 Scrapy
Scrapy
# Scrapy

# 创建项目
初始化项目
scrapy startproject 项目名称
创建爬虫
#scrapy genspider 项目名 爬取的url域名/地址
scrapy genspider dfcf “http://data.eastmoney.com/zjlx/detail.html”
2
项目名:作为爬虫运行时的参数
爬取的域名 / 地址:对爬虫设置的爬取范围,设置之后用于过滤要爬取的 url,如果爬取的 url 与允许的域不同则会被过滤掉。
项目结构
整个工程的目录结构如下:
├── scrapy.cfg #工程信息
└── xy3
├── __init__.py
├── items.py #需要解析出来的内容
├── pipelines.py #处理解析出来的items
├── settings.py #爬虫的设置内容
└── spiders
├── dhxy3.py #解析内容,生成新的请求规则的蜘蛛
└── __init__.py
2
3
4
5
6
7
8
9
10
- scrapy.cfg: 项目的配置文件。
- mySpider/: 项目的 Python 模块,将会从这里引用代码。
- mySpider/items.py: 项目的目标文件。
- mySpider/pipelines.py: 项目的管道文件。
- mySpider/settings.py: 项目的设置文件。
- mySpider/spiders/: 存储爬虫代码目录。
运行项目
在项目文件以命令行形式运行
cd tutorial
#scrapy crawl 爬虫名
scrapy crawl quotes
2
3
或在项目中创建一个 python 程序
from scrapy import cmdline
cmdline.execute('scrapy crawl txms'.split())
2
3
# Items
数据建模
定义 item 文件提前规划好哪些字段需要抓取,防止写错字段名,scrapy 会帮我们自动检查错误。
可以清晰自动需要抓取哪些字段
一些特定组件需要 Item 做支持,如 scrapy 的 imagesPipeline 管理类
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 名字
title = scrapy.Field() # 标题
desc = scrapy.Field() # 简介
2
3
4
5
其实是 scrapy 帮我们创建一个为空的特殊字典,如果没有指定的键时添加时会报错,不会像 python 字典帮我们自动创建新键。
需要注意的是:items 对象无法直接当做字段来使用,需要强转为字典
item = dict(item)
json_data = json.dumps(item, ensure_ascii = False)
2
# Request
class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])

url(string)- 此请求的网址callback(callable)- 将使用此请求的响应(一旦下载)作为其第一个参数调用的函数。有关更多信息,请参阅下面的将附加数据传递给回调函数 (opens new window)。如果请求没有指定回调,parse () 将使用 spider 的 方法。请注意,如果在处理期间引发异常,则会调用 errback。method(string)- 此请求的 HTTP 方法。默认为 'GET'。meta(dict)- 属性的初始值 Request.meta。如果给定,在此参数中传递的 dict 将被浅复制。包含此请求的任意元数据的字典。此 dict 对于新请求为空,通常由不同的 Scrapy 组件(扩展程序,中间件等)填充。因此,此 dict 中包含的数据取决于您启用的扩展。dont_filter(boolean)- 表示此请求不应由调度程序过滤。当您想要多次执行相同的请求时忽略重复过滤器时使用。小心使用它,或者你会进入爬行循环。默认为 False。body(str或unicode)- 请求体。如果 unicode 传递了 a,那么它被编码为 str 使用传递的编码(默认为 utf-8)。如果 body 没有给出,则存储一个空字符串。不管这个参数的类型,存储的最终值将是一个 str(不会是 unicode 或 None)。headers(dict)- 这个请求的头。dict 值可以是字符串(对于单值标头)或列表(对于多值标头)。如果 None 作为值传递,则不会发送 HTTP 头。cookie(dict或list)- 请求 cookie。这些可以以两种形式发送。
# pipeline 管道
- process_item(self,item,spider):
- 管道类中必须有的函数
- 实现对 item 数据的处理
- 必须 return item
- open_spider (self,spider) 在爬虫开启的时候仅执行一次
- close_spider (self,spider) 在爬虫关闭时仅执行一次
pipeline 使用前要在 settings 中开启
ITEM_PIPELINES = {
# 项目名.pipelines.类名
'myspider.pipelines.MyspiderPipeline': 300, # 优先级 小的先执行
}
2
3
4
# crawlspider 爬虫
创建模板型爬虫
scrapy genspider -t crawl 项目名 域名
对应的 crawlspider 就可以实现上述需求,能够匹配满足条件的 url 地址,组装成 Reuqest 对象后自动发送给引擎,同时能够指定 callback 函数
def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(), tags=('a', 'area'), attrs=('href',), canonicalize=False, unique=True, process_value=None, deny_extensions=None, restrict_css=(), strip=True, restrict_text=None)
CrawlSpider 与 spider 不同的是就在于下一次请求的 url 不需要自己手动解析,而这一点则是通过 LinkExtractors 实现的。
- allow:允许的 url。所有满足这个正则表达式的 url 都会被提取
- deny:禁止的 url。所有满足这个正则表达式的 url 都不会被提取
- allow_domains:允许的域名。只有在这个里面指定的域名的 url 才会被提取
- deny_domains:禁止的域名。所有在这个里面指定的域名的 url 都不会被提取
- restrict_xpaths:严格的 xpath。和 allow 共同过滤链接
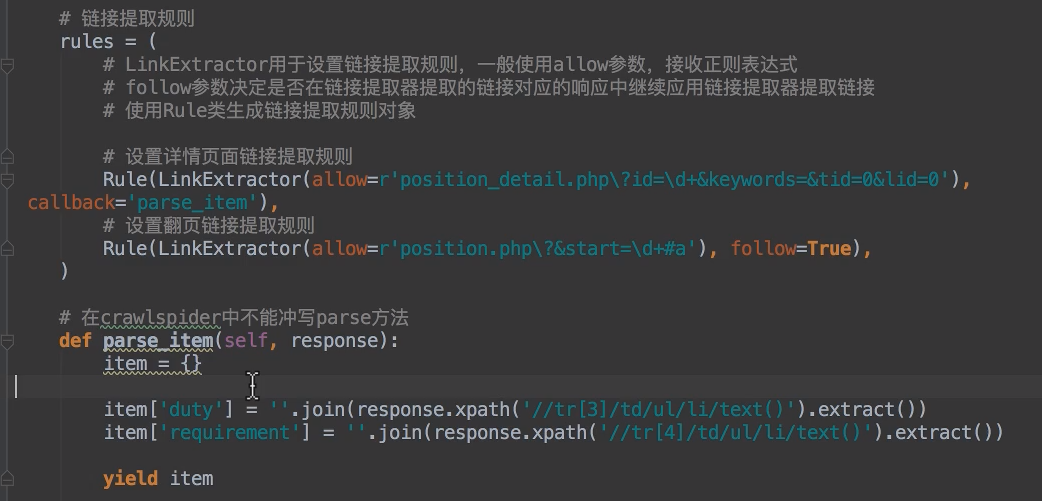
# Rule
LinkExtractors 需要传递到 Rule 类对象中才能发挥作用。Rule 类为:
- rules 是一个元组或者是列表,包含的是 Rule 对象
- Rule 表示规则,其中包含 LinkExtractor,callback 和 follow 等参数
