浅谈分布式一致性协议| 青训营笔记
浅谈分布式一致性协议| 青训营笔记
# 浅谈分布式一致性协议| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第 15 天
# 分布式系统
# 分布式系统面临的挑战
- 数据规模越来越大
- 服务的可用性要求越来越高
- 快速迭代的业务要求系统足够易用
- 各种各样的错误
- 网络
- 磁盘
- CPU
# 理想中的分布式系统
- 高性能:可拓展、低时延、高吞吐
- 正确:一致性、易于理解
- 可靠:容错、高可用
# 从 HDFS 开始
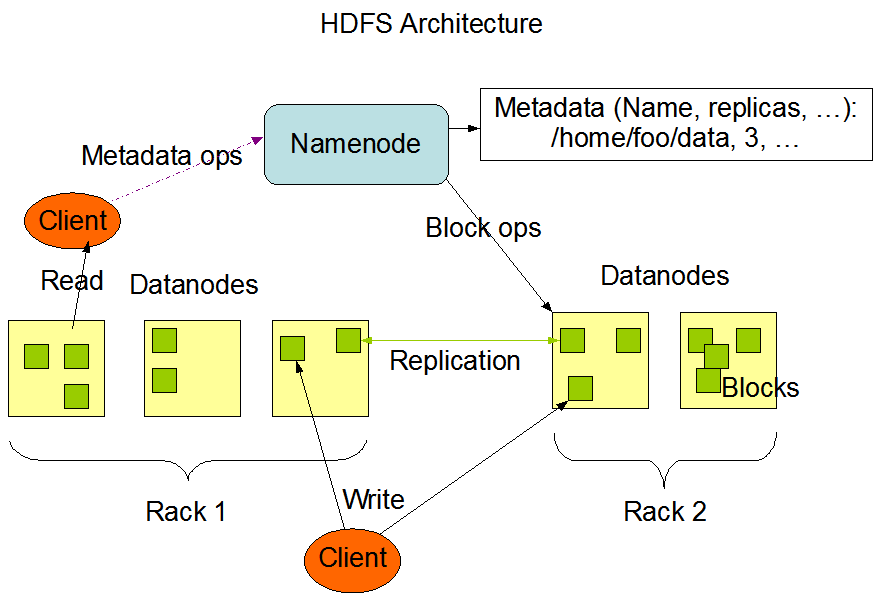
# 案例 - KV
- 从最简单机 KV 开始
- 接口:
- Get(key) -> value
- BaichPut(ki,k2,...1. [v1,v2,...])
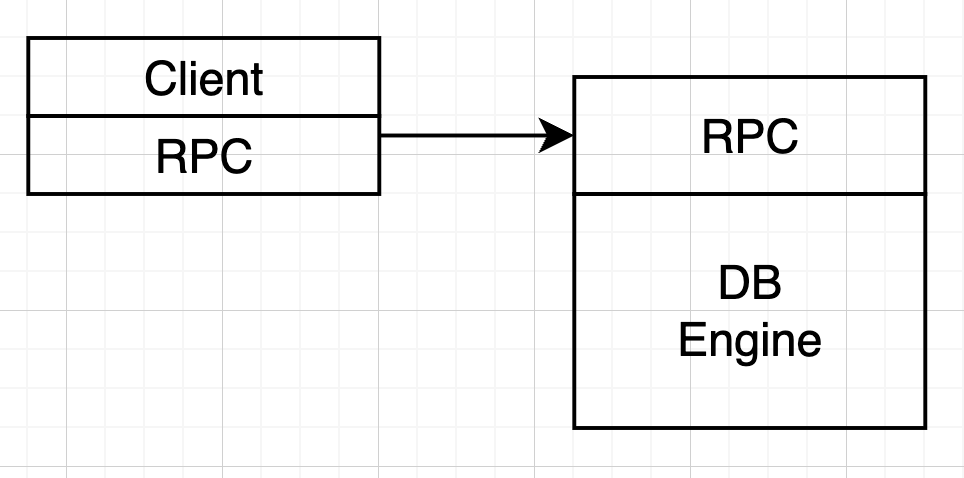
- 第一次实现
- RPC
- DB Engine
此时我们的简单 KV 没有容错和高可用可言,但由于是单进程,所有操作顺序执行,正确性保证。
