实时数据中心建设思路与企业实践| 青训营笔记
实时数据中心建设思路与企业实践| 青训营笔记
# 实时数据中心建设思路与企业实践| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第 18 天
# 企业数据架构
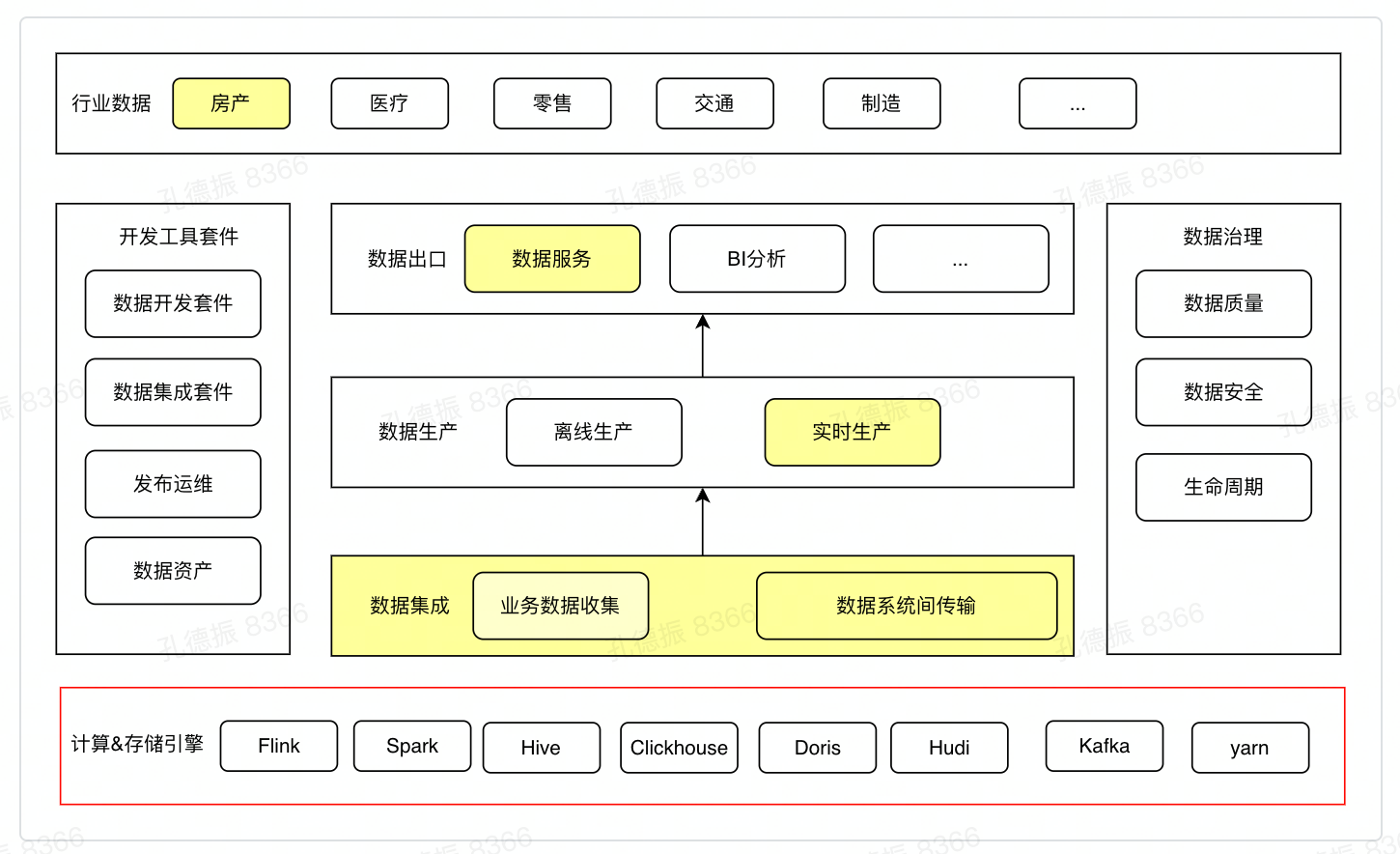
企业整体数据架构:基础引擎、数据集成 / 生产 / 服务、开发和治理工具
关键模块及数据流向
- 数据集成
- 业务数据收集:数据库变更数据收集 (CDC)、业务日志收集 (业务数据 -> 数据处理系统)
- 大数据系统内传输:基于 Flink 丰富的 connector 体系 (数据系统内)
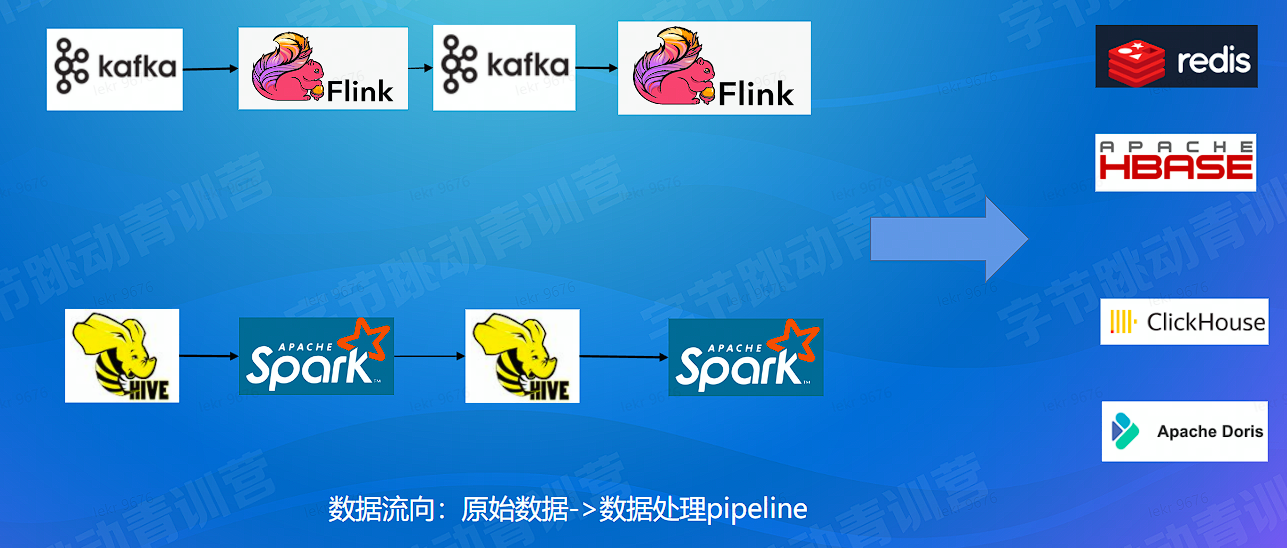
- 数据生产:实时和离线生产 pipeline (数据系统内)
- 数据服务:统一数据服务架构 (数据系统 -> 业务系统)
- 数据集成
# 数据集成
# 数据集成 - 业务数据收集 - CDC
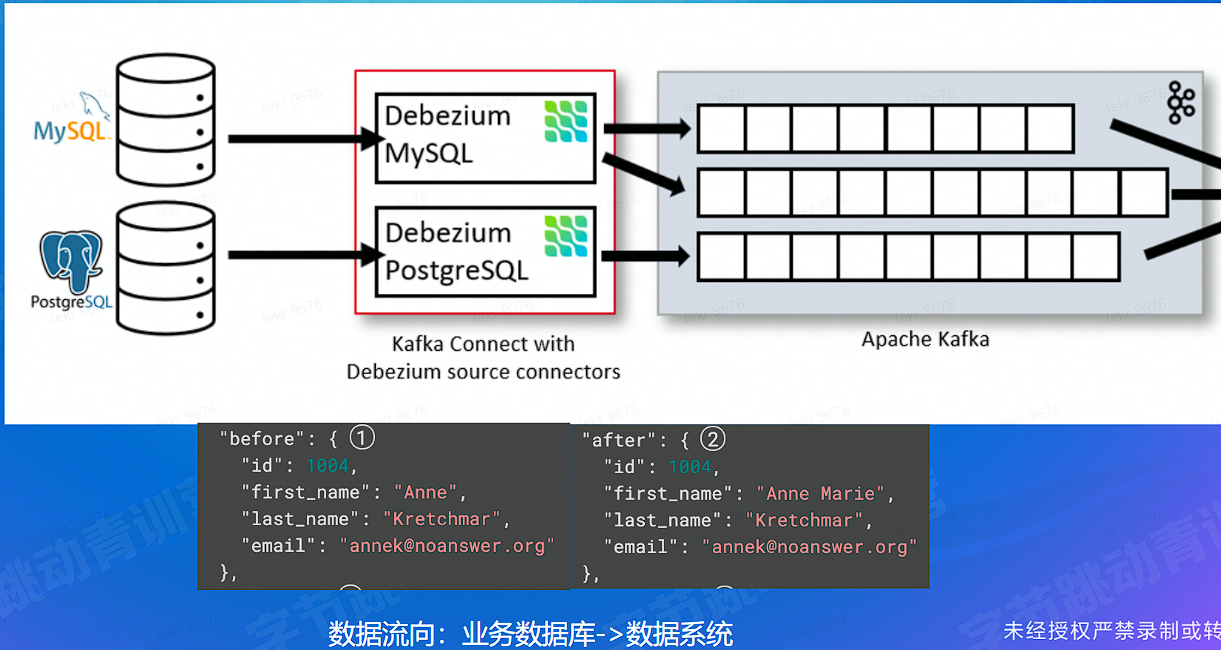
