 数组
数组
# 数组
# 一维数组
# 数组的定义
数组,是指一组具有相同数据类型的数据的有序集合。
一维数组的定义格式为
//类型说明符 数组名 [常量表达式];
int a[10]; //定义一个整型数组,数组名为 a,它有 10 个元素。
2
声明数组时要遵循以下规则:
- 数组名的命名规则和变量名的相同,即遵循标识符命名规则。
- 在定义数组时,需要指定数组中元素的个数,方括号中的常量表达式用来表示元素的个数,即数组长度。
- 常量表达式中可以包含常量和符号常量,但不能包含变量。也就是说,C 语言不允许对数组的大小做动态定义,即数组的大小不依赖于程序运行过程中变量的值。
数组声明的其他常见错误如下:
int n;
scanf("%d", &n); /* 在程序中临时输入数组的大小 */
int a[n];
float a[0]; /* 数组大小为 0 没有意义 */
int b(2)(3); /* 不能使用圆括号 */
int k=3, a[k]; /* 不能用变量说明数组大小*/
2
3
4
5
6
7
# 一维数组在内存中的存储
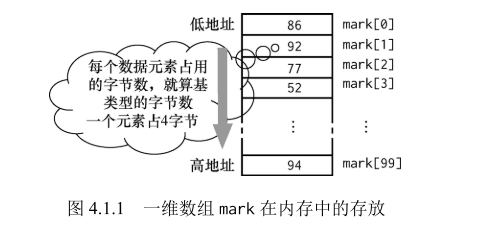
语句 int mark [100]; 定义的一维数组 mark 在内存中的存放情况如图 4.1.1 所示,每个元素都是整型元素,占用 4 字节,数组元素的引用方式是 “数组名 [下标]”,所以访问数组 mark 中的 元素的方式是 mark [0],mark [1],…,mark [99]。注意,没有元素 mark [100],因为数组元素是从 0 开始编号的。
在定义数组时对数组元素赋初值
int arr[5]={1,2,3,4,5} //定义一个整型数组,数组名为 a,它有 5 个元素。 指定前5个元素为1 2 3 4 5
只给一部分元素赋值:
int a[5] = {0,1}
//定义了a数组有5个元素,但花括号内只提供2个初值,这表示值给前面2个元素赋初值,后面3个值为0
//不能对已定义的数组 进行元素赋以初值
int a[4];
a[10]={0,1,2,3}
2
3
4
5
6
如果想要使一个数组全部元素值为 0:
int a[5] = {0,0,0,0,0}
int a[5] = {0}; //两者都可以
2
在对全部数组元素赋初值时,由于数据个数已经确定,因此可以不指定数组长度
int a[] = {1,2,3,4,5}; //定义了一个长度为5的数组,并赋初值
scanf 字符数组,不能检测输入的内容大于数组长度
int main(){
char c[5];
scanf("%s",c); //如果输入了大于5个字符的字符串 则会越界写入
print("%s\n",c); //还是会整个字符串读取出来 因为scanf已经越界写入数据了
}
2
3
4
5
一维数组的存储及函数传递
#include <stdio.h>
#include <stdlib.h>
//一维数组的传递,数组长度无法传递给子函数
//C 语言的函数调用方式是值传递
void print(int b[],int len)
{
int i;
for(i=0;i<len;i++) {
printf("%3d",b[i]);
}
b[4]=20; //在子函数中修改数组元素
printf("\n");
}
//数组越界
//一维数组的传递
#define N 5
int main()
{
int j=10;
int a[5]={1,2,3,4,5}; //定义数组时,数组长度必须固定
