 Flink 部署
Flink 部署
# Flink 部署
# 第一个 Word Count
# 创建项目
选择 Maven 原型创建项目
手动添加原型
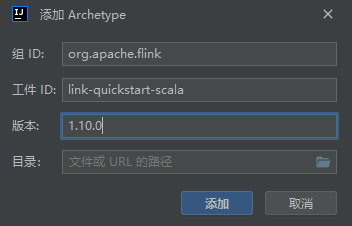
org.apache.flink
link-quickstart-scala
1.10.0
2
3
如果无法使用原型,则修改 pom.xml 文件导入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<configuration>
<encoding>UTF-8</encoding>
<args>
<arg>-nobootcp</arg>
</args>
</configuration>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
创建 在 src.main.scala 包创建 com.atguigu 包
# 批处理
object BathWordCount {
case class WordWithCount(word: String, count: Int)
def main(args: Array[String]): Unit = {
// 创建执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 从集合中创建数据源
val stream = env.fromElements("hello world", "hello world", "hello world")
val transformed = stream
.flatMap(line => line.split(("\\s")))
.map(w => WordWithCount(w, 1))
.sum(1)
// 将计算的结果输出到标准输出
transformed.print()
// 执行计算逻辑
env.execute()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 流处理
创建 WordCount.scala
package com.atguigu
// 导入隐式类型转换 implicit
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @author Iekr
* Date: 2022/11/28/0028 18:55
*/
object WordCount {
case class WordWithCount(word: String, count: Int)
def main(args: Array[String]): Unit = {
// 获取运行时环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 设置分区(并行任务)数量为1
env.setParallelism(1)
// 建立数据源
// 需要先启动 nc -lk 9999 用于发送数据
val stream = env.socketTextStream("localhost", 9999, '\n')
// 写对流的转换处理逻辑
val transformed: DataStream[WordWithCount] = stream
//使用空格切分输入的字符串
.flatMap(line => line.split("\\s"))
// 类似与MR中的map
.map(w => WordWithCount(w, 1))
// 使用 word 字段进行分钟 类似 shuffle
.keyBy(0)
// 开了一个5s的滚动窗口
.timeWindow(Time.seconds(5))
