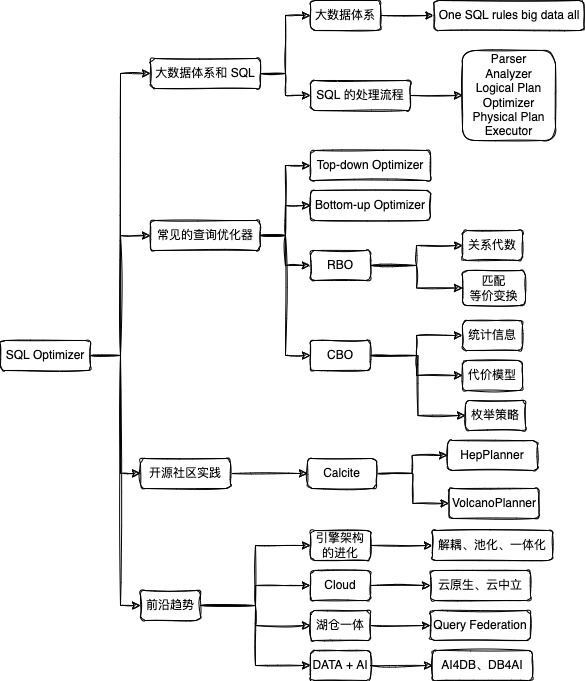
 SQL Optimizer 解析| 青训营笔记
SQL Optimizer 解析| 青训营笔记
# SQL Optimizer 解析| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第 1 天
# 大数据体系
# 大数据处理相关
- 批式计算(batch computing):统一收集数据存储到数据库中,然后对数据进行批量处理;
- 流式计算(stream computing):对数据流进行处理,实时计算;
- 交互分析引擎(interactive computing):软件实时接收用户数据输入;
- YARN:是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处;
- Kubernetes:可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化;
# 批式计算和流式计算区别
| 流式计算 | 批式计算 | |
|---|---|---|
| 特性 | 对数据流进行处理,实时计算 | 统一收集数据,存储到数据库中,然后对数据进行批量处理 |
| 时效性 | 实时计算,低延迟 | 非实时,高延迟 |
| 数据特征 | 数据一般是动态的,无边界的 | 数据一般是静态数据 |
| 应用场景 | 实时场景,时效性高,比如实时推荐,业务监控 | 时效性不用很高,离线计算,数据分析,离线报表 |
| 运行方式 | 流式计算的任务是持续进行的 | 批量计算一次性完成 |
# YARN
YARN 基本思想:
- 一个全局的资源管理器
ResourceManager和与每个应用对应的ApplicationMaster Resourcemanager和NodeManager组成全新的通用系统,以分布式的方式管理应用程序。
ResourceManager(RM):集群整体运行资源
- 处理客户端请求
- 启动 / 监控 ApplicationMaster
- 监控 NodeManager
- 资源分配与调度
APPlicationMaster(AM):单个任务运行资源
- 为应用程序申请资源,并分配任务
- 任务监控与容错
NodeManager(NM):单个节点服务器资源
- 单个节点上资源管理
- 处理来自 ResourceManager 的命令
- 处理来自 ApplicationMaster 的命令
Container:资源抽象
- Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、 CPU、 磁盘、网络等
YARN 的工作机制
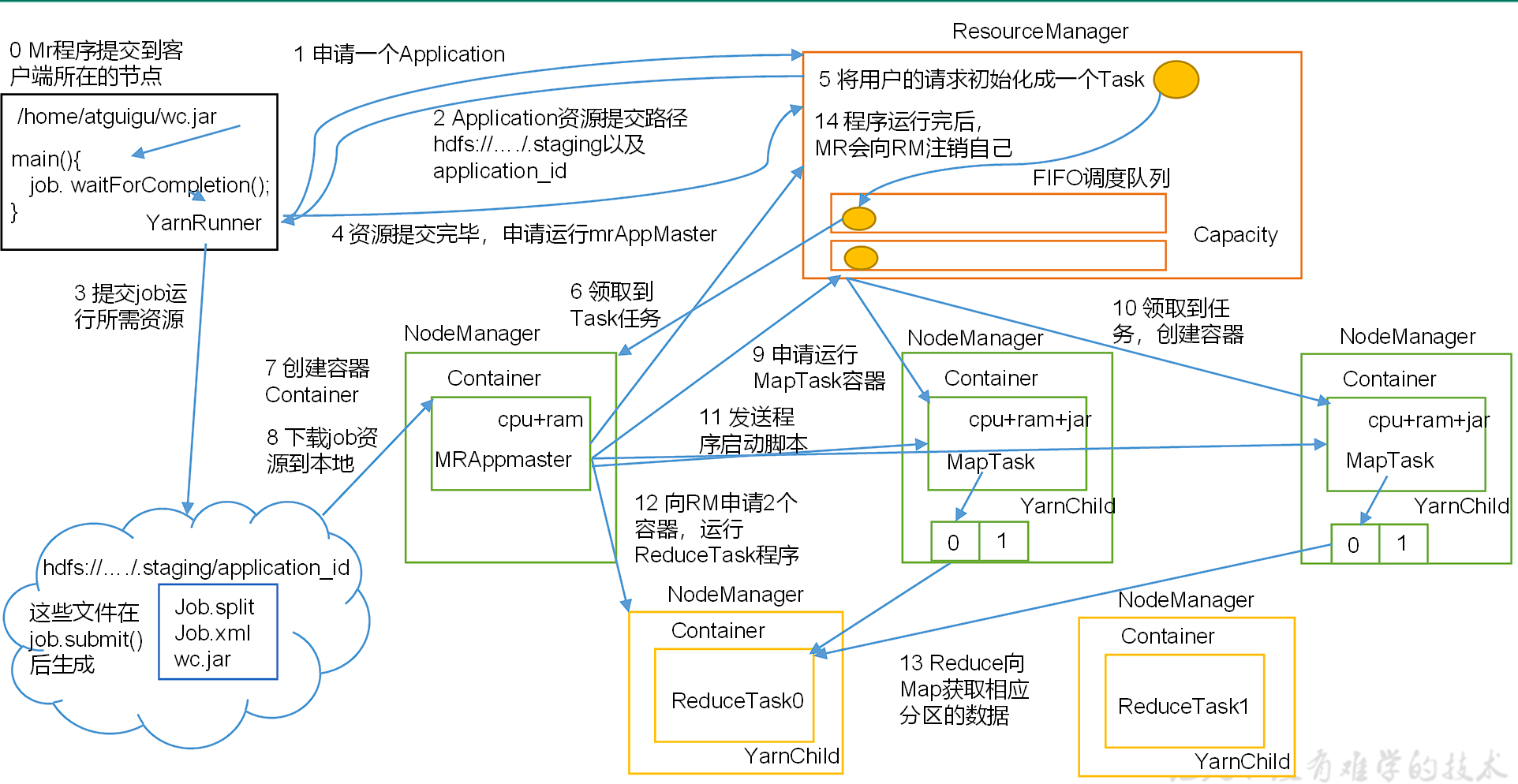
- MR 程序提交到客户端所在的节点。
- YarnRunner 向 ResourceManager 申请一个 Application。
- RM 将该应用程序的资源路径返回给 YarnRunner。
- 该程序将运行所需资源提交到 HDFS 上。
- 程序资源提交完毕后,申请运行 mrAppMaster。
- RM 将用户的请求初始化成一个 Task。
- 其中一个 NodeManager 领取到 Task 任务。
- 该 NodeManager 创建容器 Container,并产生 MRAppmaster。
- Container 从 HDFS 上拷贝资源到本地。
- MRAppmaster 向 RM 申请运行 MapTask 资源。
- RM 将运行 MapTask 任务分配给另外两个 NodeManager,另两个 NodeManager 分别领取任务并创建容器。
- MR 向两个接收到任务的 NodeManager 发送程序启动脚本,这两个 NodeManager 分别启动 MapTask,MapTask 对数据分区排序。
- MrAppMaster 等待所有 MapTask 运行完毕后,向 RM 申请容器,运行 ReduceTask。
- ReduceTask 向 MapTask 获取相应分区的数据。
- 程序运行完毕后,MR 会向 RM 申请注销自己。
# SQL
为什么 SQL 如此流行?