# 数据集成 - 业务数据收集 - Log
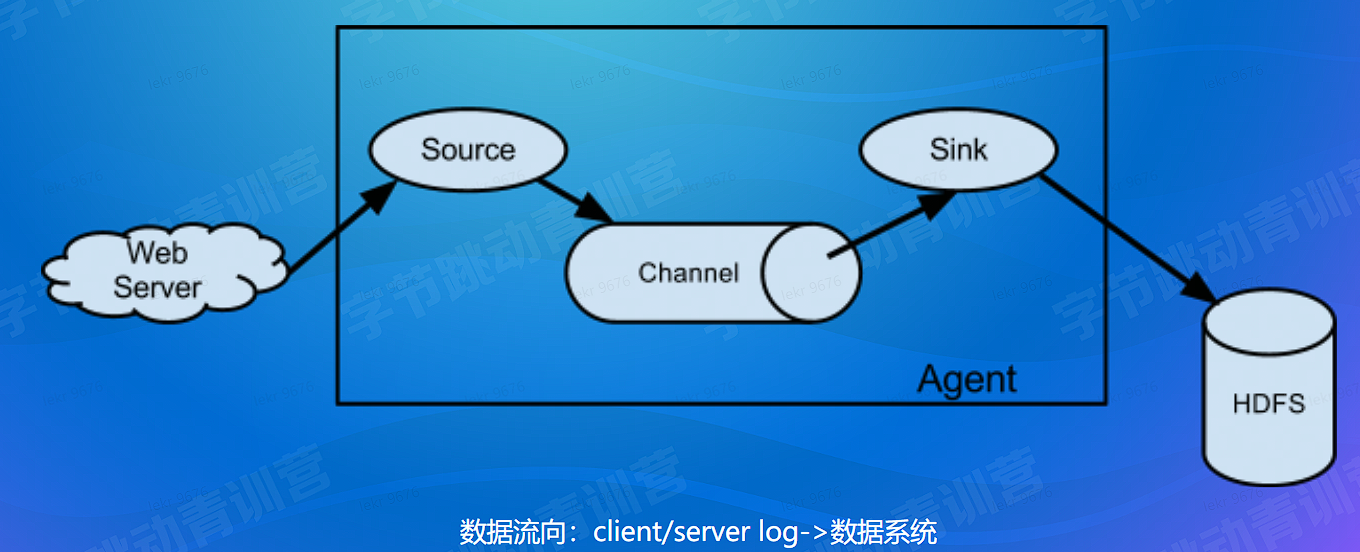
# 数据集成 - 系统间同步传输
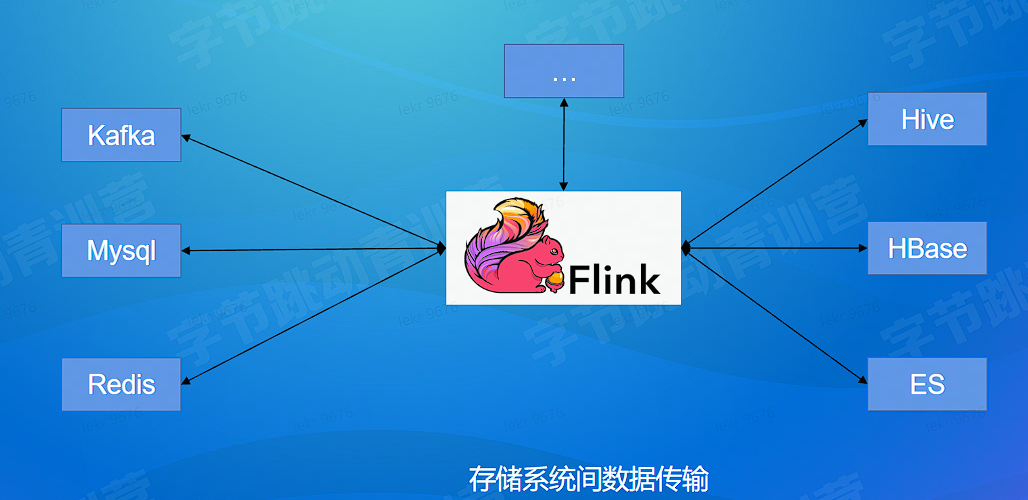
# 数据生产
# 数据生产 - 离线 & 实时
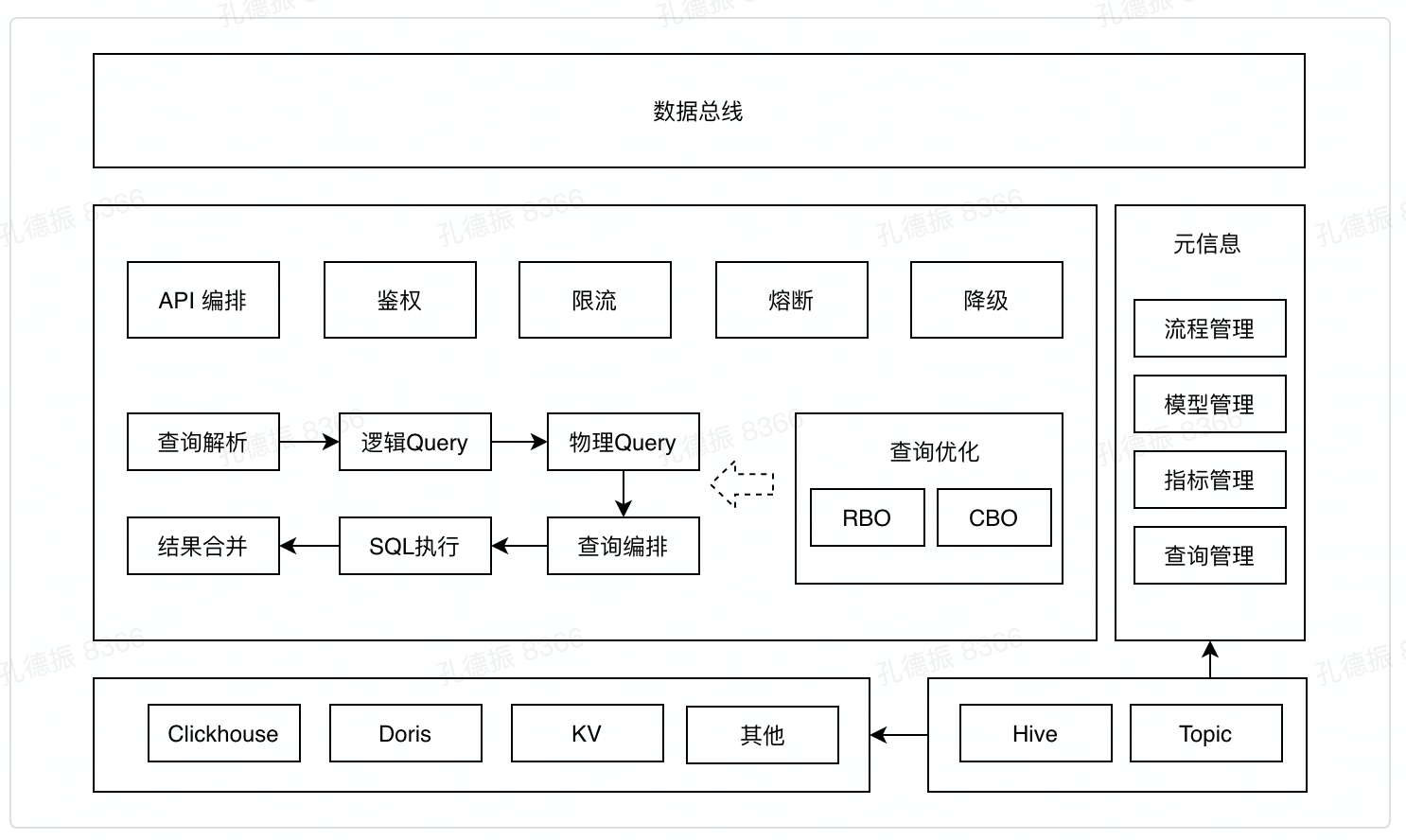
# 数据服务
数据流向:数据系统 -> 业务系统
# 数据中心案例
# 房产业务介绍
以房产业务举例说明数据中心建设目标和要求
房产业务介绍:房产服务平台、经纪人、客户
数据中心核心指标分析:供需、过程、结果
数据中心查询要求:查询条件、数据结果、技术要求
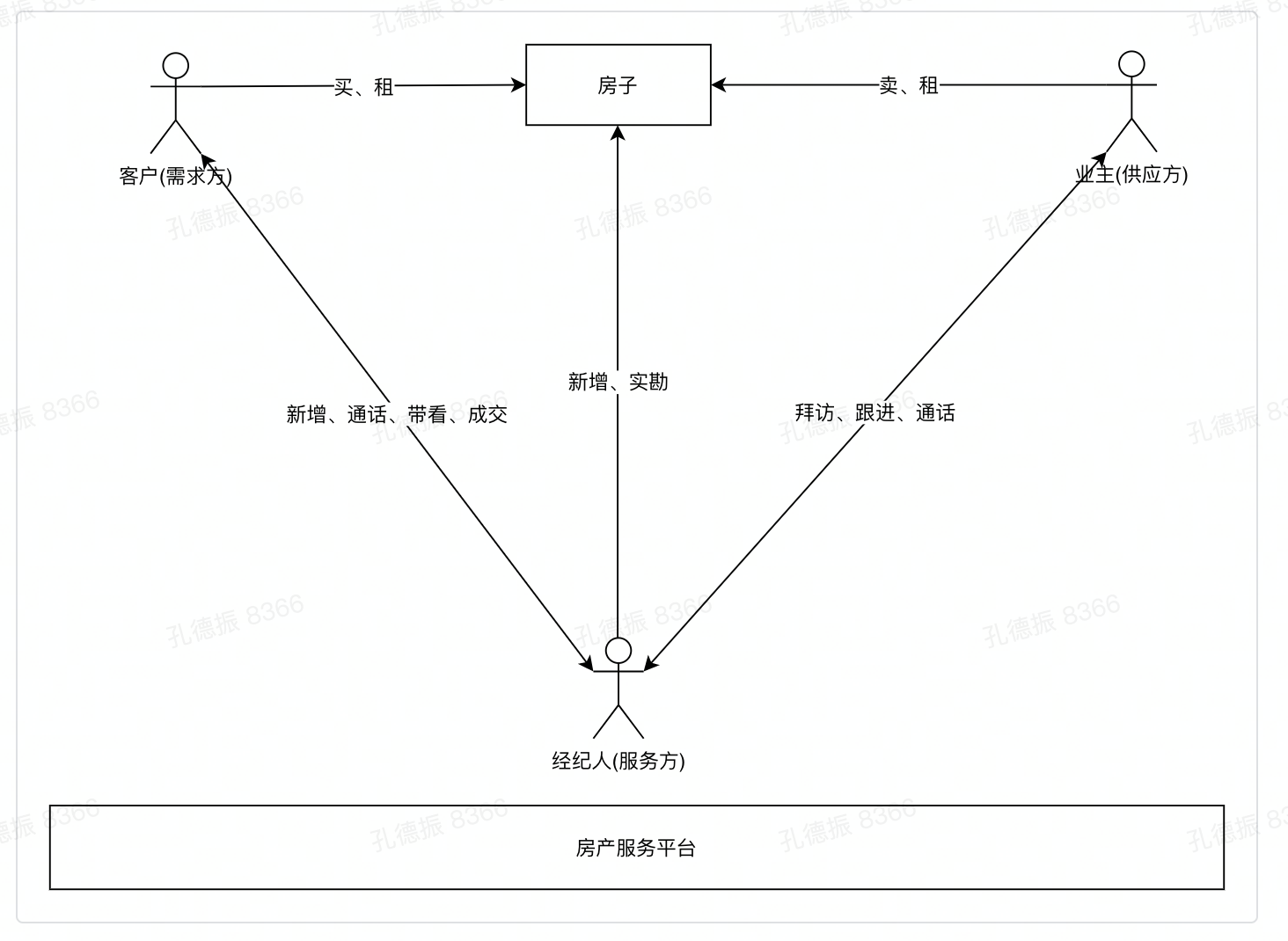
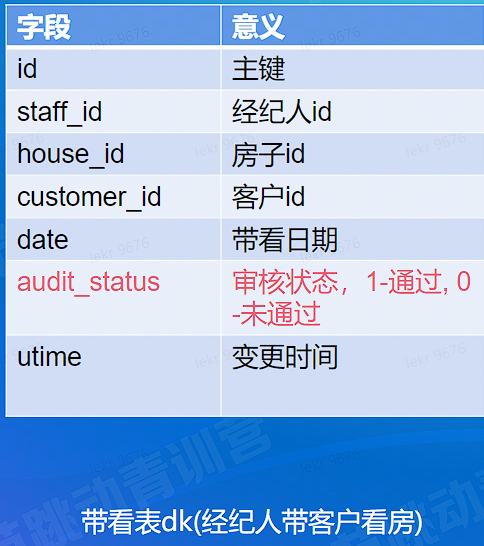
# 房产数据中心 - 核心数据指标
- 供需 (房子全不全? 客户多不多?)
- 房源
- 房增 (新增房子的录入量)
- 客源
- 客增 (新增客户的录入量)
- 房源
- 过程 (工作做的怎么样?)
- 通话次数 (经纪人和客户电话次数)
- 带看次数 (经纪人带客户看房次数)
- 结果 (结果好不好?)
