 Spark 原理与实践| 青训营笔记
Spark 原理与实践| 青训营笔记
# Spark 原理与实践| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第 5 天
# 大数据处理引擎 Spark 介绍
大数据处理技术栈
- 应用:BI 报表 / 实时大盘 / 广告 / 推荐
- 计算:Spark/Flink/Presto/Impala/ClickHouse/YARN/K8s/...
- 存储:MetaStore/Paequet/ORC/DeltaLake/Hudi/Iceberg/HDFS/Kafka/HBase/Kudu/TOS/S3/...
- 数据:Volume/Variety/Velocity On-Premise/On-cloud;平台,管理,安全 /...
常见大数据处理链路
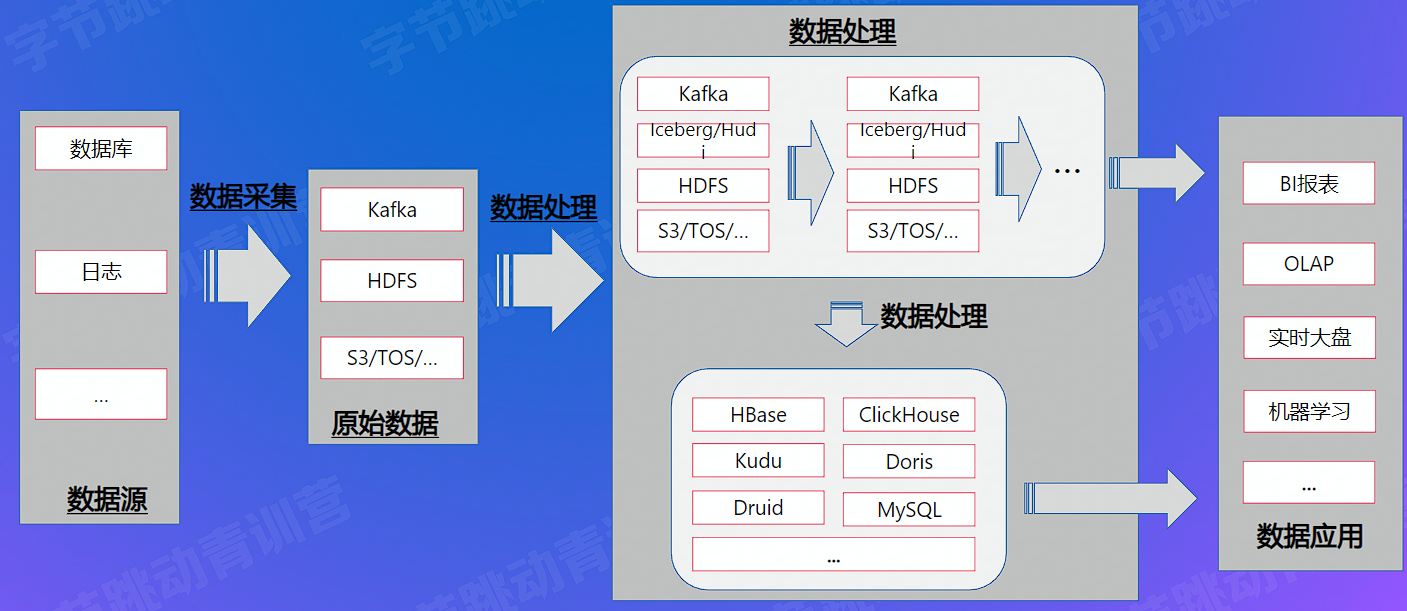
开源大数据处理引擎
- Batch:Hive/hadoop/Spark
- Streaming:Flink
- OLAP:Presto/ClickHouse/Impala/DORIS
什么是 Spark?
- Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
- 用于大规模的数据统一分析引擎,它可以在单机节点 / 集群上执行数据工程、数据科学和机器学习
- 支持多语言的 批 / 流计算处理您的数据
- 提供执行快速、分布式的 ANSI SQL 查询分析
- 对 PB 级数据执行探索性数据分析 (EDA),而无需进行下采样
- 训练机器学习算法,并使用相同的代码扩展到包含数千台机器的容错集群。
# Spark 版本演进

# Spark 生态组件
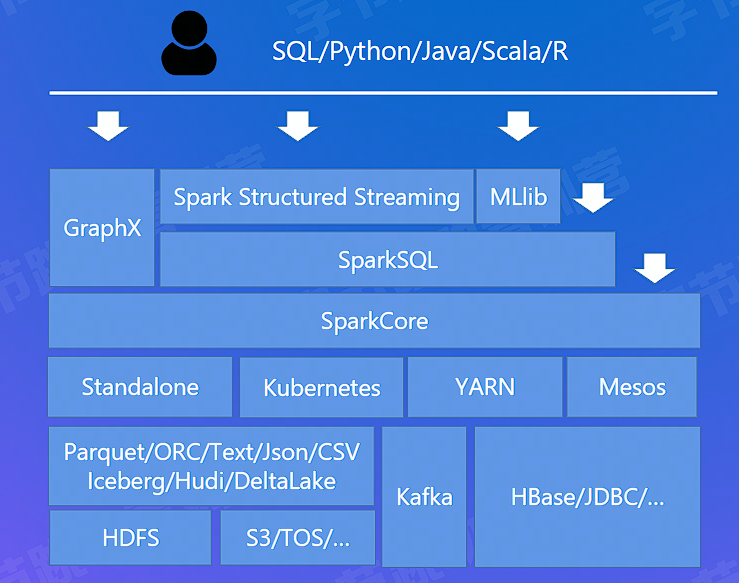
- Spark Core:Spark 核心组件,它实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。
- SparkCore --> RDD
- map/filter/flatMap/mapPartitions/repartition/groupBy/reduceBy/join/aggregate/foreach/foreachPartition/count/max/min 等 API
- SparkCore --> RDD
- Spark SQL:用来操作结构化数据的核心组件,通过 Spark SQL 可以直接查询 Hive、HBase 等多种外部数据源中的数据。
- SparkSQL --> DataFrame
- select/filter/groupBy/agg/join/union/orderBy/Hive UDF / 自定义 UDF 等算子
- SparkSQL --> DataFrame
- Spark Structured Streaming:Spark 提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理。
- MLlib:Spark 提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。
- GraphX:Spark 提供的分布式图处理框架,拥有对图计算和图挖掘算法的 API 接口以及丰富的功能和运算符。
- 独立调度器、Yarn、Mesos、Kubernetes:Spark 框架可以高效地在一个到数千个节点之间伸缩计算,集群管理器则主要负责各个节点的资源管理工作,为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(Cluster Manager)上运行。
- 提供丰富的数据源
- 内置 DataSource 支持 Text、Parquet/ORC、JSON/CSV、JDBC 等
- 自定义 DataSource,自己实现或者社区提供其他数据源的自定义实现
# Spark 运行架构
图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。
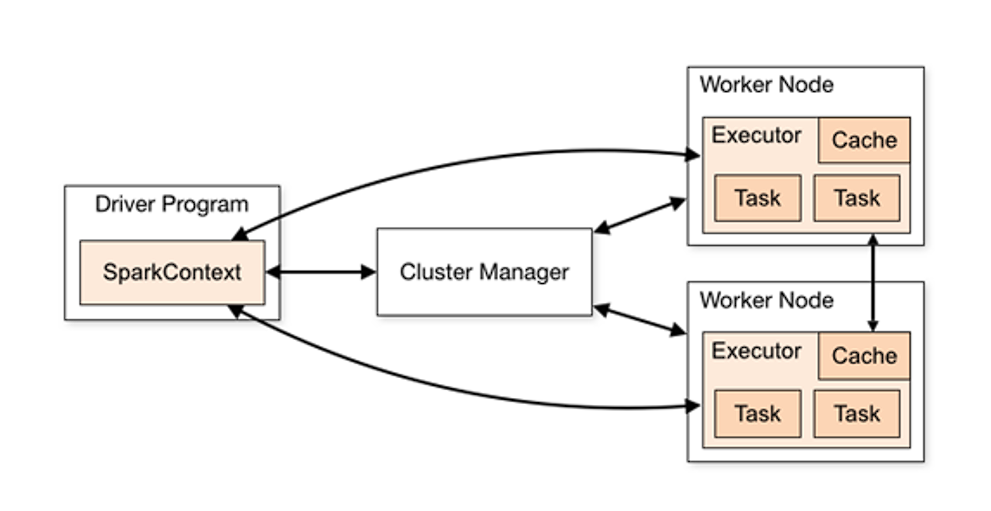
Application(应用):Spark 上运行的应用。Application 中包含了一个驱动器(Driver)进程和集群上的多个执行器(Executor)进程。
Driver Program(驱动器):运行 main () 方法并创建 SparkContext 的进程。
- Driver 在 Spark 作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在 Executor 之间调度任务 (task)