- 有 MySQL、Oracle 之类使用 SQL 作为交互语言的数据库
- 有 JDBC、ODBC 之类和各种数据库交互的标准接口
- 有大量数据科学家和数据分析师等不太会编程语言但又要使用数据的人
- 大数据计算引擎大多数都支持 SQL 作为更高抽象层次的计算入口
- Hive:把 sql 解析后用 MapReduce 跑(HQL)
- SparkSQL:把 sql 解析后用 Spark 跑,比 hive 快点
- FlinkSQL:FlinkSQL 则是基于 Apache Calcite 实现了标准的 SQL,可以通过编写 SQL 的方式进行 Flink 数据处理
- Phoenix:一个绕过了 MapReduce 运行在 HBase 上的 SQL 框架
- Drill/Impala/Presto:交互式查询
- Druid/Kylin:olap 预计算系统
# SQL 语句执行的基本流程
下图是 MySQL 的一个简要架构图,从下图你可以很清晰的看到用户的 SQL 语句在 MySQL 内部是如何执行的。
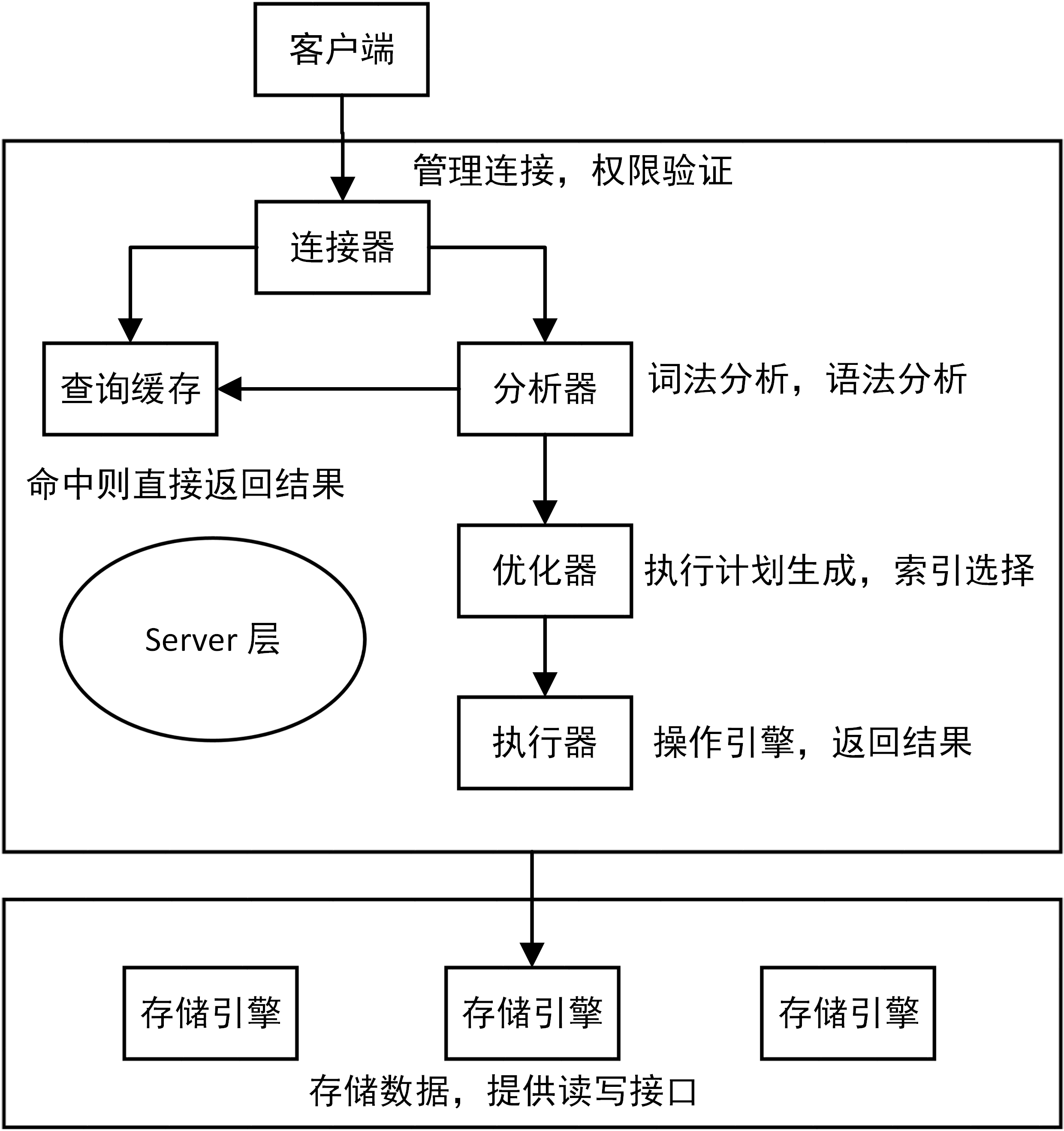
连接层 使用 TCP 加密的 ssl 通信协议,管理连接,控制最大连接量,检测连接时长,权限验证(账号密码等),优先查询缓存(两次同样的 select 之间有更新操作,查询缓存会清空)
服务层 连接层会把 sql 语句交给服务层,这里面又包含一系列的流程:
- 解析器:和编译器的角色一样,要生成语法树,解析 SQL 词法以及语法分析
- 优化器:生成 SQL 的执行计划以及当前 SQL 相应的索引的选择(explain 可查看)
- 执行器:调用存储引擎相应的 API 接口进行数据的读写操作
比如查询缓存的判断、根据 sql 调用相应的接口,对我们的 sql 语句进行词法和语法的解析(比如关键字怎么识别,别名怎么识别,语法有没有错误等等)。
然后就是优化器,MysqL 底层会根据一定的规则对我们的 sql 语句进行优化,最后再交给执行器去执行。
存储引擎 存储引擎就是我们的数据真正存放的地方,在 MysqL 里面支持不同的存储引擎。再往下就是内存或者磁盘。
花费磁盘 I/O 读写磁盘数据,构建 B + 树索引,事务日志(undo log/redo log),锁机制,隔离级别…
# SQL 的处理流程


# Parser(词法分析)
文本 String --> 抽象语法树 AST(abstract syntax tree)
- 词法分析:拆分字符串得到关键词、数值常量、字符串常量、运算符号等 TOKEN
- 语法分析:将 TOKEN 组成 AST Node,最终得到一个 AST
实现:递归下降(ClickHouse),Flex 和 Bison(PostgreSQL),JavaCC(Flink),Antlr(Presto,Spark)
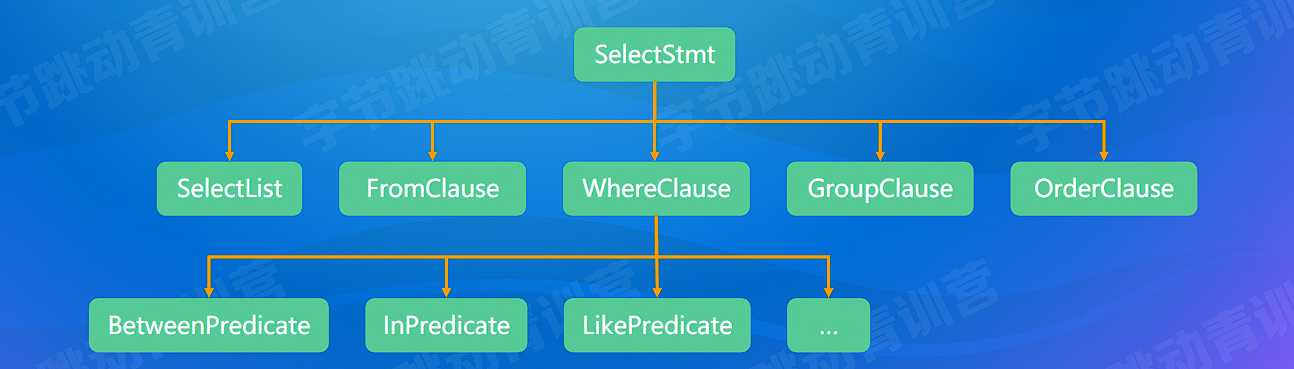
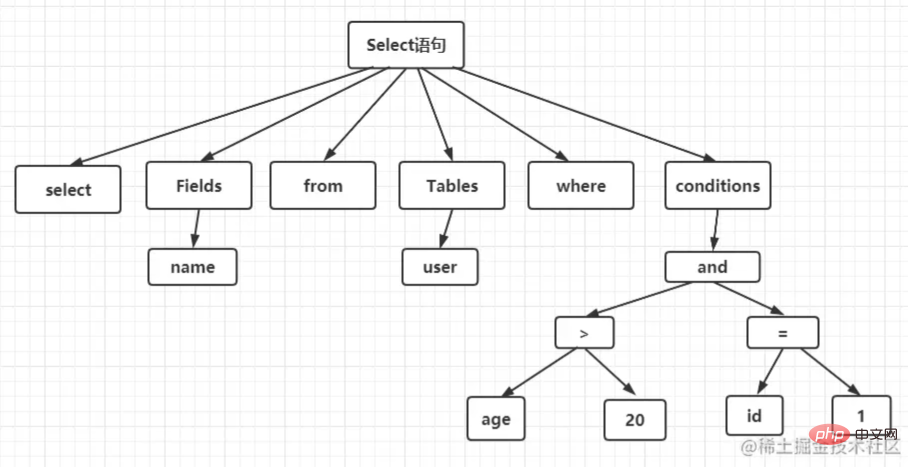
词法分析就是把一个完整的 SQL 语句打碎成一个个的单词。
比如一个简单的 SQL 语句: select name from user where id = 1 and age > 20;
# Analyzer(分析器)
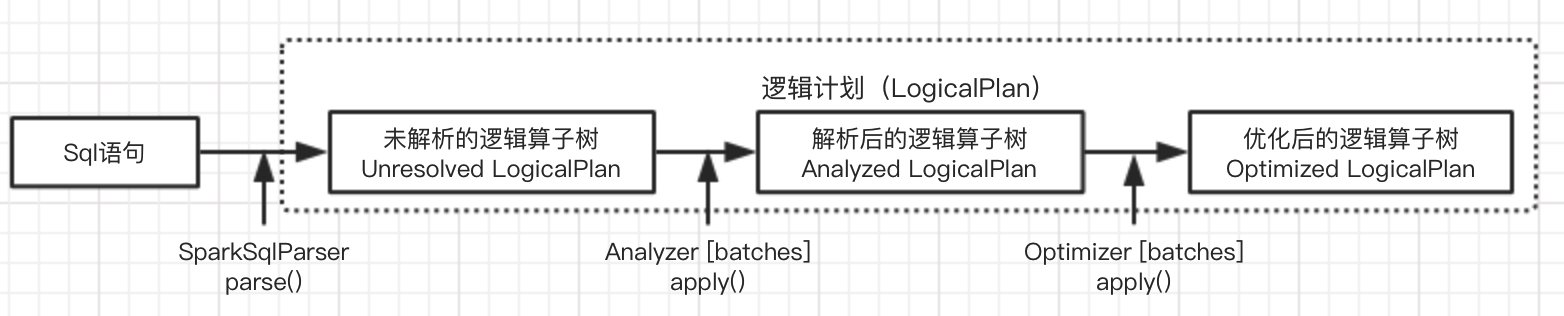
