直接进入老年代。对于老年代比较多的应用,可以提高效率。 如果将此值设置为一个较大值,则年轻代对象会在 Survivor 区进行多次复制,这样可以增加对象在年轻代的存活时间,增加在年轻代即被回收的概率。
# 输出详细的 GC 处理日志
-XX:+PrintGCDetails用于输出详细的 GC 处理日志

显示如下:
Heap
PSYoungGen total 9728K, used 2497K [0x00000000fd580000, 0x00000000fe000000, 0x0000000100000000)
eden space 8704K, 28% used [0x00000000fd580000,0x00000000fd7f06e8,0x00000000fde00000)
from space 1024K, 0% used [0x00000000fdf00000,0x00000000fdf00000,0x00000000fe000000)
to space 1024K, 0% used [0x00000000fde00000,0x00000000fde00000,0x00000000fdf00000)
ParOldGen total 22016K, used 0K [0x00000000f8000000, 0x00000000f9580000, 0x00000000fd580000)
object space 22016K, 0% used [0x00000000f8000000,0x00000000f8000000,0x00000000f9580000)
Metaspace used 3511K, capacity 4498K, committed 4864K, reserved 1056768K
class space used 388K, capacity 390K, committed 512K, reserved 1048576K
2
3
4
5
6
7
8
9
# 允许担保失败
-XX:HandlePromotionFailure在发生 Minor GC 之前,虚拟机会检查老年代最大可用的连续空间是否大于新生代所有对象的总空间,如果大于,则此次 Minor GC 是安全的,如果小于,则虚拟机会查看-XX:HandlePromotionFailure设置值是否允许担保失败。 如果HandlePromotionFailure=true,那么会继续检查老年代最大可用连续空间是否大于历次晋升到老年代的对象的平均大小,如果大于,则尝试进行一次 Minor GC,但这次 Minor GC 依然是有风险的;如果小于或者HandlePromotionFailure=false,则改为进行一次 Full GC。
在 JDK 6 Update 24 之后,HandlePromotionFailure 参数不会再影响到虚拟机的空间分配担保策略,观察 OpenJDK 中的源码变化,虽然源码中还定义了 HandlePromotionFailure 参数,但是在代码中已经不会再使用它。JDK 6 Update 24 之后的规则变为只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小就会进行 Minor GC,否则将进行 Full GC。
# 堆,是分配对象的唯一选择吗
在《深入理解 Java 虚拟机中》关于 Java 堆内存有这样一段描述:
随着 JIT 编译期的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么 “绝对” 了。
在 Java 虚拟机中,对象是在 Java 堆中分配内存的,这是一个普遍的常识。但是,有一种特殊情况,那就是如果经过逃逸分析 (Escape Analysis) 后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配。这样就无需在堆上分配内存,也无须进行垃圾回收了。这也是最常见的堆外存储技术。
- 逃逸分析