- 跟踪 Executor 的执行情况
- 通过 UI 展示查询运行情况
- Driver 在 Spark 作业执行时主要负责:
Cluster Manager(集群管理器):用于在集群上申请资源的外部服务(如:独立部署的集群管理器、Mesos 或者 Yarn)。
Worker Node(工作节点):集群上运行应用程序代码的任意一个节点。
Executor(执行器):在集群工作节点上为某个应用启动的工作进程,该进程负责运行计算任务,并为应用程序存储数据。
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
Task(任务):执行器的工作单元。
Job(作业):一个并行计算作业,由一组任务(Task)组成,并由 Spark 的行动(Action)算子(如:save、collect)触发启动。
Stage(阶段):每个 Job 可以划分为更小的 Task 集合,每组任务被称为 Stage。
Spark 目前支持几个集群管理器:
- Standalone :Spark 附带的简单集群管理器,可以轻松设置集群。
- Apache Mesos:通用集群管理器,也可以运行 Hadoop MapReduce 和服务应用程序。(已弃用)
- Hadoop YARN: Hadoop 2 和 3 中的资源管理器。
- Kubernetes:用于自动部署、扩展和管理容器化应用程序的开源系统。
# SparkCore 原理解析
# SparkCore
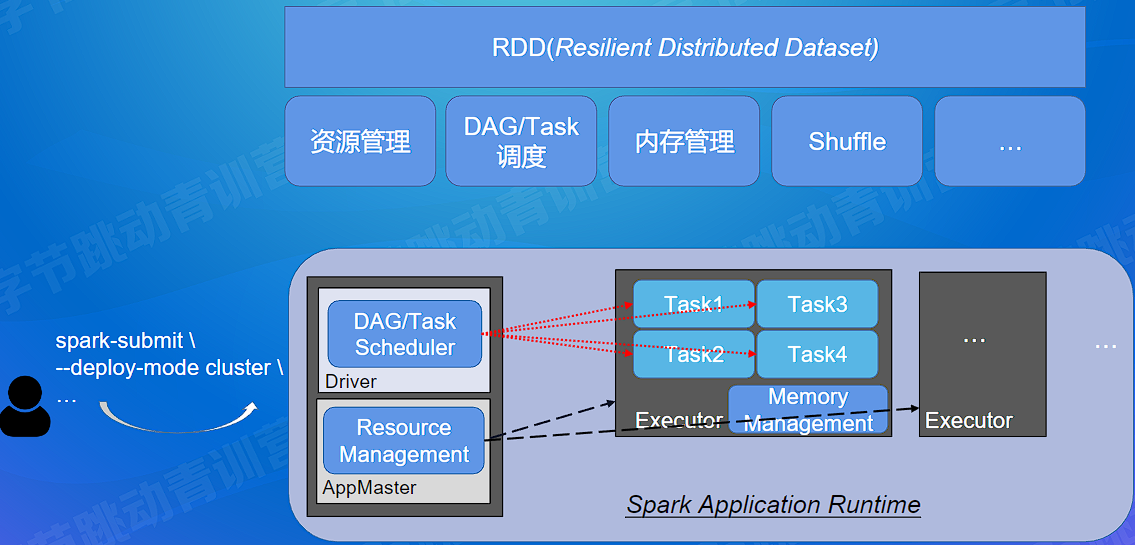
# RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
- 弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
- 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD 封装了计算逻辑,并不保存数据
- 数据抽象:RDD 是一个抽象类,需要子类具体实现
- 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
- 可分区、并行计算
# RDD 核心属性
- 分区列表
- RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
- 分区计算函数
- Spark 在计算时,是使用分区函数对每一个分区进行计算
- RDD 之间的依赖关系
- RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
- 分区器(可选)
- 当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
- 首选位置(可选)
- 计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
# RDD 创建
从集合(内存)中创建 RDD
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val rdd1 = sparkContext.parallelize(List(1,2,3,4))
val rdd2 = sparkContext.makeRDD(List(1,2,3,4))
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sparkContext.stop()
// 从底层代码实现来讲,makeRDD方法其实就是parallelize方法
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
从外部存储(文件)创建 RDD
由外部存储系统的数据集创建 RDD 包括:本地的文件系统,所有 Hadoop 支持的数据集,比如 HDFS、HBase 等。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val fileRDD: RDD[String] = sparkContext.textFile("input")
fileRDD.collect().foreach(println)
sparkContext.stop()
2
3
4
5
6
7
# RDD 算子
- Transform 算子:生成一个新的 RDD
- 如 map/filter/flatMap/groupByKey/reduceByKey/...
- Action 算子:触发 Job 提交
- 如 collect/count/take/saveAsTextFile/...