SQL 语句⾸先通过 Parser 模块被解析成 parsed Logical Plan AST 语法树,⽽这棵树是 Unresolved Logical Plan(未解决的逻辑计划)的,parsed Logical Plan 通过 Analyzer(分析器)模块借助于 Catalog 中的表信息解析成为 Analyzer Logical Plan AST 语法树,这棵树是 resolved Logical Plan(解决的逻辑计划);
- 访问库 / 表源信息并绑定:检查并绑定 Database、Table、Column 等信息
- 判断 Query 是否合理:比如 min/max/avg 的输入是数值;检查合法性比如数据库;表和列名是否存在;类型检查和类型转换;Where 中不能有 Grouping 操作;HLL 和 Bitmap 列不能 Sum 等; Table 和 Column 的别名处理;
- 将 AST 转化为 Logical Plan(逻辑计划树)
# Logical Plan(逻辑计划树)
- 逻辑地描述 SQL 如何一步一步执行查询计算,最终得到结果的分步计划
- 树中每个节点都是一个算子(Operator),定义对数据集合的计算操作
- 边代表数据流向 从子节点流向父节点
- 仅为逻辑流程,无实际的算法
- 左深树(Left-deep tree):右边必须为表
- Left-deep tree:如果对 A,B,C,D 执行 join,那么首先 A join B 得到一个临时表 AB 并 AB 物化到磁盘,然后 AB join C 得到中间临时表 ABC 并物化到磁盘,最后 ABC joinD 得到最终结果。可以发现,这种 join 顺序非常简单,缺点是只能串行 join,并且由于产生了大量的中间临时表,因此不太适合 OLAP 中的星型和雪花模型。
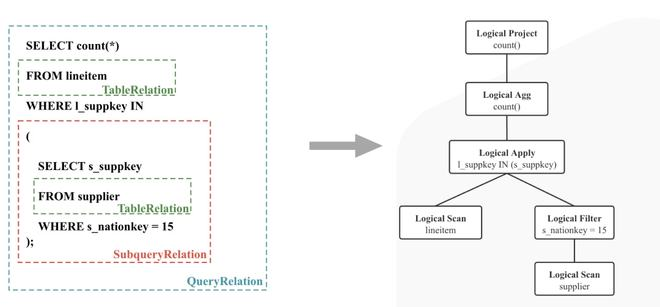
# Optimizer(查询优化)
- SQL 是一种声明式语言,用户只描述做什么,没有告诉数据库怎么做
- 目标:找到一个正确且执行代价最小的物理执行计划
- 复杂 NP-Hard
- SQL 越复杂,JOIN 表越多,数据量越大,优化意义就越大
Optimizer 的输入是一棵逻辑计划树,输出是一棵 Cost “最低” 的分布式物理计划树。
# Physical Plan/Executor(物理执行计划)
拆分时充分考虑数据的亲和性,减少网络传输的 Cost
Plan Fragment (执行计划子树)
- 目标: 最小化网络数据传输
- 利用数据的物理分布(数据亲和性)
- 增加 Shuffle 算子
Executor(执行节点)
- 单机并行:cache,pipeline,SIMD
- 多机并行:一个 Fragment 对应多实例
小结:
- One SQL rules big data all
- SQL 需要依次经过 Parser,Analyzer,Optimizer 和 Executor 处理
- 查询优化器是数据库的大脑,对查询性能至关重要
- 查询优化器需要感知数据分布,充分利用数据亲和性
- 查询优化器按照最小化网络数据传输的目标把逻辑计划拆分成多个物理计划片段
参考文章:
StarRocks 技术内幕:查询原理浅析 (opens new window)
【大数据专场 学习资料一】第四届字节跳动青训营 (opens new window)