# 一致性与共识算法
# 从复制开始
我们目的是设计一个可靠的 KV,就需要容错性,使用多台机器,设计分发副本。
既然一台机器会挂
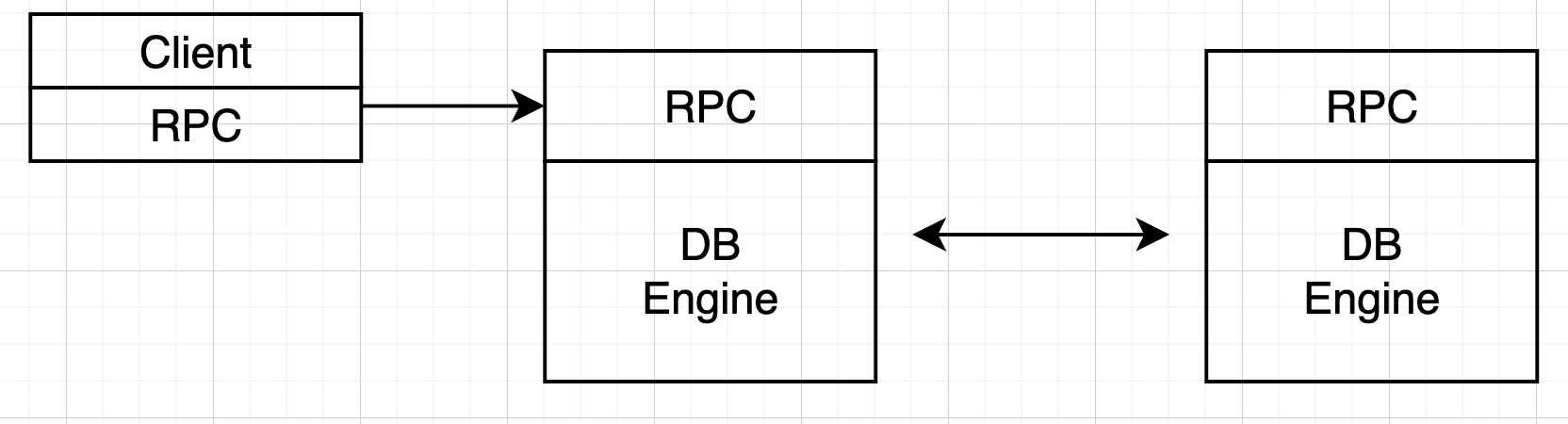
如果两个副本都能接受请求,多个副本之间交叉复制,系统过庞大。
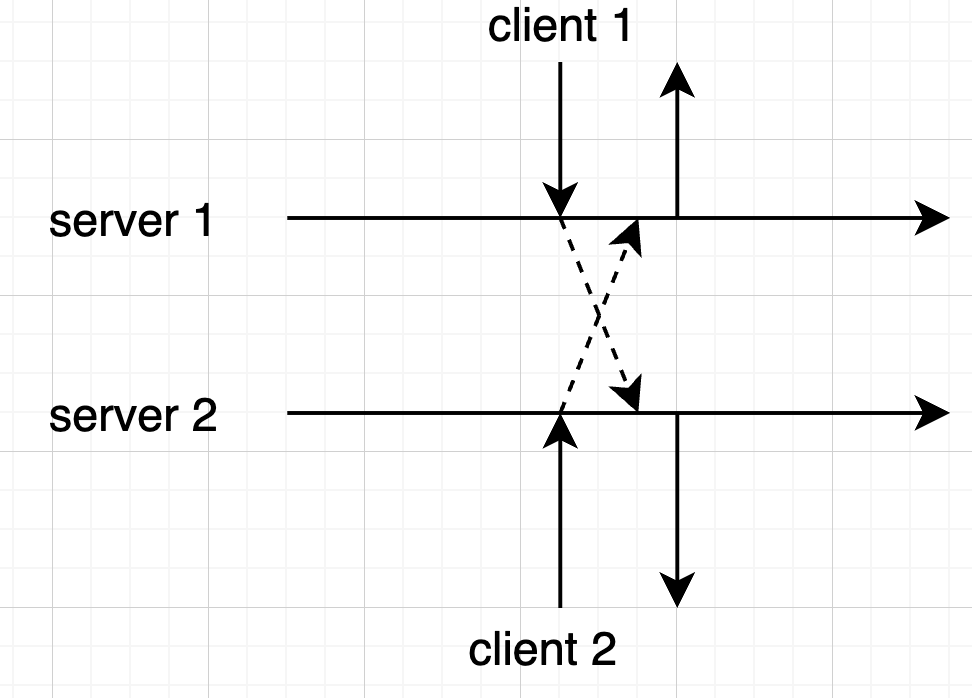
# 如何复制
- 主副本定期拷贝全量数据到从副本,不排除主副本挂掉未能及时拷贝副本。
- 主副本拷贝操作到从副本
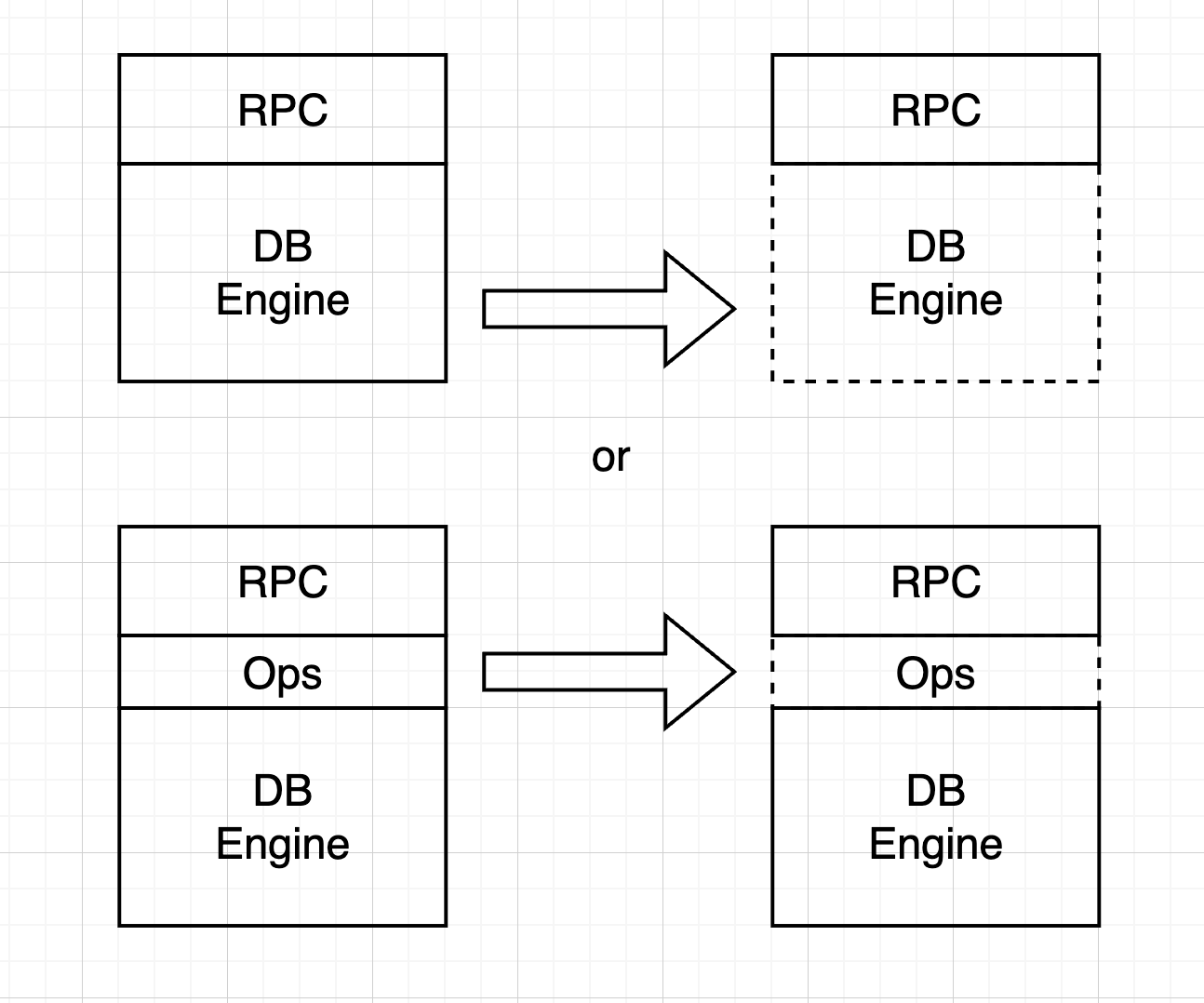
# 如何复制操作
- 主副本把所有的操作打包成 Log
- 所有的 Log 写入都是持久化的,保存在磁盘上
- 应用包装成状态机,只接收 Log 作为 Input
- 主副本确认 Log 已经成功写入到副本机器上,当状态机 apply 后,返回客户端
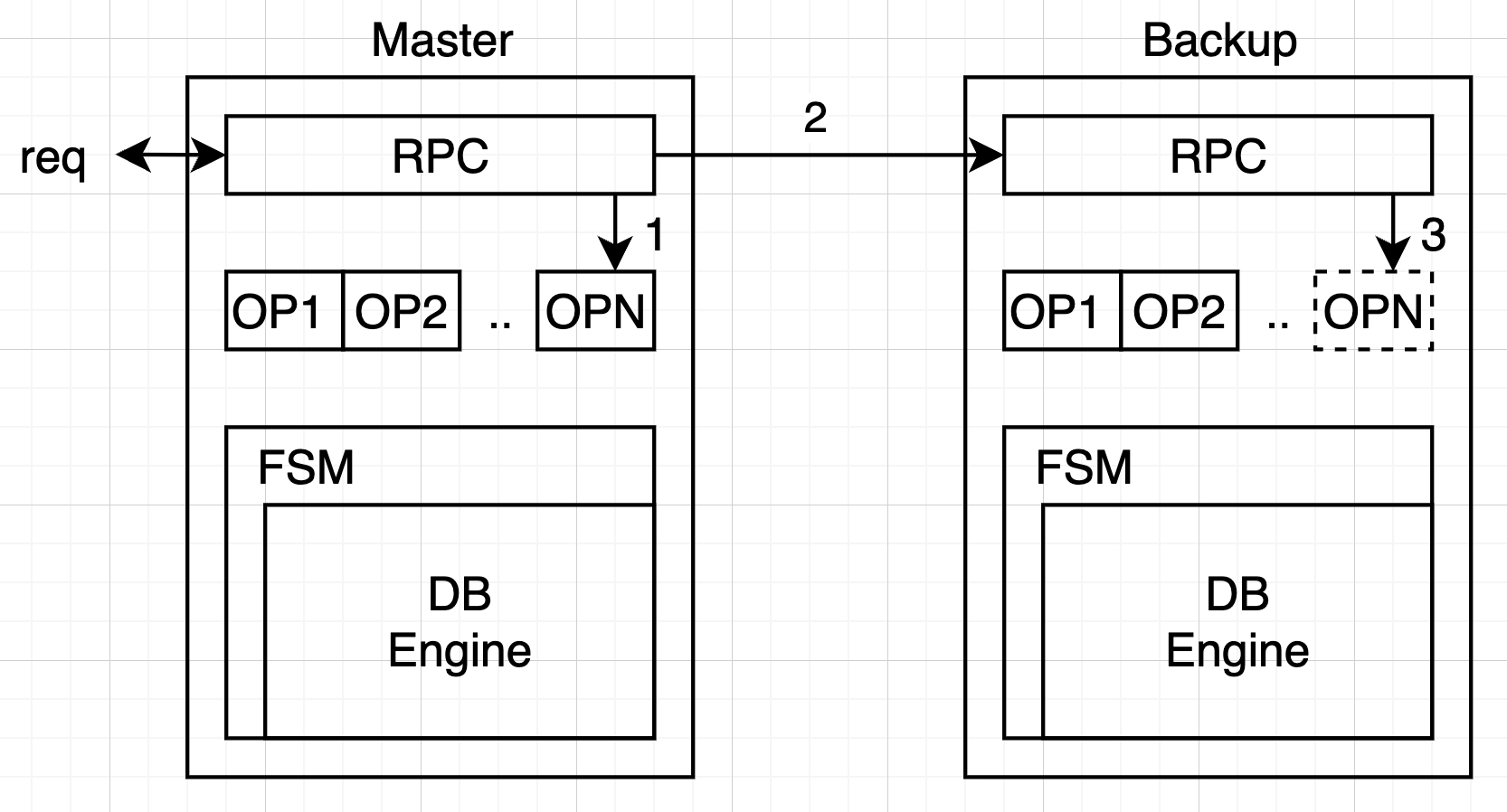
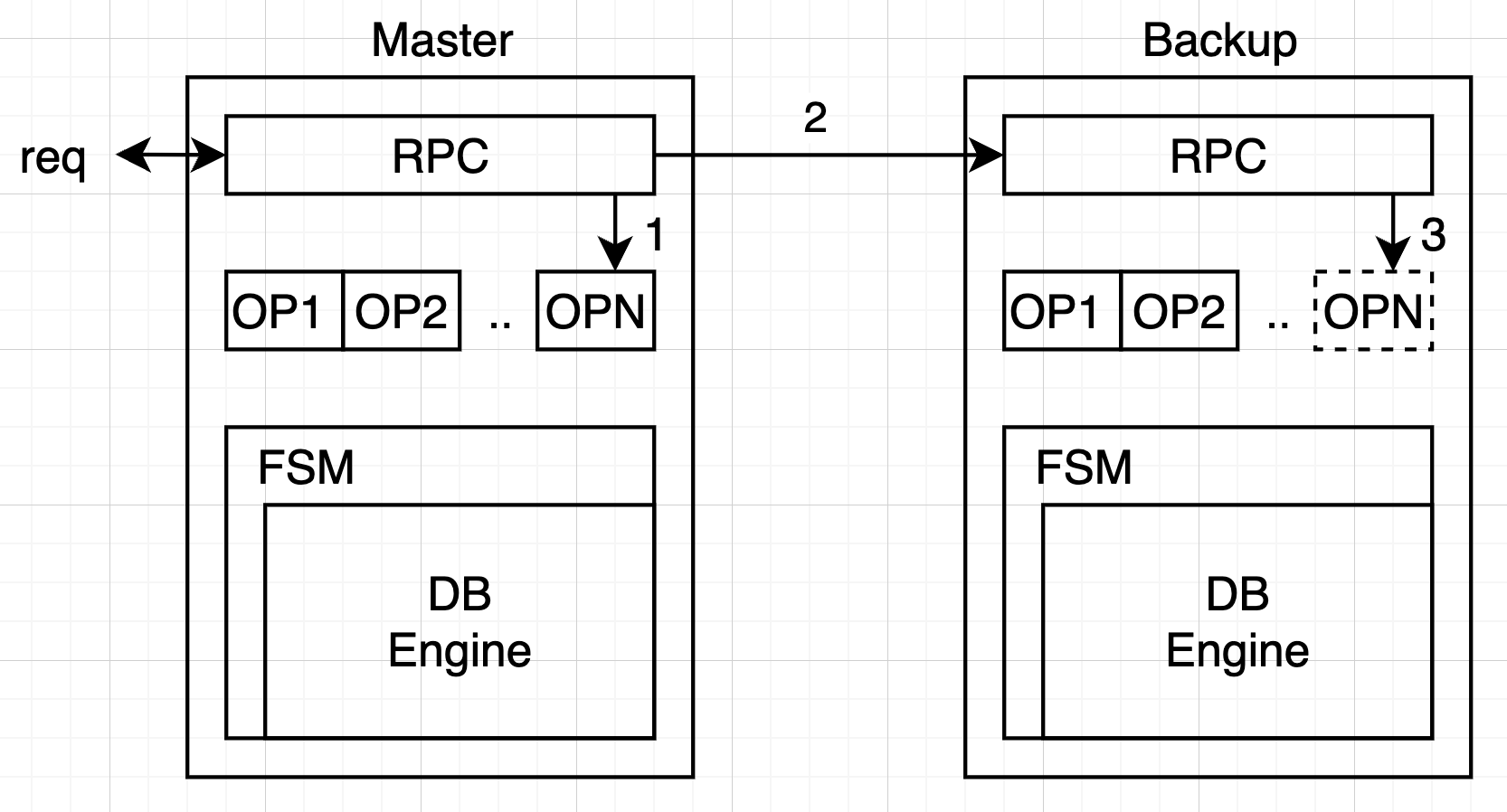
