 SprakCore
SprakCore
# SprakCore
# RDD 之装饰者模式
我们的 bufferreadReader 就是典型的装饰者模式,通过原有类不断增强功能,并保持原有类的功能
装饰者模式:动态地将责任附加到对象上。若要扩展功能,装饰者提供了比继承更有弹性的替代方案。
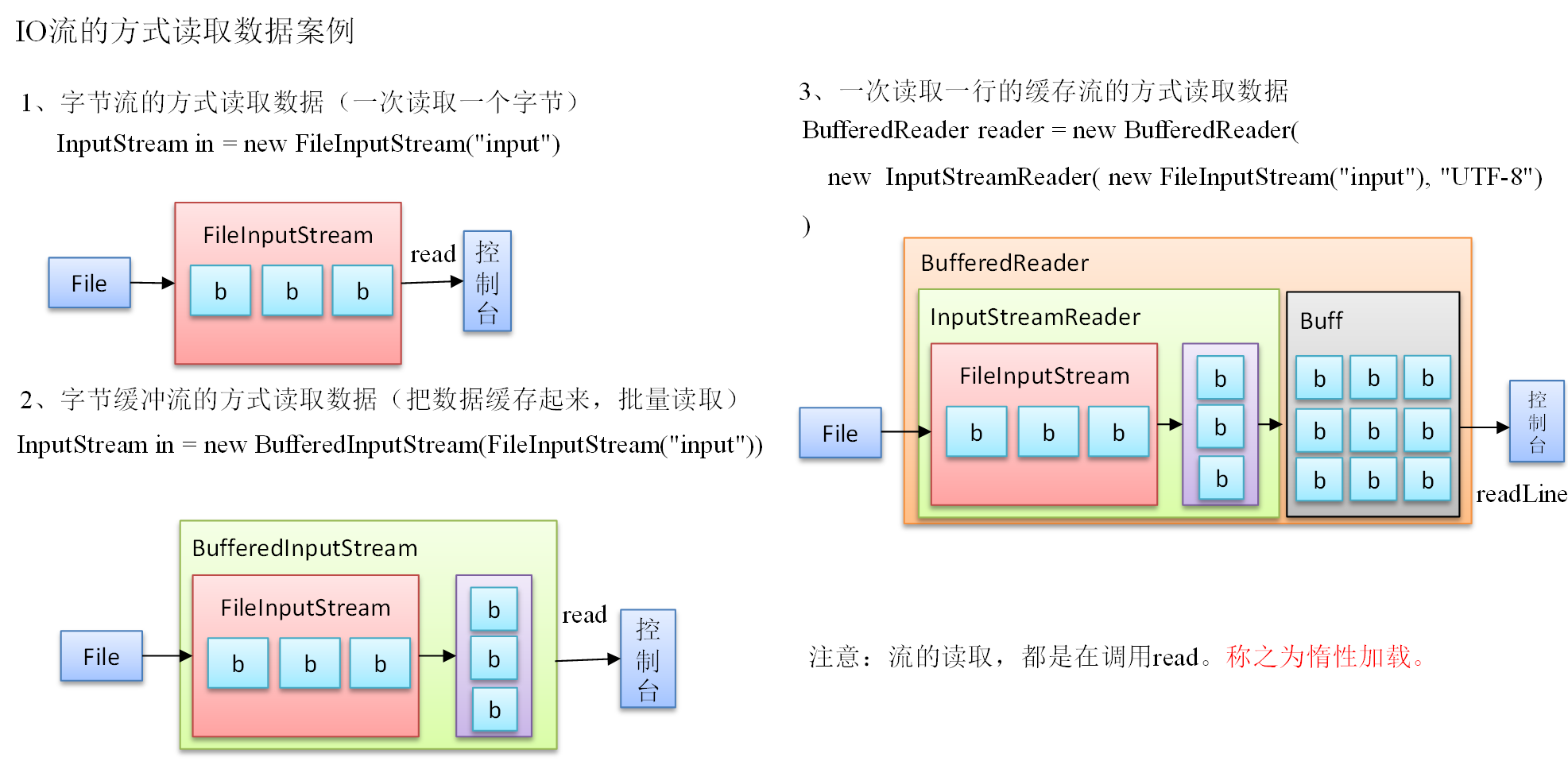
并且拥有一个特殊的特征 只有最外层的装饰者调用时 才会调用内部原有的装饰对象 称为惰性加载
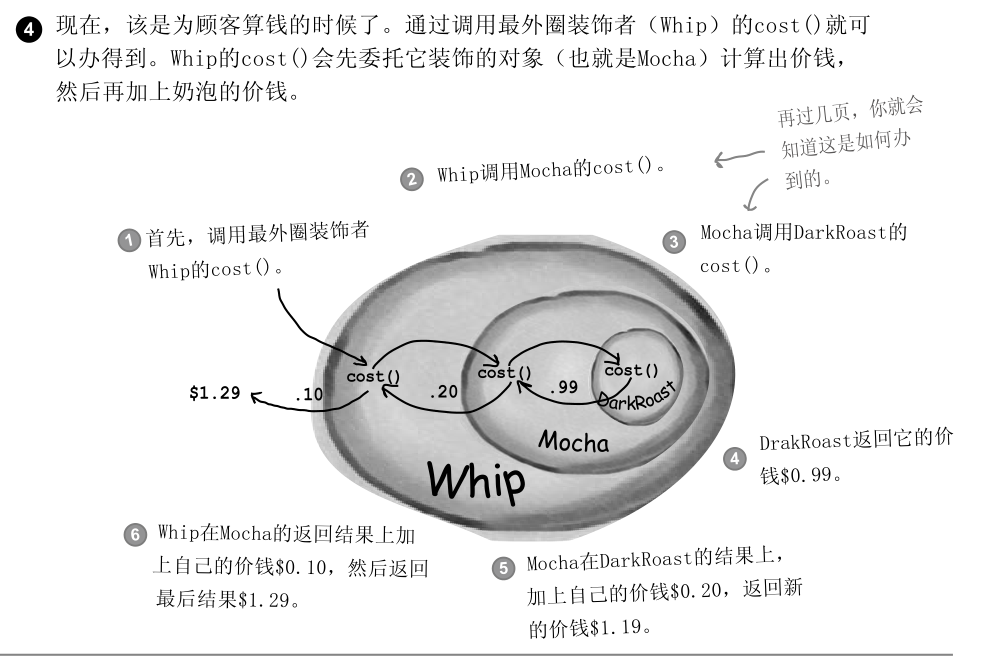
而我们 RDD 也是通过装饰者马上来包装不断装饰原有的功能

# RDD 弹性分布式数据集
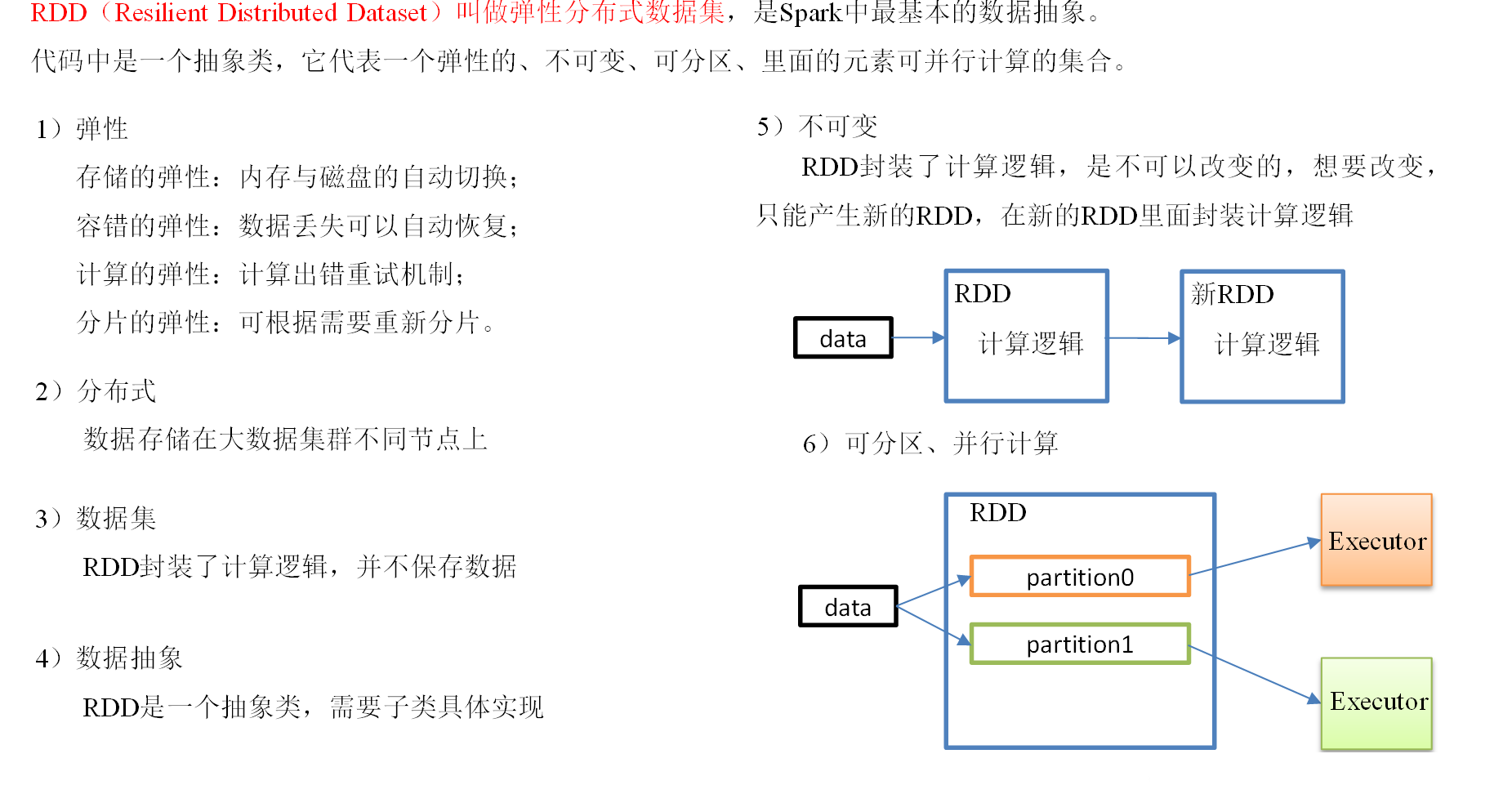
# RDD 特性
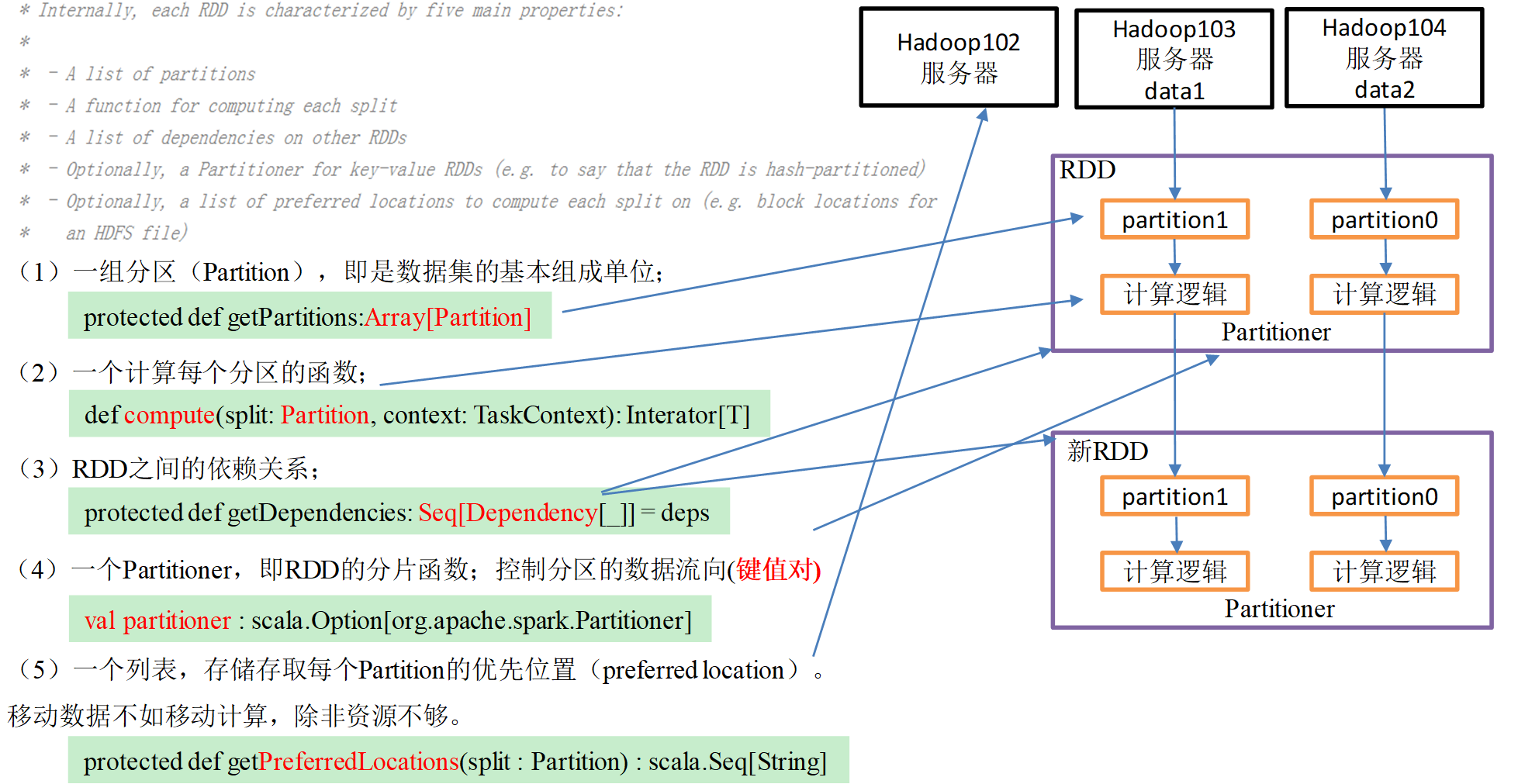
# RDD 编程
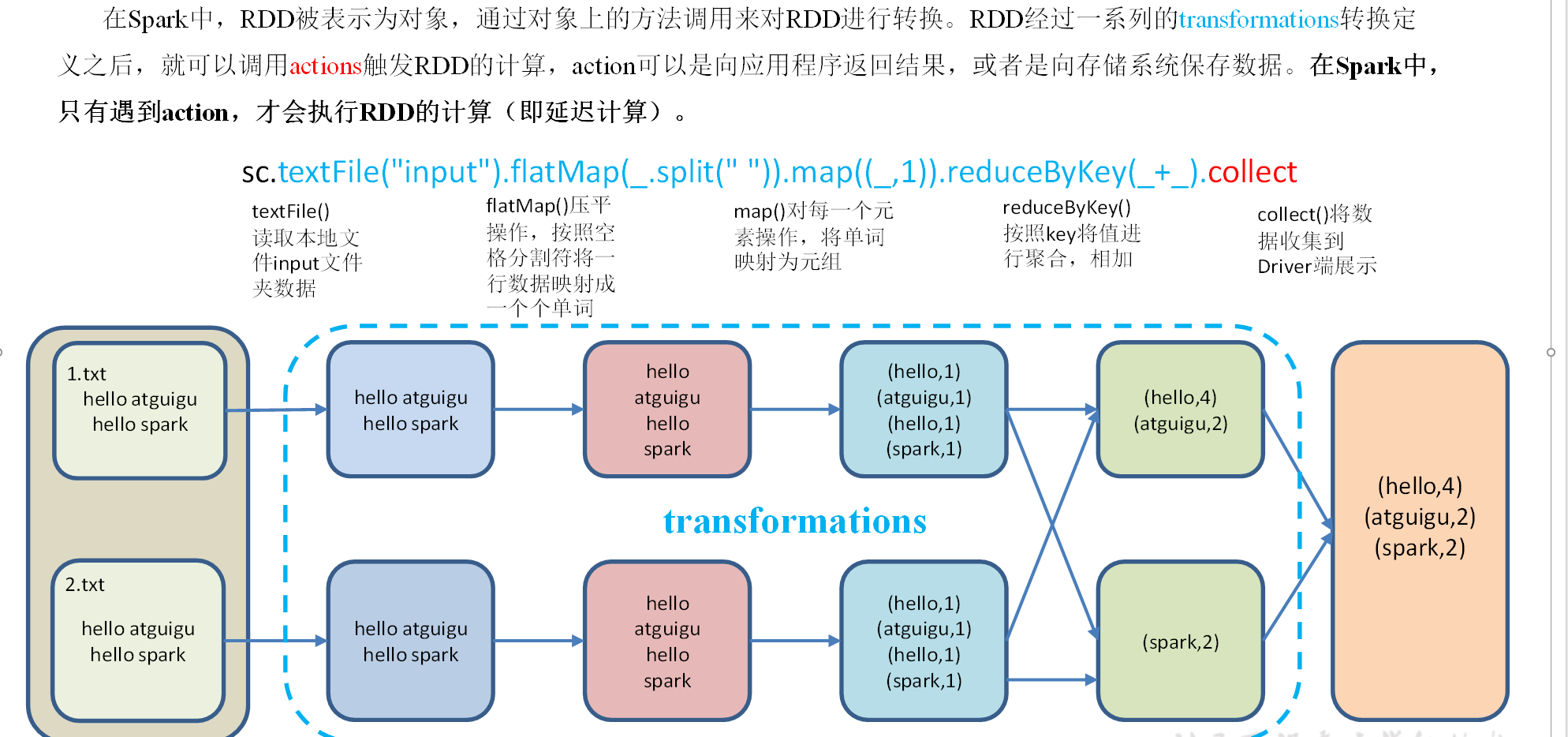
算子:从认知心理学角度来讲,解决问题其实是将问题的初始状态,通过一系列的转换操作(operator),变成解决状态。
# RDD 创建
在 Spark 中创建 RDD 的创建方式可以分为三种:从集合中创建 RDD、从外部存储创建 RDD、从其他 RDD 创建。
# 从集合中创建 RDD
- sc.parallelize(list)
- sc.makeRDD(list)
package com.atguigu.spark.day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//通过读取内存集合中的数据 创建RDD
object Spark01_CreateRDD_mem {
def main(args: Array[String]): Unit = {
//Spark配置文件对象
val conf: SparkConf = new SparkConf().setAppName(" Spark01_CreateRDD_mem").setMaster("local[*]")
//创建SparkContext对象
val sc: SparkContext = new SparkContext(conf)
//创建一个集合
val list: List[Int] = List(1, 2, 3, 4)
//根据集合创建RDD 方式一
// val rdd: RDD[Int] = sc.parallelize(list)
//根据集合创建RDD 方式二 底层调用是parallelize方法
val rdd: RDD[Int] = sc.makeRDD(list)
rdd.collect().foreach(println)
sc.stop()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 从外部存储系统的数据集创建
- sc.textFile(path)
package com.atguigu.spark.day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//通过读取外部文件 创建RDD
object Spark02_CreateRDD_file {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Spark02_CreateRDD_file").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//读取本地文件数据
val rdd: RDD[String] = sc.textFile("D:\\code\\spark\\input\\1.txt")
rdd.collect().foreach(println)
//从HDFS读取数据
val hdfsRdd: RDD[String] = sc.textFile("hdfs://hadoop102:8020/input")
hdfsRdd.collect().foreach(println)
sc.stop()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 分区规则
# 默认分区规则
- rdd.partitions 查看分区
package com.atguigu.spark.day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partition, SparkConf, SparkContext}
/**
* 默认分区
* - 从集合中创建RDD
* 取决于分配给应用的CPU的核数 如为* 则为cpu全部核数
* - 读取外部文件创建RDD
* math.min(取决于分配给应用的CPU的核数,2)
*/
object Spark03_Partition_default {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Spark03_Partition_default").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//通过集合创建RDD
// val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val rdd: RDD[String] = sc.textFile("D:\\code\\spark\\input\\1.txt")
//查看分区效果
val partitions: Array[Partition] = rdd.partitions
println(partitions.size) //分区数
rdd.saveAsTextFile("D:\\code\\spark\\output")
sc.stop()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31

# 指定分区
- sc.makeRDD(data , partition)
package com.atguigu.spark.day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partition, SparkConf, SparkContext}
/**
* 指定分区分区
* -根据下标与分区数进行运算 求出 [x,y) 开始到结束下标元素的具体分区分配
* - start (i * arr.lent) / partition
* - end ((i +1) * arr.lent ) / partition
*/
object Spark04_Partition_mem {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Spark04_Partition_mem").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//通过集合创建RDD
// val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),4) //默认分区数为cpu核数
//1)4个数据,设置4个分区,输出:0分区->1,1分区->2,2分区->3,3分区->4
//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 4)
//2)4个数据,设置3个分区,输出:0分区->1,1分区->2,2分区->3,4
//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 3)
//3)5个数据,设置3个分区,输出:0分区->1,1分区->2、3,2分区->4、5
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5), 3)
//查看分区效果
val partitions: Array[Partition] = rdd.partitions
println(partitions.size) //分区数
rdd.saveAsTextFile("D:\\code\\spark\\output")
sc.stop()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38

# 读取文件指定分区
package com.atguigu.spark.day02
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 读取外部文件 创建RDD
* - 默认分区规则
* math.min(分配的核数,2)
* - 指定分区 minPartitions 最小分区数 并不是实际分区个数
* - 在实际计算分区个数的时候 会根据文件的总大小和 最小分区数进行相除运算
* - 如果余数为0 最小分区数为实际分区数
* - 如果余数不为0 则实际分区数要看实际切片
*
*/
object Spark05_Partition_file {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Spark05_Partition_file").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
// val rdd: RDD[String] = sc.textFile("D:\\code\\spark\\input\\1.txt") //默认分区为2个
//2)输入数据1-4,每行一个数字;输出:0=>{1、2} 1=>{3} 2=>{4} 3=>{空}
//val rdd: RDD[String] = sc.textFile("input/3.txt",3)
//3)输入数据1-4,一共一行;输出:0=>{1234} 1=>{空} 2=>{空} 3=>{空}
val rdd: RDD[String] = sc.textFile("input/4.txt", 3)
rdd.saveAsTextFile("D:\\code\\spark\\output")
sc.stop()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32

getSplits 文件返回的是切片规划,真正读取是在 compute 方法中创建 LineRecordReader 读取的,有两个关键变量
start=split.getStart()
end = start + split.getLength
假设读取 text.txt 指定最小分区为 5
abc
ef
g
hj
klm
2
3
4
5
此文件总大小为 19 字节 19%5=3 每个分区每次追加个数要求为 19/6=3 字节 19 字节总大小 / 3 每次字节 = 6 个分区 余 1 所有实际分区数为 6+1 =7
如果 目前总大小 /(总大小 / 最小分区数) < 1.1 则不切片 则以指定分区数 详情源码看上图的 while 循环
分区 0 的数据为 每个分区每次读取 3 字节 因为读取是读取一行如果这一行数据超过了每次读取则整行读取 并读取下个分区
0~3 索引的数据
abc\r\n
分区 1 的数据为 3~6 索引的数据
ef\r\n
分区 2 的数据为 6~9 索引的数据
g\r\n
分区 3 数据为 9~12 索引的数据
hj\r\n
分区 4 数据为 12~15 索引的数据
分区 5 数据为 15~18 索引的数据
klm\r
分区 6 数据为 18~1 索引的数据