关系型数据库进阶(三)连接运算及查询实例 (opens new window)
# 常见的查询优化器
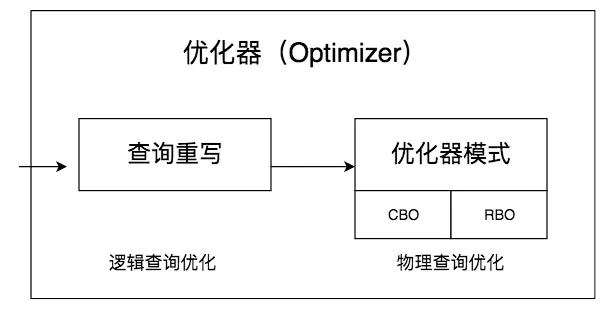
查询优化器的目的就是生成最佳的执行计划,而生成最佳执行计划的策略通常有以下两种方式。
- 第一种是基于规则的优化器(RBO,Rule-Based Optimizer),规则就是人们以往的经验,或者是采用已经被证明是有效的方式。通过在优化器里面嵌入规则,来判断 SQL 查询符合哪种规则,就按照相应的规则来制定执行计划,同时采用启发式规则去掉明显不好的存取路径。
- 第二种是基于代价的优化器(CBO,Cost-Based Optimizer),这里会根据代价评估模型,计算每条可能的执行计划的代价,也就是 COST,从中选择代价最小的作为执行计划。相比于 RBO 来说,CBO 对数据更敏感,因为它会利用数据表中的统计信息来做判断,针对不同的数据表,查询得到的执行计划可能是不同的,因此制定出来的执行计划也更符合数据表的实际情况。
但我们需要记住,SQL 是面向集合的语言,并没有指定执行的方式,因此在优化器中会存在各种组合的可能。我们需要通过优化器来制定数据表的扫描方式、连接方式以及连接顺序,从而得到最佳的 SQL 执行计划。
你能看出来,RBO 的方式更像是一个出租车老司机,凭借自己的经验来选择从 A 到 B 的路径。而 CBO 更像是手机导航,通过数据驱动,来选择最佳的执行路径。
# RBO
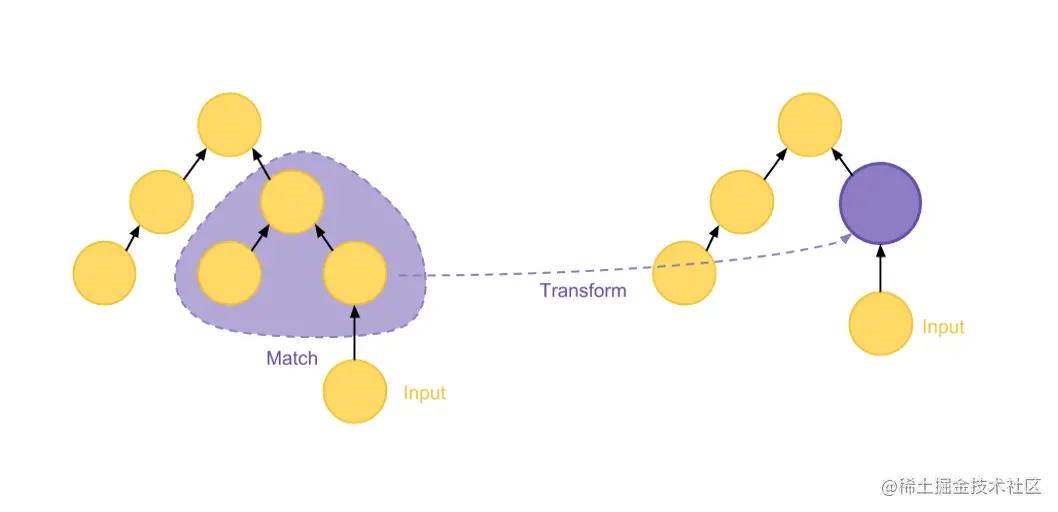
- Pattern:定义了特定结构的 Operator 子树(结构)
- Rule:定义了如何将其匹配的节点替换(Substitute)为新形态,从而生成新的、等价的 Operator 树(原地替换)
- 优化器搜索过程被抽象为不断匹配 Pattern 然后应用 Rule 转换,直到没有可以匹配的 rule
- 根据关系代数等价语义,重写查询
- 基于启发式规则
- 会访问表的元信息 (catalog),不会涉及具体的表数据 (data)
# 关系代数与匹配等价变换
- 运算符:Select (
), Project( ), Join( ), Rename( ), Union( ) - 等价变换:结合律、交换律、传递性
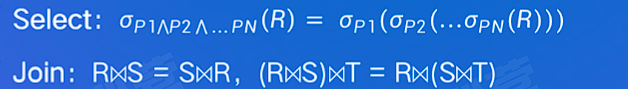
以具体 SQL 做例子:

# 优化原则
- 少读取、快读取:Read data less and faster(I/O)
- 少交换、快交换:Transfer data less and faster(Network)
- 少处理、快处理:Process data less and faster (CPU & Memory)
# 优化方法
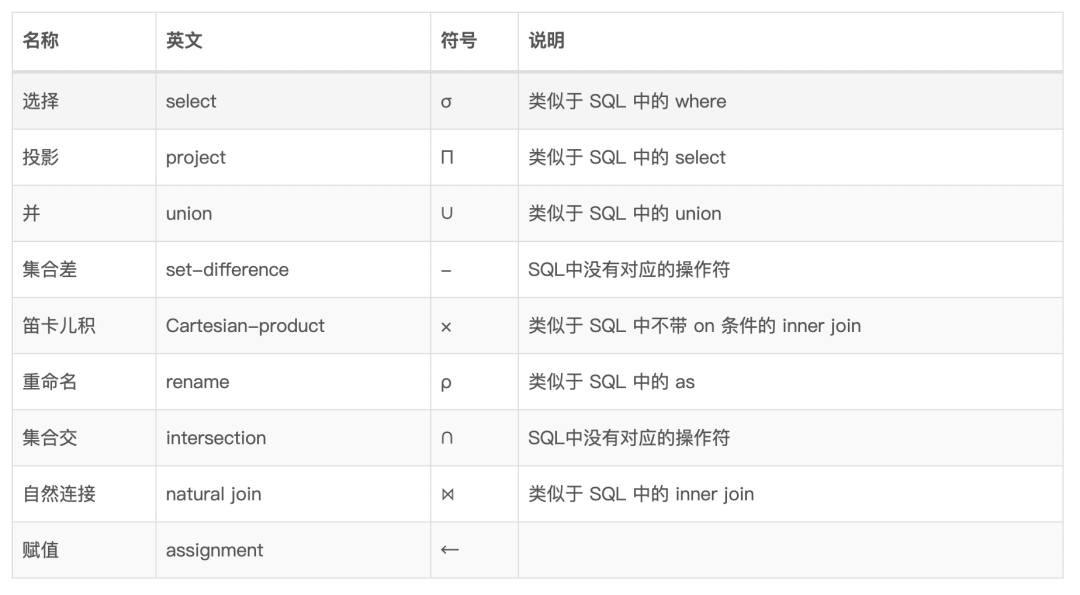
# 列裁剪
- 对于没用到的列,则没有必要读取它们的数据去浪费无谓的 IO
- 列裁剪的算法就是自顶向下的把算子过一遍,某个节点需要用到的列就等于它自己需要用到的列加上它的父节点所需要用到的列。这样得到整个 SQL 语句所涉及到的列,从而再读取数据时只读取需要的列即可。
以下面 SQL 为例进行列裁剪后的计划树,通过判断 SQL 中无用的列 如不参与条件 / 查询的,减少原始表的无用数据
SELECT pv.siteld, user.name