- 成交量 (成交合同量)
# 房产数据中心 - 数据查询要求
数据中心看板查询条件:
- 时间范围:今天前的任意日期范围
- 业务类型:租赁 / 买卖 / 全部
数据展示:
- 查询条件下的每个经纪人的汇总数据
- 支持下钻明细数据
技术要求:
- 300ms 内返回结果
- 数据是实时秒级
# 实时数据生产
案例生产方案分析:数据探查、明确指标口径和产出粒度、生产架构、计算难点
数据探查:分析数据信息是否齐全,即基于原始数据计算指标可行性
数据架构:lambda 架构和全量计算架构比对,确定合适的生产架构方案
计算难点解决
- 全量数据获取:hybrid source
- 精确计算
- 去重 & 更新处理:基于 retract 机制
- 乱序问题解决:流 join 乱序问题方案
- 计算效率
- MiniBatch - 聚合计算
- MiniBatch-join
数据质量
- 任务稳定性:消费 LAG、JVM、资源、算子
- 数据正确性:和离线比对、趋势比对、异常值占比
实时数仓
- 数据分层:数据复用,减少重复开发
- 数据管理:格式、元数据
# 数据分析
# 数据分析 - 数据产出目标
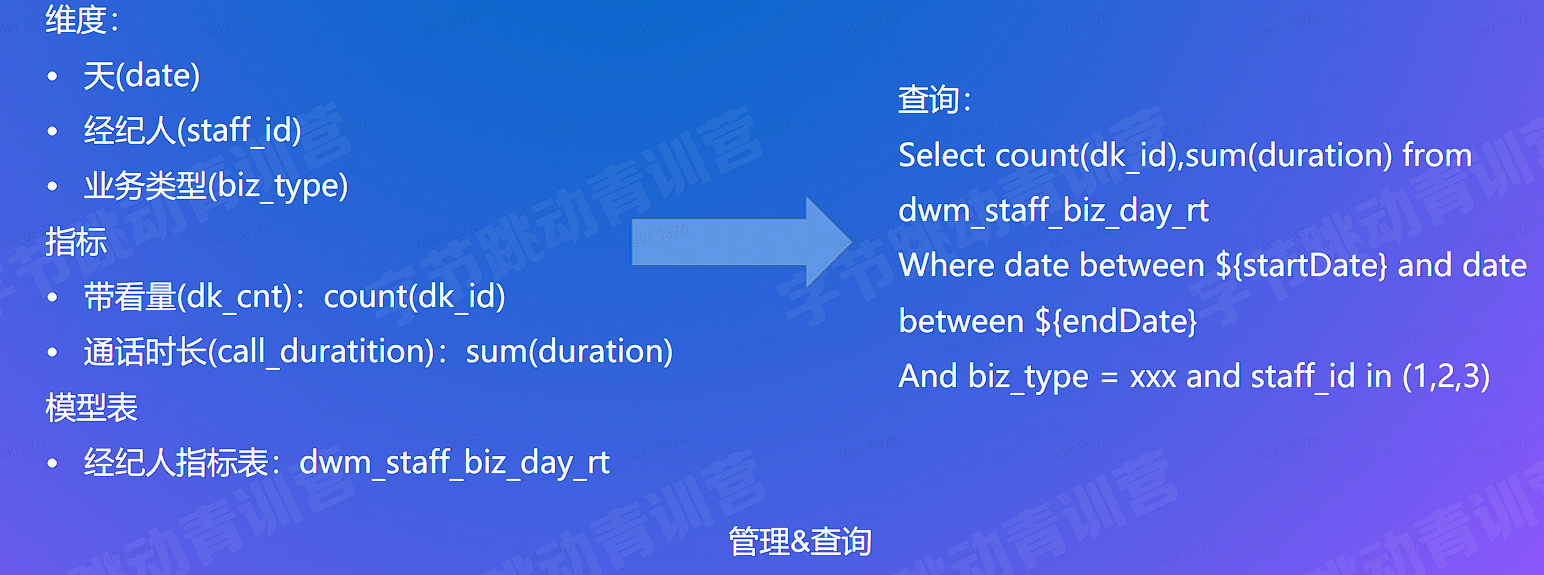
用户要什么数据? 根据日期、业务类型 (买卖、租赁) 查询经纪人汇总数据
目标数据产出粒度:经纪人 + 业务日期 + 业务类型
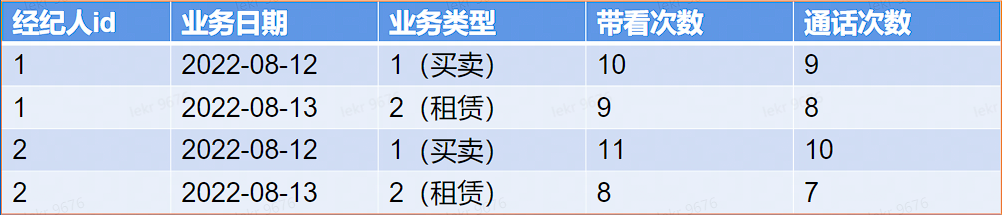
# 数据分析 - 数据生产可行性
生产逻辑:
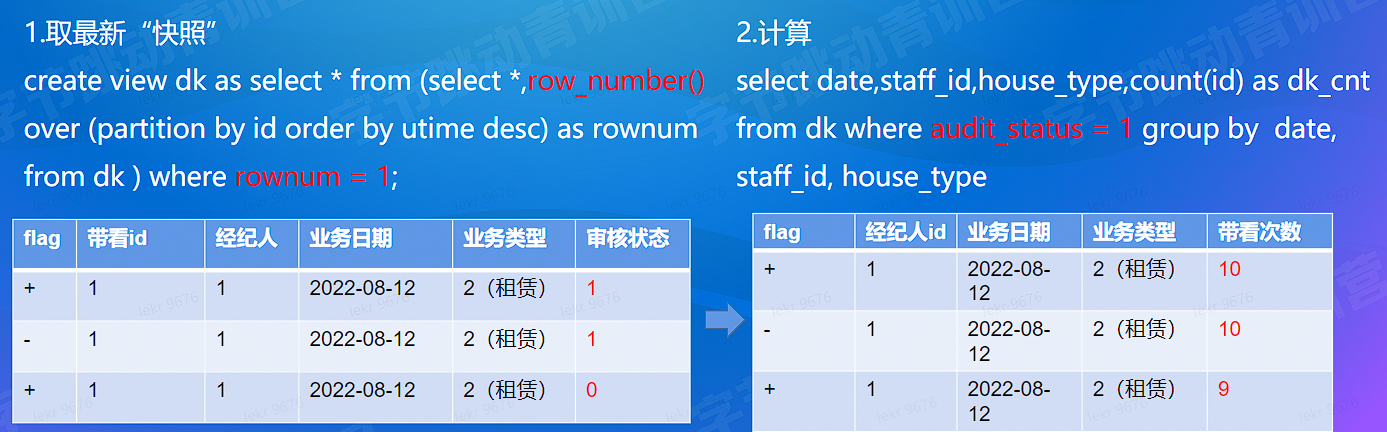
select
Dk.date,-- 日期
Dk.staff_id, -- 经纪人
House.house_type, -- 业务类型
Count(id) as dk_cnt -- 指标,带看量
from dk left join house On dk.house id = house.house id
Where audit_status = 1 -- (可变更)
Group by dk.date, Dk.staff_id, house.house_type
2
3
4
5
6
7
8
# 计算分析
# 计算分析 - 目标
- 开发效率:较快满足用户的需要
- 资源成本:计算效率高
- 数据质量:准确无误、数据实时
# 计算分析 - 计算架构 - Lambda
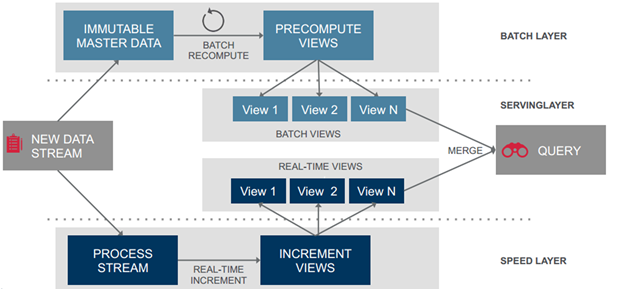
# 计算分析 - Lambda 架构 - 数据产出
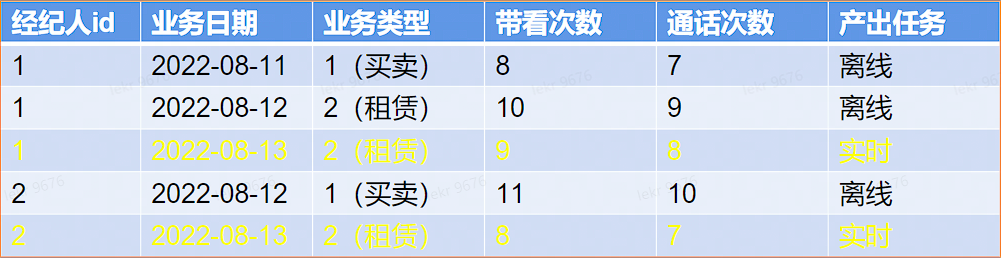
# 计算分析 - Lambda 架构 - 问题
# 计算分析 - 计算架构 - 全量计算
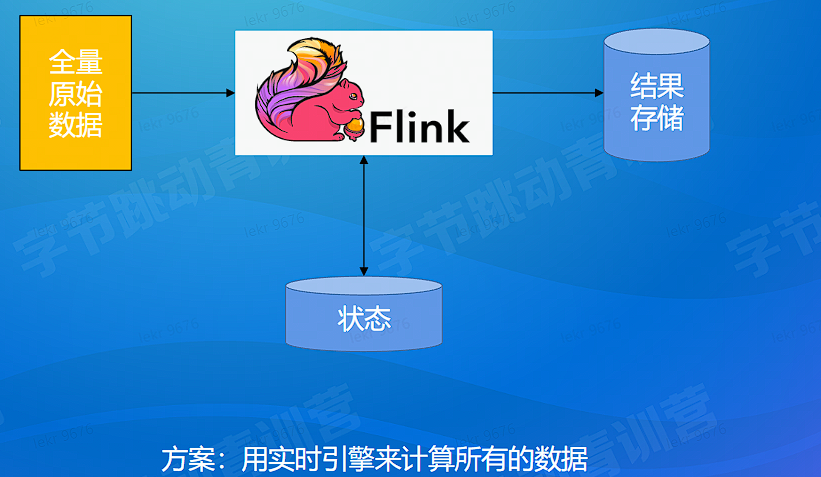
# 计算分析 - 全量计算架构 - 问题解决
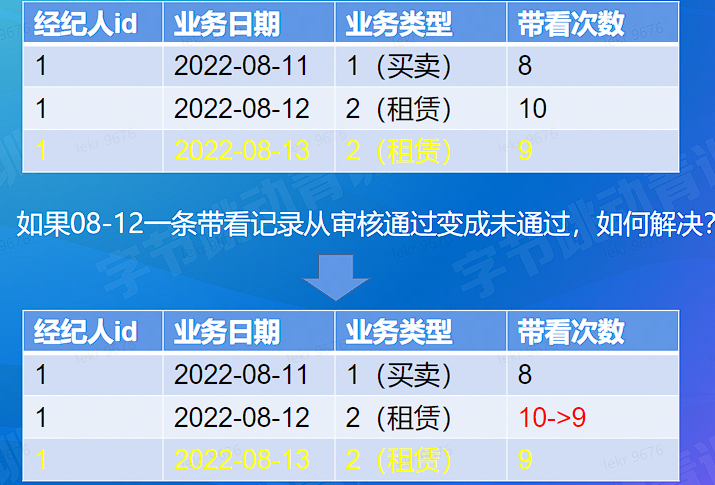
还是原来的问题

# 计算分析 - 计算架构 - 全量计算问题分析
问题:
- 如何获取全量的原始数据?
- 数据湖,实时性相对差
- CDC: log 等数据?
- 其他?