// 针对count字段进行累加操作 类型mr中的reduce
.sum(1)
// 将计算的结果输出到标准输出
transformed.print()
// 执行计算逻辑
env.execute()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 打包
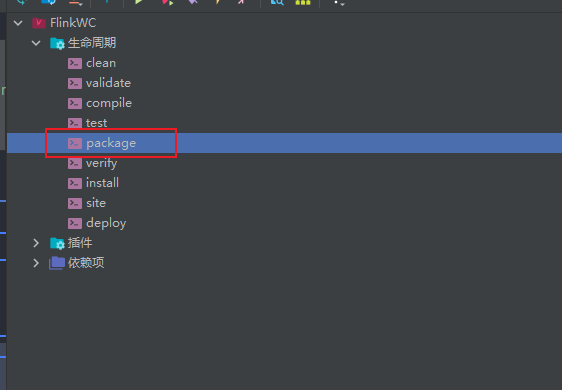
打包后的 jar 在
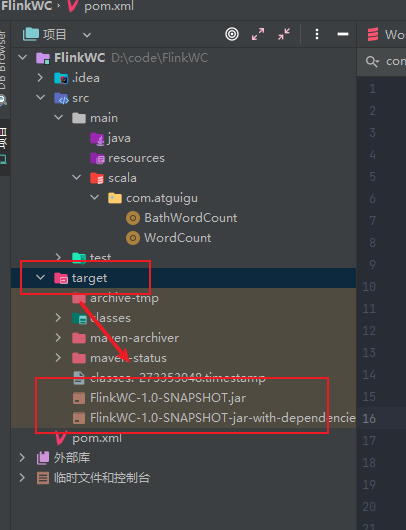
上传不带依赖的即不带后缀的
# Standalone 模式
# 安装
解压安装
tar -zxvf /opt/software/flink-1.10.0-bin-scala_2.11.tgz -C /opt/module/
mv /opt/module/flink-1.10.0/ /opt/module/flink
2
添加环境变量
sudo vim /etc/profile.d/my_env.sh
添加以下内容
#FLINK_HOME
export FLINK_HOME=/opt/module/flink
export PATH=$PATH:$FLINK_HOME/bin
2
3
修改 /conf/ flink-conf.yaml 文件
vim /opt/module/flink/conf/flink-conf.yaml
修改以下内容
jobmanager.rpc.address: hadoop102
修改 /conf/ slaves 文件
vim /opt/module/flink/conf/slaves
覆盖写入以下内容
hadoop103
hadoop104
2
分发到另外两台机器
xsync /opt/module/flink/
sudo xsync /etc/profile.d/my_env.sh