FROM pv JOIN user
ON pv.siteld = user.siteld AND pv.userld = user.id
WHERE user.siteld > 123;
2
3
4
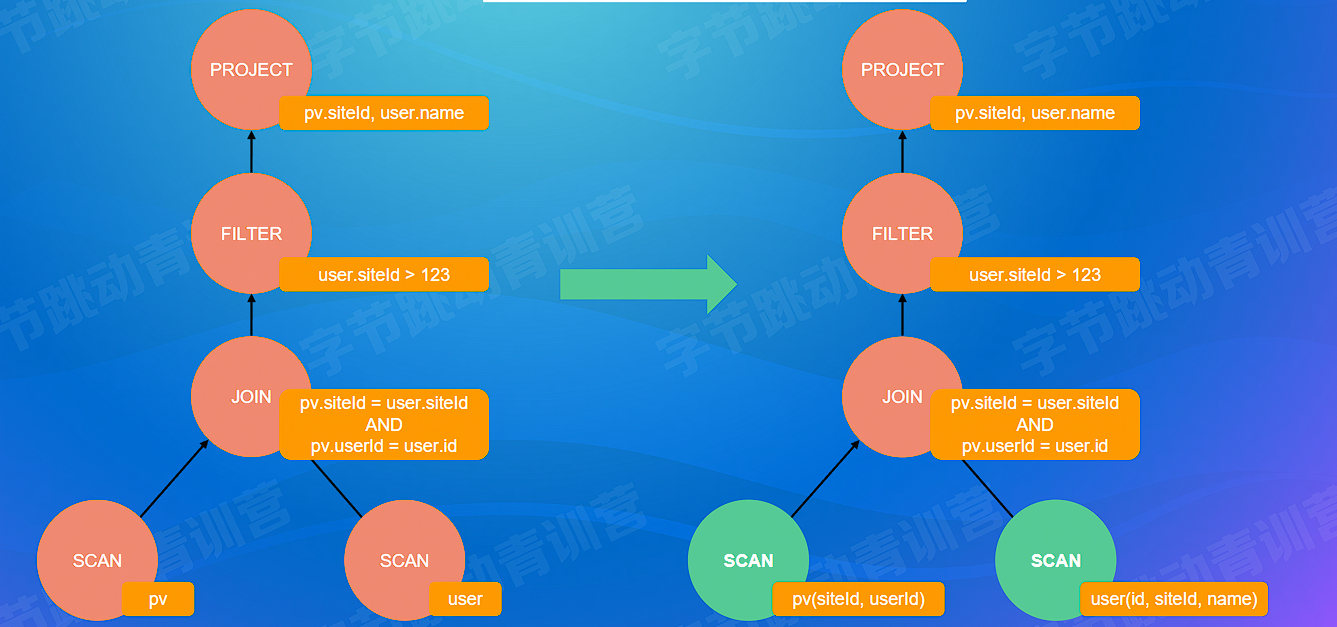
# 谓词下推
谓词即 WHERE 关键字后面的条件
- 将过滤条件进行下推,实现数据提前过滤
- 下推取决于 JOIN 的类型,不同 JOIN 的下推方式实现不同
通过 WHERE user.siteld > 123 条件提前过滤掉不符合的数据,减少中间表的数据量
SELECT pv.siteld, user.name
FROM pv JOIN user
ON pv.siteld = user.siteld AND pv.userld = user.id
WHERE user.siteld > 123;
2
3
4
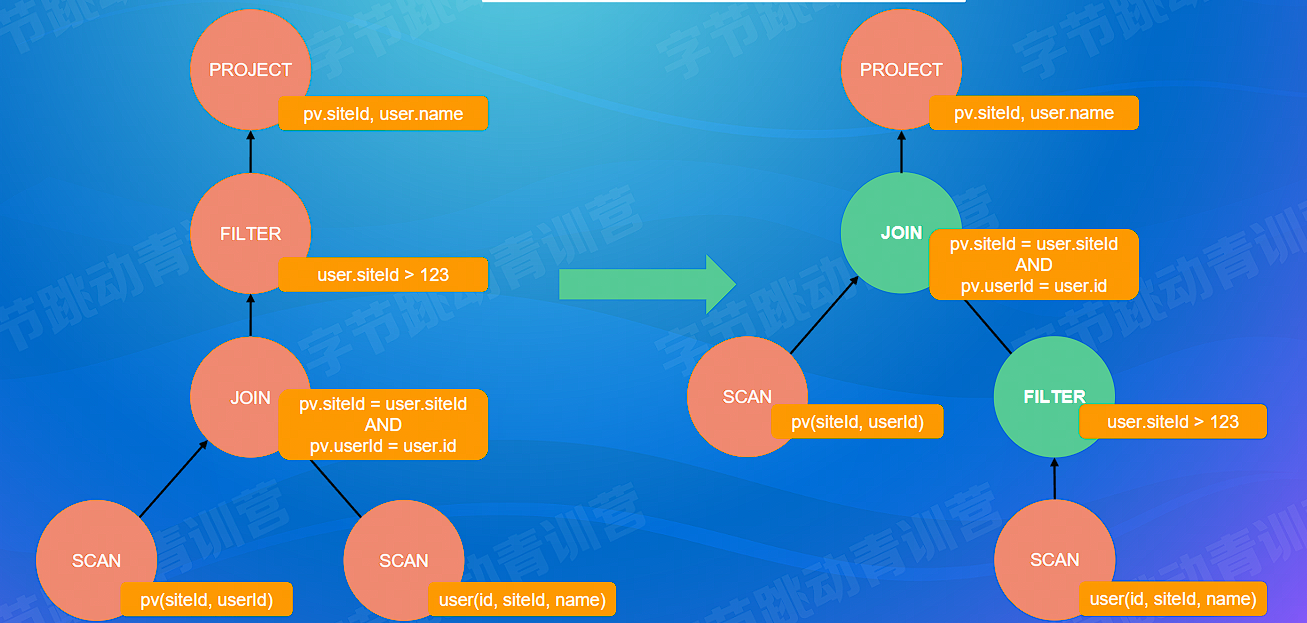
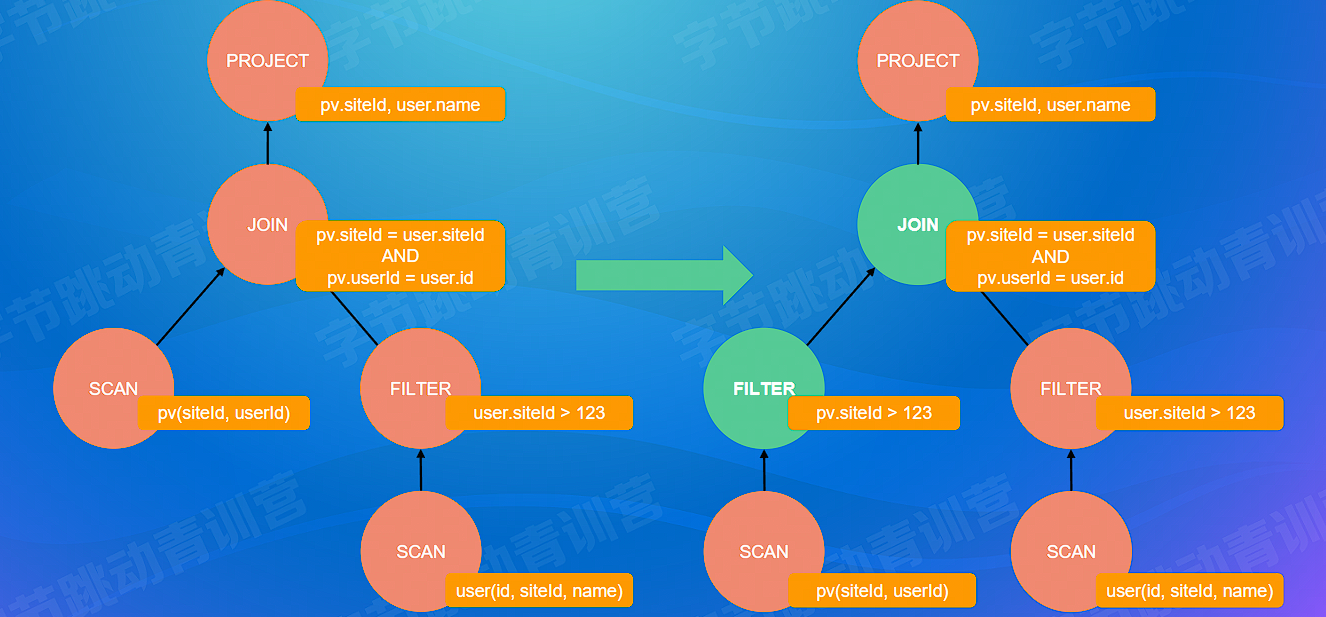
# 传递闭包(高级)
- 根据表达式的等价关系及过滤条件,推导出更全面的过滤条件,实现更加完全的过滤
因 pv 表和 user 表是条件连接, pv.siteld = user.siteld 已经明确该两表的两列要值相等才能进行连接,而我们 WHERE 关键字跟随的条件是 user.siteld > 123 == user.siteld > 123 AND pv.siteld > 123 ,所以我们可以进行传递提前过滤条件
SELECT pv.siteld, user.name
FROM pv JOIN user
ON pv.siteld = user.siteld AND pv.userld = user.id
WHERE user.siteld > 123;
2
3
4
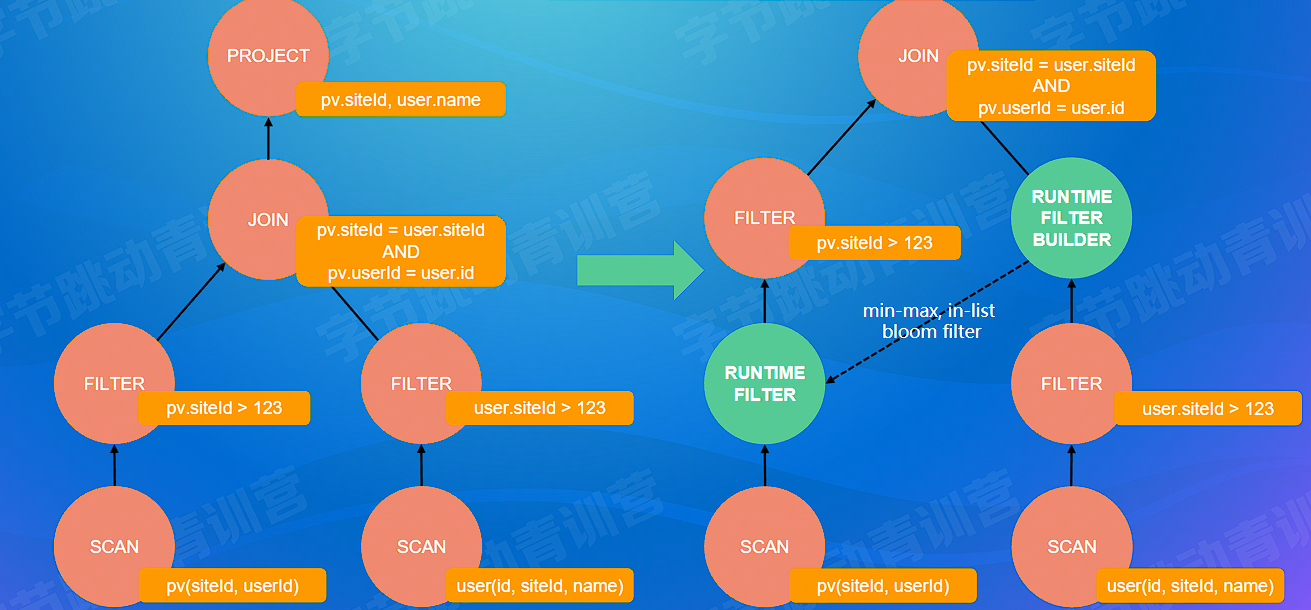
# Runtime Filter
- 运行时才能产生,在数据库中广泛使用
- 在运行中扫描单边时对数据进行简单统计(min-max,in-list,bloom filter)得到扫描的数据范围并提供给另外一边,使得扫描另外半边表时可以得知需要的范围,进行提前过滤,节约数据传输
- min-max 只能处理数据比较集中的情况,如 min-max 数据偏移过大基本和没有 filter 一样
- in-list 只能处理数据可取值相对较小的情况,如果 in-list 中数据量过大通过网络传输的带宽和可靠性也不是可忽略的
- 布隆过滤器:固定大小不像 in-list 大小不可控,标记为不存在则不存在,标记为存在则有可能存在或者可能不存在
# 小结
- 主流 RBO 实现一般都有几百条基于经验归纳得到的优化规则
- 优点:实现简单,优化速度快
- 缺点:不保证得到最优的执行计划
- 单表扫描:索引扫描(随机 I/O)vs. 全表扫描(顺序 I/O)
- 如果查询的数据分布非常不均衡,索引扫描可能不如全表扫描
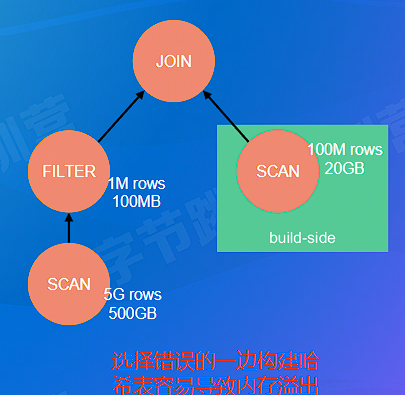
- Join 的实现: Hash Join vs. SortMerge Join
- 两表 Hash Join:用小表构建哈希表 —— 如何识别小表?
- 多表 Join:
- 哪种连接顺序是最优的?
- 是否要对每种组合都探索?