# RDD 依赖
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage(血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
RDD 依赖:描述父子 RDD 之间的依赖关系(lineage)
这里所谓的依赖关系,其实就是两个相邻 RDD 之间的关系
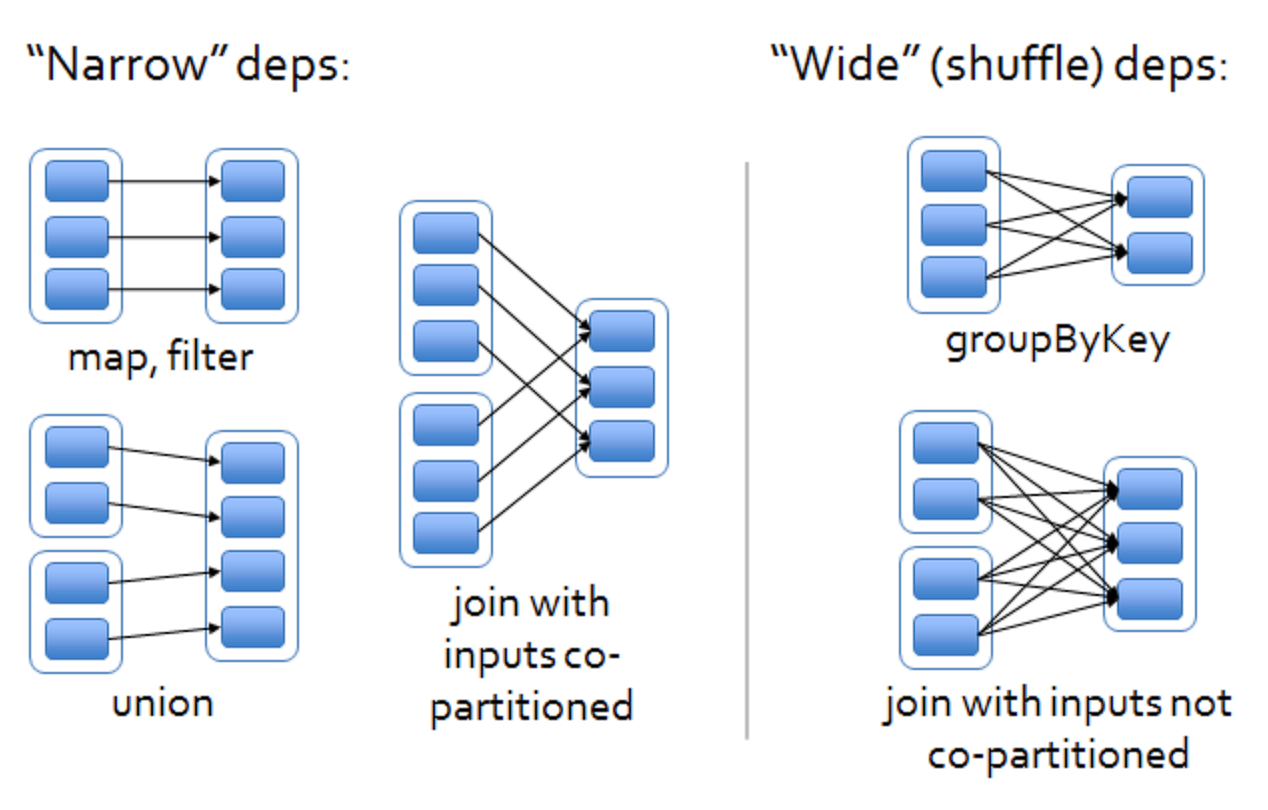
- 窄依赖:表示每一个父 (上游) RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用,窄依赖我们形象的比喻为独生子女。
- NarrowDependency
- OneToOneDependency
- RangeDependency
- PruneDependency
- 宽依赖(会产生 Shuffle):表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
- ShuffleDependency
# RDD 执行流程
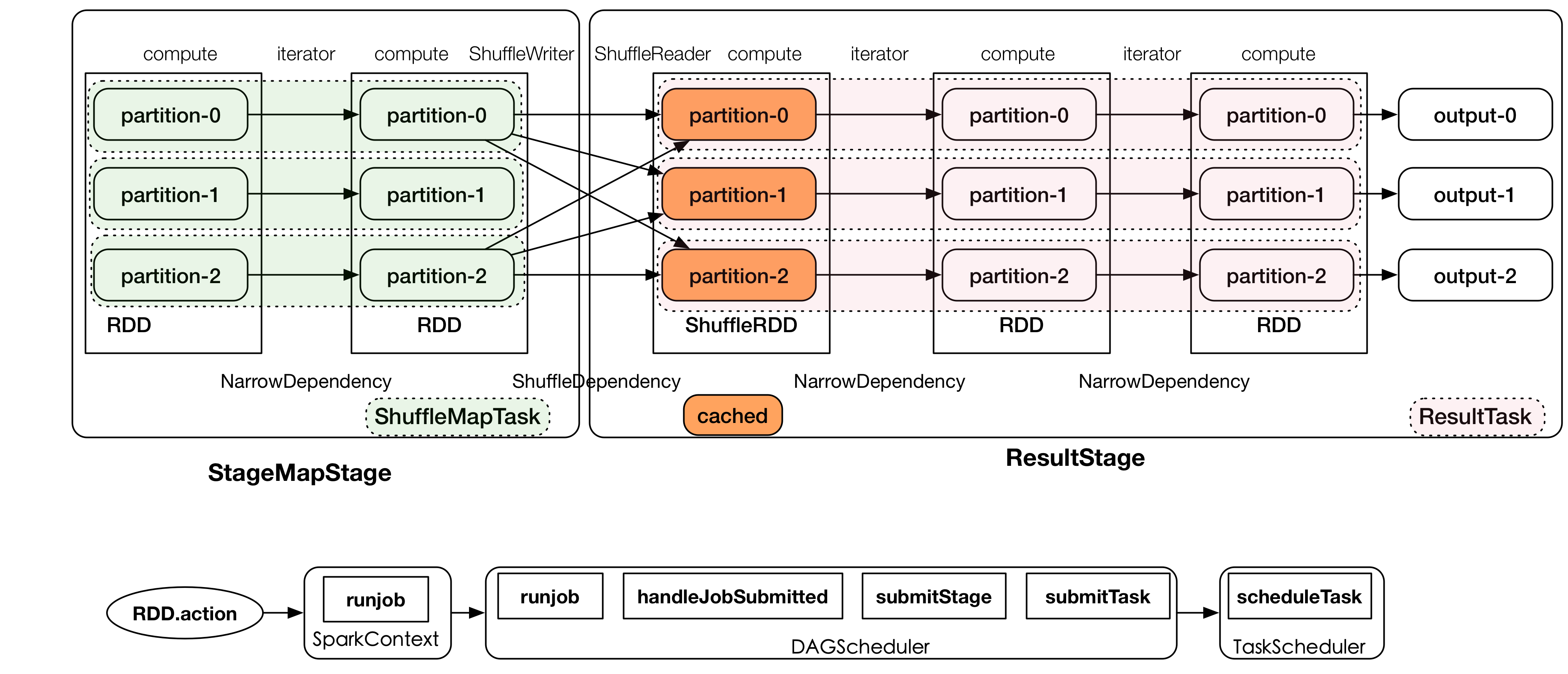
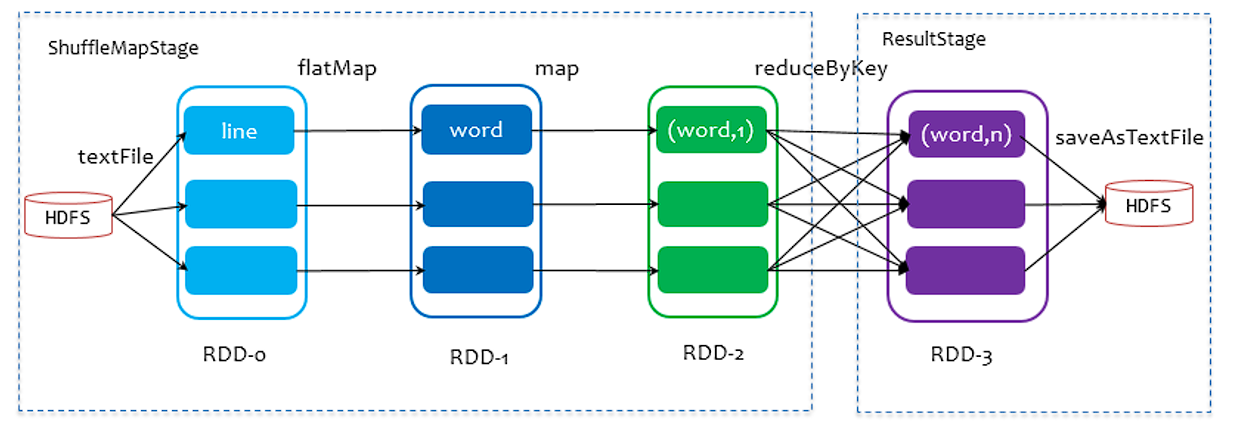
划分 Stage 的整体思路:从后往前推,遇到宽依赖就断开,划分为一个 Stage。遇到窄依赖,就将这个 RDD 加入该 Stage 中,DAG 最后一个阶段会为每个结果的 Partition 生成一个 ResultTask。每个 Stage 里面的 Task 数量由最后一个 RDD 的 Partition 数量决定,其余的阶段会生成 ShuffleMapTask。
当 RDD 对象创建后,SparkContext 会根据 RDD 对象构建 DAG 有向无环图,然后将 Task 提交给 DAGScheduler。DAGScheduler 根据 ShuffleDependency 将 DAG 划分为不同的 Stage,为每个 Stage 生成 TaskSet 任务集合,并以 TaskSet 为单位提交给 TaskScheduler。TaskScheduler 根据调度算法 (FIFO/FAIR) 对多个 TaskSet 进行调度,并通过集群中的资源管理器 (Standalone 模式下是 Master,Yarn 模式下是 ResourceManager) 把 Task 调度 (locality) 到集群中 Worker 的 Executor,Executor 由 SchedulerBackend 提供。
RDD 任务切分中间分为:Application、Job、Stage 和 Task
- Application:初始化一个 SparkContext 即生成一个 Application;
- Job:一个 Action 算子就会生成一个 Job;
- Stage:Stage 等于宽依赖 (ShuffleDependency) 的个数加 1;
- Task:一个 Stage 阶段中,最后一个 RDD 的分区个数就是 Task 的个数。