2
启动
cd /opt/module/flink/bin/
./start-cluster.sh
2
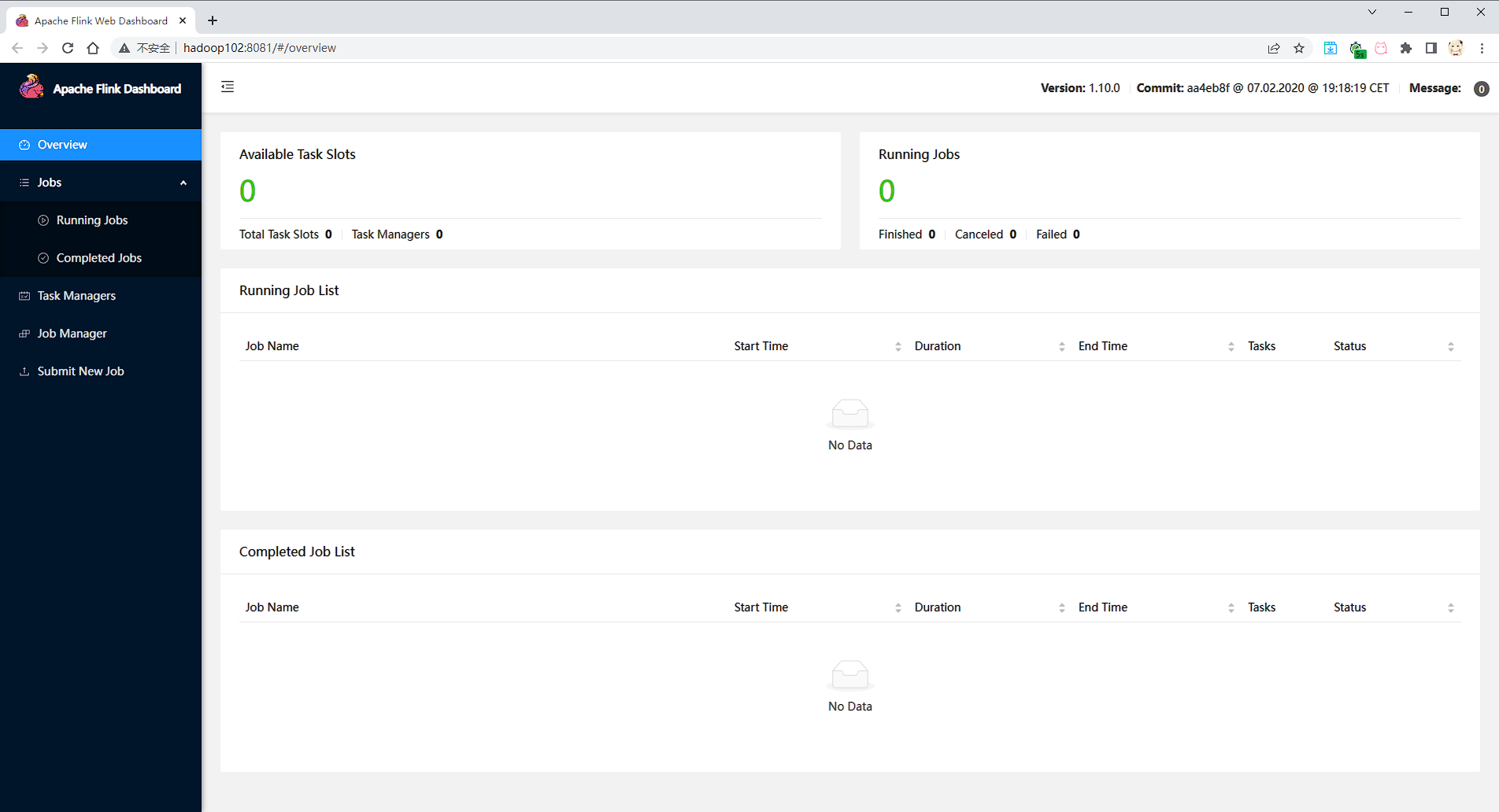
访问 http://hadoop102:8081 可以对 flink 集群和任务进行监控管理
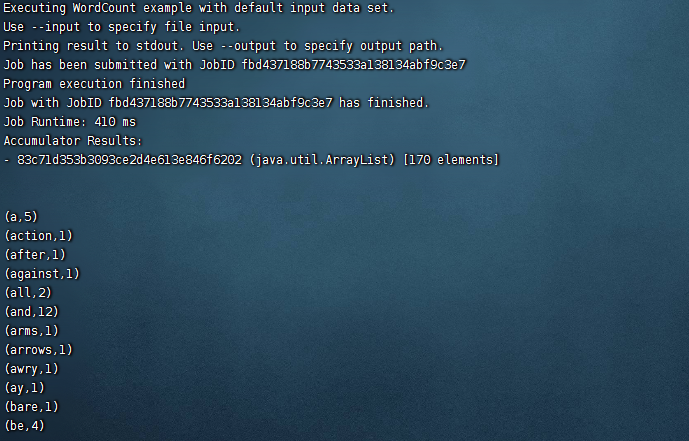
测试
flink run /opt/module/flink/examples/batch/WordCount.jar
# Yarn 模式
# Flink on Yarn
Flink 提供了两种在 yarn 上运行的模式,分别为 Session-Cluster 和 Per-Job-Cluster 模式。
Session-cluster 模式:
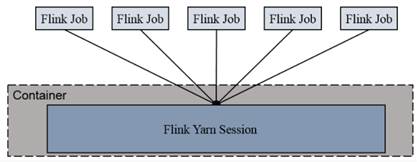 Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。Per-Job-Cluster 模式:
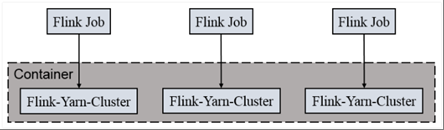
一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn 申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。 每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
# Session Cluster
启动 hadoop 集群
start-all.sh
将 flink-shaded-hadoop-2-uber-2.7.5-10.0.jar 依赖放到 flink 目录下的 lib 中
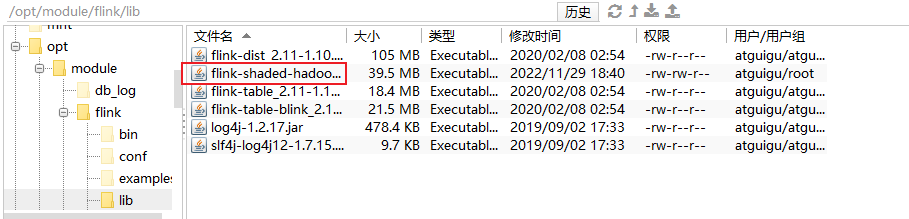