# 计算分析 - 计算架构 - 架构选择
| 目标 | Lambda 架构 | 全量计算架构 |
|---|---|---|
| 开发运维效率 | 效率低:存在实时离线开发任务和 merge 逻辑, | 效率高:只存在一套实时任务 |
| 资源效率 | 计算资源占用高:离线全量 (例行任务)+ 实时增量 | 状态存储成本相对高:全量 (首次冷启动)+ 增量 |
| 数据质量实时、准确 | 符合要求 | 符合要求 |
全量计算框架有一定的优势
# 计算难点
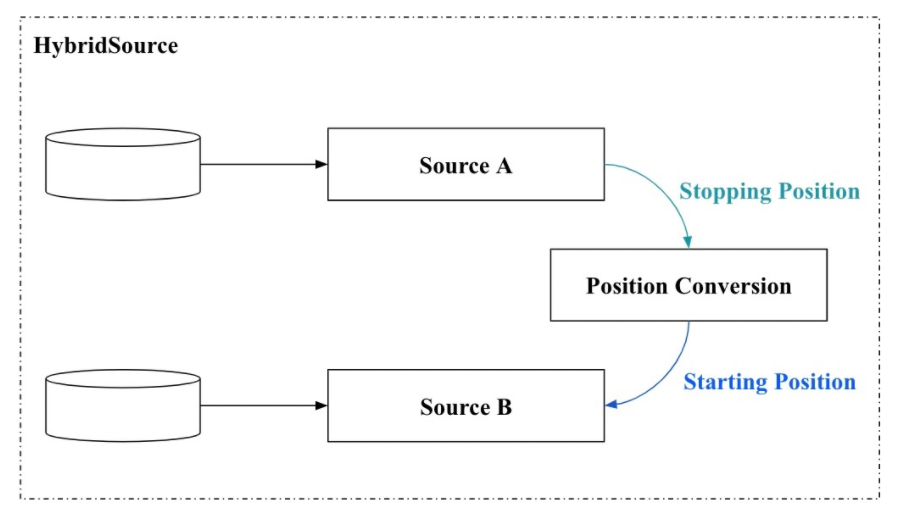
# 计算难点 - 全量数据获取 - Hybrid Source
方案: Hybrid base (Hive) + Delta (Kafka)
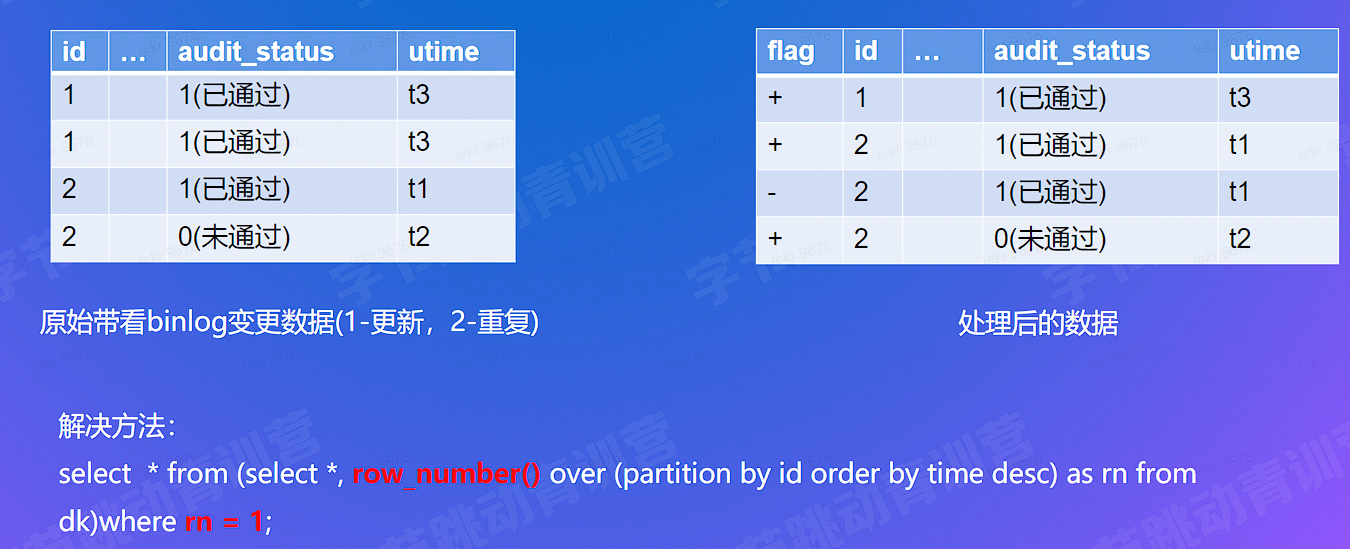
# 计算难点 - 准确 - 处理去重 & 更新 (Retract)
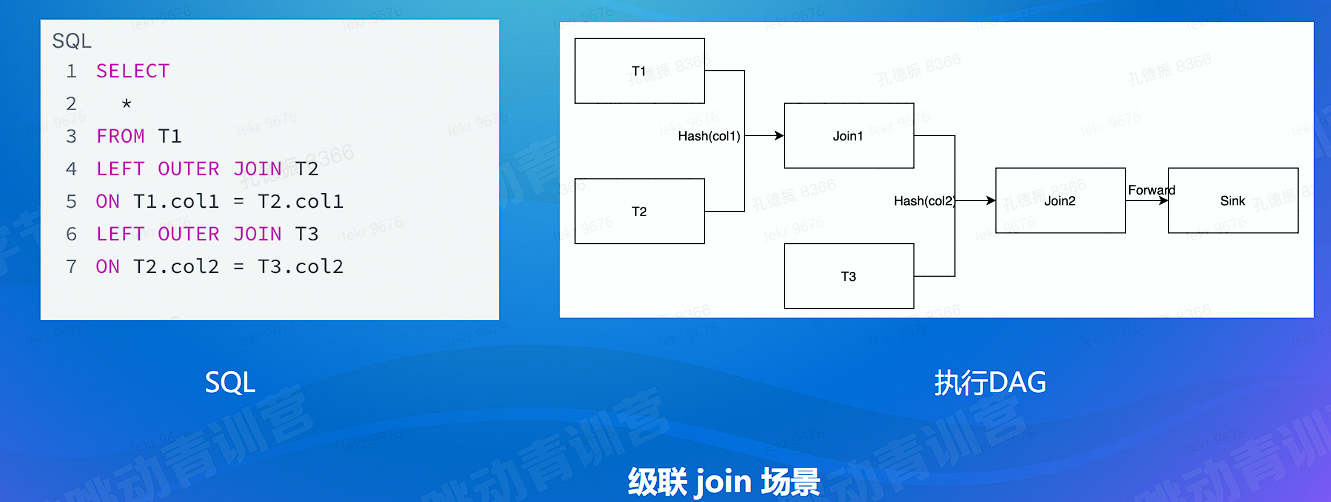
# 计算难点 - 准确 - join 乱序问题场景
为什么会产生乱序问题
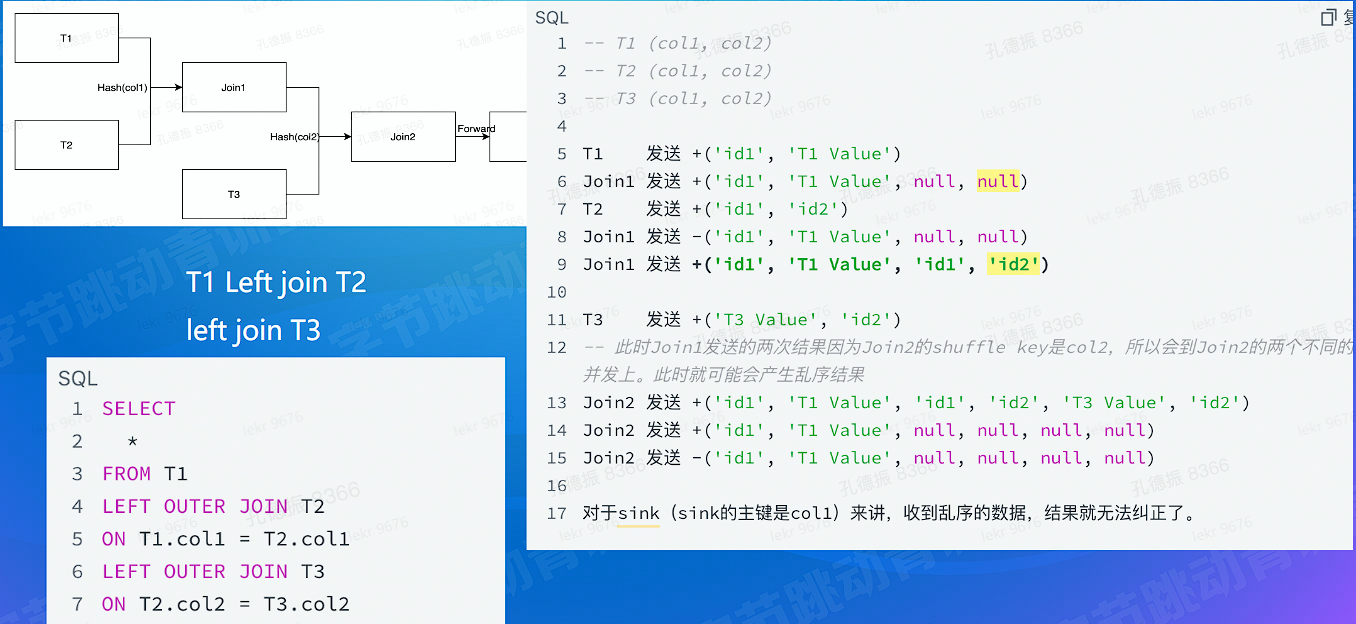
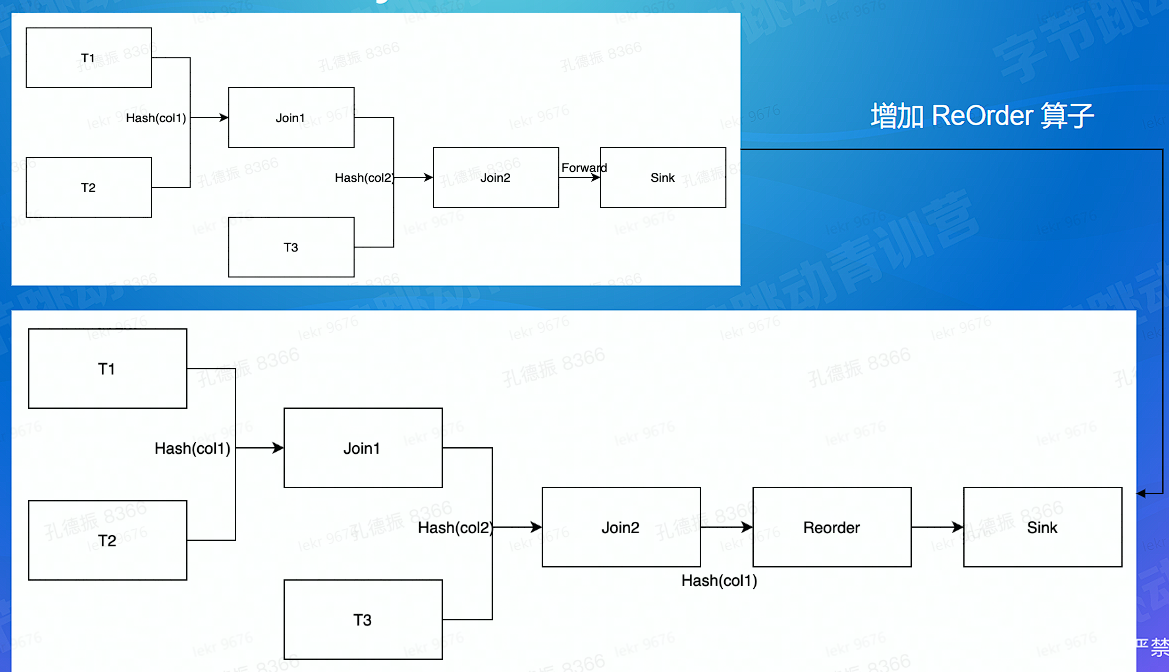