# 关于读操作
- 方案一:直接读状态机,要求写操作进入状态机后再返回 client
- 方案二:写操作复制完成后直接返回,读操作 Block 等待所有 pending log 进入状态机
如果不遵循上述两周方案,可能存在刚刚写入的值读不到的情况(在 Log 中)。
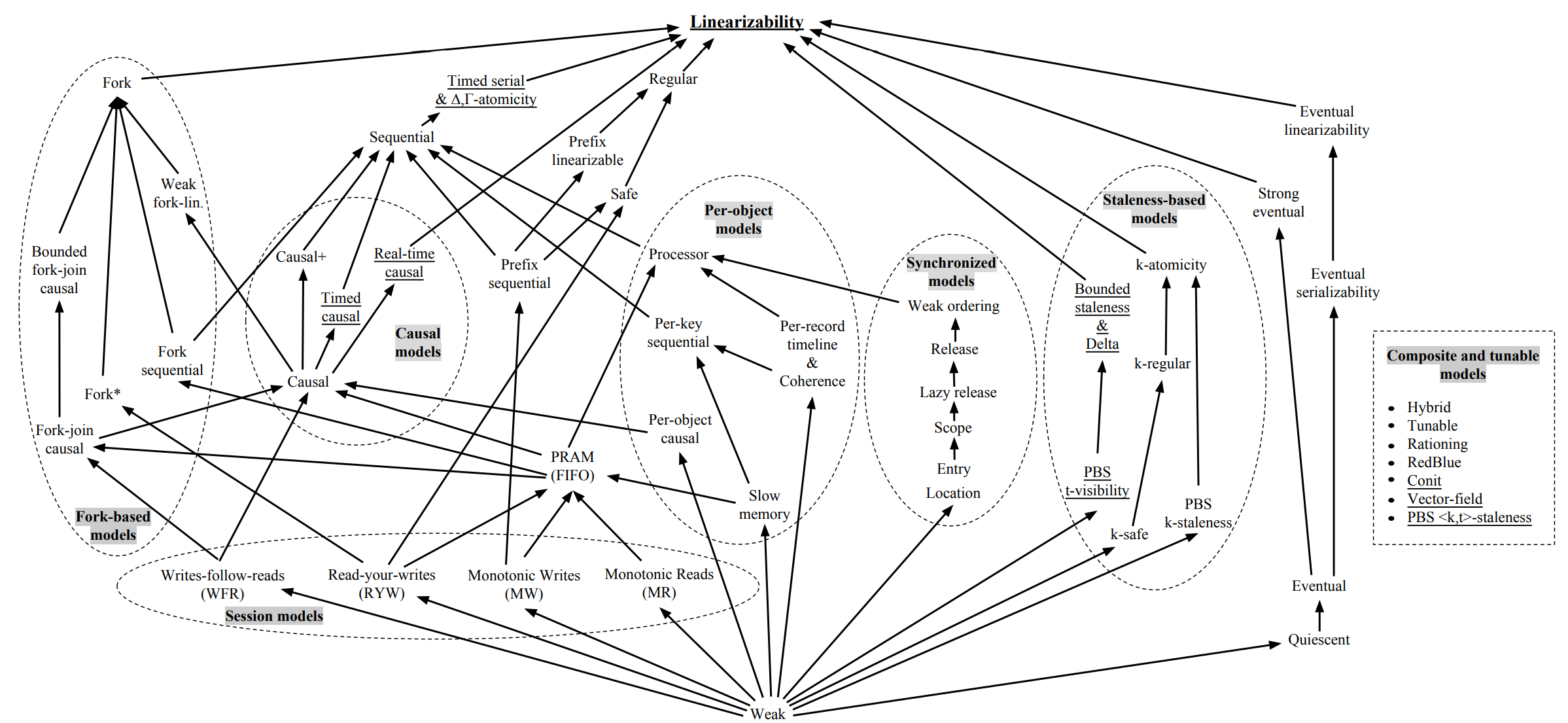
# 什么是一致性 - 1
- 对于我们的 KV
- 像操作一台机器一样
- 要读到最近写入的值
- 像操作一台机器一样
- 一致性是一种模型(或语义)
- 来约定一个分布式系统如何向外界(应用)提供服务
- KV 中常见的一致性模型
- 最终一致性∶读取可能暂时读不到但是总会读到
- 线性一致性:最严格,线性执行
# 什么是一致性 - 2
- 一致性的分类
- 经常与应用本身有关
- Linearizability 是最理想的
# 复制协议 - 当失效发生
当主副本失效:
- 手动切换
- 容错?
- 不,我们的服务还是停了
- 高可用?
- 也许,取决于我们从发现到切换的过程的有多快
- 正确?