- 栈上分配
- 同步省略
- 标量替换
# 方法区
《Java 虚拟机规范》中明确说明: “尽管所有的方法区在逻辑上是属于堆的一部分,但一些简单的实现可能不会选择去进行垃圾收集或者进行压缩。” 但对于 HotSpotJVM 而言,方法区还有一个别名叫做 Non-Heap (非堆),目的就是要和堆分开。所以,方法区看作是一块独立于 Java 堆的内存空间。

# 栈、堆、方法区的关系
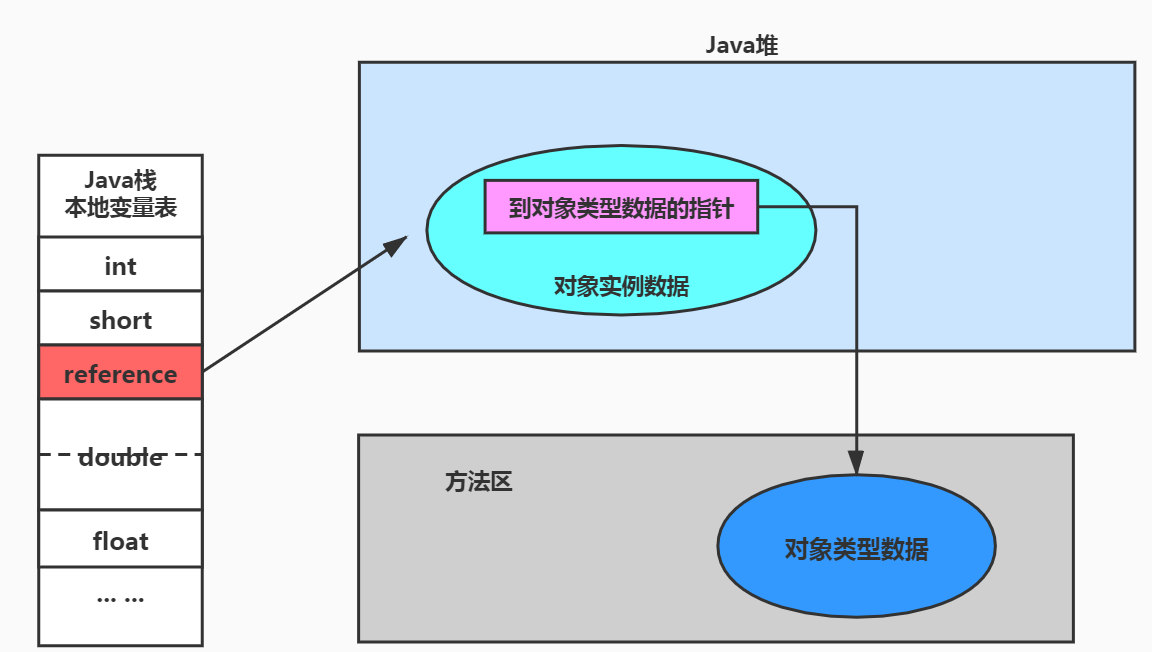
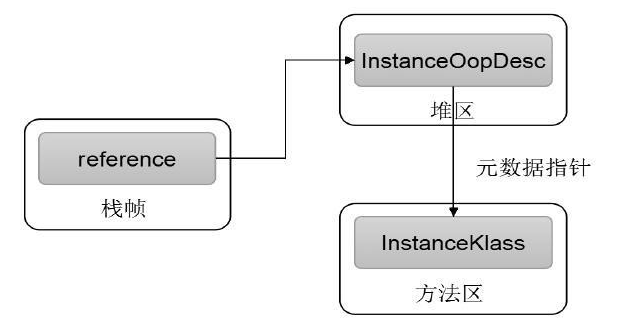
# 方法区都存什么


# 运行时常量池
要弄清楚方法区的运行时常量池,需要理解清楚 ClassFile 中的常量池。

举例:
public class SimpleClass {
public void sayHello() {
System.out.println("hello");
}
}
2
3
4
5
这个已生成的类文件中的常量池像如下这样:
Constant pool:
#1 = Methodref #6.#17 // java/lang/Object.”<init>”:()V
#2 = Fieldref #18.#19 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #20 // “Hello”
#4 = Methodref #21.#22 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #23 // org/jvminternals/SimpleClass
#6 = Class #24 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lorg/jvminternals/SimpleClass;
#14 = Utf8 sayHello
#15 = Utf8 SourceFile
#16 = Utf8 SimpleClass.java
#17 = NameAndType #7:#8 // “<init>”:()V
#18 = Class #25 // java/lang/System
#19 = NameAndType #26:#27 // out:Ljava/io/PrintStream;
#20 = Utf8 Hello
#21 = Class #28 // java/io/PrintStream
#22 = NameAndType #29:#30 // println:(Ljava/lang/String;)V
#23 = Utf8 org/jvminternals/SimpleClass
#24 = Utf8 java/lang/Object
#25 = Utf8 java/lang/System
#26 = Utf8 out
#27 = Utf8 Ljava/io/PrintStream;
#28 = Utf8 java/io/PrintStream
#29 = Utf8 println
#30 = Utf8 (Ljava/lang/String;)V
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
常量池,可以看做是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等类型。
# 永久代与元空间
BEA JRockit、IBM J9 等来说,是不存在永久代的概念的。原则上如何实现方法区属于虚拟机实现细节,不受《Java 虚拟机规范》管束,并不要求统一。
HotSpot 中永久代的变化
- jdk1.6 及之前:有永久代 (permanent generation)
- jdk1.7:有永久代,但已经逐步 “去永久代”,字符串常量池、静态变量移除,保存在堆中
- jdk1.8 及之后: 无永久代,类型信息、字段、方法、常量保存在本地内存的元空间,但字符串常量池仍在堆