# 计算难点 - 准确 - join 乱序问题解决

# 计算难点 - 计算效率 - 聚合
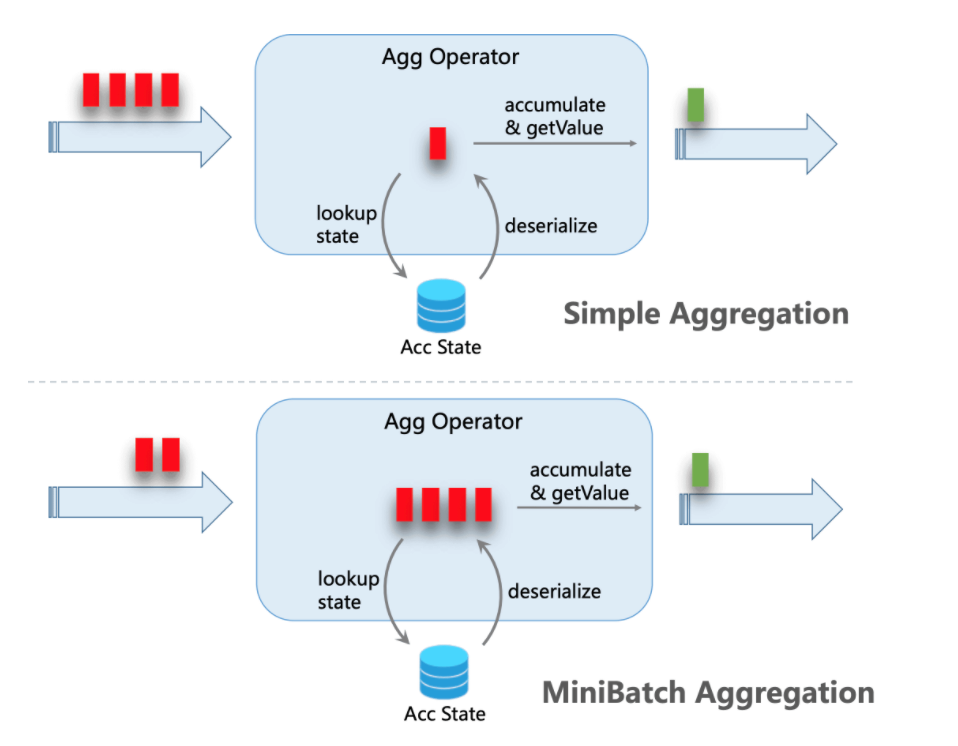
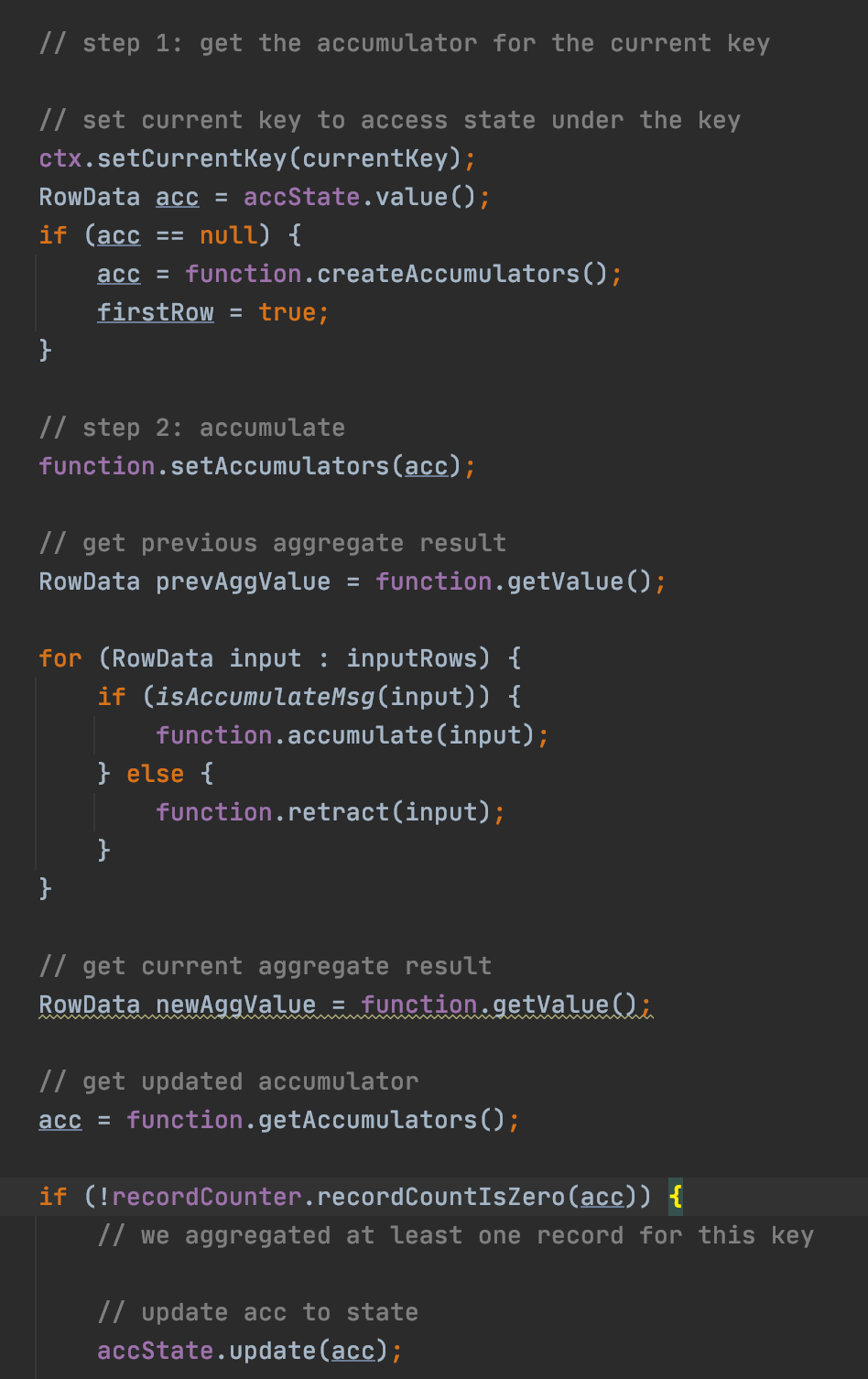
聚合函数批式处理,本质是延迟换吞吐
# 计算难点 - 效率 - Join
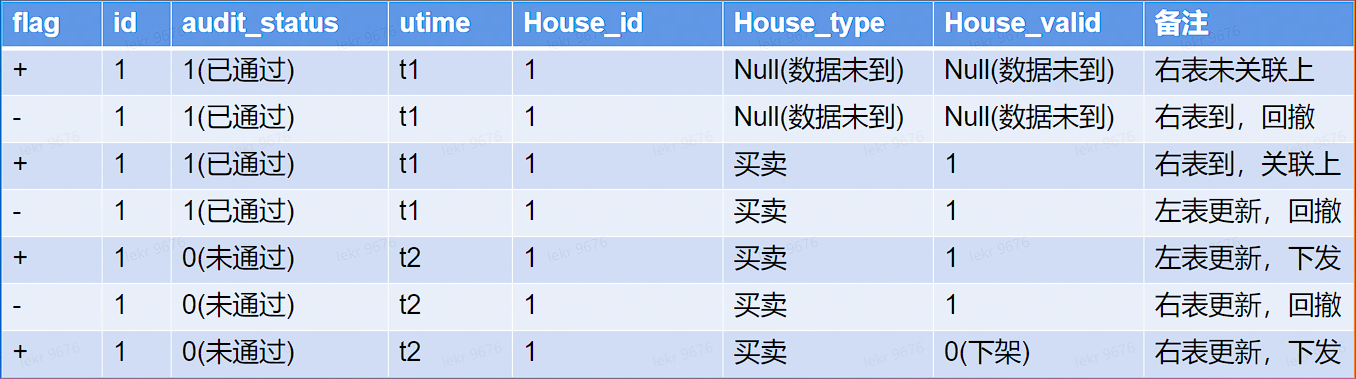
# 计算难点 - 效率 - Join 算子逻辑
关联触发:左右流互相关联触发
回撤来源 (left join 举例):
- 右表晚到
- 左右表本身的回撤
# 计算难点 - 效率 - Minibatch Join
中间数据可抵消,MInibatch 方案,抵消批次内的变更导致的中问数据
# 数据质量
# 任务稳定性
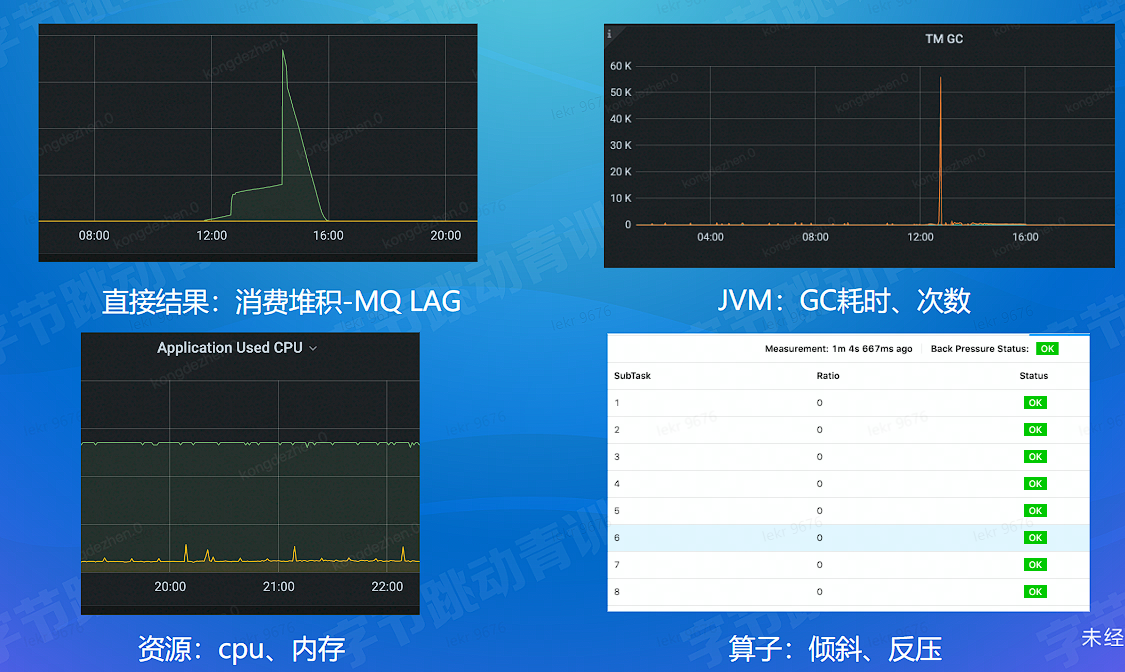
# 数据质量 - 数据持续正确性 - 监控比对
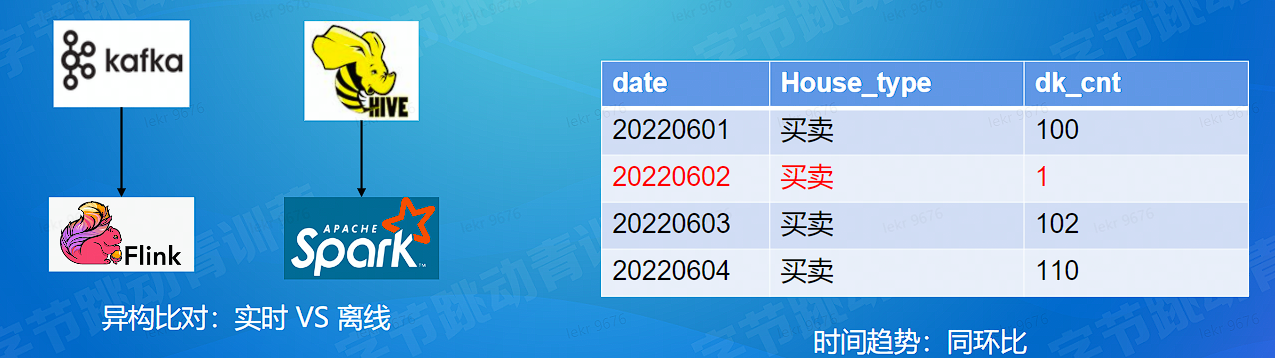

# 计算总结
计算架构:开发效率
- Lambda 架构 -> 全量计算:一套开发任务
数据源获取:全量能力
- Hybrid Source (逻辑全量表,hive+kafka,成熟存储方案)
计算:正确、效率,核心是算子选择 + 优化
- 正确
- 处理更新 / 重复:rownumber+retract 机制
- 乱序: join reorder
- 效率