- 操作只从一台机器上发起
- 所有操作返回前都已经复制到另一台机器了
小结:
- 当主副本失效时,为了使得算法简单
- 我们人肉切换,只要足够快
- 我们还是可以保证较高的可用性。
- 我们人肉切换,只要足够快
- 但是如何保证主到本是真的失效了呢?
- 在切换的过程中,主副本又开始接收 client 端的请求
- 两个主副本显然是不正确的,log 会被覆盖写掉
- 我们希望算法能在这种场景下仍然保持正确
- 要是增加到三个节点呢?
- 每次都等其他节点操落盘性能较差
- 能不能允许少数节点挂了的情况下,仍然可以工作
剩
- falut-tolerance
# 共识算法
什么是共识算法:
"The consensus problem requires agreement among a number of processes (or agents) for a single data value. Some of the processes (agents) may fail or be unreliable in other ways, so consensus protocols must be fault tolerant (opens new window) or resilient"
简而言之一个值一旦确定,所有人都认同。
有文章证明是一个不可能的任务 (FLP impossibility)
"In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. We do not consider Byzantine failures, and we assume that the message system is reliableit delivers all messages correctly and exactly once." --JACM 85 [1]
错误总是发生
- Non-Byzantine fault
错误类型很多
- 网络断开,分区,缓慢,重传,乱序
- CPU、IO 都机会停住
容错(falute-tolerance)
- 共识协议不等于一致性
- 应用层面不同的一致性,都可以用共识协议来实现
- 比如可以故意返回旧的值
- 简单的复制协议也可以提供线性一致性
- 应用层面不同的一致性,都可以用共识协议来实现
- 一般讨论共识协议时提到的一致性,都指线性一致性
- 因为弱一致性往可以使用相对简单的复制算法实现