# Scheduler(调度器)
当 Driver 起来后,Driver 则会根据用户程序逻辑准备任务,并根据 Executor 资源情况逐步分发任务。在详细阐述任务调度前,首先说明下 Spark 里的几个概念。一个 Spark 应用程序包括 Job、Stage 以及 Task 三个概念:
- Job 是以 Action 方法为界,遇到一个 Action 方法则触发一个 Job;
- Stage 是 Job 的子集,以 RDD 宽依赖 (即 Shuffle) 为界,遇到 Shuffle 做一次划分;
- Task 是 Stage 的子集,以并行度 (分区数) 来衡量,分区数是多少,则有多少个 task。
Spark 的任务调度总体来说分两路进行,一路是 Stage 级的调度,一路是 Task 级的调度,总体调度流程如下图所示:
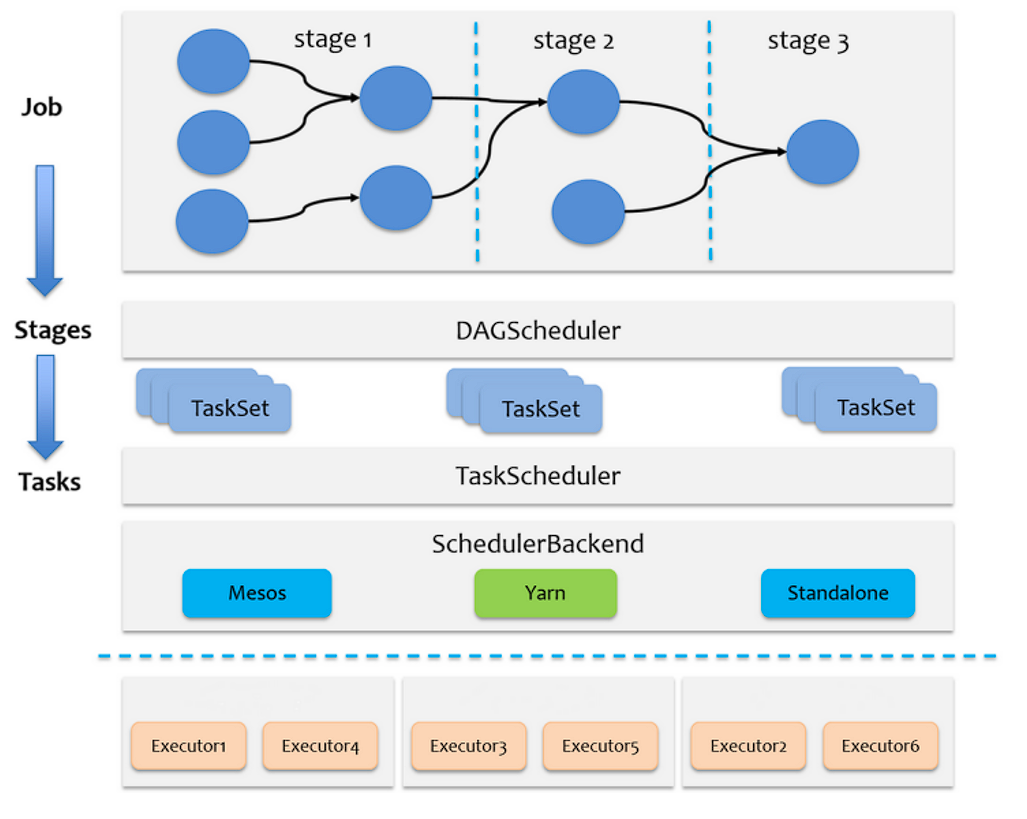
Spark RDD 通过其 Transactions 操作,形成了 RDD 血缘(依赖)关系图,即 DAG,最后通过 Action 的调用,触发 Job 并调度执行,执行过程中会创建两个调度器:DAGScheduler 和 TaskScheduler。
- DAGScheduler 负责 Stage 级的调度,主要是将 job 切分成若干 Stages,并将每个 Stage 打包成 TaskSet 交给 TaskScheduler 调度。
- TaskScheduler 负责 Task 级的调度,将 DAGScheduler 给过来的 TaskSet 按照指定的调度策略分发到 Executor 上执行,调度过程中 SchedulerBackend 负责提供可用资源,其中 SchedulerBackend 有多种实现,分别对接不同的资源管理系统。
- TaskScheduler 支持两种调度策略,一种是 FIFO,也是默认的调度策略,另一种是 FAIR。
# Memory Management(内存管理)
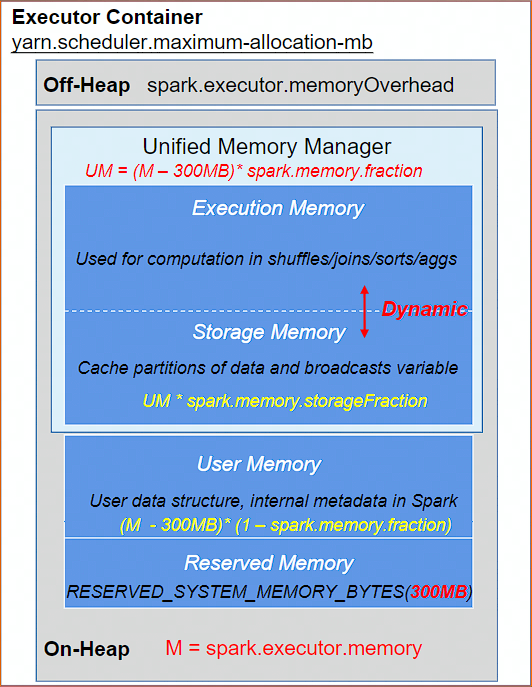
Spark 作为一个基于内存的分布式计算引擎,Spark 采用统一内存管理机制。重点在于动态占用机制。
设定基本的存储内存 (Storage) 和执行内存 (Execution) 区域,该设定确定了双方各自拥有的空间的范围,UnifiedMemoryManager 统一管理 Storage/Execution 内存
UnifiedMemoryManager 统一管理多个并发 Task 的内存分配
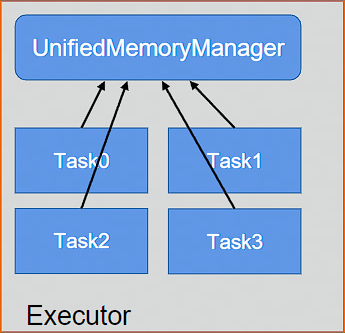
每个 Task 获取的内存区间为
~ , N 为当前 Executor 中正在并发运行的 task 数量
双方的空间都不足时,则存储到硬盘;若己方空间不足而对方空余时,可借用对方的空间
当 Storage 空闲,Execution 可以借用 Storage 的内存使用,可以减少 spill 等操作, Execution 内存不能被 Storage 驱逐。Execution 内存的空间被 Storage 内存占用后,可让对方将占用的部分转存到硬盘,然后 "归还" 借用的空间