- 时效性换效率:Minibatch (聚合、join)
- 质量:稳定性监控、数据监控
# 数仓建设
.png)
数仓建设:数据复用,减少重复开发
# 数仓 - 数据组织方案

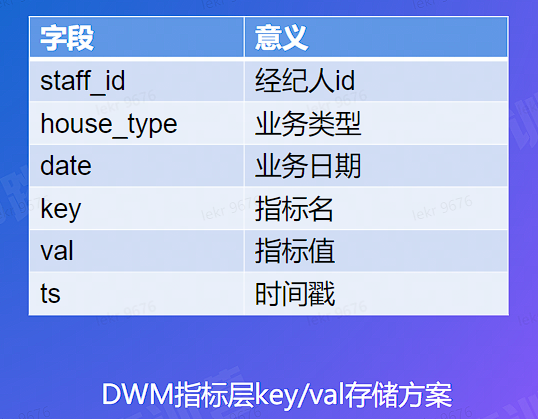
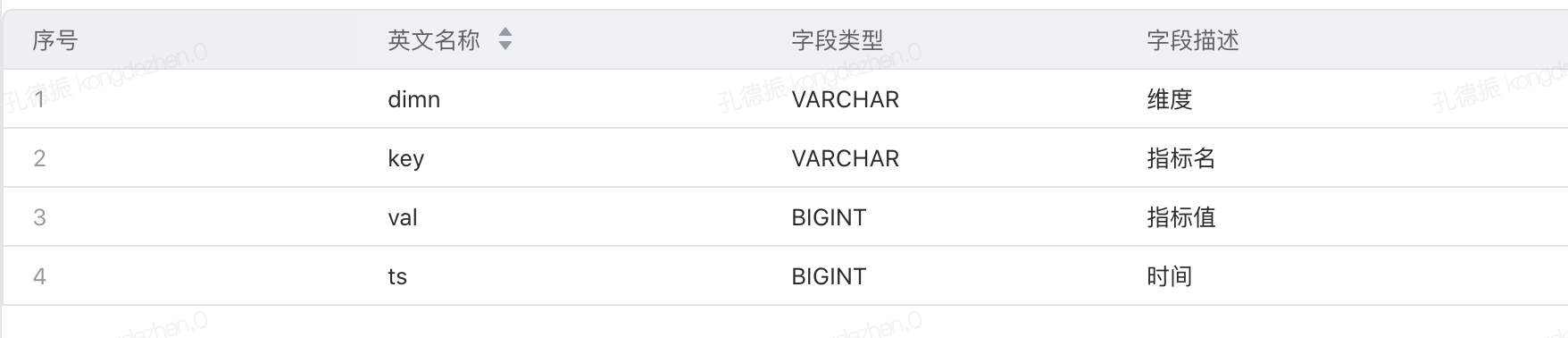
# 元数据管理

# 数据服务
整体架构:查询引擎、查询优化和执行、稳定性、元数据
案例查询方案分析
- 如何更快的查询
- 原始信息筛选和关联效率
- 计算处理效率
- 只关注目标所需数据
- 如何更快的查询
关注目标信息
- 列存
原始信息筛选效率
- OLAP 引擎索引方案
原始信息关联
- join 方案及优化
计算效率
- 向量化
执行计划优化:RBO、CBO
应用层优化
- 宽表构建
- 提升信息密度:bit 化、bitmap
查询稳定性
- 熔断、限流、降级
元数据管理:指标口径管理、查询生成
# 数据服务架构
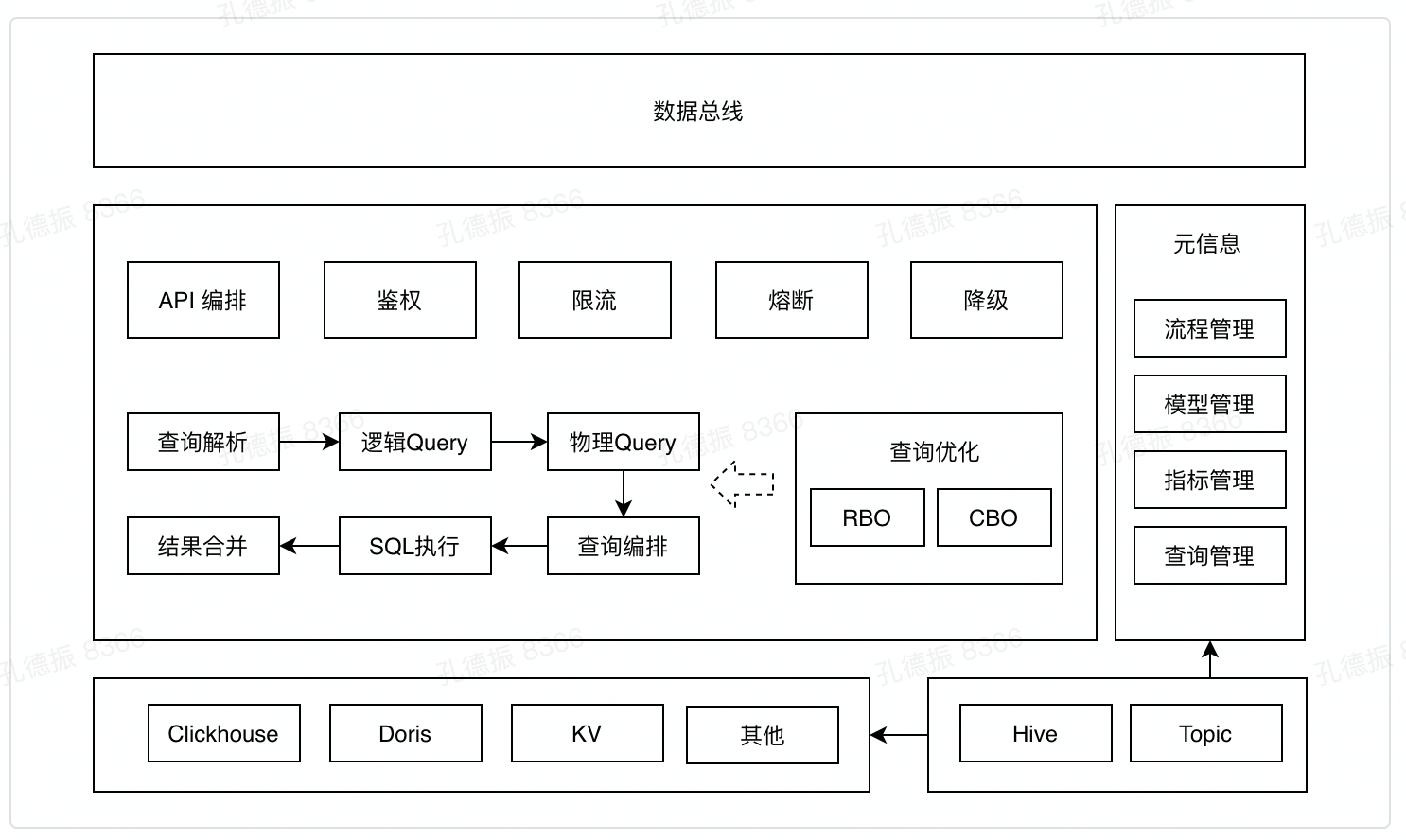
# 查询快 - 引擎选择
- 指定 key 查询 value, 类似 Hash Map
- Redis 等 kv 数据库
- 分析: join、agg
- ClickHouse、Doris 等 OLAP 分析
# 查询快 - 怎么做?

查询优化分析:
- 关注目标:不需要的信息不关注,比如只查询带看量
