Hbase与Hive的集成
Hbase与Hive的集成
# Hbase 与 Hive 的集成
# HBase 与 Hive 的对比
1.Hive (1) 数据分析工具 Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以方便使用 HQL 去管理查询。 (2) 用于数据分析、清洗 Hive 适用于离线的数据分析和清洗,延迟较高。 (3) 基于 HDFS、MapReduce Hive 存储的数据依旧在 DataNode 上,编写的 HQL 语句终将是转换为 MapReduce 代码执行。 2.HBase (1) 数据库 是一种面向列族存储的非关系型数据库。 (2) 用于存储结构化和非结构化的数据 适用于单表非关系型数据的存储,不适合做关联查询,类似 JOIN 等操作。 (3) 基于 HDFS 数据持久化存储的体现形式是 HFile,存放于 DataNode 中,被 ResionServer 以 region 的形式进行管理。 (4) 延迟较低,接入在线业务使用 面对大量的企业数据,HBase 可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
# HBase 与 Hive 集成使用
启动 yarn 和 hive 服务
start-yarn.sh
hiveservices.sh start
beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
2
3
# 从 Hive 映射到 HBase 上
建立 Hive 表,关联 HBase 表,插入数据到 Hive 表的同时能够影响 HBase 表
在 Hive 中创建表同时关联 HBase
CREATE TABLE emp_hbase(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
2
3
4
5
6
7
8
9
10
11
12
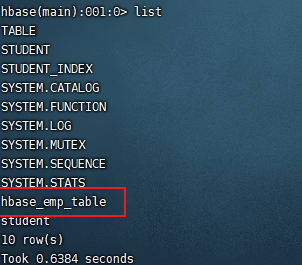
从 hbase 中查看所有表 自动创建了映射表
hive 中创建 emp 表并导入文本数据
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
2
3
4
5
6
7
8
9
10
查询工资大于 2000 的数据插入到 emp_hbase 表中
insert into emp_hbase select * from emp where sal > 2000;
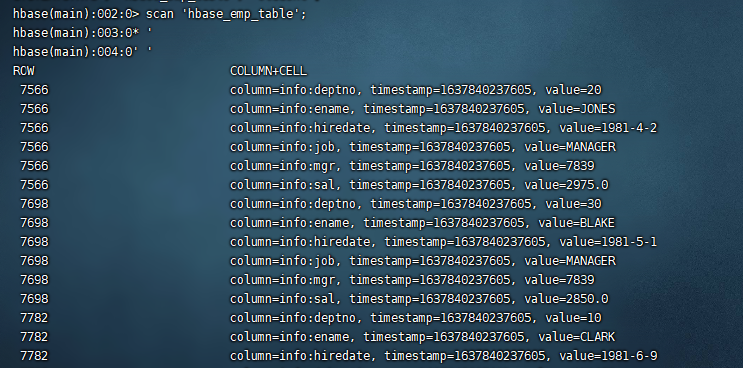
使用 hbase shell 查看 hbase_emp_table
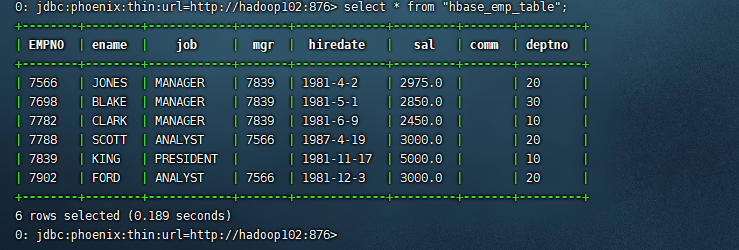
将 emp_hbase 表映射 Phoenix 上
CREATE VIEW "hbase_emp_table"(empno varchar PRIMARY KEY,
"info"."ename" varchar,
"info"."job" varchar,
"info"."mgr" varchar,
"info"."hiredate" varchar,
"info"."sal" varchar,
"info"."comm" varchar,
"info"."deptno" varchar);
2
3
4
5
6
7
8
select * from "hbase_emp_table";
# 从 HBase 映射到 Hive
在 HBase 中已经存储了某一张表 hbase_emp_table,然后在 Hive 中创建一个外部表来关联 HBase 中的 hbase_emp_table 这张表,使之可以借助 Hive 来分析 HBase 这张表中的数据。
在 Hive 中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
2
3
4
5
6
7
8
9
10
11
12
13
14
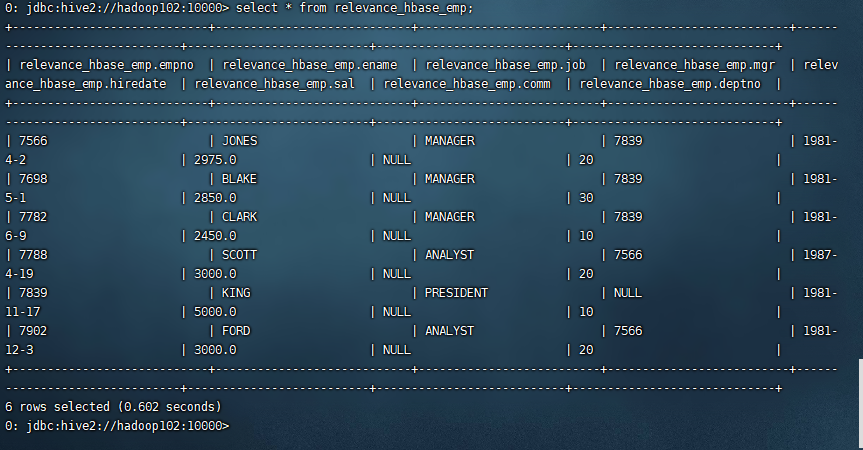
关联后就可以使用 Hive 函数进行一些分析操作了
select * from relevance_hbase_emp;