当 Execution 空闲,Storage 可以借用 Execution 内存使用,当 Execution 需要内存时,可以驱逐被 Storage 借用的内存,可让对方将占用的部分转存到硬盘,然后 "归还" 借用的空间
user memory 存储用户自定义的数据结构或者 spark 内部元数据
Reserverd memory:预留内存,防止 OOM,
堆内 (On-Heap) 内存 / 堆外 (Off-Heap) 内存:Executor 内运行的并发任务共享 JVM 堆内内存。为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 可以直接操作系统堆外内存,存储经过序列化的二进制数据。减少不必要的内存开销,以及频繁的 GC 扫描和回收,提升了处理性能。
# Shuffle
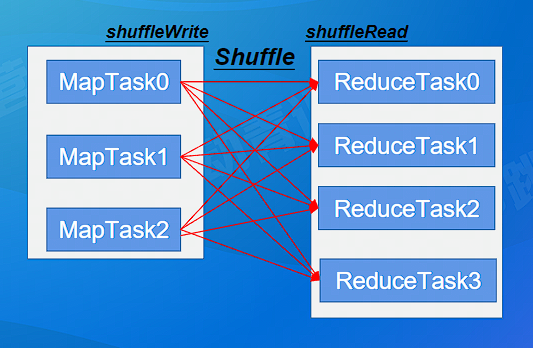
Spark 是以 Shuffle 为边界,将一个 Job 划分为不同的 Stage,这些 Stage 构成了一个大粒度的 DAG。Spark 的 Shuffle 主要分为 Shuffle Write 和 Shuffle Read 两个阶段。
执行 Shuffle 的主体是 Stage 中的并发任务,这些任务分为 ShuffleMapTask 和 ResultTask 两大类。ShuffleMapTask 要进行 Shuffle,ResultTask 负责返回计算结果,一个 Job 中只有最后一个 Stage 采用 ResultTask,其它均为 ShuffleMapTask。ShuffleMapStage 的结束伴随着 shuffle 文件的写磁盘。
- Shuffle Write 阶段:发生于 ShuffleMapTask 对该 Stage 的最后一个 RDD 完成了 map 端的计算之后,首先会判断是否需要对计算结果进行聚合,然后将最终结果按照不同的 reduce 端进行区分,写入前节点的本地磁盘。
- Shuffle Read 阶段:开始于 reduce 端的任务读取 ShuffledRDD 之后,首先通过远程或者本地数据拉取获得 Write 阶段各个节点中属于当前任务的数据,根据数据的 Key 进行聚合,然后判断是否需要排序,最后生成新的 RDD。
# SortShuffl
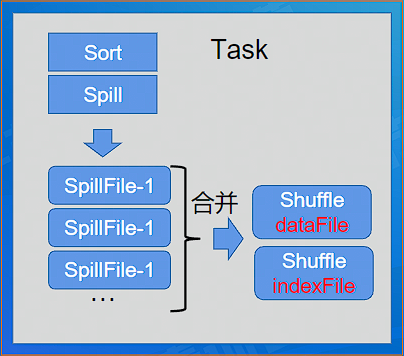
每个 MapTask 生成一个 Shuffle 数据文件和一个 index 文件,该文件中的记录首先是按照 Partition Id 排序,每个 Partition 内部再按照 Key 进行排序,Map Task 运行期间会顺序写每个 Partition 的数据,同时生成一个索引文件记录每个 Partition 的大小和偏移量。
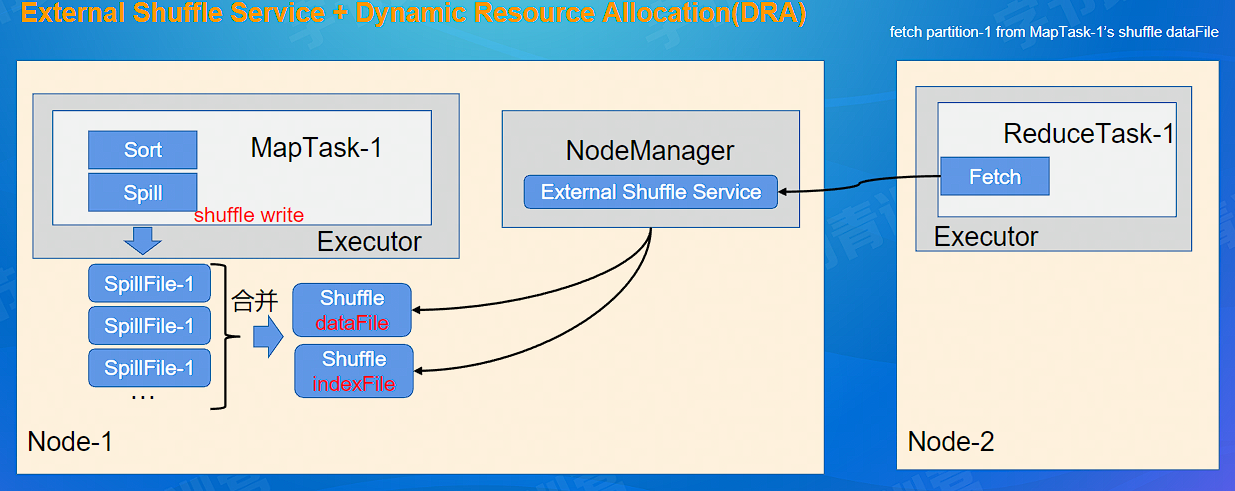
shuffle write 的文件被 NodeManage r 中的 Shuffle Service 托管,供后续 Reduce Task 进行 shuffle fetch, 如果 Executor 空闲,DRA 可以进行回收