永久代为什么要被元空间替换? (元空间,使用本地内存)
http://openjdk.java.net/jeps/122

- 为永久代设置空间大小是很难确定的
- 对永久代进行调优是困难的
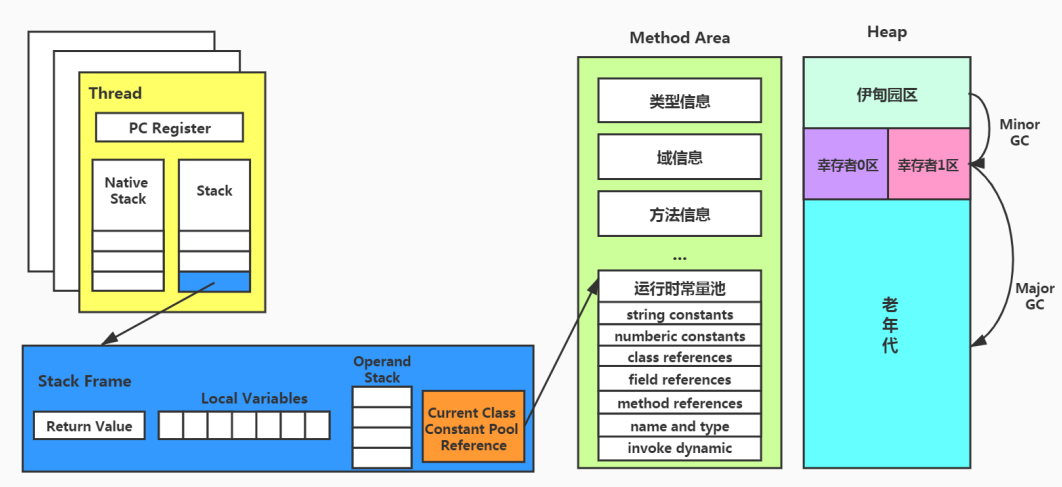
# 内存结构小结
# VM 参数小结
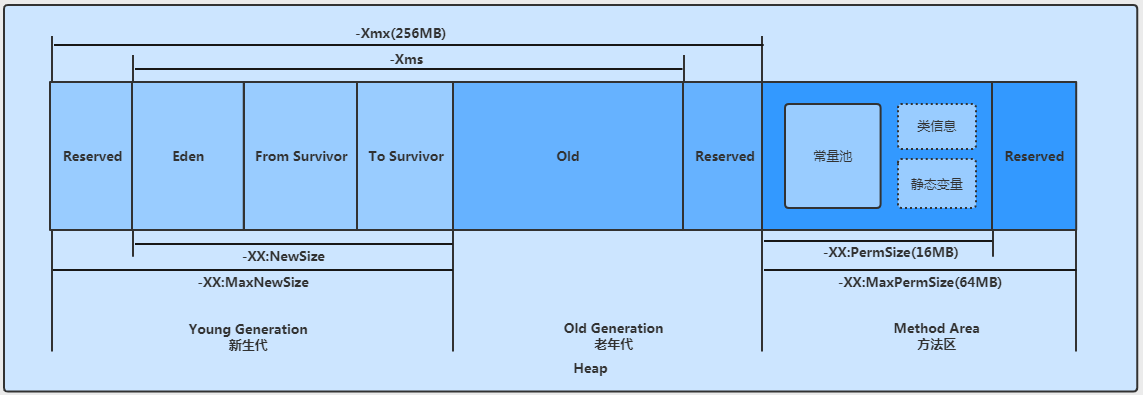
JDK8 中:
-XX:MetaspaceSize-XX:MaxMetaspaceSize:默认值是 - 1,即不限制
# 直接内存
直接内存是在 Java 堆外的、直接向系统申请的内存区间。通常,访问直接内存的速度会优于 Java 堆。即读写性能高。
缺点:
- 分配回收成本较高
- 不受 JVM 内存回收管理
# StringTable
# String 的不可变性
- 通过字面量的方式(区别于 new)给一个字符串赋值,此时的字符串值声明在字符串常量池中。
- 字符串常量池中是不会存储相同内容的字符串的。
案例
@Test
public void testDemo() {
String a = "1";
String b = "2";
String c = "12";
String d = a + b;
System.out.println(c == d);
}
2
3
4
5
6
7
8
9

@Test
public void test1() {
String s1 = "abc";//字面量的定义方式
String s2 = "abc";
s1 = "hello";
System.out.println(s1 == s2);//比较s1和s2的地址值
System.out.println(s1);//hello
System.out.println(s2);//abc
System.out.println("*****************");
String s3 = "abc";
s3 += "def";
System.out.println(s3);//abcdef
System.out.println(s2);
System.out.println("*****************");
String s4 = "abc";
String s5 = s4.replace('a', 'm');
System.out.println(s4);//abc
System.out.println(s5);//mbc
}
@Test
public void test2(){
StringTest1 ex = new StringTest1();
ex.change(ex.str, ex.ch);
System.out.print(ex.str + " and ");//
System.out.println(ex.ch);
}
String str = new String("good");
char[] ch = { 't', 'e', 's', 't' };
public void change(String str, char ch[]) {
str = "test ok";
ch[0] = 'b';
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# String 的内存分配
整体来说:
- Java 6 及以前,字符串常量池存放在永久代。
- Java 7 中 Oracle 的工程师对字符串池的逻辑做了很大的改变,即将字符串常量池的位置调整到 Java 堆内。
- Java 8 中,字符串常量仍然在堆。
StringTable 为什么要调整?
https://www.oracle.com/technetwork/java/javase/jdk7-relnotes-418459.html#jdk7changes

举例:
jdk6:

jdk8:
具体细节:数组 + 链表