# 一致性协议案例: Raft
# Paxos
The Part-Time Parliamen by Lamport 1989
- 也就是人们提到的 Paxos
- 基本上就是一致性协议的的同义词
- 该算法的正确性是经过数学证明的
那么问题解决了吗?
- Paxos 是出了名的难以理解,Lamporr 本人在 01 年又写了一篇 PaxosMade Smple
- "The Paxos Algorighm, when presented in plain English, is very simple."
- 算法整体是以比较抽象的形式描述,工程实现时需要做一些修改
- Google 在实现 Chubby 的时候是这样描述的
- here are significant gaps between the description of the Paxos algorithm and the needs of a real-world system ... the mal system will be based on an unproven protocol.
# Raft
- 2014 年发表
- 易于理解作为算法的设计目标
- 使用了 RSM、Log、RPC 的概念
- 直接使用 RPC 对算法进行了描述
- Strong Leader-based
- 使用了随机的方法减少约束
- 正确性
- 形式化验证
- 拥有大量成熟系统

# 复制状态机 (RSM)
- RSM (replicated state machine)
- Raft 中所有的 consensus 都是直接使用 Log 作为载体
- Commited Index
- 一旦 Raft 更新 Commited Index,意味着这个 Index 前的所有 Log 都可以提交给状态机了
- Commited Index 是不持久化的,状态机也是 volatile 的,重启后从第一条 Log 开始
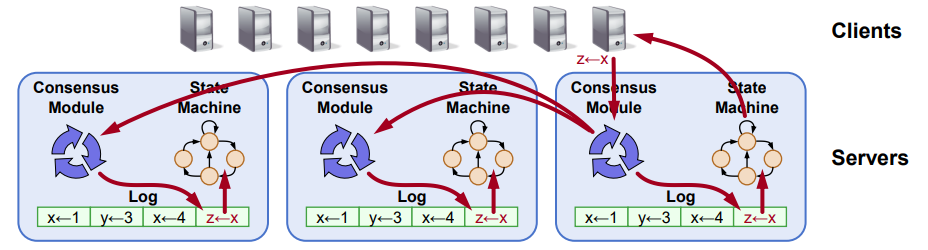
# Raft 角色
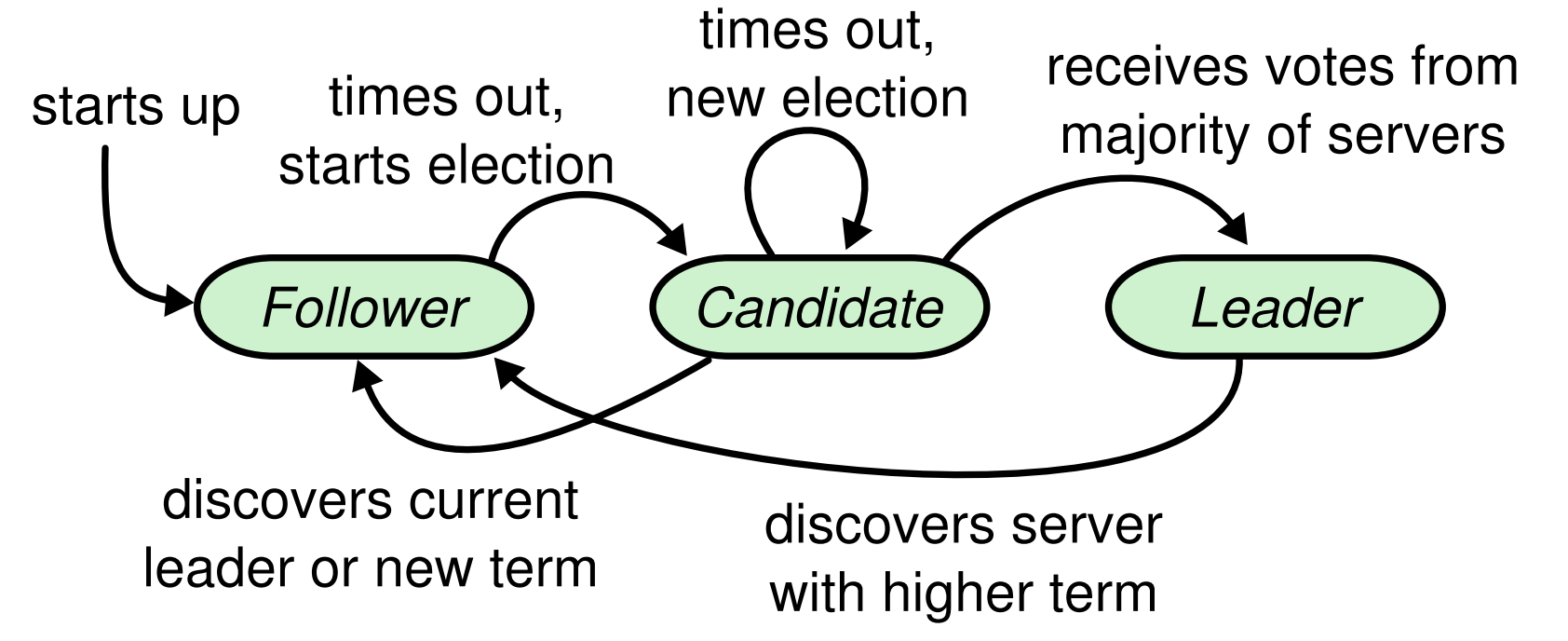
# Raft 日志复制
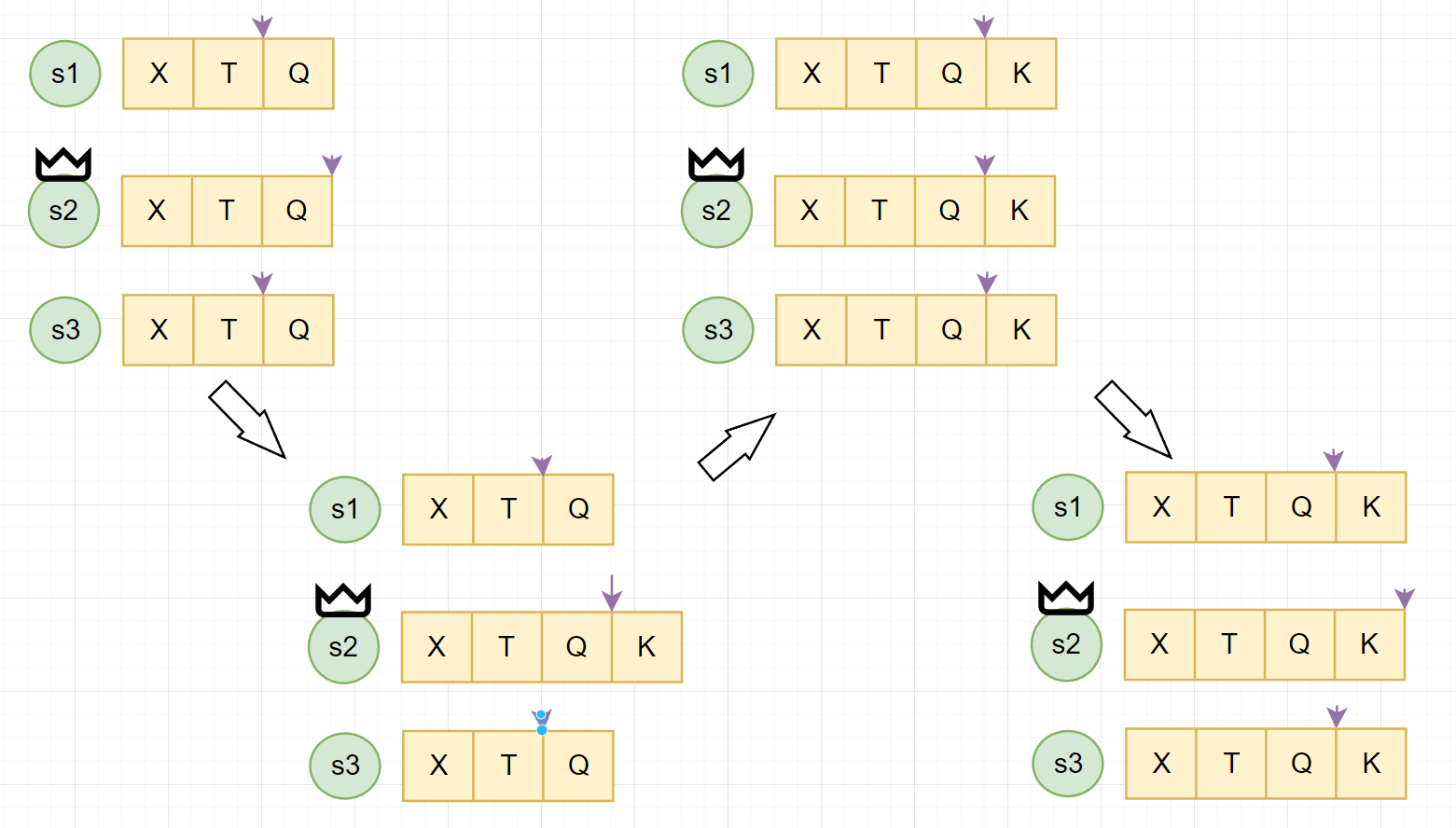
# Raft 从节点失效
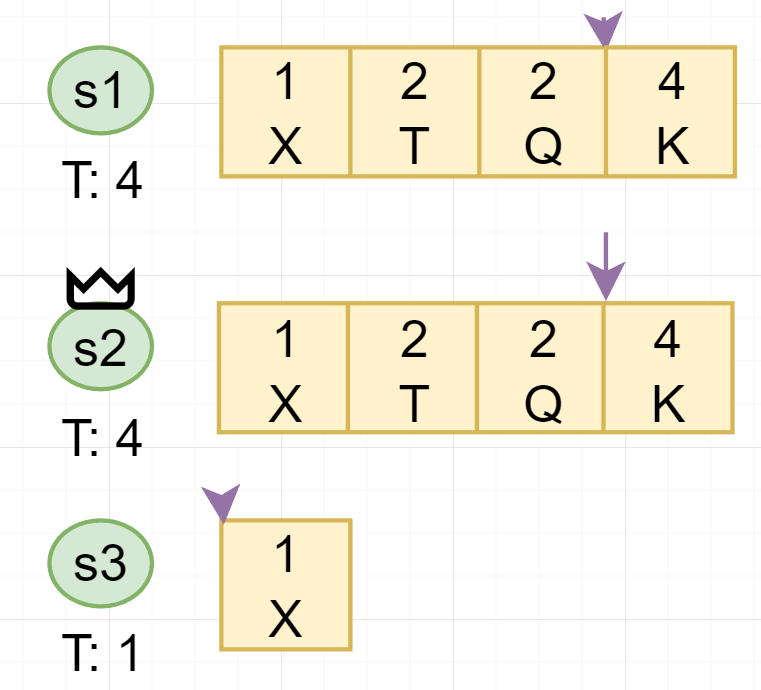