# SparkSQL 原理解析
Spark SQL 是 Spark 的其中一个模块,用于结构化数据处理。与基本的 Spark RDD API 不同,Spark SQL 提供的接口为 Spark 提供了有关数据结构和正在执行的计算的更多信息,Spark SQL 会使用这些额外的信息来执行额外的优化。
下图为 Spark SQL 的流程
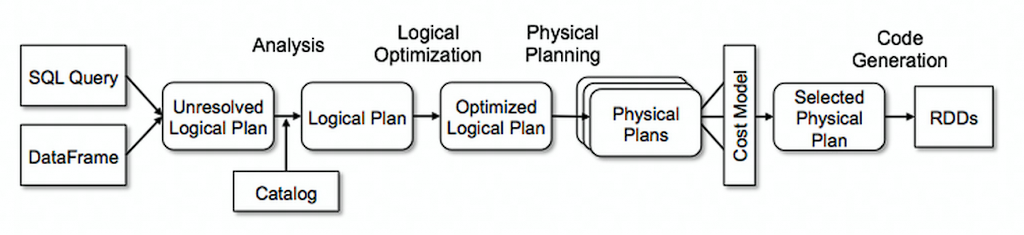
- SQL Parse: 将 SparkSQL 字符串或 DataFrame 解析为一个抽象语法树 / AST,即 Unresolved Logical Plan
- Analysis:遍历整个 AST,并对 AST 上的每个节点进行数据类型的绑定以及函数绑定,然后根据元数据信息 Catalog 对数据表中的字段进行解析。 利用 Catalog 信息将 Unresolved Logical Plan 解析成 Analyzed Logical plan
- Logical Optimization:该模块是 Catalyst 的核心,主要分为 RBO 和 CBO 两种优化策略,其中 RBO 是基于规则优化,CBO 是基于代价优化。 利用一些规则将 Analyzed Logical plan 解析成 Optimized Logic plan
- Physical Planning: Logical plan 是不能被 spark 执行的,这个过程是把 Logic plan 转换为多个 Physical plans
- CostModel: 主要根据过去的性能统计数据,选择最佳的物理执行计划 (Selected Physical Plan)。
- Code Generation: sql 逻辑生成 Java 字节码
# Catalyst 优化器
# RBO
Rule Based Optimizer (RBO): 基于规则优化,对语法树进行一次遍历,模式匹配能够满足特定规则的节点,再进行相应的等价转换。
下图为 逻辑树 --> RBO 规则执行 --> 物理树 流程
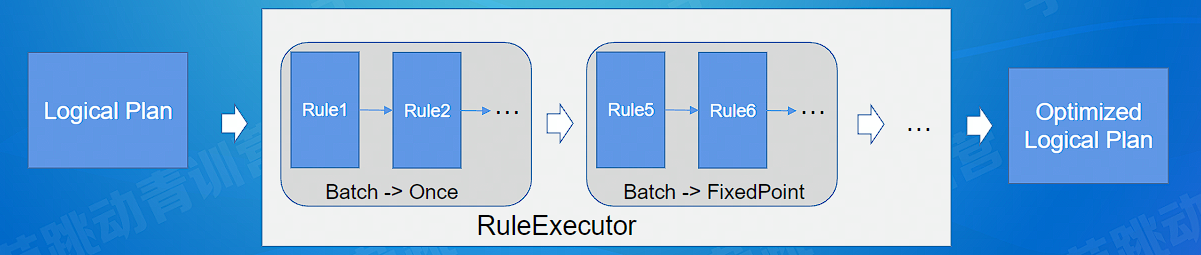
Batch 执行策略:
- Once:只执行一次
- FixedPoint:重复执行,直到 plan 不再改变, 或者执行达到固定次数 (默认 100 次)
两种遍历规则:
- transformDown 先序遍历树进行规则匹配
- transformUp 后序遍历树进行规则匹配
# CBO
Cost Based Optimizer (CBO): 基于代价优化,根据优化规则对关系表达式进行转换,生成多个执行计划,然后 CBO 会通过根据统计信息 (Statistics) 和代价模型 (Cost Model) 计算各种可能执行计划的代价,从中选用 COST 最低的执行方案,作为实际运行方案。CBO 依赖数据库对象的统计信息,统计信息的准确与否会影响 CBO 做出最优的选择。
JoinSelection
- Broadcast Join:大表和小表
- Shuffle Hash Join
- SortMergeJoin:大表