- 计算处理:能不能足够快,比如 count/sum/avg 等聚合函数
- 原始信息:单表筛选够不够快、信息关联够不够快
# 查询快 - 关注目标信息
clickhouse
select 带看量,通话量 from table (100 + 列)
- 行存:大量 io,每行查找需要的列
- 列存:直接取出对应的列文件
# 查询快 - 筛选 - 分区
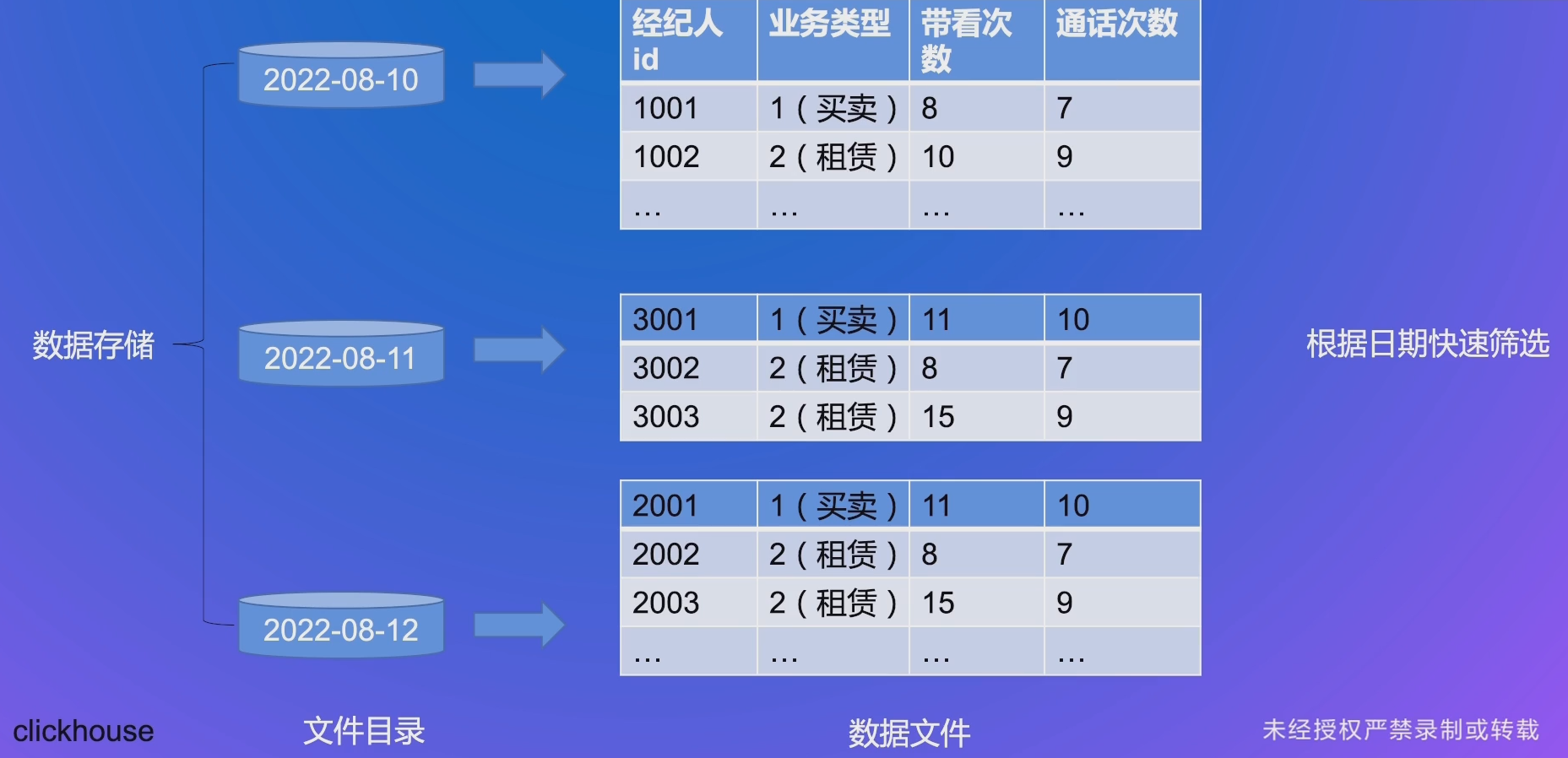
# 查询快 - 筛选 - primary key 构建
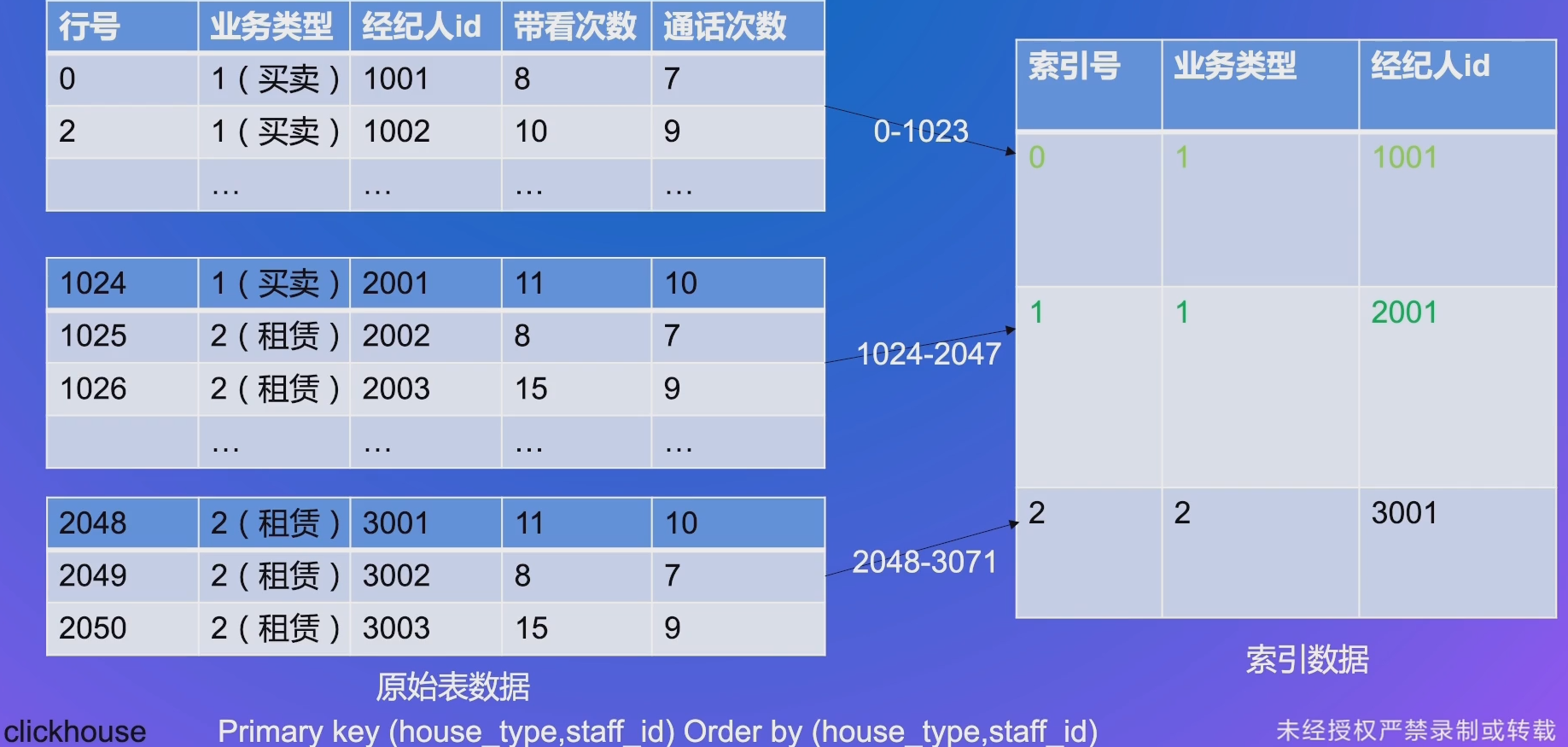
# 查询快 - 筛选 - primary key 查找
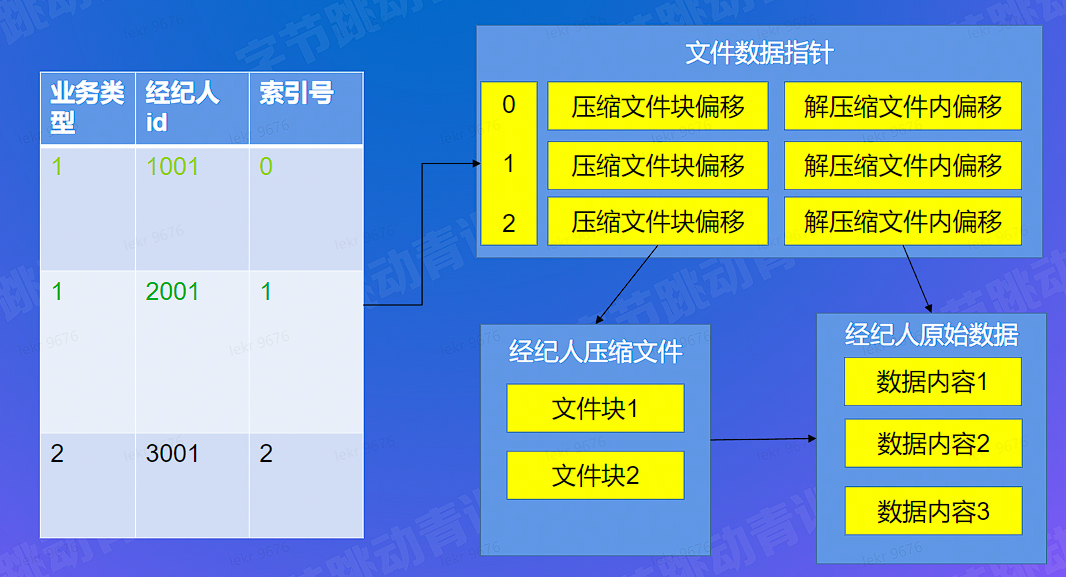
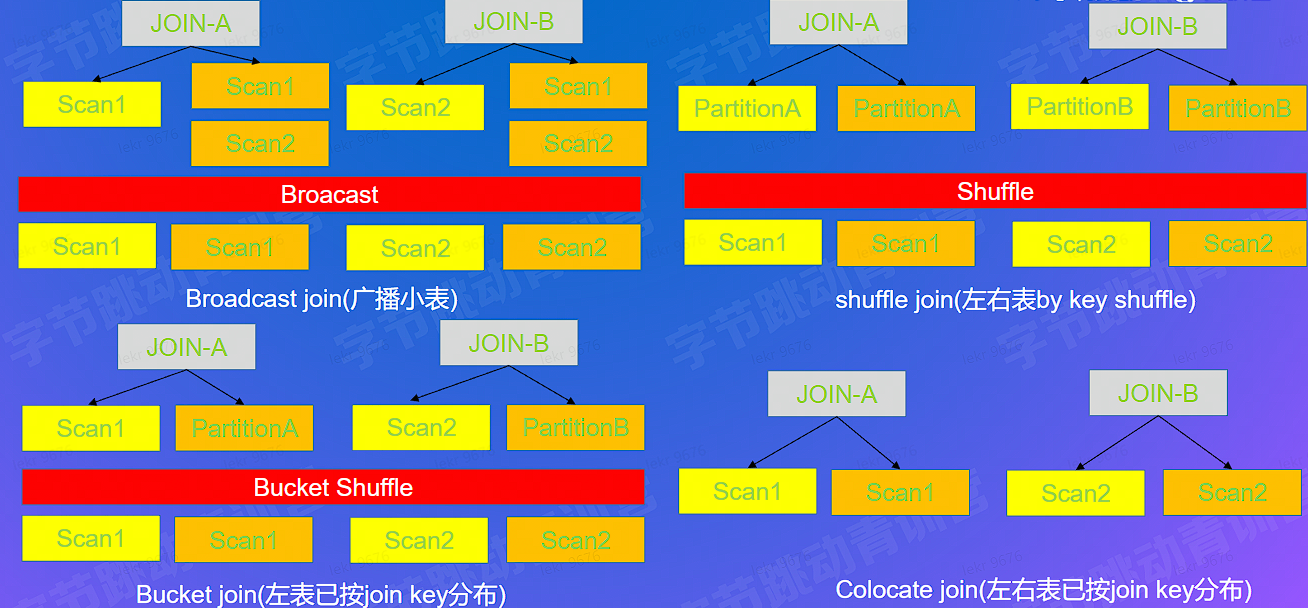
# 查询快 - 原始信息关联 - IO 优化
doris
# 更快的查询 - 计算向量化
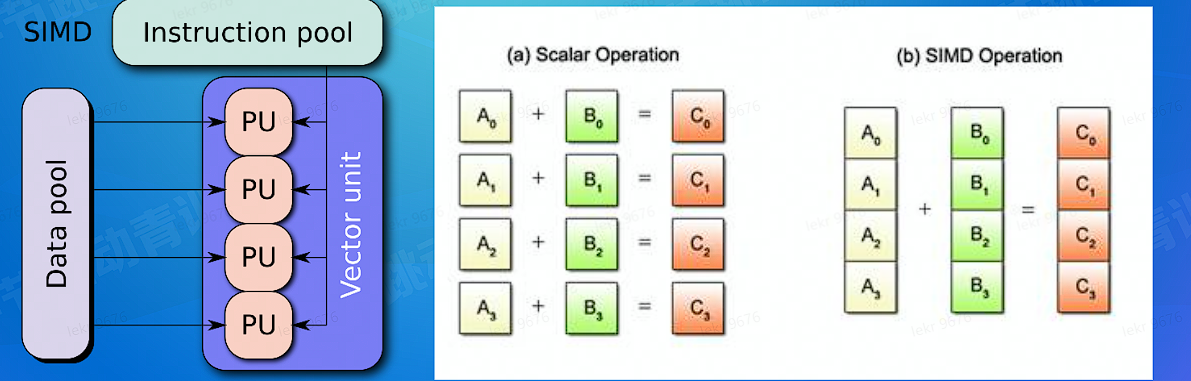
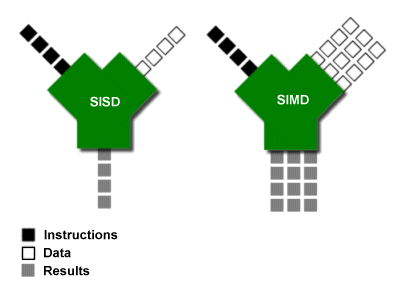
CPU 支持向量化指令,单指令多数据处理
# 查询快 - 执行计划
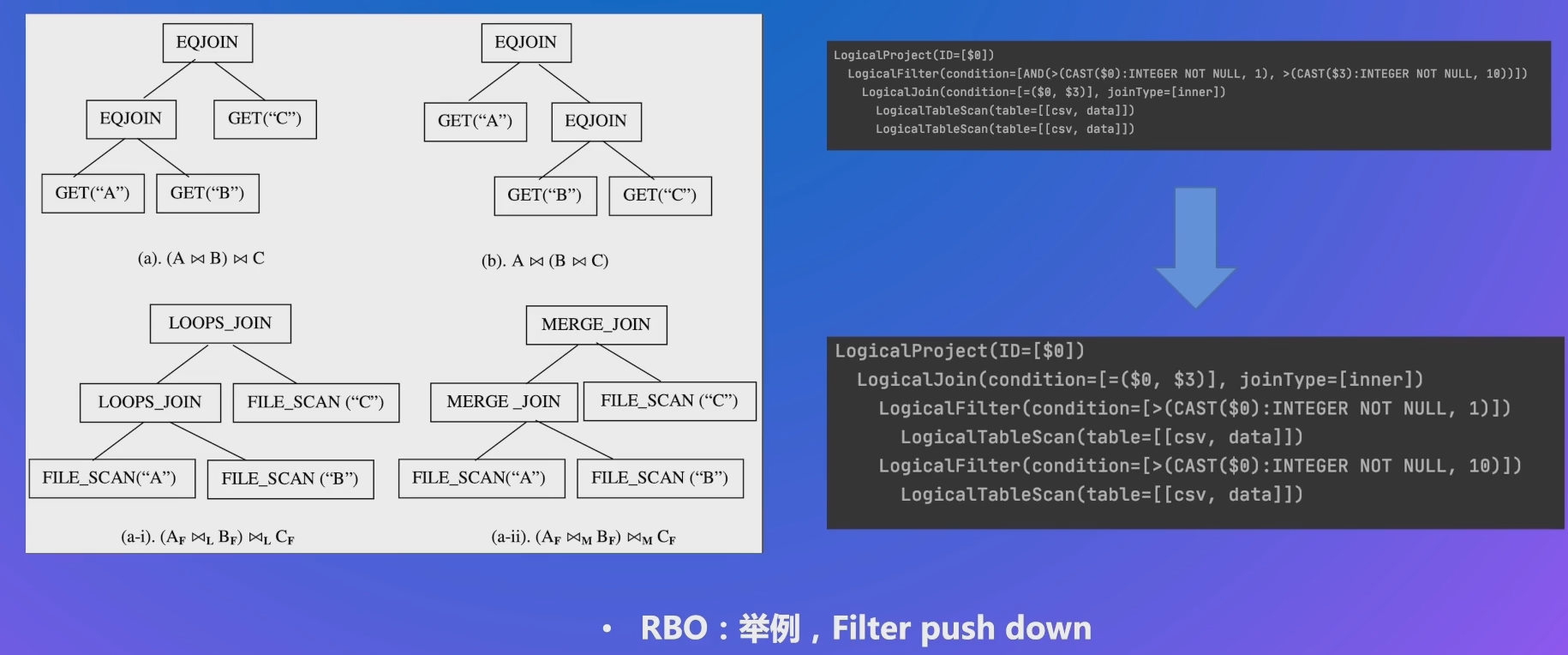
# 查询快 - 应用优化
- 原始信息关联
- Local Join: 如计算带看量,带看数据和房信息按照 house_id 分布,无 shuffle io 开销
- 预关联:直接生产 “大宽表”
- 计算复杂度
- 预计算:提前聚合到特定粒度,如带看量聚合到经纪人 + 天 + 业务类型
- 提升信息密度: bit 化,
# 查询快 - 应用 - 宽表构建
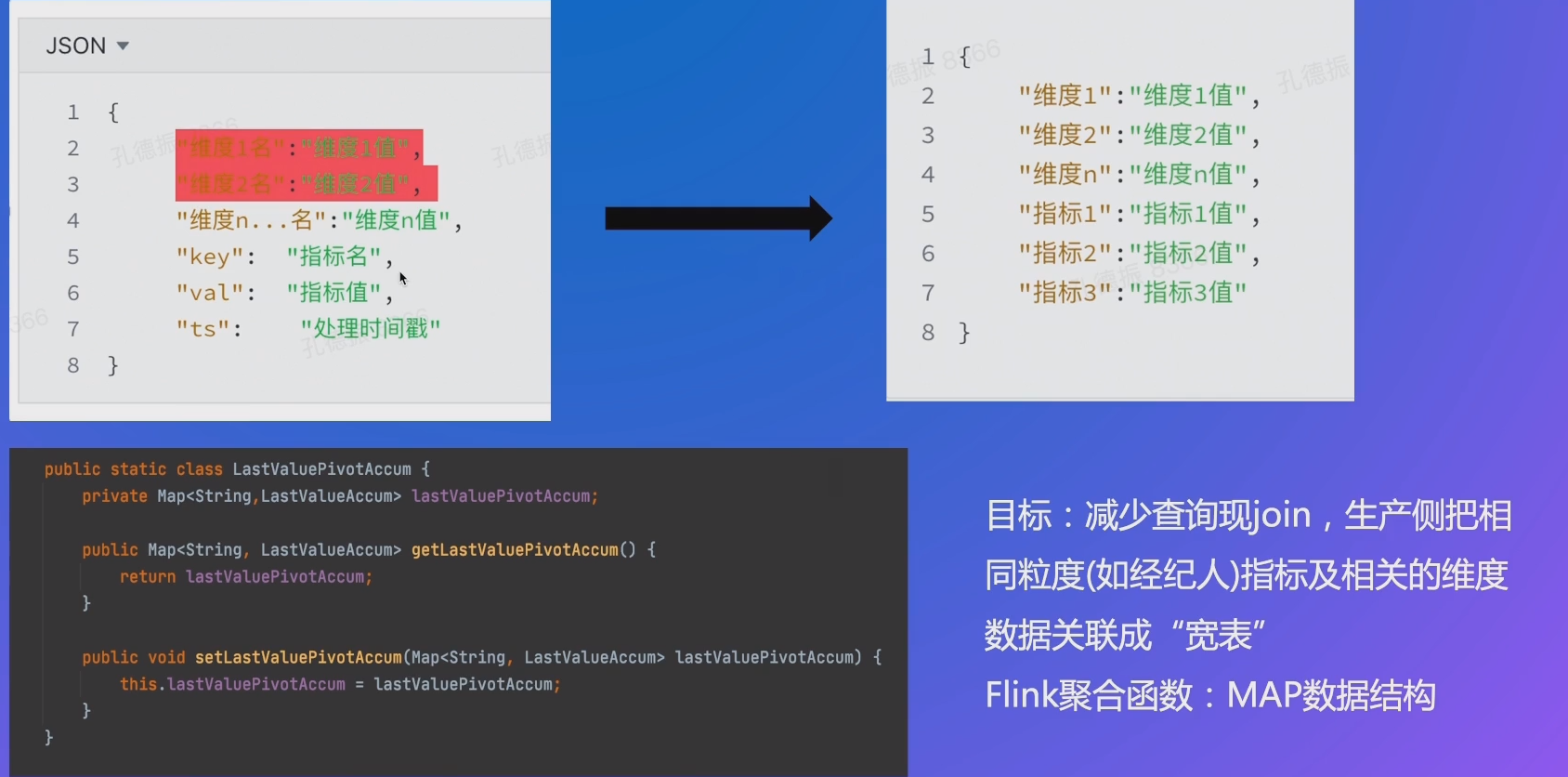
# 查询快 - 提升信息密度 - bit 化
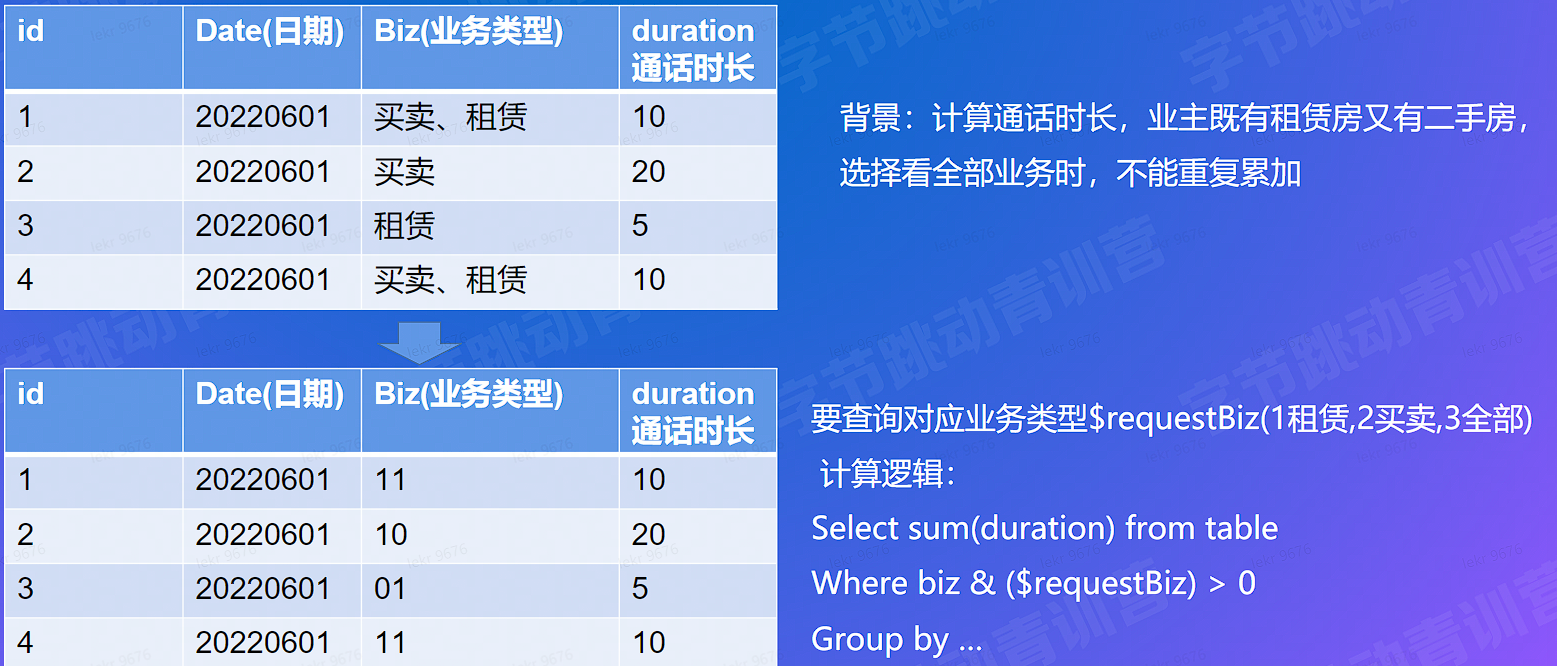
Biz (业务类型):第 1 位代表是否有租赁 (1/0),第二位代表是否有买卖 (1/0)
# 查询快 - 提升信息密度 - bitmap

# 稳定 - 解决的问题
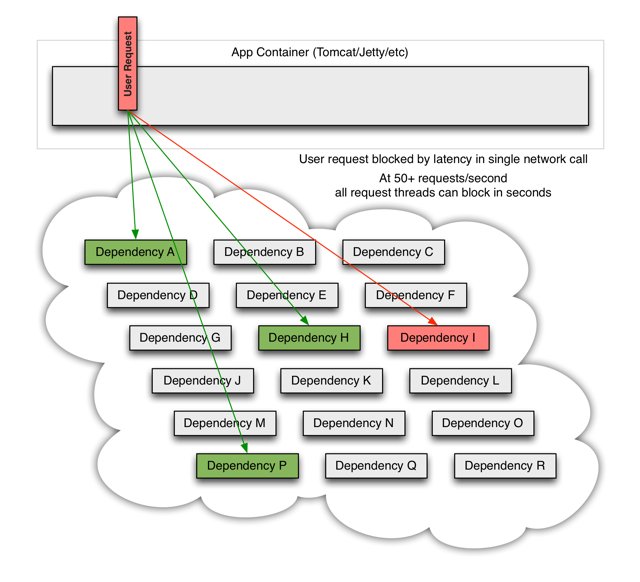
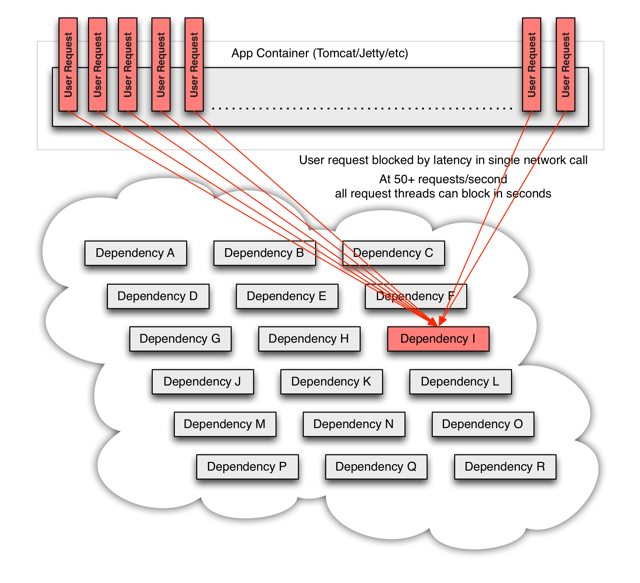
异常节点导致服务雪崩
# 稳定 - 如何解决
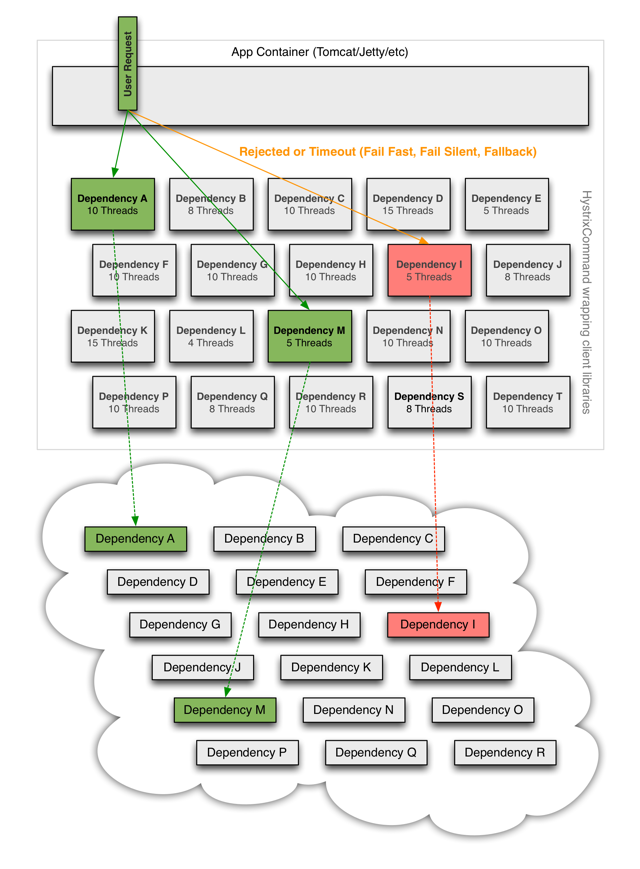
熔断触发策略:
- 比如错误率每秒超过 10%
- 响应时间 > 5s
动作:
- 直接返回失败
Source Hystrix
限流、降级
- 限流:根据查询客户端、接口等配置查询限额
- 降级:主备存储 / 服务集群,降级预案
# 查询 - 数据管理