String 的 String Pool 是一个固定大小的 Hashtable,默认值大小长度是 1009,如果放进 String Pool 的 String 非常多,就会造成 Hash 冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用 String.intern 时性能会大幅下降(因为要一个一个找)。
在 jdk6 中 StringTable 是固定的,就是 1009 的长度,所以如果常量池中的字符串过多就会导致效率下降很快。在 jdk7 中,StringTable 的长度可以通过一个参数指定:
-XX:StringTableSize=99991
# String 的基本操作
public class StringTest3 {
@Test
public void test1(){
System.out.println();//2320
System.out.println();//2321
System.out.println();//2321
System.out.println("1");//2321
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10");//2330
System.out.println("1");//2331
System.out.println("2");//2331
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10");//2331
}
@Test
public void test2(){
String s1 = "a" + "b" + "c";//常量优化机制,编译的时候就已经是abc
String s2 = "abc";
/*
* 最终.java编译成.class,再执行.class
* String s1 = "abc";
* String s2 = "abc"
*/
System.out.println(s1 == s2); //true
System.out.println(s1.equals(s2)); //true
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 字符串拼接操作
@Test
public void test3(){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;//new StringBuilder().append("a").append("b").toString() --> new String("ab")
System.out.println(s3 == s4);
}
@Test
public void test4(){
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);
}
//体会执行效率:
public void method1(){
String src = "";
for(int i = 0;i < 10;i++){
src = src + "a";//每次循环都会创建一个StringBuilder
}
System.out.println(src);
}
public void method2(){
StringBuilder src = new StringBuilder();
for (int i = 0; i < 10; i++) {
src.append("a");
}
System.out.println(src);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# new String () 问题
String 的实例化方式:
- 方式一:通过字面量定义的方式
- 方式二:通过 new + 构造器的方式
- 面试题:String s = new String ("abc"); 方式创建对象,在内存中创建了几个对象?