# Adaptive Query Execution(AQE)
AQE 对于整体的 Spark SQL 的执行过程做了相应的调整和优化,它最大的亮点是可以根据已经完成的计划结点真实且精确的执行统计结果来不停的反馈并重新优化剩下的执行计划。每个 Task 结束会发送 MapStatus 信息给 Driver,Task 的 MapStatus 中包含当前 Task Shuffle 产生的每个 Partition 的 size 统计信息,Driver 获取到执行完的 StagesMapStatus 信息之后,按照 MapStatus 中 partition 大小信息识别匹配一些优化场景,然后对后续未执行的 Plan 进行优化。
AQE 框架三种优化场景:
- 动态合并 shuffle 分区(Dynamically coalescing shuffle partitions)
- 动态调整 Join 策略(Dynamically switching join strategies)
- 动态优化数据倾斜 Join(Dynamically optimizing skew joins)
# Coalescing Shuffle Partitions
未经动态合并 Shuffle 分区时
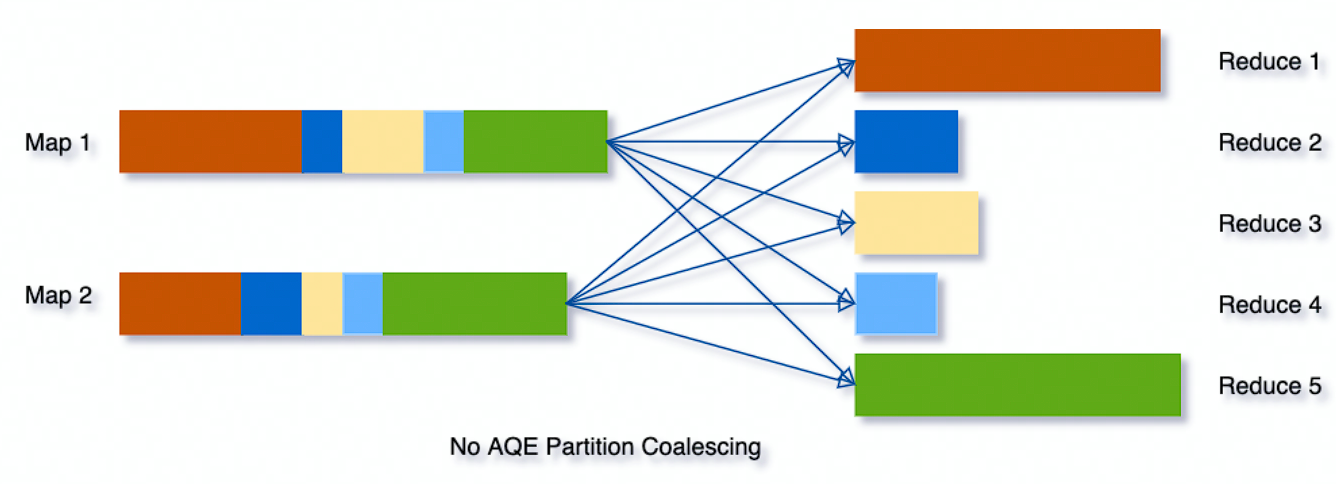
动态合并 Shuffle 后
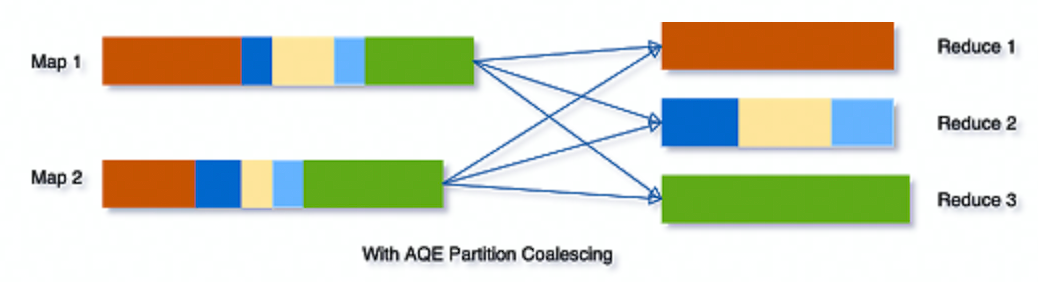
作业运行过程中,根据前面运行完的 Stage 的 MapStatus 中实际的 partiton 大小信息,可以将多个相邻的较小的 partiton 进行动态合并,由一个 Task 读取进行处理。
spark.sql.adaptive.coalescePartitions.enabled
spark.sql.adaptive.coalescePartitions.initialPartitionNum
spark.sql.adaptive.advisoryPartitionSizelnBytes
2
3
# Switching Join Strategies
AQE 运行过程中动态获取准确 Join 的 leftChild/rightChild 的实际大小,将 SortMergeJoin (SMJ) 转化为 BroadcastHashJoin (BHJ)
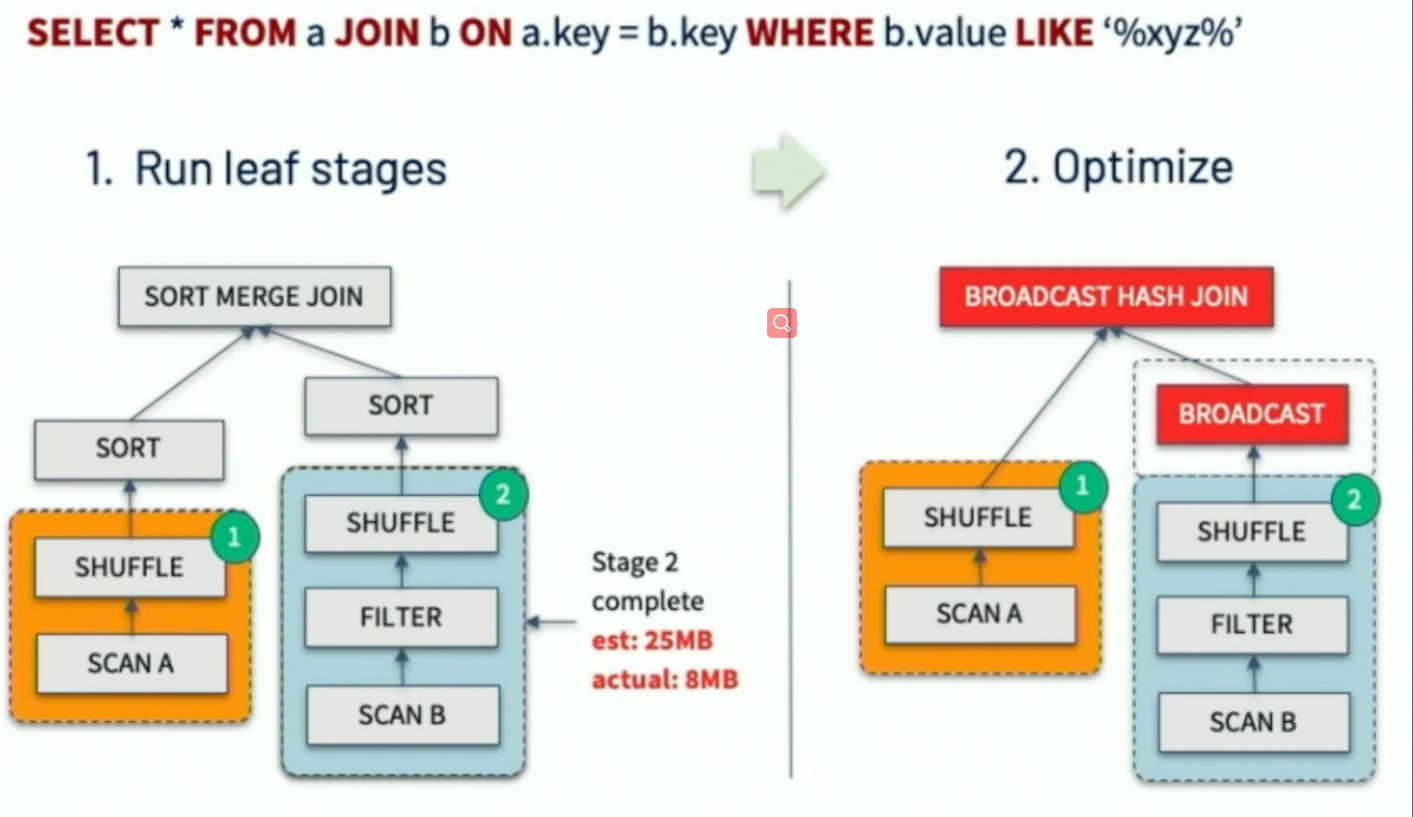
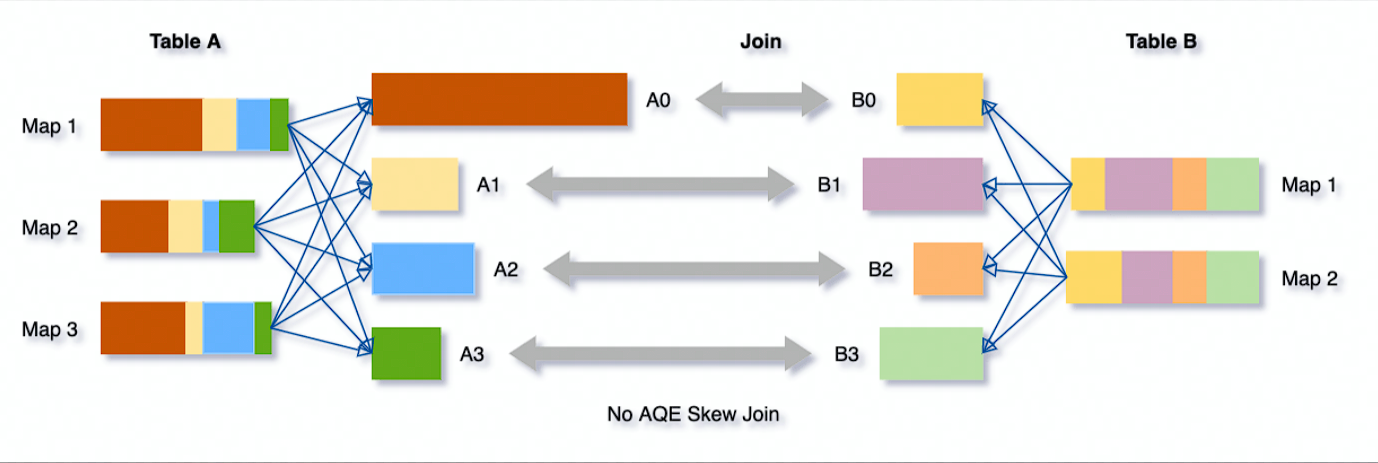
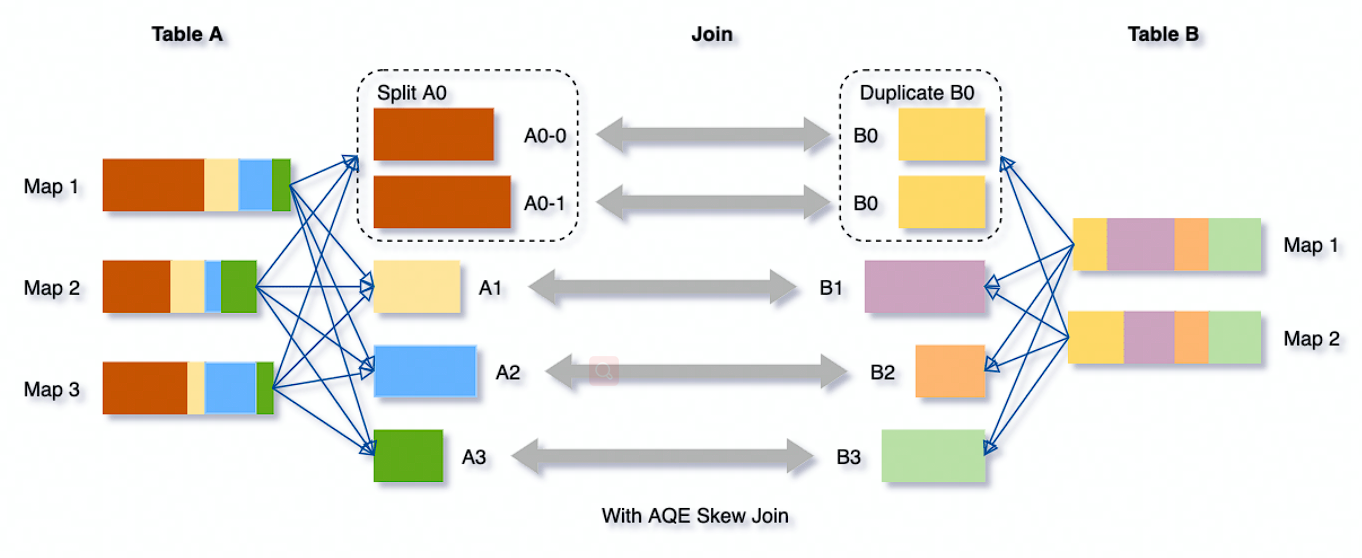
# Optimizing Skew Joins
AQE 根据 MapStatus 信息自动检测是否有倾斜,将大的 partition 拆分成多个 Task 进行 Join。
未优化前
优化后
spark.sql.adaptive.skewJoin.enabled
spark.sql.adaptive.skewJoin.skewedPartitionFactor
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBvtes
2
3
# Runtime Filter
实现在 Catalyst 中。动态获取 Filter 内容做相关优化,当我们将一张大表和一张小表等值连接时,我们可以从小表侧收集一些统计信息,并在执行 join 前将其用于大表的扫描,进行分区修剪或数据过滤。可以大大提高性能