- N 个表连接,仅仅是 left-deep tree 就有差不多 N! 种连接顺序
- e.g. N = 10 -> 总共 3,628,800 个连接顺序
# CBO

- 使用一个模型估算执行计划的代价,选择代价最小的执行计划
- 分而治之,执行计划的代价等于所有算子的执行代价之和
- 通过 RBO 得到(所有)可能的等价执行计划(非原地替换)
- 算子代价包含 CPU,cache misses,memory,disk I/O,network I/O 等代价
- 和算子的统计信息有关,比如输入、输出结果的行数,每行大小等
- 叶子算子 scan:通过统计原始表数据得到
- 中间算子:根据一定的推导规则,从下层算子的统计信息推导得到
- 和具体的算子类型,以及算子的物理实现有关(e.g. hash join vs. sort join)
- Sprak Join 算子代价 =
- 使用动态规划枚或贪心举所有执行计划,选出执行代价最小的执行计划
# 统计信息
原始表统计信息
- 表或者分区级别:行数、行平均大小、表在磁盘中占用了多少字节等
- 列级别: min、max、num nulls、num not nulls、 num distinct value (NDV)、histogram 等
推导统计信息
- 选择率 (selectivity) : 对于某一个过滤条件,查询会从表中返回多大比例的数据
- 基数(cardinality):在查询计划中常指算子需要处理的行数
统计信息的收集方式

# 统计信息推导规则:假设列和列之间是独立的,列的值均匀分布
- Filter Selectivity (fs 选择率)
- AND 条件:
- OR 条件:$ fs (a\ OR\ b)=fs (a)+fs (b)-(fs (a)*fs (b))$
- NOT 条件:
- 等于条件(x = literal):
&& :0 即 literal 不在 范围中自然没有符合条件的行
- 小于条件 (x < literal):
: 1
- AND 条件:
- Filter Selectivity (fs 选择率)
统计信息的问题:
- 假设列列独立,列值均匀分布。这个假设与现实不符
- 列列之间可以关联:用户指定 / 数据库自动识别相关联的列
- 列值不是均匀分布:使用直方图处理
# CBO 在 MySQL 中
MySQL 中的 COST Model , COST Model 就是优化器用来统计各种步骤的代价模型,在 5.7.10 版本之后,MySQL 会引入两张数据表,里面规定了各种步骤预估的代价(Cost Value) ,我们可以从 mysql.server_cost 和 mysql.engine_cost 这两张表中获得这些步骤的代价:
SELECT * FROM mysql.server_cost
server_cost 数据表是在 server 层统计的代价,具体的参数含义如下:
disk_temptable_create_cost,表示临时表文件(MyISAM 或 InnoDB)的创建代价,默认值为 20。disk_temptable_row_cost,表示临时表文件(MyISAM 或 InnoDB)的行代价,默认值 0.5。key_compare_cost,表示键比较的代价。键比较的次数越多,这项的代价就越大,这是一个重要的指标,默认值 0.05。memory_temptable_create_cost,表示内存中临时表的创建代价,默认值 1。memory_temptable_row_cost,表示内存中临时表的行代价,默认值 0.1。row_evaluate_cost,统计符合条件的行代价,如果符合条件的行数越多,那么这一项的代价就越大,因此这是个重要的指标,默认值 0.1。
看下在存储引擎层都包括了哪些代价:
SELECT * FROM mysql.engine_cost
engine_cost 主要统计了页加载的代价,我们之前了解到,一个页的加载根据页所在位置的不同,读取的位置也不同,可以从磁盘 I/O 中获取,也可以从内存中读取。因此在 engine_cost 数据表中对这两个读取的代价进行了定义:
io_block_read_cost,从磁盘中读取一页数据的代价,默认是 1。memory_block_read_cost,从内存中读取一页数据的代价,默认是 0.25。
既然 MySQL 将这些代价参数以数据表的形式呈现给了我们,我们就可以根据实际情况去修改这些参数。因为随着硬件的提升,各种硬件的性能对比也可能发生变化,比如针对普通硬盘的情况,可以考虑适当增加 io_block_read_cost 的数值,这样就代表从磁盘上读取一页数据的成本变高了。当我们执行全表扫描的时候,相比于范围查询,成本也会增加很多。
比如我想将 io_block_read_cost 参数设置为 2.0,那么使用下面这条命令就可以:
UPDATE mysql.engine_cost SET cost_value = 2.0 WHERE cost_name = 'io_block_read_cost';FLUSH OPTIMIZER_COSTS;
如果我们想要专门针对某个存储引擎,比如 InnoDB 存储引擎设置 io_block_read_cost ,比如设置为 2,可以这样使用:
INSERT INTO mysql.engine_cost(engine_name, device_type, cost_name, cost_value, last_update, comment) VALUES ('InnoDB', 0, 'io_block_read_cost', 2, CURRENT_TIMESTAMP, 'Using a slower disk for InnoDB');FLUSH OPTIMIZER_COSTS;
在论文《Access Path Selection-in a Relational Database Management System》 (opens new window)中给出了计算模型,如下图所示:
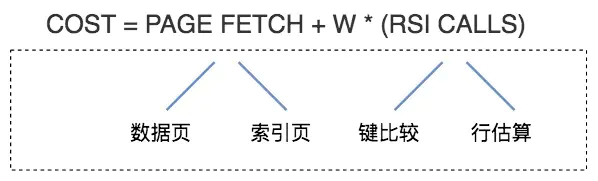
你可以简单地认为,总的执行代价等于 I/O 代价 +CPU 代价。在这里 PAGE FETCH 就是 I/O 代价,也就是页面加载的代价,包括数据页和索引页加载的代价。
# CBO 效果
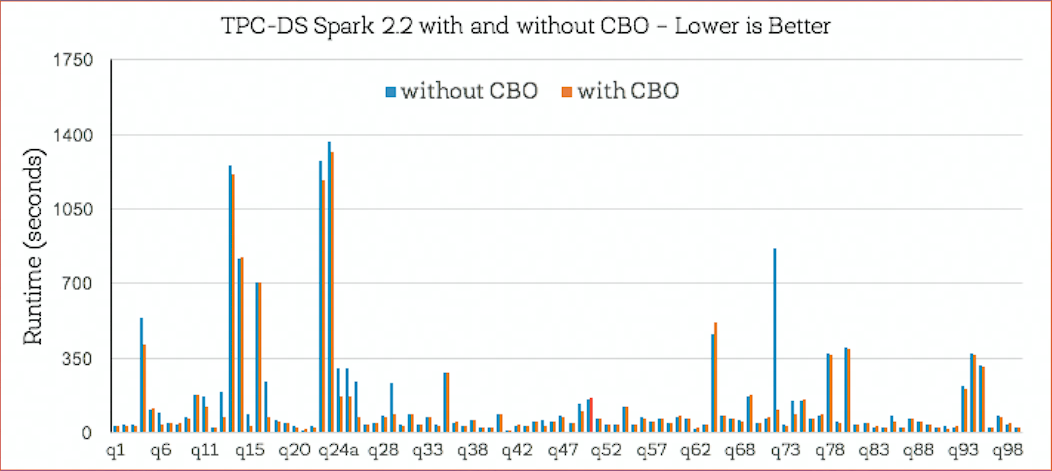
- 关闭 CBO:shuffle 数据量太大,执行效率差
- 开启 CBO:减少 90% shuffle 数据量,加速 3.4 倍
- 大概一半的查询无性能变化:RBO 能找到最优执行计划;但 16 个查询在 CBO 下有更好的执行性能(总体性能提升 30%,加速比 2.2X~8X)
# 小结
- CBO 使用代价模型和统计信息估算执行计划的代价
- CBO 使用贪心或者动态规划算法寻找最优执行计划
- 在大数据场景下 CBO 对查询性能非常重要
# Top-Down & Bottom-up Optimizer
Top-Down:
- 从目标输出开始,由上往下遍历计算树,找到完整的最优执行计划
- 如:Volcano/Cascade,SQLServer
Bottom-Up:
- 从零开始,从下往上遍历计划树,找到完整的执行计划
- 如:System R,PostgreSQL,IBM DB2
# 小结
- 主流 RBO 实现一般都有几百条基于经验归纳得到的优化规则
- RBO 实现简单,优化速度快
- RBO 不保证得到最优的执行计划
- CBO 使用代价模型和统计信息估算执行计划的代价
- CBO 使用贪心或者动态规划算法寻找最优执行计划
- 大数据场景下 CBO 对查询性能非常重要
参考文章:
SQL 必知必会 (查询优化器) (opens new window)
《Access Path Selection-in a Relational Database Management System》 (opens new window)
# 查询优化器的社区开源介绍
| 数据库 | SQL Optimizer 选型 |
|---|---|
| Hive、Flink、Alibaba MaxCompute 等 | 基于 Apache Calcite,属于 Volcano/Cascade 框架 |
| Greenplum、HAWQ | 自研 Orca,属于 Volcano/Cascade 框架 |