- LinkExtractor: 连接提取器,可以通过正则或者是 xpath 来进行 url 地址的匹配
- callback : 表示经过连接提取器提取出来的 url 地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
- follow:连接提取器提取的 url 地址对应的响应是否还会继续被 rules 中的规则进行提取,True 表示会,Flase 表示不会
def __init__(self, link_extractor=None, callback=None, cb_kwargs=None, follow=None,
process_links=None, process_request=None, errback=None):
2
- link_extractor:LinkExtractor 对象,用于定义爬取规则
- callback:对于满足该规则的 url 所要执行的回掉函数,类似于之前提到的 scrapy.Request () 中的 callback。而 CrawlSpider 使用了 parse 作为回调函数,因此不要覆盖 parse 作为回调函数自己的回调函数
- follow:从 response 中提取的链接是否需要跟进
- process_links:从 link_extractor 中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接
# middlewares 中间件
# 下载中间件
- process_request(self, request, spider):
- 每个 request 通过下载中间件时 该方法被调用
- 返回 Node 值: 没有 return 也是返回 Node 该 request 对象传递给下载器 或通过引擎传递给其他权重低的 process_request 方法
- 返回 Rsponse 对象:不再请求 把 response 返回给引擎
- 返回 Request 对象: 把 request 对象通过引擎给的调度器 此时将不通过其他权重低的 process——request 方法
# 爬虫中间件
- process_response(self, request, response, spider):
- 当下载器完成 http 请求 传递响应给引擎的时候调用
- 返回 Rsponse 对象:通过引擎给爬虫处理或交给权重更低的其他下载中间件的 process_response 方法
- 返回 Request 对象:通过引擎交给调度器继续请求 此时将不通过其他权重低的 process_request 方法
# Xpath
1. 路径查询 //:查找所有子孙节点,不考虑层级关系 / :找直接子节点
2. 谓词查询 //div[@id] //div[@id="maincontent"]
3. 属性查询 //@class
4. 模糊查询 //div[contains(@id, "he")] //div[starts‐with(@id, "he")]
5. 内容查询 //div/h1/text()
6. 逻辑运算 //div[@id="head" and @class="s_down"] //title | //price
response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8')
hxs = HtmlXPathSelector(response)
print(hxs) # selector对象
hxs = Selector(response=response).xpath('//a')
print(hxs) #查找所有的a标签
hxs = Selector(response=response).xpath('//a[2]')
print(hxs) #查找某一个具体的a标签 取第三个a标签
hxs = Selector(response=response).xpath('//a[@id]')
print(hxs) #查找所有含有id属性的a标签
hxs = Selector(response=response).xpath('//a[@id="i1"]')
print(hxs) # 查找含有id=“i1”的a标签
hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]')
print(hxs) # 查找含有href=‘xxx’并且id=‘xxx’的a标签
hxs = Selector(response=response).xpath('//a[contains(@href, "link")]')
print(hxs) # 查找 href属性值中包含有‘link’的a标签
hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]')
print(hxs) # 查找 href属性值以‘link’开始的a标签
hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]')
print(hxs) # 正则匹配的用法 匹配id属性的值为数字的a标签
hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/text()').extract()
print(hxs) # 匹配id属性的值为数字的a标签的文本内容
hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]/@href').extract()
print(hxs) #匹配id属性的值为数字的a标签的href属性值
hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract()
print(hxs)
hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first()
print(hxs)
ul_list = Selector(response=response).xpath('//body/ul/li')
for item in ul_list:
v = item.xpath('./a/span')
# 或
# v = item.xpath('a/span')
# 或
# v = item.xpath('*/a/span')
print(v)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 保存数据
scrapy 保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,命令如下:
scrapy crawl itcast -o teachers.json
json lines 格式,默认为 Unicode 编码
scrapy crawl itcast -o teachers.jsonl
csv 逗号表达式,可用 Excel 打开
scrapy crawl itcast -o teachers.csv
xml 格式
scrapy crawl itcast -o teachers.xml