 Doris 概述
Doris 概述
# Doris 概述
Apache Doris 由百度大数据部研发(之前叫百度 Palo,2018 年贡献到 Apache 社区后,更名为 Doris )
Apache Doris 是一个现代化的 MPP (Massively Parallel Processing,即大规模并行处理)分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache Doris 可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
数据源经过各种数据集成和加工处理后,通常会入库到实时数仓 Doris 和离线湖仓(Hive, Iceberg, Hudi 中),Apache Doris 被广泛应用在以下场景中。
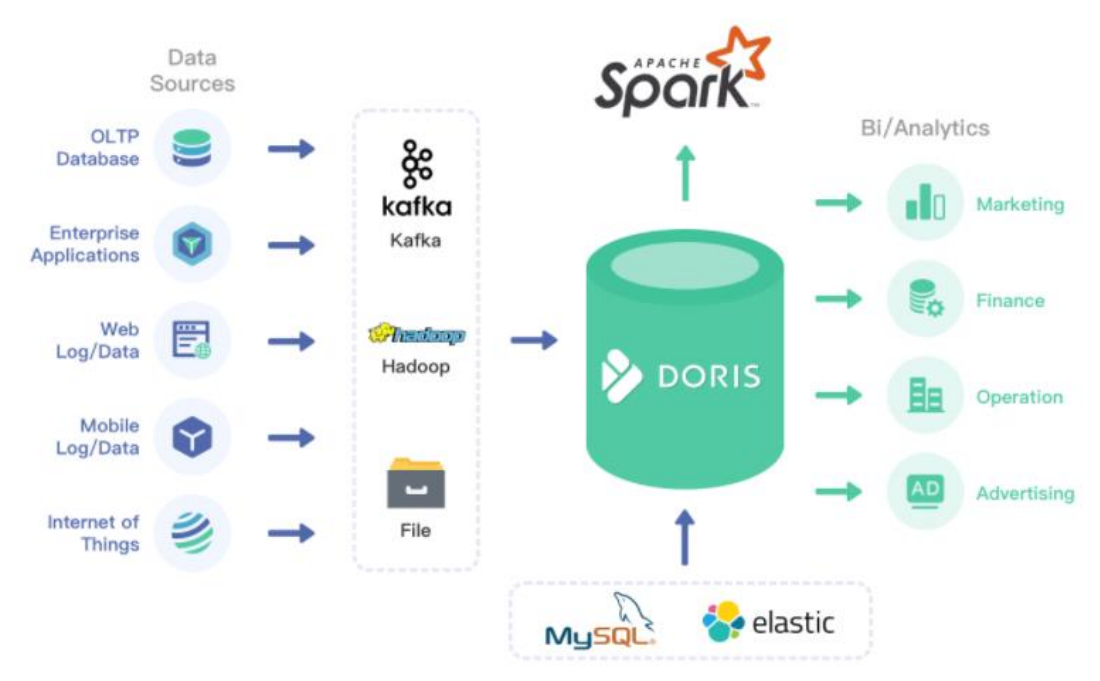
报表分析
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
即席查询(Ad-hoc Query)
面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
统一数仓构建
一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
数据湖联邦查询
通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
# Doris 架构
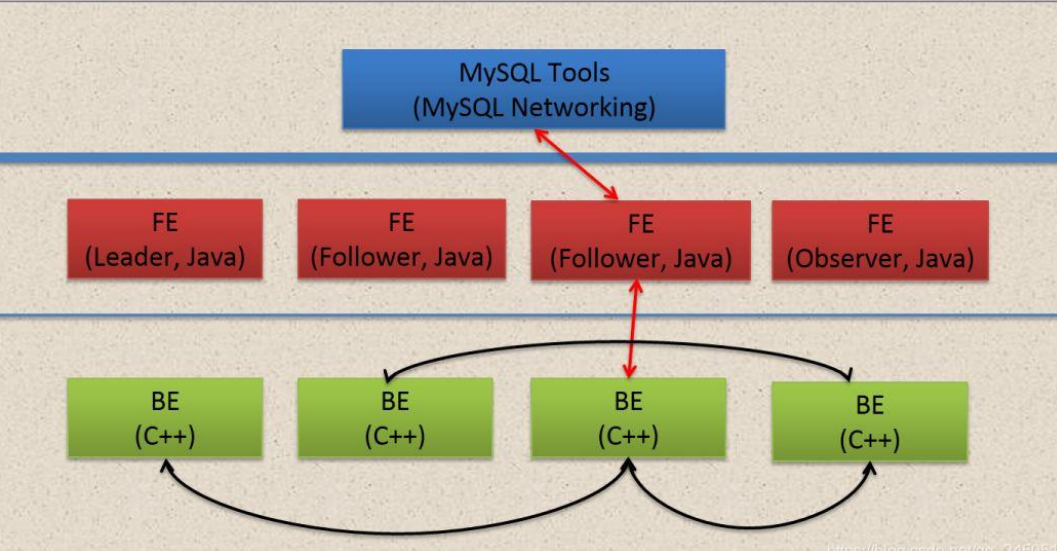
Doris 的架构很简洁,只设 FE (Frontend)、BE (Backend) 两种角色、两个进程,不依赖于 外部组件,方便部署和运维,FE、BE 都可线性扩展。
- FE (Frontend) :存储、维护集群元数据;负责接收、解析查询请求,规划查询计划,
调度查询执行,返回查询结果。主要有三个角色:
- Leader 和 Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下, 元数据能够实时地在线恢复,而不影响整个服务。
- Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力 非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不 参与任何的写入,只参与读取。
- BE (Backend) :负责 物理数据的存储和计算;依据 FE 生成的物理计划,分布式地执行查询。数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据 需求动态调整。
- MySQL Client:Doris 借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC 以及 MySQL 的客户 端,都可以直接访问 Doris。
- Broker:Broker 为一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统 中文件的能力,包括 HDFS,S3,BOS 等。