| Alibaba Hologres(定位 HSAP) | 基于 Orca,属于 Volcano/Cascade 框架 |
| TiDB | 自研,属于 Volcano/Cascade 框架 |
| Spark | 自研,RBO+CBO |
| Presto | 自研,RBO+CBO |
| Doris | 自研,RBO+CBO |
| ClickHouse | 自研,RBO |
| Alibaba OceanBase | 自研,RBO+CBO |
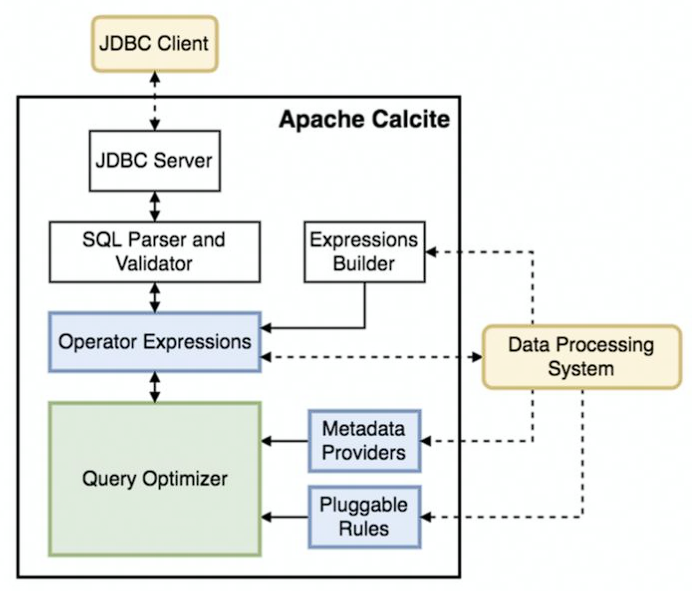
# Apache Calcite 概览
One size for all:统一的 SQL 查询引擎
模块化,插件化,稳定可靠
支持异构数据模型:
- 关系型
- 半结构化
- 流式
- 地理空间数据
内置 RBO,CBO
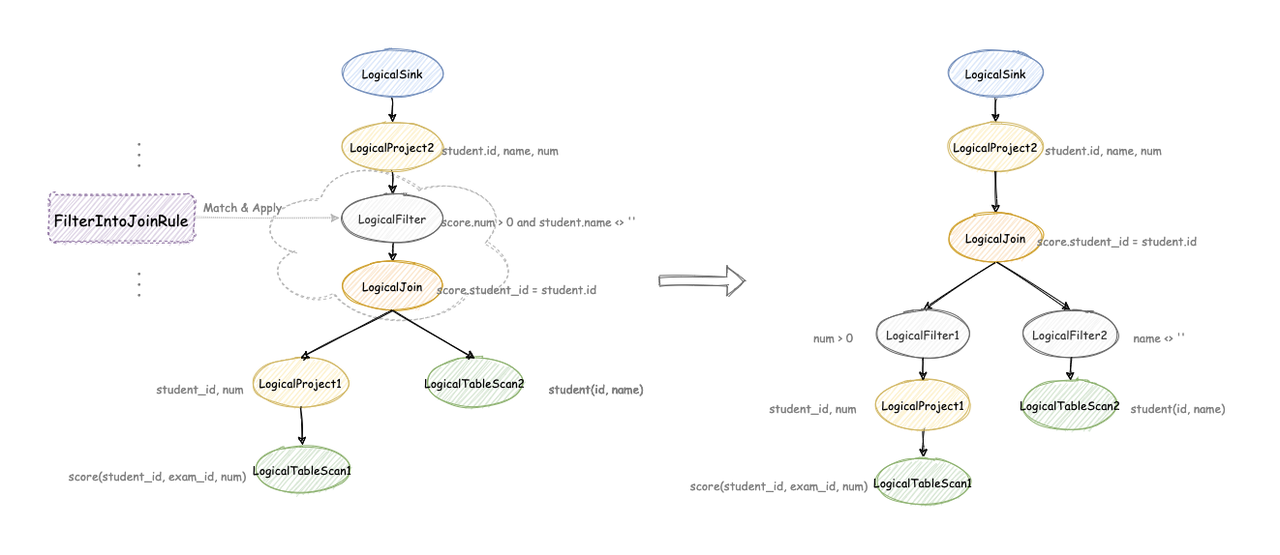
# Calcite RBO
- HepPlanner
- 优化规则(Rule)
- Pattern: 匹配表达式子树
- 等价变换:得到新的表达式
- 内置有 100 + 优化规则
- 四种匹配规则
- ARBITRARY/DEPTH_FIRST : 深度优先
- TOP_DOWN:拓扑顺序
- BOTTOM UP: 与 TOP DOWN 相反
- 遍历所有的 rule,直到没有 rule 可以被触发
- 优化速度快,实现简单,但是不保证最优
- 优化规则(Rule)
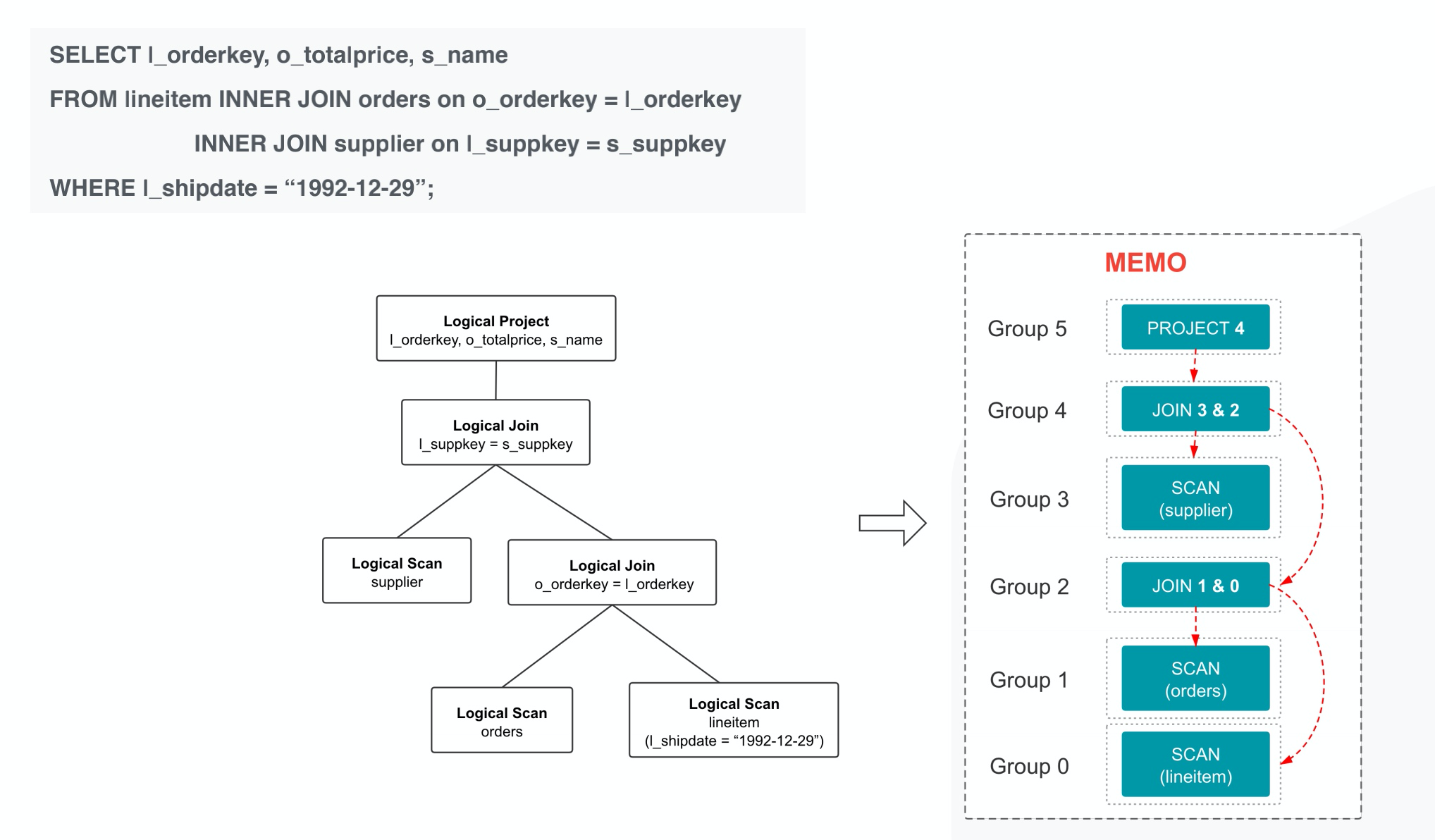
# Calcite CBO
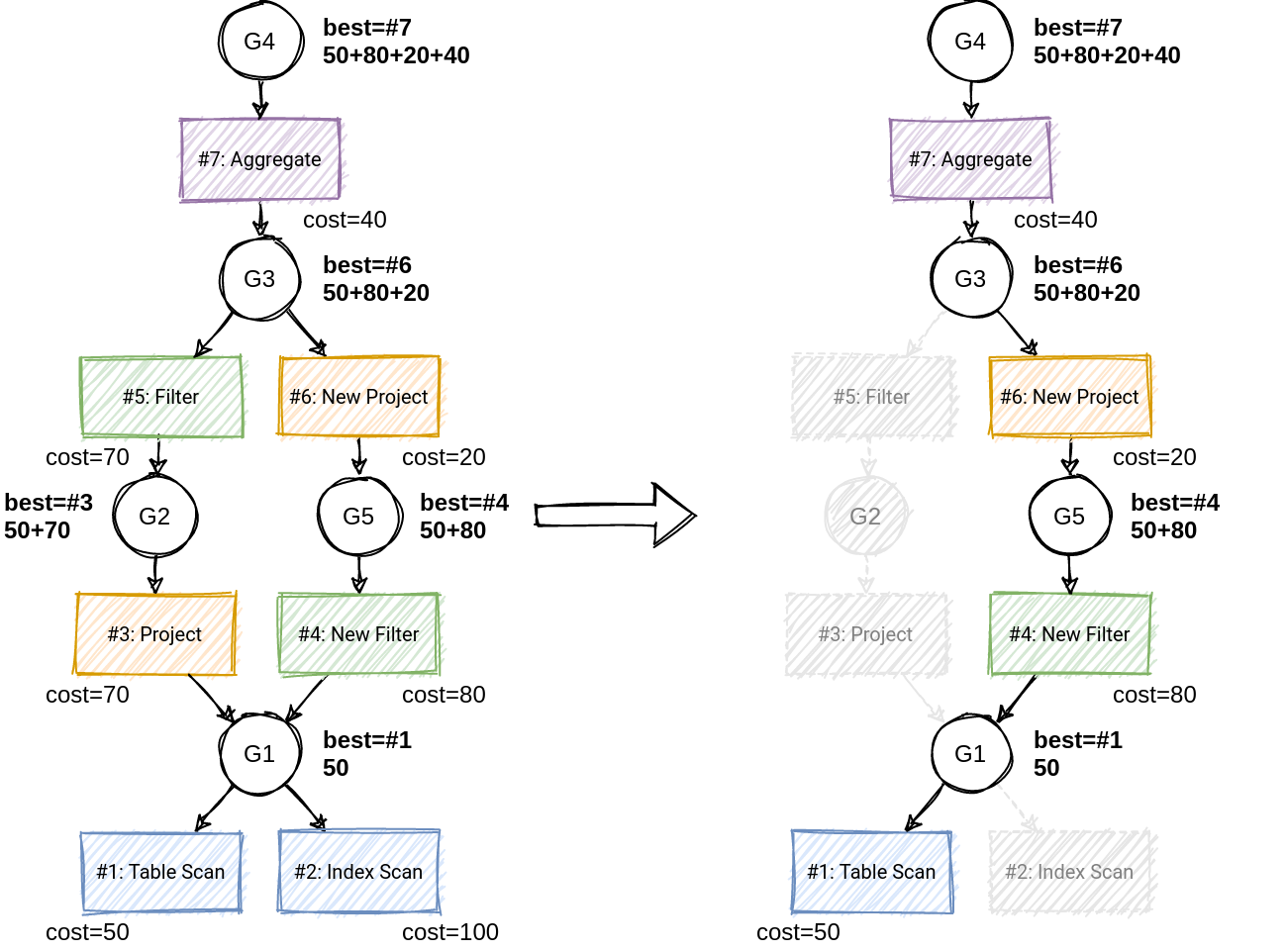
- VolcanoPlanner
- 基于 Volcano/Cascade 框架
- 成本最优假设
- 应用 Rule 搜索候选计划
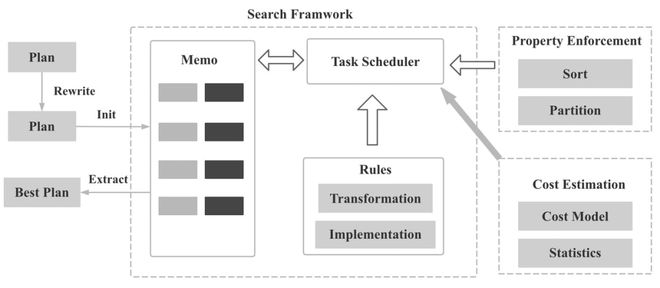
- Memo:存储侯运执行计划(相对应缓存表 /dp 表)
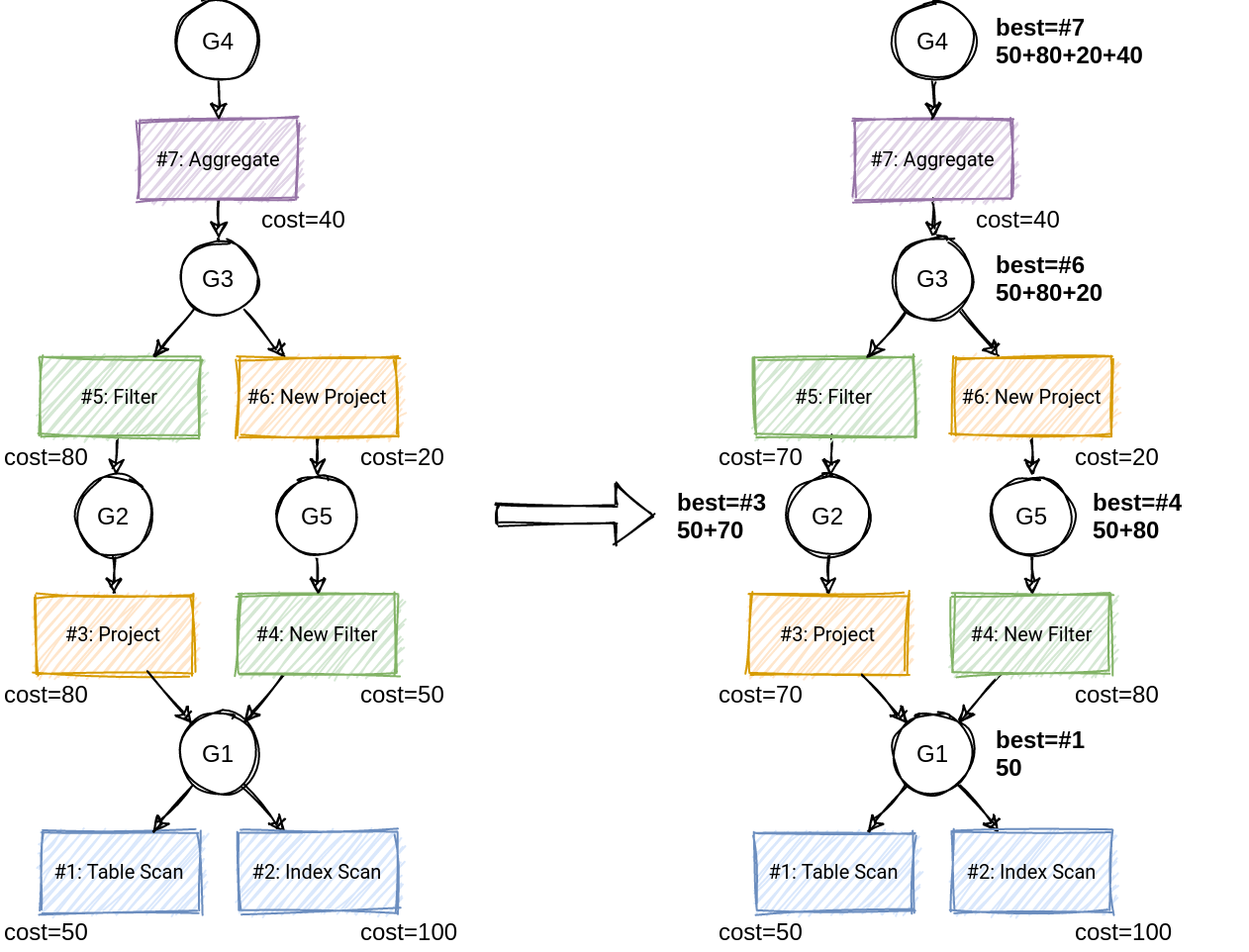
- Group:等价计划集合
- 本质: AND/OR graph
- 共享子树减少内存开销
- Group winner:记录目前的最优计划
- 剪枝(branch-and-bound pruning)减少搜索空间,即当前策略 cost 大于目前最优计划直接结束,无需继续下推计划树
- Top-down 动态规划搜索:选择 winner 构建最优执行计划
# 小结
- 主流的查询优化器都包含 RBO 和 CBO
- Apache Calcite 是大数据领域很流行的查询优化器
- Apache Calcite RBO 定义了许多优化规则,使用 pattern 匹配子树,执行等价变换
- Apache Calcite CBO 基于 Volcano/Cascade 框架
- Volcano/Cascade 的精髓: Memo、动态规划、剪枝
# SQL 相关的前沿趋势
存储计算分离
一体化(HTAP, HSAP, HTSAP)
Serverless,K8S
数据仓库,数据湖,湖仓一体,联邦查询
DATA + AI
- AI4DB
- 自配置:
- 智能调参(OtterTune (opens new window),QTune (opens new window))
- 负载预测 / 负载调度
- 自诊断和自愈合:软硬件错误、错误恢复和迁移
- 自优化:
- 统计信息估计( Learned cardinalities (opens new window))
- 代价估计
- 学习型优化器(IBM DB2 LEO (opens new window))
- 索引 / 视图推荐
- 自配置:
- DB4AI
- 内嵌人工智能算法(MLSQL,SQLFlow)
- 内嵌机器学习框架(SparkML, Alink, dl-on-flink )
- AI4DB
# 课后总结
- 大数据创业如火如荼,SQL 查询优化器仍然是必不可少的一个重要组件
- 引擎架构的进化、 云原生、 湖仓一体等对 SQL 查询优化器有新的要求和挑战
- Al 加持,学习型查询优化器在不断进化