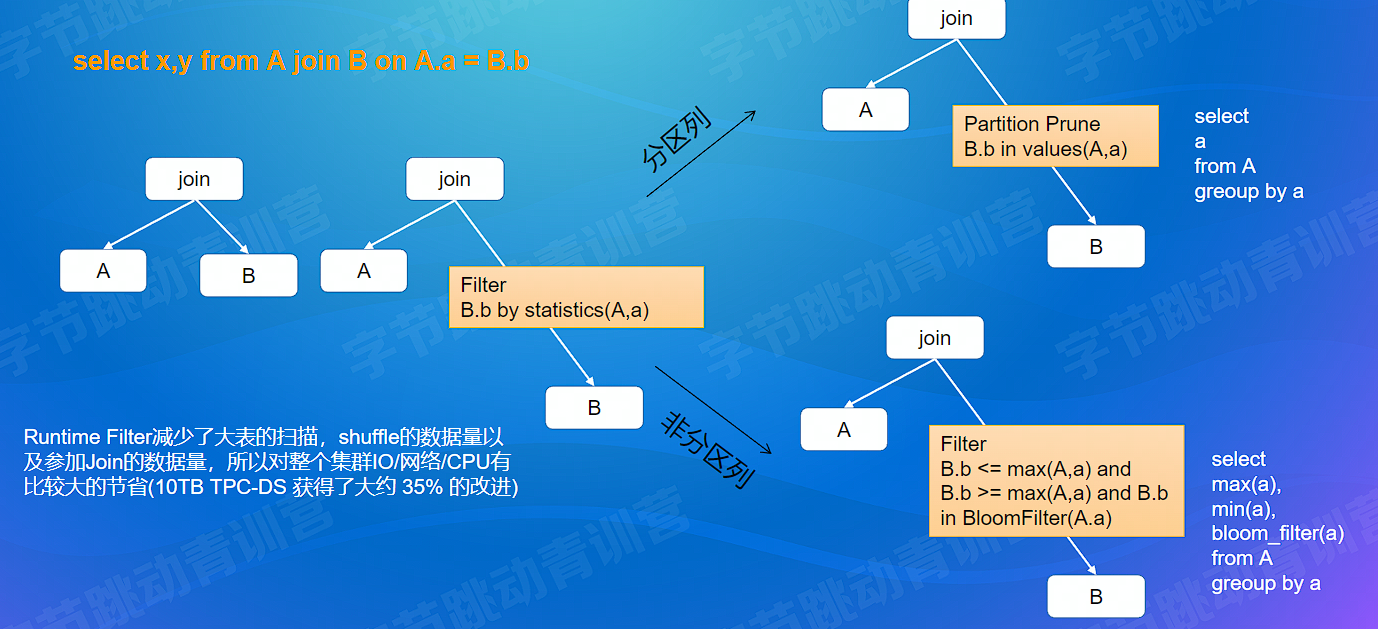
Runtime 优化分两类:
- 全局优化:从提升全局资源利用率、消除数据倾斜、降低 IO 等角度做优化。包括 AQE。
- 局部优化:提高某个 task 的执行效率,主要从提高 CPU 与内存利用率的角度进行优化。依赖 Codegen 技术。
# Codegen
从提高 cpu 的利用率的角度来进行 runtime 优化。
- Expression 级别
表达式常规递归求值语法树。需要做很多类型匹配、虚函数调用、对象创建等额外逻辑,这些 overhead 远超对表达式求值本身,为了消除这些 overhead,Spark Codegen 直接拼成求值表达式的 java 代码并进行即时编译
- WholeStage 级别
传统的火山模型:SQL 经过解析会生成一颗查询树,查询树的每个节点为 Operator,火山模型把 operator 看成迭代器,每个迭代器提供一个 next () 接口。通过自顶向下的调用 next 接口,数据则自底向上的被拉取处理,火山模型的这种处理方式也称为拉取执行模型,每个 Operator 只要关心自己的处理逻辑即可,耦合性低。
火山模型问题:数据以行为单位进行处理,不利于 CPU cache 发挥作用;每处理一行需要调用多次 next () 函数,而 next () 为虚函数调用。会有大量类型转换和虚函数调用。虚函数调用会导致 CPU 分支预测失败,从而导致严重的性能回退
Spark WholestageCodegen:为了消除这些 overhead,会为物理计划生成类型确定的 java 代码。并进行即时编译和执行。
Codegen 打破了 Stage 内部算子间的界限,拼出来跟原来的逻辑保持一致的裸的代码(通常是一个大循环)然后把拼成的代码编译成可执行文件。
# 业界挑战与实践
# Shuffle 稳定性问题
在大规模作业下 开源 ESS 的实现机制容易带来大量随机读导致磁盘的 IOPS 瓶颈、fetch 请求积压等问题,进而导致运算过程中经常出现 stage 重算及作业失败继而引起资源使循环
- 业内目前解决方案:各公司开源的 RemoteShuffleService 进行优化
# SQL 执行性能问题
压榨 CPU 资源 CPU 瓶颈
- 超标量流水线 / 乱序执行 / 分支预测 并行程序越多越好 / CPU 缓存友好(后续 cache 预存)/SIMD(单指令多数据流)
- Vectorized 向量化(拉取模式函数返回一批 CPU 开销一组数据分摊 适用于列存储 缺点中间数据很大)/ Codegen (打破算子之间界限,复合算子)
- Codegen 限制 Java 代码,相对 native C++ 等性能有缺陷,无法进行 SIMD 优化
# 参数推荐 / 作业诊断
- 问题:
- Spark 参数很多,资源类 /shuffle/join/agg 等,调参难度大
- 参数不合理的作业对资源利用率 /shuffle 稳定性 / 性能有非常大影响
- 线上作业失败 / 运行慢,用户排查难度大
- 解决方案:
- 自动参数推荐 / 作业诊断