# Raft Term
- 每个 Leader 服务于一个 term
- 每个 term 至多只有一个 leader
- 每个节点存储当前的 term
- 每个节点 term 从一开始,只增不减
- 所有 rpc 的 request reponse 都携带 term
- 只 commit 本 term 内的 log
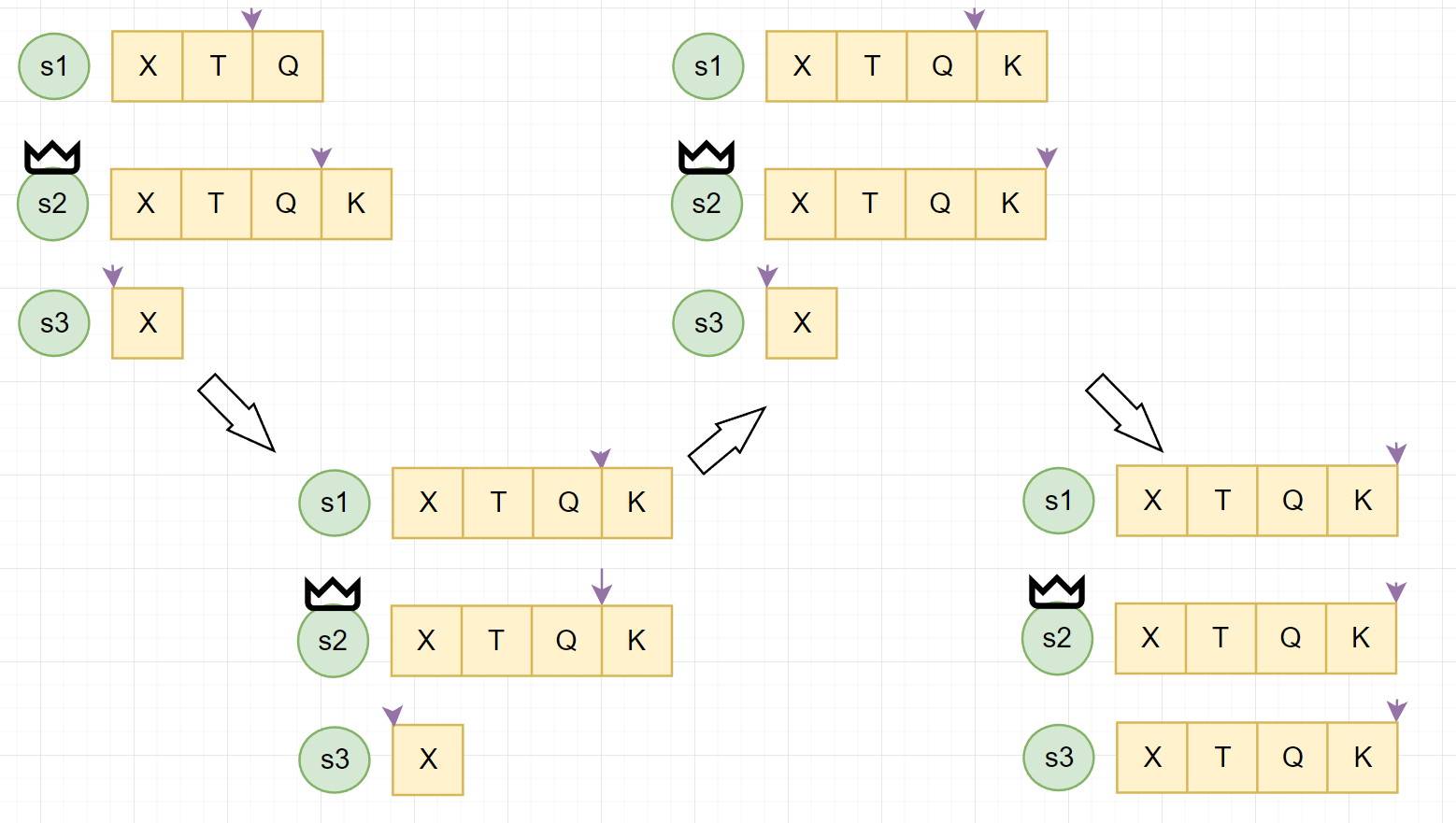
# Raft 主节点失效
- Leader 定期的发送 AppendEntries RPCs 给其余所有节点
- 如果 Follower 有一段时间没有收到 Leader 的 AppendEntries,则转换身份成为 Candidate
- Candidate 自增自己的 term,同时使用 RequestVote RPCs 向剩余节点请求投票
- raft 在检查是否可以投票时,会检查 log 是否 outdated,至少不比本身旧才会投给对应的 Candidate
- 如果多数派节点投给它,则成为该 term 的 leader
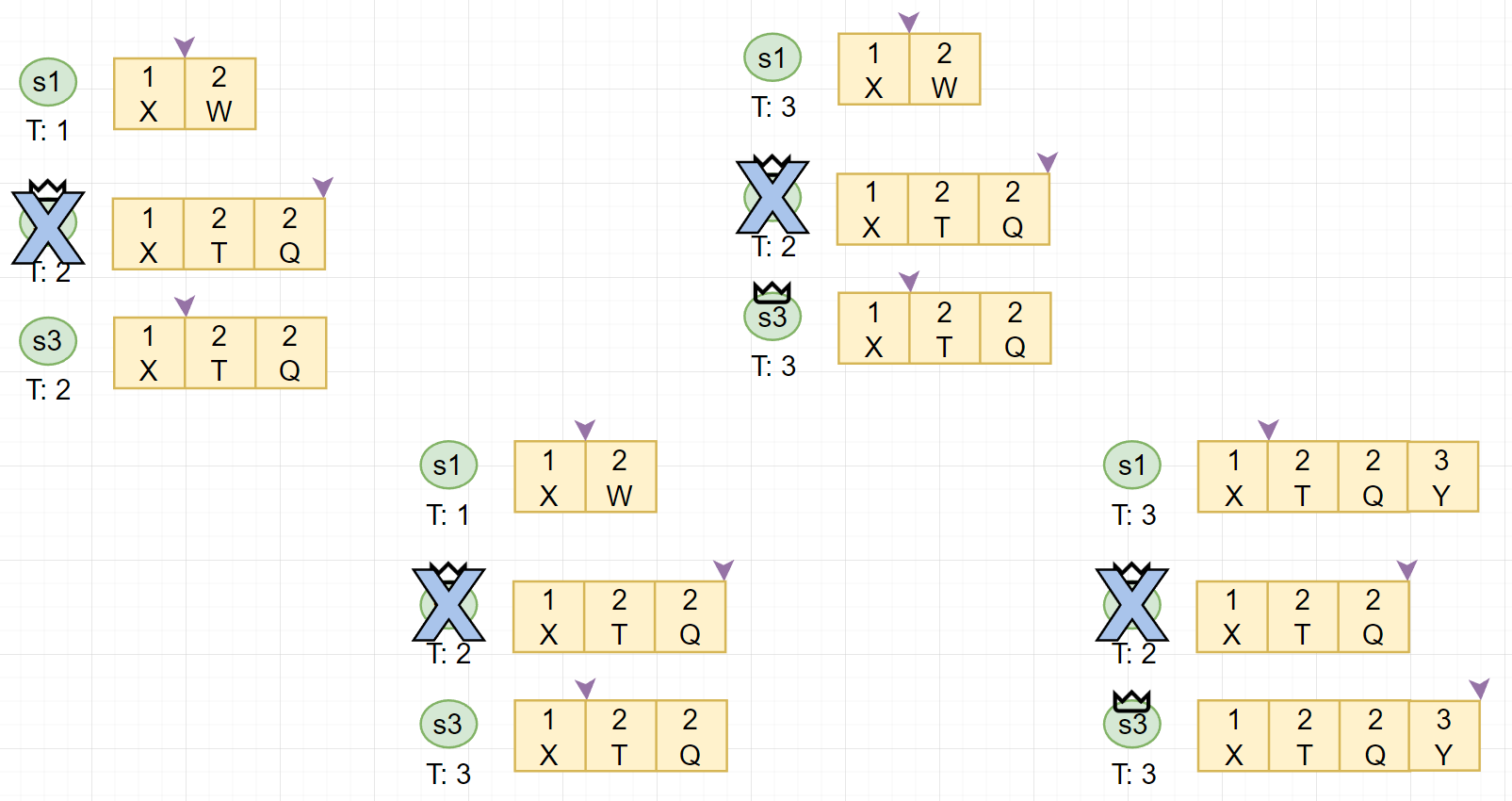
# Raft 安全性 - 同 Term
- 对于 Term 内的安全性
- 目标:对于所有已经的 commited 的
<term, index>位置上至多只有一条 log
- 目标:对于所有已经的 commited 的
- 由于 Raft 的多数派选举,我们可以保证在一个 term 中只有一个 leader
- 我们可以证明一条更严格的声明:在任何 <tem, mdexc 位置上,至多只有一条 log
# Raft 安全性 - 跨 Term
- 对于跨 Term 的安全性
- 目标:如果一个 log 被标记 commited,那这个 log 一定会在未来所有的 leader 中出现 Leader completeness
- 可以证明这个 property
- Raft 选举时会检查 Log 的是否 outdated,只有最新的才能当选 Leader
- 选举需要多数派投票,而 commitedlog 也已经在多数派中(必有 overlap)
- 新 Leader 一定持有 commited log,且 Leader 永远不会 overwrite log
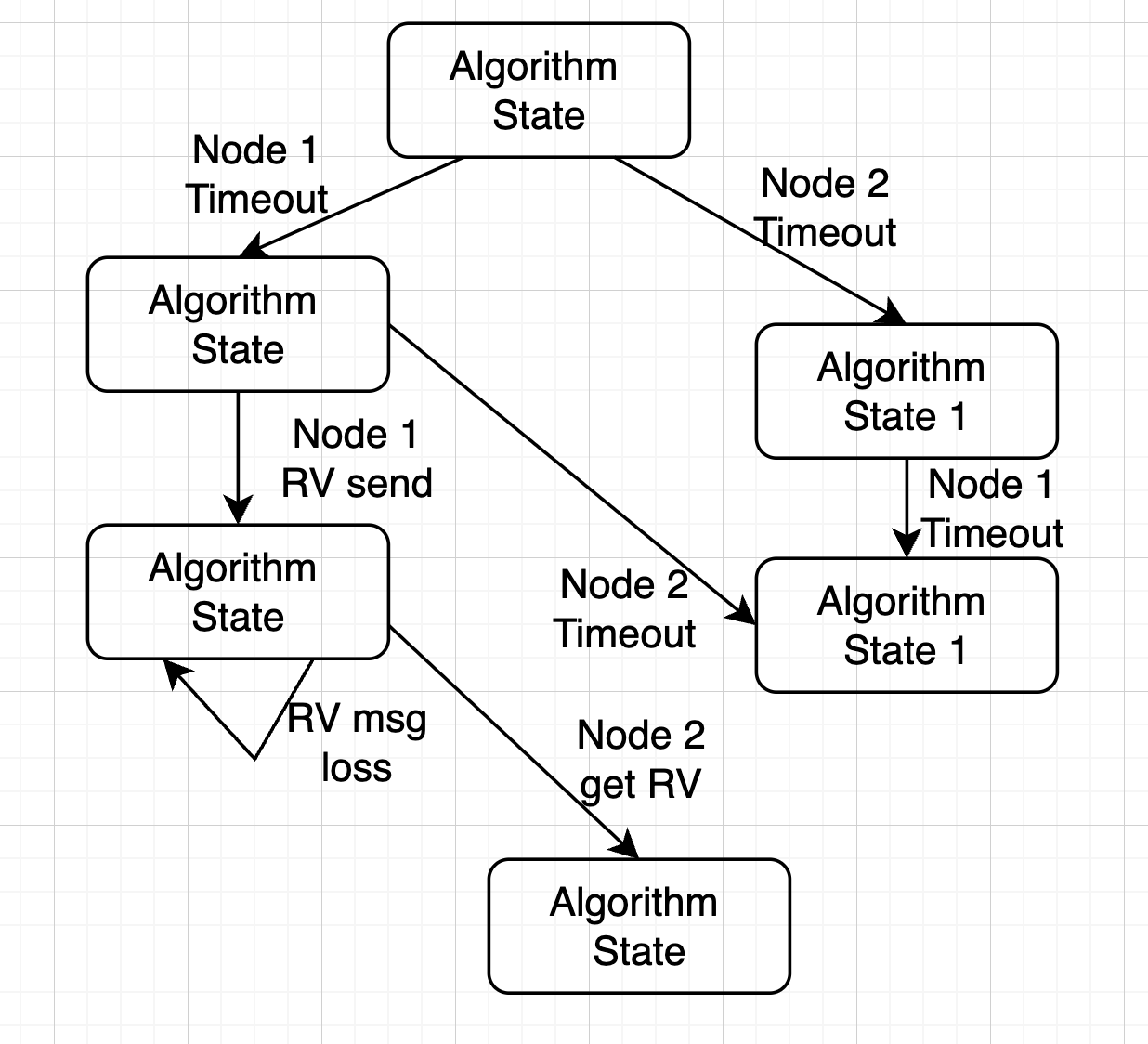
# Raft 安全性验证
真的安全吗?
- Raft 使用 TLA+ 进行了验证
- 形式验证 (FormalMethod):以数学的形式对算法进行表达,由计算机程序对算法所有的状态进行遍历
# 回到 KV
# 案例 - KV
利用 Raft 算法,重新打造我们的 KV
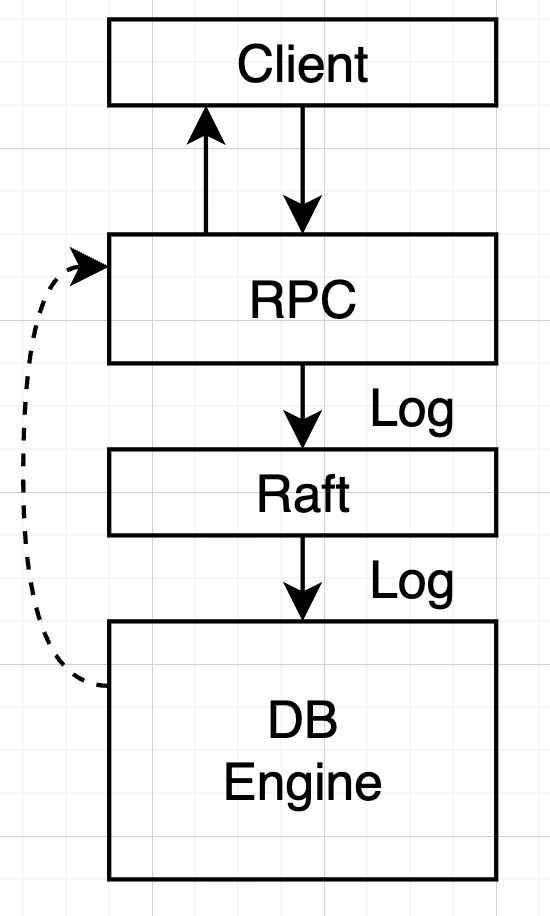
回顾一下一致性读写的定义
- 方案一:
- 写 log 被 commit 了,返回客户端成功,
- 读操作也写入一条 log,状态机 apply 时返回 client
- 增加 Log 量
- 方案二:
- 写 log 被 commit 了,返回客户端成功
- 读操作先等待所有 commited log apply,再读取状态机
- 优化写时延
- 方案三:
- 写 Log 被状态机 apply,返回给 client
- 读操作直接读状态机
- 优化读时延
- Raft 不保证一直有一个 leader
- 只保证一个 term 至多有一个 leader
- 可能存在多个 term 的 leader
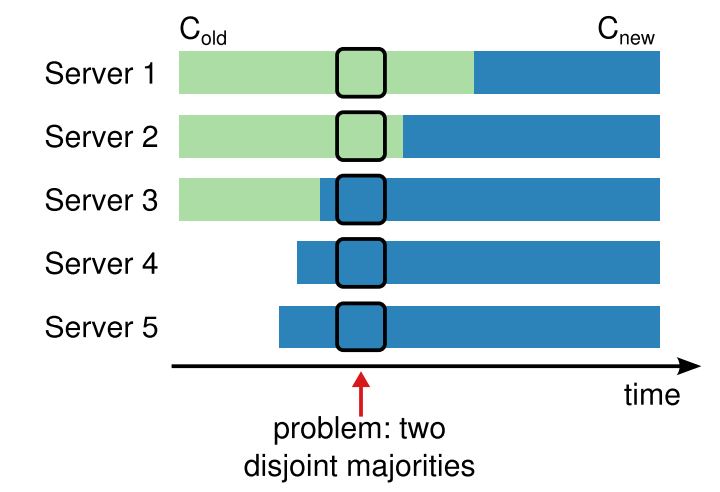
- Split-brain
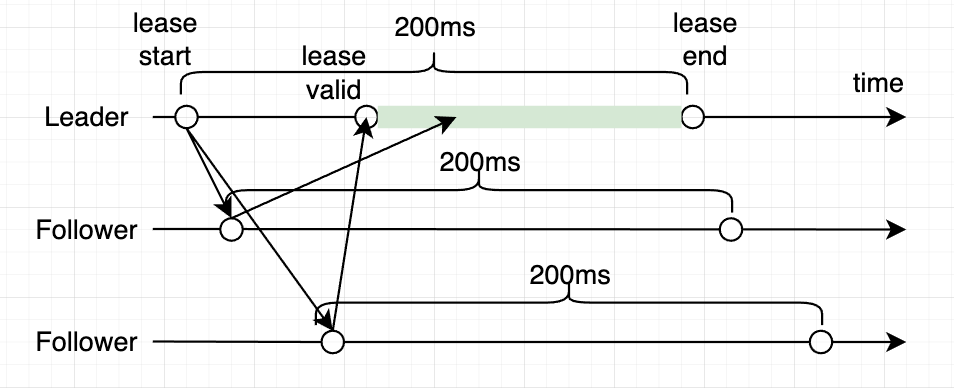
确定合法的 Leadership
- 方案一:
- 通过一轮 Heartbeat 确认 Leadership (获取多数派的响应)
- 方案二:
- 通过上一次 Heartbeat 时间来保证接下来的有段时间内 follower 不会 timeout
- 同时 follower 在这段时间内不进行投票
- 如果多数 follower 满足条件,那么在这段时间内则保证不会有新的 Leader 产生
- 结合实际情况选择方案二或方案三
- 取决于 raft 的实现程度以及读写的情况
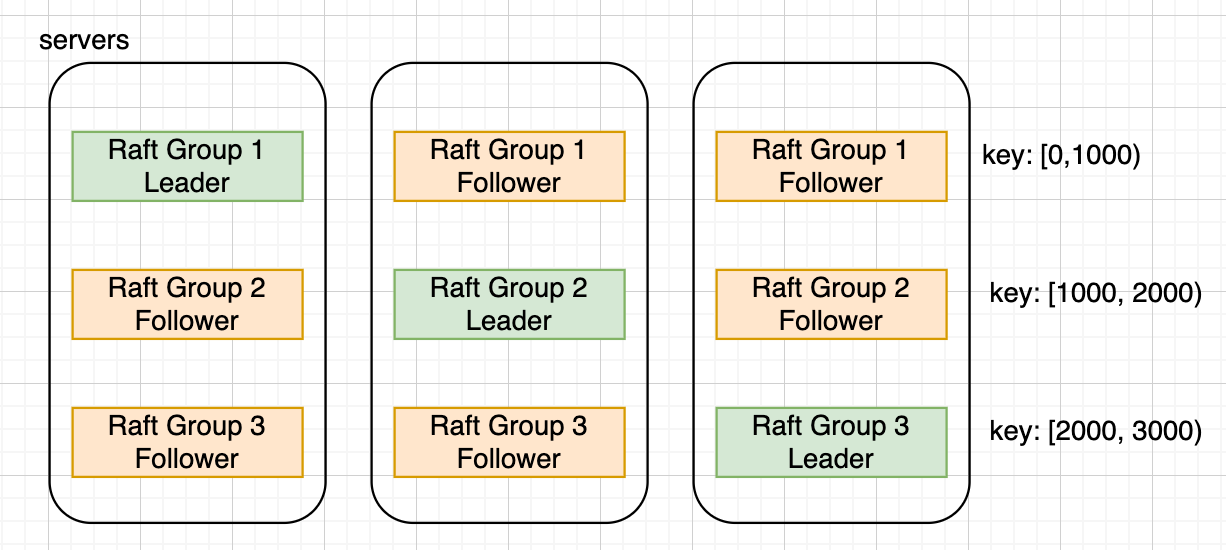
- 多个副本只有单个副本可以提供服务
- 服务无法水平拓展
- 增加更多 Raft 组
- 如果操作跨 Raft 组
按 key 分 raft 组
# 回到共识算法
- Raft:关于 Log
- 论文中就给出的方案,当过多的 Log 占用后,启动 snapshot,替换掉 Log
- 如果对于持久化的状态机,如何快速的产生 Snapshot
- 多组 Raft 的应用中,Log 如何合流
- 关于 configuration change
- 论文中给出的 joint-consensus 以及单一节点变更两种方案
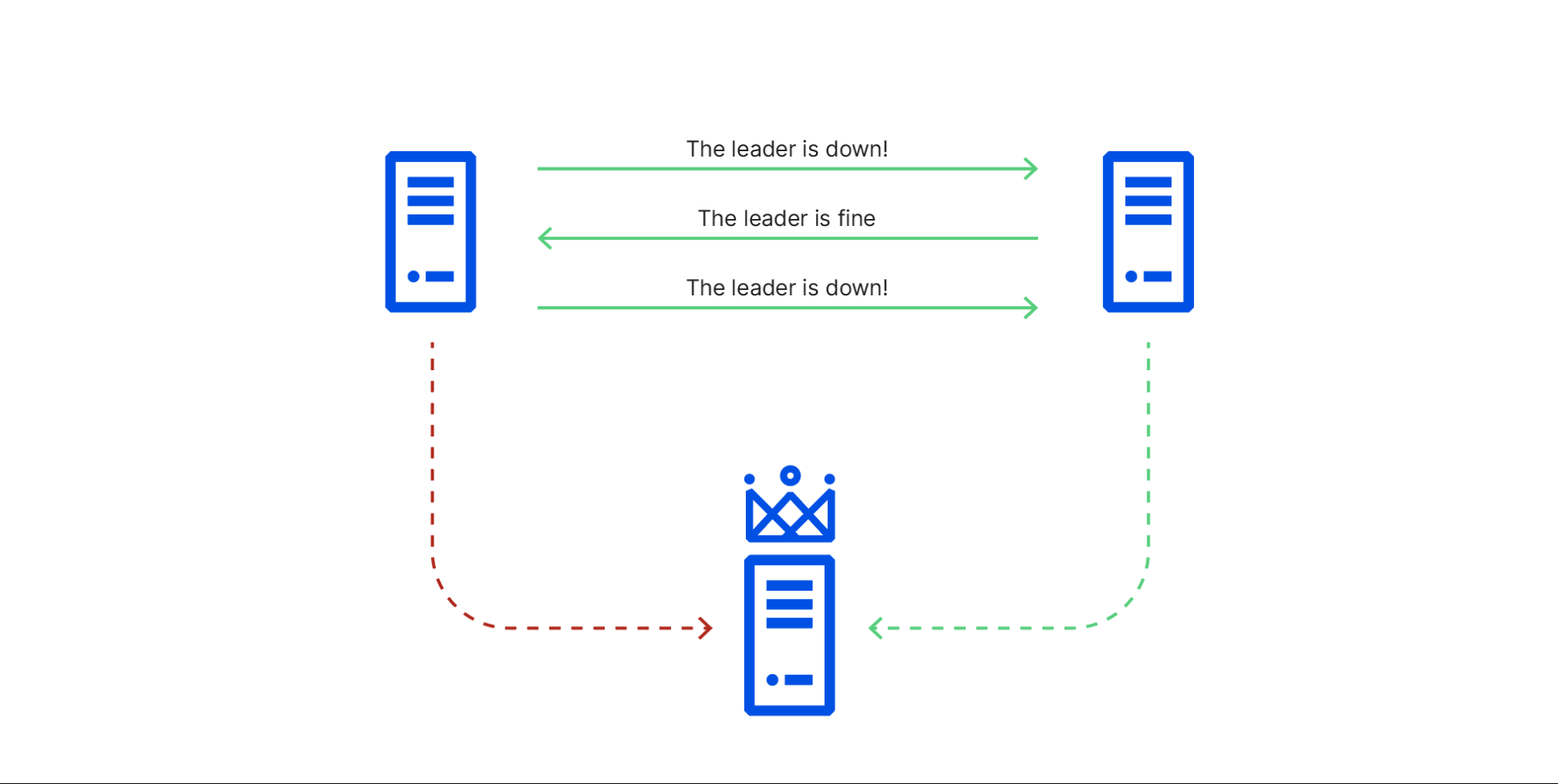
Raft 是正确的,但是在工程世界呢?
- 真实世界中不是所有的错误都是完美 fail-stop 的
- cloudflare 的 case, etcd 在 partial network 下,outage 了 6 个小时 [1]
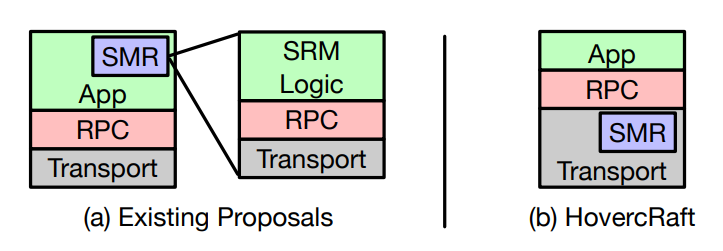
高性能
数据中心网络 100G,时延约为几个 us
RDMA 网卡以及 programable switch 的应用
我们想要的是: us 级别的共识,以及 us 级别的容错
HovercRaft
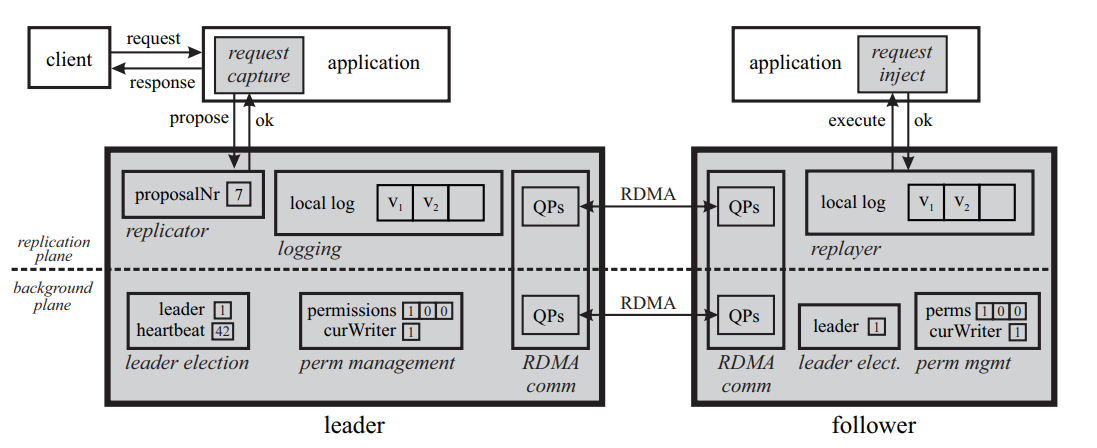
- P4 programable switch: IP multicast
Mu
- Use one-sided RDMA
- pull based heartbeat instead of push-based.
- 多节点提交 (Leaderless)
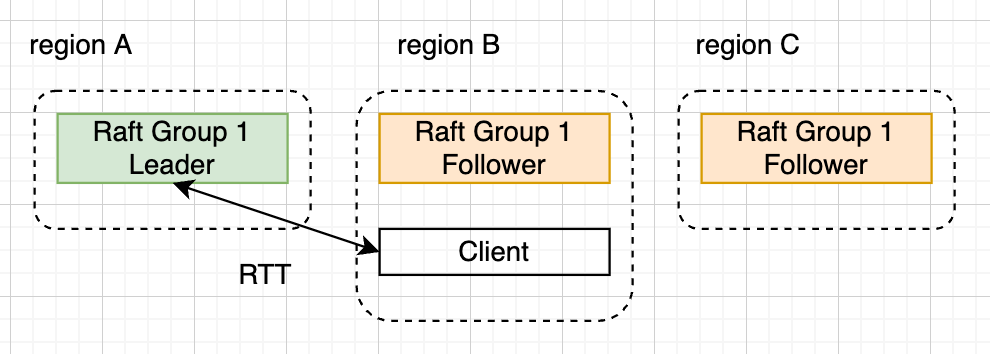
- 节点跨地域,导致节点间的 RTT (Round Trip Time) 很大
- EPaxos[1]
- 使用了冲突图的方式来允许并行 Commit
- 不冲突的情况下 1RTT 提交时间
# 共识算法的未来
- Raft Paxos 相互移植
- Raft 有很多成熟的实现
- 研究主要关注在 Paxos 上
- 如何关联两种算法
- On the Parallels between Paxos and Raft, and how to Port Optimizations[1]
- Paxos vs Raft: Have we reached consensus on distributed consensus?[2]
- 共识算法作为一个系统
- 多数分布式系统都选择共识算法作为底座
- 不同一致性协议有不同的特性
- Vrual consensus in delos[1]
- 对外暴露一致性的 LOG 作为借口
- 内部对于 LOG 可以选择不同的实现