启动 yarn-session
yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
- -n (--container):TaskManager 的数量。
- -s (--slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个 taskmanager 的 slot 的个数为 1,有时可以多一些 taskmanager,做冗余。
- -jm:JobManager 的内存(单位 MB)。
- -tm:每个 taskmanager 的内存(单位 MB)。
- -nm:yarn 的 appName (现在 yarn 的 ui 上的名字)。
- -d:后台执行。
启动成功后端口是随机生成
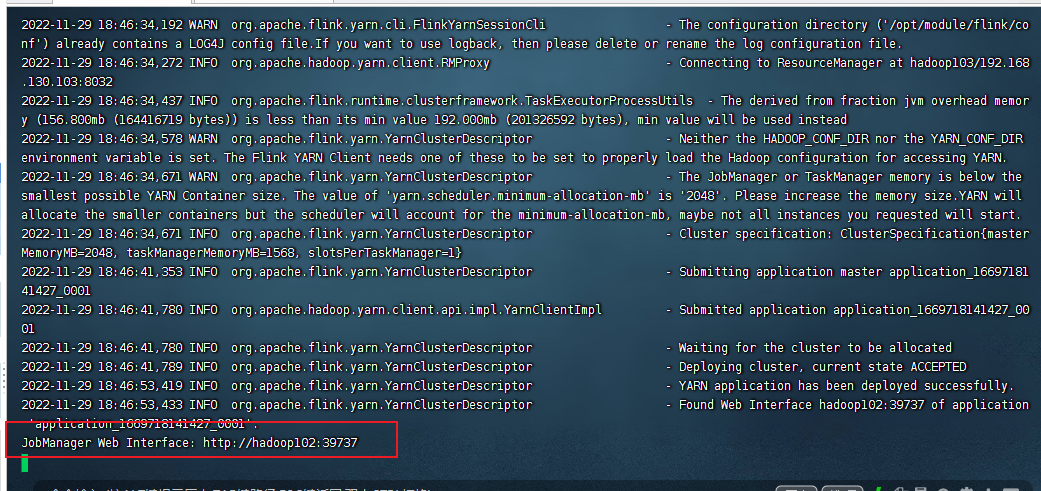
访问 http://hadoop102:39737 / 网页
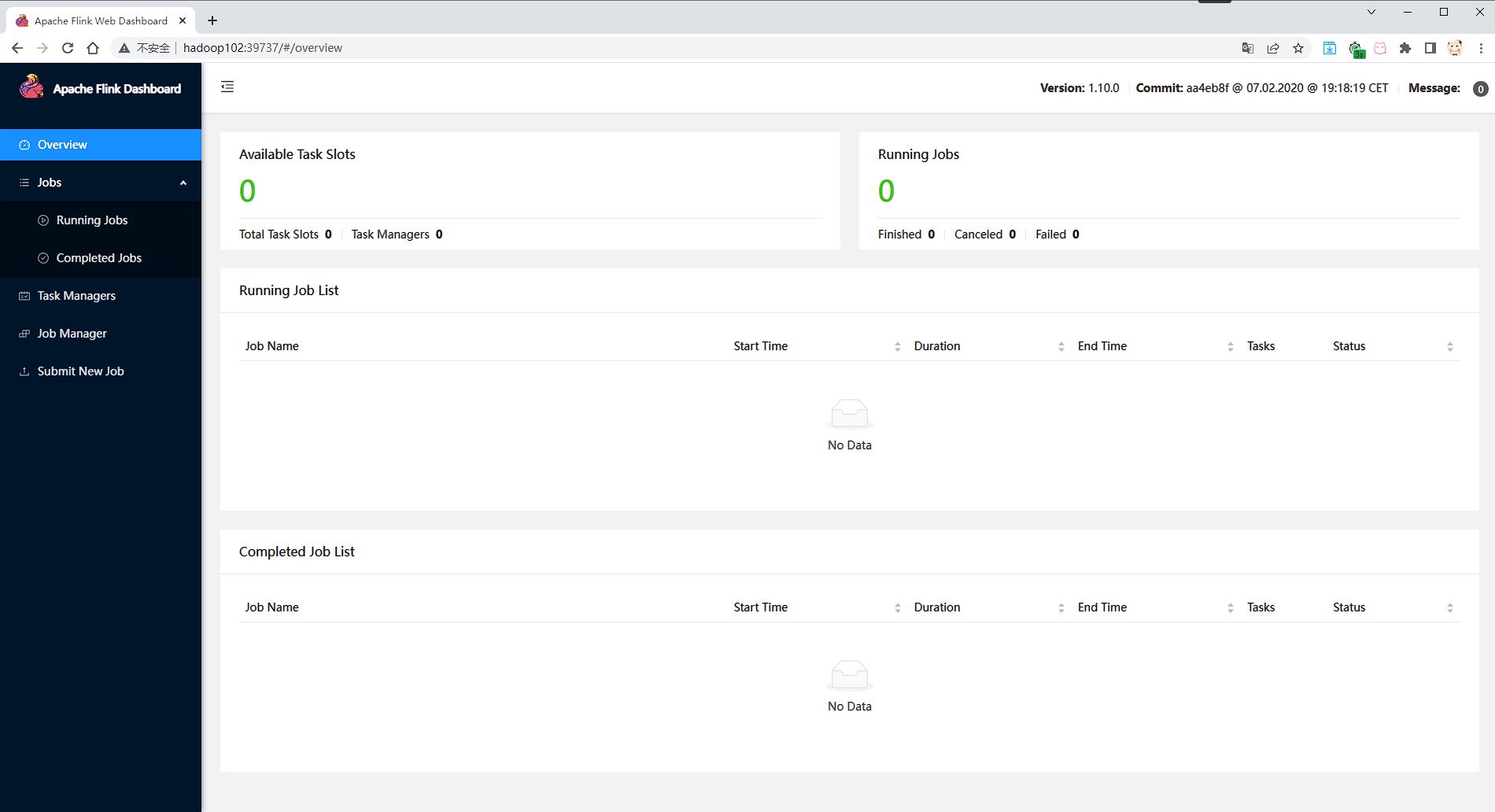
执行我们打包上去的 Word Count 程序
flink run -c com.atguigu.BathWordCount FlinkWC-1.0-SNAPSHOT.jar --host hadoop102 –port 9999
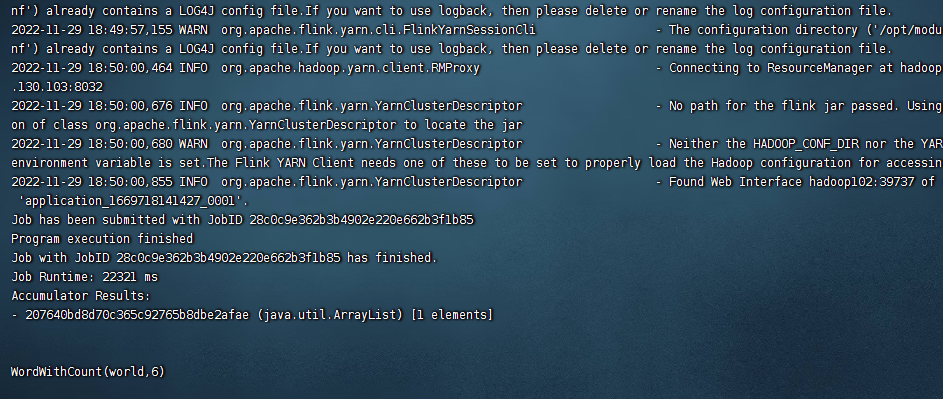
# Per Job Cluster
启动 hadoop 集群
start-all.sh
不启动 yarn-session,直接执行 job
flink run –m yarn-cluster -c com.atguigu.WordCount FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar