 数据类型、运算符与表达式
数据类型、运算符与表达式
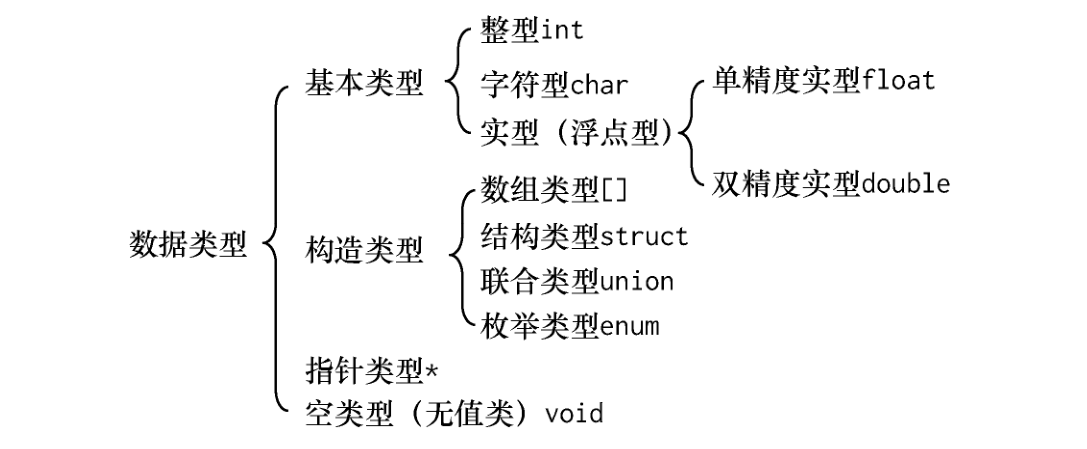
# 数据类型、运算符与表达式
# 常量
常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。
在 C 中,有两种简单的定义常量的方式:
- 使用 #define 预处理器。
- 使用 const 关键字。
#define num 7 //define关键字定义常量
#define num2 4+3 //支持运算符
int main(){
printf("%d\n",num);
printf("%d\n",num+1); // 因为num定义为常量 编译器在预处理时会把代码中所有常量num替换成7 将7+1
const int num3 = 9; // 使用const关键字定义常量
printf("%d\n",num3);
}
2
3
4
5
6
7
8
常量又可分为整型、实型(也称浮点型)、字符型和字符串型

# 变量
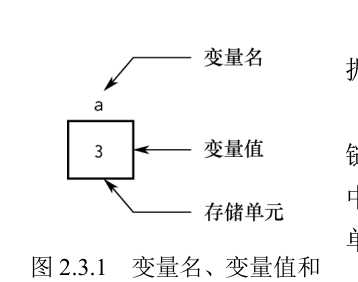
变量代表内存中具有特定属性的一个存储单元,它用来存放数据,即变量的值。这些值在程序的执行过程中是可以改变的。
//形如 type variable_list;
//type 必须是一个有效的 C 数据类型,可以是 char、w_char、int、float、double 或任何用户自定义的对象
//variable_list 可以由一个或多个标识符名称组成,多个标识符之间用逗号分隔
int i, j, k;
char c, ch;
float f, salary;
double d;
2
3
4
5
6
7
上面的几个案例只是变量的声明, C 语言要求对所有用到的变量做强制定义,即 “先定义,后使用”。
extern int d = 3, f = 5; // d 和 f 的声明与初始化
int d = 3, f = 5; // 定义并初始化 d 和 f
byte z = 22; // 定义并初始化 z
char x = 'x'; // 变量 x 的值为 'x'
2
3
4
不带初始化的定义:带有静态存储持续时间的变量会被隐式初始化为 NULL(所有字节的值都是 0),其他所有变量的初始值是未定义的。
# 整型数据
| 类型 | 存储大小 | 值范围 |
|---|---|---|
| int | 4 字节(16 位为 2 字节) | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| short | 2 字节 | -32,768 到 32,767 |
| long | 4 字节(64 位为 8 字节) | -2,147,483,648 到 2,147,483,647 或 |
| char | 1 字节 | -128 到 127 |
| unsigned int | 4 字节(16 位为 2 字节) | 0 到 65,535 或 0 到 4,294,967,295 |
| unsigned short | 2 字节 | 0 到 65,535 |
| unsigned long | 4 字节(64 位为 8 字节) | 0 到 4,294,967,295 或 0~ |
| unsigned char | 1 字节 | 0 到 256 |
# 整型常量
整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。
整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。后缀可以是大写,也可以是小写,U 和 L 的顺序任意。
85 /* 十进制 */
0213 /* 八进制 */
0x4b /* 十六进制 */
30 /* 整数 */
30u /* 无符号整数 */
30l /* 长整数 */
30ul /* 无符号长整数 */
2
3
4
5
6
7
# 浮点型数据
系统把一个浮点型数据分成小数部分(用 M 表示)和指数部分(用 E 表示)并分别存放。指数部分采用规范化的指数形式,指数也分正、负(符号位,用 S 表示)
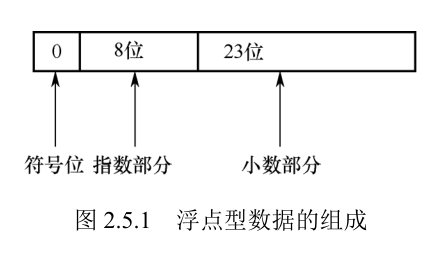
数符占 1 位,是 0 时代表正数,是 1 时代表负数。下面的表格是 IEEE-754 浮点型变量存储标准。
| 格式 | SEEEEEEE | EMMMMMMM | MMMMMMMM | MMMMMMMM |
|---|---|---|---|---|
| 二进制数 | 01000000 | 10010000 | 00000000 | 00000000 |
| 十六进制数 | 40 | 90 | 00 | 00 |
- S:S 是符号位,用来表示正、负,是 1 时代表负数,是 0 时代表正数。
- E:E 代表指数部分,指数部分运算前都要减去 127(这是 IEEE-754 的规定),因为还要表示负指数。这里的 10000001 转换为十进制数为 129,129 − 127 = 2,即实际指数部分为 2。
- M:M 代表小数部分,这里为 0010 0000 0000 0000 0000 000。底数左边省略存储了一个 1,使用的实际底数表示为 1.00100000000000000000000。
下面以浮点数 4.5(十进制数)为例具体介绍。
计算机并不能计算 10 的幂次,指数值为 2,代表 2 的 2 次幂,因此将 1.001 向左移动 2 位即可,也就是 100.1;然后转换为十进制数,整数部分是 4,小数部分是 2 −1 ,刚好等于 0.5,因此十进制数为 4.5。浮点数的小数部分是通过
| 类型 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|
| float | 4 byte | 1.2E-38 到 3.4E+38 | 6~7 位小数 |
| double | 8 byte | 2.3E-308 到 1.7E+308 | 15~16 位小数 |
| long double | 10 byte | 3.4E-4932 到 1.1E+4932 | 18~19 位小数 |
int main(){
float f = 1e3; //1000.000000
float f2 = 1e-3; //0.001000
double f3 = 3.14;
printf("%f\n%f\n%0.2f\n",f,f2,f3);
}
2
3
4
5
6
# 字符型数据
# 字符常量
字符常量是括在单引号中,例如,'x' 可以存储在 char 类型的简单变量中。
| 转义序列 | 含义 |
|---|---|
| \\ | \ 字符 |
| ' | ' 字符 |
| " | " 字符 |
| ? | ? 字符 |
| \a | 警报铃声 |
| \b | 退格键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车,将当前位置移到本行开头如果接着输出的话,本行之前的内容会被逐一覆盖 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ooo | 一到三位的八进制数 |
| \0 | 空字符,用于标示字符串的结尾,它不是空格,无法打印 |
| \xhh | 一个或多个数字的十六进制数 |
| \ddd | ddd 表示 1~3 位八进制数,用处不大 |
# 字符数据在内存中的存储形式及其使用方法
一个字符常量存放到一个字符型变量中时,实际上并不是把该字符的字型放到内存中,而是把该字符的 ASCII 码值放到存储单元中。
打印字符型变量时,如果以字符形式打印,那么计算机会到 ASCII 码表中查找字符型变量的 ASCII 码值,查到对应的字符后会显示对应的字符,如下图。
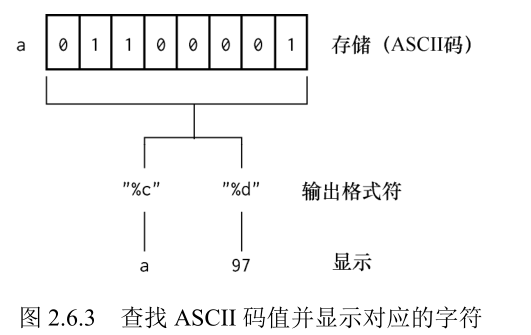
这样,字符型数据和整型数据之间就可以通用。字符型数据既可以以字符形式输出,又可以以整数形式输出,还可以通过运算获取想要的各种字符。
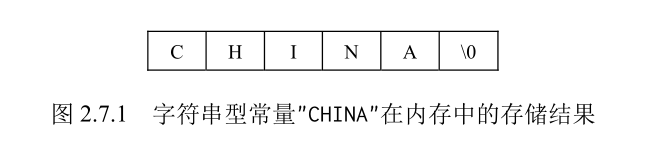
# 字符串型常量
字符串型常量是由一对双引号括起来的字符序列。例如,"How do you do."、"CHINA"、"a" 和 "$123.45" 是合法的字符串型常量,我们可用语句 printf ("How do you do.") 输出一个字符串。但要注意的是,'a' 是字符型常量,而 "a" 是字符串型常量,二者是不同的。
如果先用语句 char c 定义字符型变量 c,后令 c="a" 或 c="CHINA",那么这样的赋值都是非法的,原因是不可以将字符串型常量赋值给字符型变量。
C 语言规定,在每个字符串型常量的结尾加一个字符串结束标志,以便系统据此判断字符串是否结束。C 语言规定以字符 '\0' 作为字符串结束标志。
例如,字符串型常量 "CHINA" 在内存中的存储结果如图 2.7.1 所示,它占用的内存单元不是 5 个字符,而是 6 个字符,即大小为 6 字节,最后一个字符为 '\0'。然而,在输出时不输出 '\0',因为 '\0' 无法显示。
# 混合运算
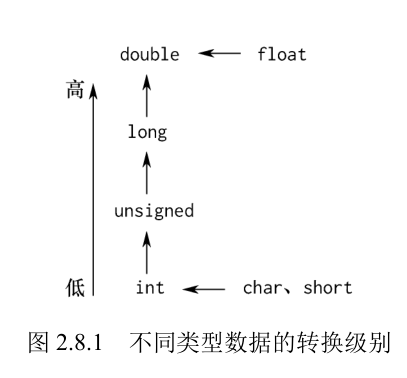
字符型(char)、整型(包括 int、short、long)、浮点型(包括 float、double)数据可以混合运算。运算时,不同类型的数据首先要转换为同一类型,然后进行运算。
不同类型数据的转换级别如下图所示,从短字节到长字节的类型转换是由系统自动进行的,编译时不会给出警告;若反向进行,则编译时编译器会给出警告。
# 数值按 int 型运算
C 语言中的整型数算术运算总是以默认整型类型的精度进行的。为了获得这个精度,表达式中的字符型和短整型操作数在使用之前会被转换为基本整型(int 型)操作数,这种转换被称为整型提升(Integral Promotion)。例如
char a,b,c;
a = b + c; // 自动提升为int作加法运算 运算后赋值到char a中 此时 b+c为int 赋值到a中被截短
2
其中,b 和 c 的值首先被提升为基本整型数,然后执行加法运算。加法运算的结果将被截短,然后存放到 a 中。
但在下面的例中,结果不再相同。
#include <stdio.h>
#include <stdlib.h>
int main()
{
char b = 0x93<<1>>1;
printf("%x\n",b); //ffffff93
b = 0x93<<1; //0x26
b = b>>1; //0x13
printf("%x\n",b); //13
}
2
3
4
5
6
7
8
9
10
为什么采用十六进制数打印呢?这是因为输出时 % x 是取 4 字节进行输出的;b 中存储的只有 93,为什么前面却打印出了 3 字节的 ff 也就是 6 个 ff 呢?如果用 % d 输出,那么可以得到一个负值,当我们用 % x 输出一个少于 4 字节的数时,前面补的字节是按照对应数据的最高位来看的, 因为字符 b 为char类型存储大小为1 字节,即8位 而b的十六进制为0x93,二进制为1001 0011 最高位为 1,所以其他 3 字节补的都是 1, 补全4字节后就变成ffffff93的形式 。
为什么把操作分成两步后,b 的值就为 13 呢?因为 0x93 左移一位时后面补 0 从 1001 0011 变成 0010 0110,虽然按 4 字节进行,但是最低一字节的值为 0x26,赋值给 b 后,b 内存储的就是 0x26,这时再对 b 进行右移时,单字节拿到寄存器中是按 4 字节运算的,但是因为右移后此时 b 的最高位为零,因此拿到寄存器中按 4 字节运算,前面补的都是零,再右移一位表示除以 2,因此得到的值是 13。
总结:数值按 4 个字节进行运算,即在 C 中会自动提升为 int 类型进行运算
# 两个较大常量相乘溢出
另外一种场景是我们对两个整型常量做乘法,并赋值给一个长整型变量,对编译器来讲这是按照 int 型进行的。
#include <stdio.h>
#include <stdlib.h>
int main()
{
long l;
l = 131072*131072;
printf("%ld\n",l); // 0
}
2
3
4
5
6
7
8
9
我们可以在做乘法前,将整型数强制转换为 long 型,在 32 位操作系统下,long long 型只占 8 字节而 long 型占 4 字节。如果是 64 位程序,那么转化为 long 型即可。
#include <stdio.h>
#include <stdlib.h>
int main()
{
// 32位操作系统下
long long l;
l = (long long)131072*131072;
printf("%lld\n",l); //17179869184
// 64位操作系统下
long l2;
l2 = (long)131072*131072;
printf("%ld\n",l2); //17179869184
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 浮点型常量默认按 double 型运算
#include <stdio.h>
#include <stdlib.h>
//浮点型常量默认按 8 字节运算
int main()
{
float f = 12345678900.0+1;
printf("%f\n",f); // 12345678848.000000 float精度丢失
printf("%f\n",12345678900.0+1); // 12345678901.000000 浮点数默认为double
return 0;
}
2
3
4
5
6
7
8
9
10
第一个打印的值只有 7 位精度,原因是单精度浮点数 f 只有 4 字节的存储空间,能够表示的精度是 6~7 位,所以只保证 1~7 位是正确的,后面的都是近似值。第二个打印的值是正确的浮点型常量,它是按 8 字节即 double 型进行运算的,同时 % f 会访问寄存器 8 字节的空间进行浮点运算,因此可以正常输出。
# 类型强制转换场景
整型数进行除法运算时,如果运算结果为小数,那么存储浮点数时一定要进行强制类型转换
#include <stdio.h>
#include <stdlib.h>
// 混合运算, 从长字节到短字节数据需要强制类型转换
int main()
{
int i = 5;
float f,g;
short m ;
long l =5;
f = i/2; //结果为2.000000 因为没有强制类型转换 i/2 为整型运算
g=(float)i/2; //2.500000
m=(short)l+2; //结果为7 不加short强转编译可能会警告
printf("i=%d,f=%f,g=%f,m=%d\n",i,f,g,m);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 常用的数据输入 / 输出函数
C 语言通过函数库读取标准输入,然后通过对应函数处理将结果打印到屏幕上。下面介绍标准输入函数 scanf、getchar,以及打印到屏幕上的标准输出函数 pintf、putchar。
# scanf 函数的原理
C 语言未提供输入 / 输出关键字,其输入和输出是通过标准函数库来实现的。C 语言通过 scanf 函数读取键盘输入,键盘输入又被称为标准输入。当 scanf 函数读取标准输入时,如果还没有输入任何内容,那么 scanf 函数会被卡住(专业用语为阻塞)。
// 缓存区里所有数据都是字符,scanf根据你的要求进行匹配
int main()
{
int i;
char c;
scanf("%d",&i);//阻塞函数
printf("i=%d\n",i);
scanf("%c",&c);//这里不会阻塞了 读到是\n
printf("c=%c\n",c);//好像没打印出来的样子
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12

执行时输入 20,然后回车。为什么第二个 scanf 函数不会被阻塞呢?其实是因为第二个 scanf 函数读取了缓冲区中的 '\n', 即 scanf("%c",&c)实现了读取\n,打印其实输出了换行,所以不会阻塞 。
缓冲区其实就是一段内存空间,分为读缓冲、写缓冲。C 语言缓冲的三种特性如下。
- 全缓冲:在这种情况下,当填满标准 I/O 缓存后才进行实际 I/O 操作。全缓冲的典型代表是对磁盘文件的读写操作。
- 行缓冲:在这种情况下,当在输入和输出中遇到换行符时,将执行真正的 I/O 操作。这时,我们输入的字符先存放到缓冲区中,等按下回车键换行时才进行实际的 I/O 操作。典型代表是标准输入缓冲区(stdin)和标准输出缓冲区(stdout)。
- 不带缓冲:也就是不进行缓冲,标准出错情况(stderr)是典型代表,这使得出错信息可以直接尽快地显示出来。
ANSI C(C89)要求缓存具有下列特征。 (1)当且仅当标准输入和标准输出不涉及交互设备时,它们才是全缓存的。
(2)标准出错绝不会是全缓存的。
我们向标准输入缓冲区中放入的字符为 '20\n',输入 '\n'(回车)后,scanf 函数才开始匹配,scanf 函数中的 % d 匹配整型数 20,然后放入变量 i 中,接着进行打印 输出,这时 '\n' 仍然在标准输入缓冲区(stdin)内,如果第二个 scanf 函数为 scanf("%d",&i)或scanf("%f",&i) , 那么依然会发生阻塞,因为 scanf 函数在读取整型数、浮点数、字符串时,会忽略 '\n'(回车符)、空格符等字符(忽略是指 scanf 函数执行时会首先删除这些字符, 然后再阻塞)。scanf 函数匹配一个字符时,会在缓冲区删除对应的字符。因为在执行 scanf ("% c",&c) 语句时,不会忽略任何字符,所以 scanf ("% c",&c) 读取了还在缓冲区中残留的 '\n'。
// 缓存区里所有数据都是字符,scanf根据你的要求进行匹配
int main()
{
int i;
char c;
scanf("%d",&i);//第一次输入
printf("i=%d\n",i);
//scanf("%f",&i);
scanf("%d",&i);//这里阻塞了 因为 %d 和 %f 不读取\n
printf("i2=%c\n",i);//打印第二次输入的
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
# scanf 函数的循环读取
如果想输入多个整数(每次输入都回车),让 scanf 函数读取并打印输出,那么我们需要一个 while 循环
int main(){
int i,ret;
while (ret = scanf("%d",&i) != EOF)
{
printf("i=%d\n",i);
}
}
2
3
4
5
6
7
上述代码有设计缺陷,如果我们输错了,输入的为字符型数据,那么 scanf 函数就无法匹配成功,scanf 函 数未匹配成功时其返回值为 0,即 ret 的值为 0,但这并不等于 EOF,因为 EOF 的返回值为 - 1。 当 scanf 函数无法匹配成功时,程序仍然会进入循环,这时会导致不断地重复打印,如下图所示。

那么我们如何解决这个问题呢,需要使用 fflush 函数把标准输入里面的 a 清空掉,因为 fflush 函数具有刷新(清空)标准输入缓冲 区的作用。
int main(){
int i,ret;
while (fflush(stdin),ret = scanf("%d",&i) != EOF)
{
printf("i=%d\n",i);
}
}
2
3
4
5
6
7
8
9

scanf 函数每次读取一个字符并打印,由于我们一次性输入一个字符串,然后回车,而 scanf 函数是循环匹配的,所以不能加 fflush (stdin)。如果加了,那么会导致第一个字符匹配以后, 后面的字符被清空。
int main(){
char c;
while(scanf("%c",&c)!=EOF){
printf("%c\n",c); // 会把\n也读取进来 如下图所示出现两个\n
}
}
2
3
4
5
6
# 多种数据类型混合输入
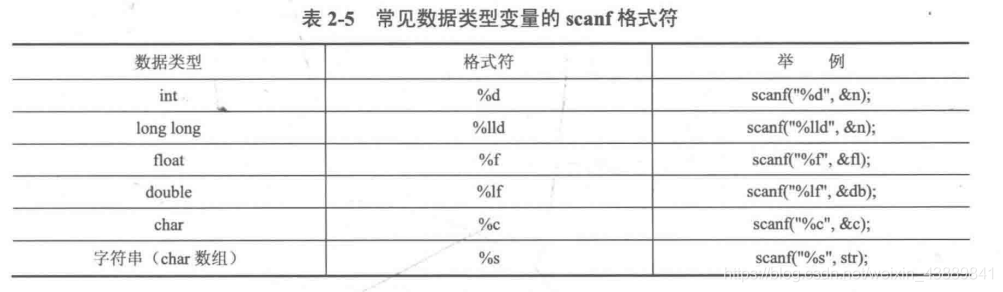
当我们让 scanf 函数一次读取多种类型的数据时,对于字符型数据要格外小心,因为当一行数据中存在字符型数据读取时,读取的字符并不会忽略空格和 '\n'(回车符),下面演示错误例子。
int main(){
int i;
char c;
float f;
scanf("%d%c%f",&i,&c,&f);
printf("%d%c%f",i,c,f);
}
2
3
4
5
6
7
会发现除了第一个正确读取输入外,由于 scanf 读取不会忽略空格和换行符,所以读取的为 20,空格,m。
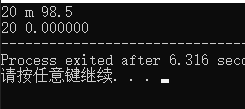
编写代码时,我们需要在 % d 与 % c 之间加入一个空格,输入格式和输出效果就正常。scanf 也可以正确匹配逗号,具体规则请查看 scanf 的正则匹配。 scanf 函数匹配成功了 3 个成员,所以返回值为 3,我们可以通过返回值来判断 scanf 函数匹配成功了几个成员,中间任何有一个成员匹配出错,后面的成员都会匹配出错。
浮点数输出默认带了 6 位小数,%5.2f 中的 5 代表输出的浮点数占 5 个空格的位置,2 代表小数点后显示两位。要注意的是如果是 double 类型需要用 %lf 来读取,否则将会按 float 的 4 个字节进截断。
int main(){
int i;
char c;
float f;
int ret;
ret = scanf("%d %c%f",&i,&c,&f);
printf("%d %c %5.2f %d\n",i,c,f,ret);
}
2
3
4
5
6
7
8
# getchar 和 putchar 函数介绍
使用 getchar 函数可以一次从标准输入读取一个字符,它等价于 char c,scanf("%c",&c)
输出字符型数据时使用 putchar 函数,其作用是向显示设备输出一个字符。
语法格式如下:
int main(){
char c;
c = getchar();
putchar(c);
c = getchar(); // 不会阻塞
putchar(c);
}
2
3
4
5
6
7
当只有一个字符时,使用多个 getchar 不会造成阻塞。
当有多个字符时,使用多少个 getchar 函数就读取多少个字符。
# printf 函数介绍
int main() {
int i = 10;
float f = 96.3;
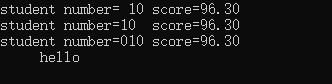
printf("student number=%3d score=%5.2f\n", i, f); //限制长度 并且printf默认是右对齐
printf("student number=%-3d score=%5.2f\n", i, f); //使用左对齐需要在前面放置负号
printf("student number=%03d score=%5.2f\n", i, f); //如不足定义的长度,需要在前面补0时,则在限制长度前面放置0
printf("%10s\n", "hello");
}
2
3
4
5
6
7
8
# 运算符与表达式
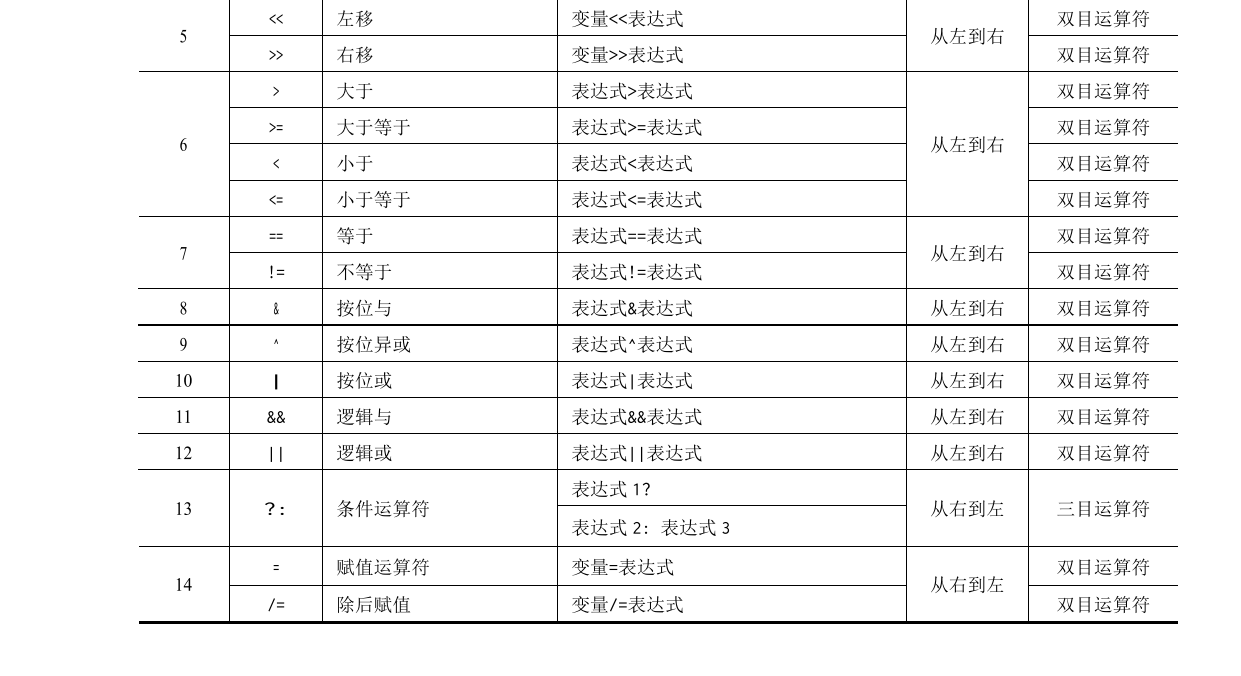
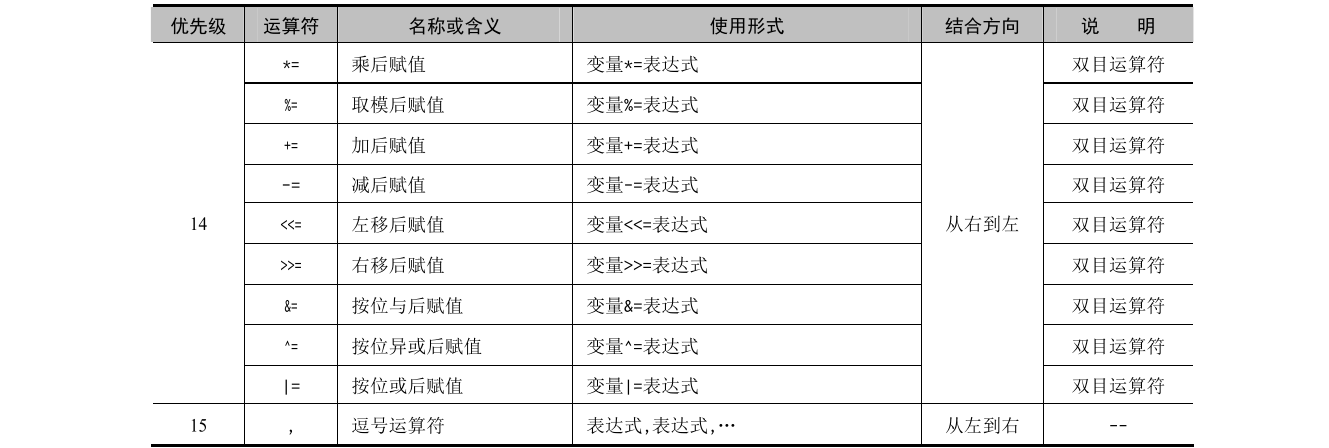
# 运算符分类
C 语言提供了 13 种类型的运算符,如下所示。
- 算术运算符(+ - * / %)。
- 关系运算符(> <==>= <= !=)。
- 逻辑运算符(! && ||)。
- 位运算符(<<>> ~ | ^ &)。
- 赋值运算符(= 及其扩展赋值运算符)。
- 条件运算符(?:)。
- 逗号运算符(,)。
- 指针运算符(* 和 &)。
- 求字节数运算符(sizeof)。
- 强制类型转换运算符((类型))。
- 分量运算符(. ->)。
- 下标运算符([])。
- 其他(如函数调用运算符 ())。
# 自增、自减运算符及求字节运算符
int main() {
int i = -1;
int j;
//5++ //报错 编译不通过
j = i++>-1; //分解 j=i>-1;然后i++;
printf("i=%d,j=%d\n",i,j); //0 0
j=!++i; //先++,按优先级结合顺序
printf("i=%d,j=%d\n",i,j); //1 0
}
2
3
4
5
6
7
8
9
上面代码块中的 j=i++>-1,对于后 ++ 或者后 --,首先我们需要去掉 ++ 或 -- 运算符,也就是首先计算 j=i>-1,因为 i 本身等于 - 1,所以得到 j 的值为 0,接着单独计算 i++,也就是对 i 加 1,所以 i 从 - 1 加 1 得到 0,因此 printf ("i=% d,j=% d\n",i,j); 语句的执行结果是 0 和 0。