- 两个:一个是堆空间中 new 结构,另一个是 char [] 对应的常量池中的数据:"abc"
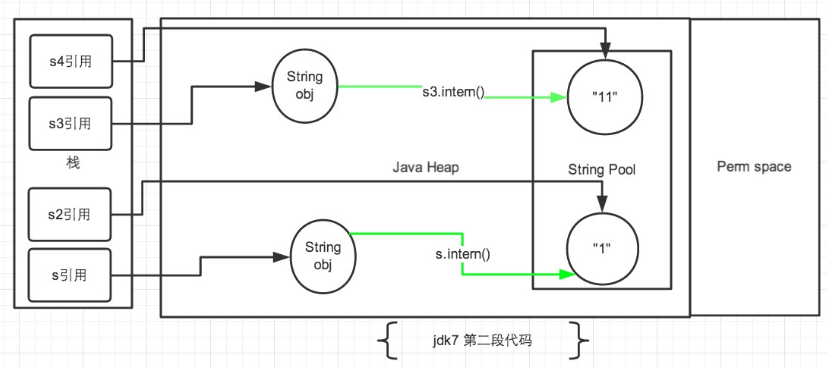
# intern () 方法
public class StringTest4 {
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);//
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);//
}
}
2
3
4
5
6
7
8
9
10
11
12
13
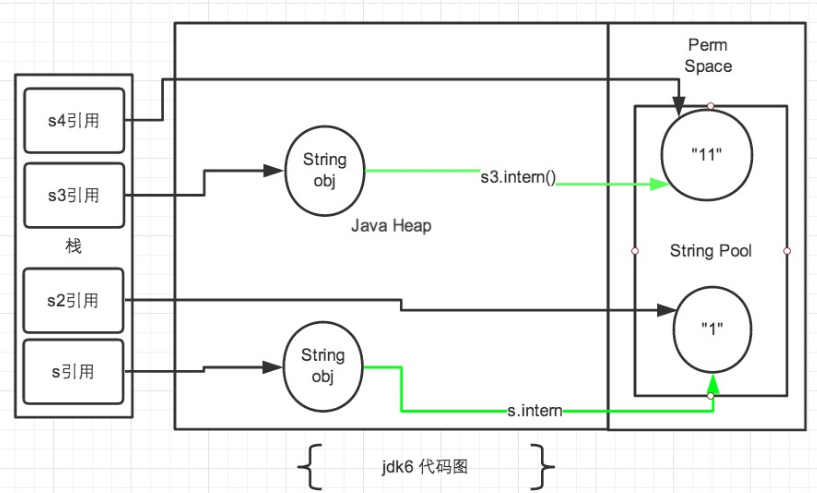
jdk6 中的解释:
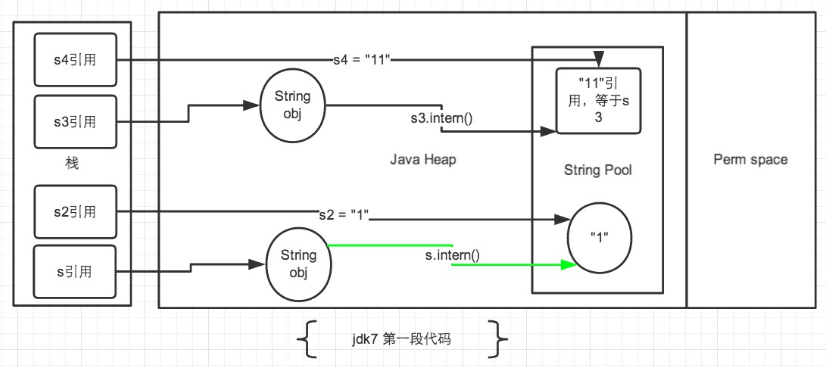
jdk7 中的解释:
题目变形:
@Test
public void test1(){
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);//
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);//
}
2
3
4
5
6
7
8
9
10
11
12
13
# G1 的 String 去重操作
String 底层是什么结构?
新的需求: 许多大规模的 java 应用的瓶颈在于内存,测试表明,在这些类型的应用里面,java 堆中存活的数据集合差不多 25% 是 String 对象。更进一步,这里面差不多一半 String 对象是重复的,重复的意思是说:string1.equals (string2)=true。堆上存在重复的 String 对象必然是一种内存的浪费。这个项目将在 G1 垃圾收集器中实现自动持续对重复的 String 对象进行去重,这样就能避免浪费内存。
说明:String 去重不需要对 jdk 的类库和已经存在的 java 代码做任何的改动。