int i=3;
a[5]=20; //越界访问
a[6]=21;
a[7]=22; //越界访问会造成数据异常
print(a,5);
printf("a[4]=%d\n",a[4]); //a[4]发生改变
system("pause");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
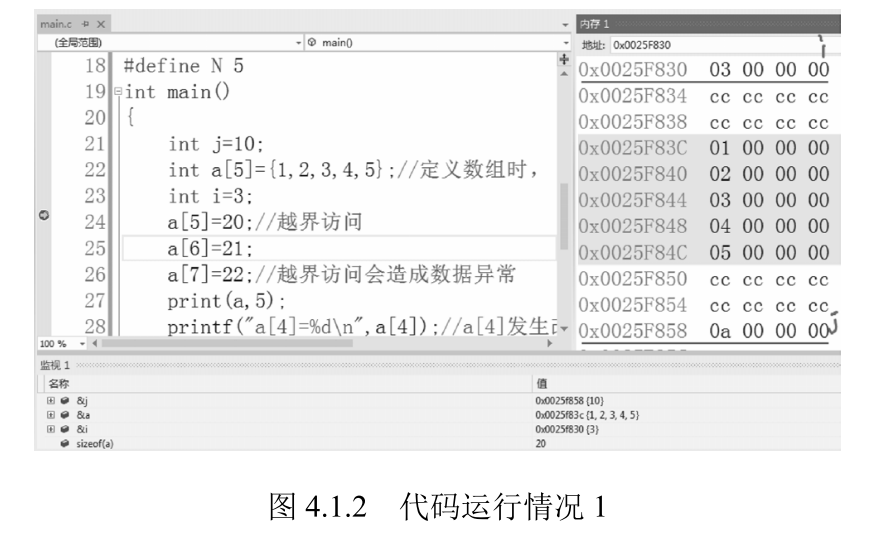
图 4.1.2 显示了代码运行情况。如图 4.1.2 所示,在第 24 行左键打上断点,然后单击 “运行” 按钮,在监视窗口一次输入 & j、&a、&i 来查看整型变量 j、整型数组 a、整型变量 i 的地址,左 键拖动对应地址到内存窗口即可看到三个变量的地址,这里就像我们给衣柜的每个格子的编号, 第一格、第二格…… 一直到柜子的最后一格。
操作系统对内存中的每个位置也给予一个编号,对 于 Windows 32 位控制台应用程序来说,这个编号的范围是从 0x00 00 00 00 到 0xFF FF FF FF, 总计为 2 的 32 次方,大小为 4G。这些编号称为地址。
我们看到,先定义的变量 j 的地址大于后定义的变量 i 的地址,所以先定义的变量放在高地址,后定义的变量放在低地址。其实每个函数开始执行时,系统会为其分配对应的函数栈空间, 而变量 j、变量 a、变量 i 都在 main 函数的栈空间中,由于后定义的变量在上面,因此这种效果 称为栈向上增长。
在监视窗口中输入 sizeof (a),可以看到数组 a 的大小为 20 字节,计算方法其实就是 sizeof (int)*5:数组中有 5 个整型元素,每个元素的大小为 4 字节,所以共有 20 字节。访问元素 的顺序是依次从 a [0] 到 a [4],a [5]=20、a [6]=21 均为访问越界。图 4.1.3 也显示了代码运行情况
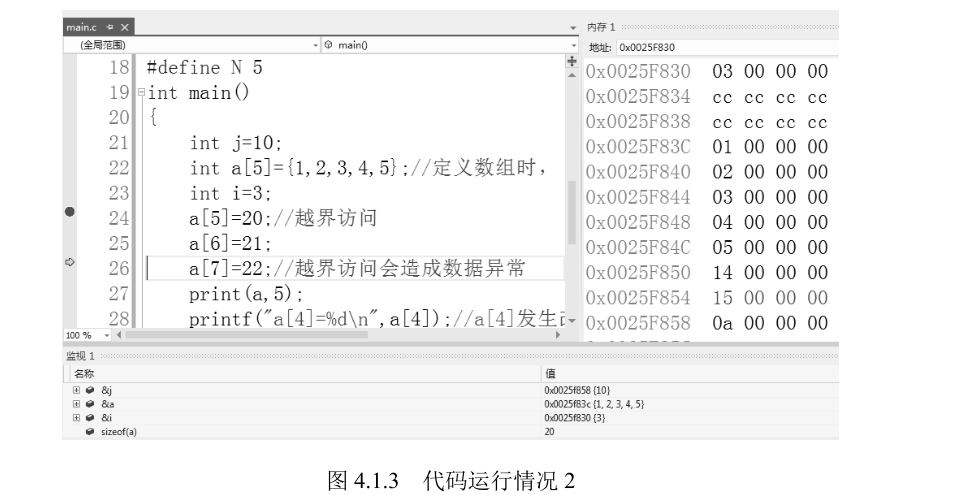
从中看出,执行到第 26 行时,数组 a 与变量 j 中间的 8 字节的保护空间已被赋值(微软公司的编译 器在不同的变量间设置了保护空间),而执行到第 27 行时,变量 j 的值被修改了,这就是访问越界 的危险性 —— 未对变量 j 赋值,其值却发生了改变!
数组另一个值得关注的地方是,编译器并不检查程序对数组下标的引用是否在数组的合法范围内。这种不加检查的行为有好处也有坏处,好处是不需要浪费时间对有些已知正确的数组下标 进行检查,坏处是这样做将无法检测出无效的下标引用。
一个良好的经验法则是:如果下标值是 通过那些已知正确的值计算得来的,那么就无须检查;如果下标值是由用户输入的数据产生的, 那么在使用它们之前就必须进行检查,以确保它们位于有效范围内(对于后端开发工程师来说, 如果这个下标是从前端接收过来的,那么一定要进行判断)。
如图 4.1.4 所示,在第 27 行按 F11 键,进入 print 函数,这时会发现数组 b 的大小变为 4 字节
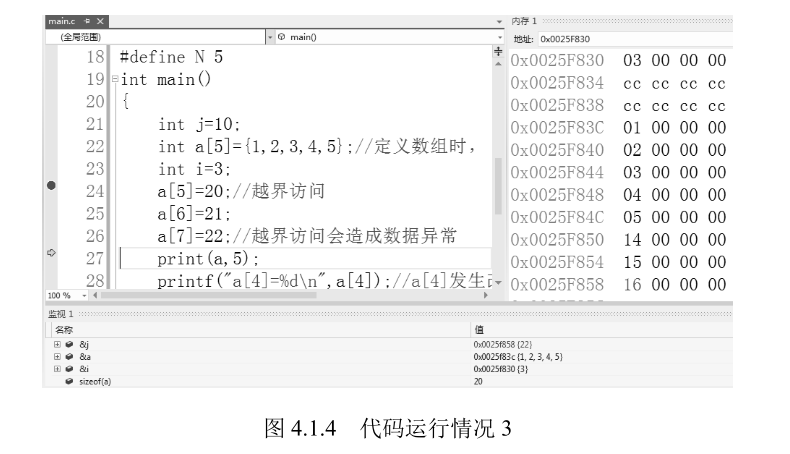
如图 4.1.5 所示,这是因为一维数组在传递时,其长度是传递不过去的,所以我们通过 len 来传递数组中的元素个数。实际数组名中存储的是数组的首地址,在调用函数传递时,是将数组 的首地址给了变量 b(其实变量 b 是指针类型,具体原理会在下一章讲解),在 b [] 的方括号中填 写任何数字都是没有意义的。
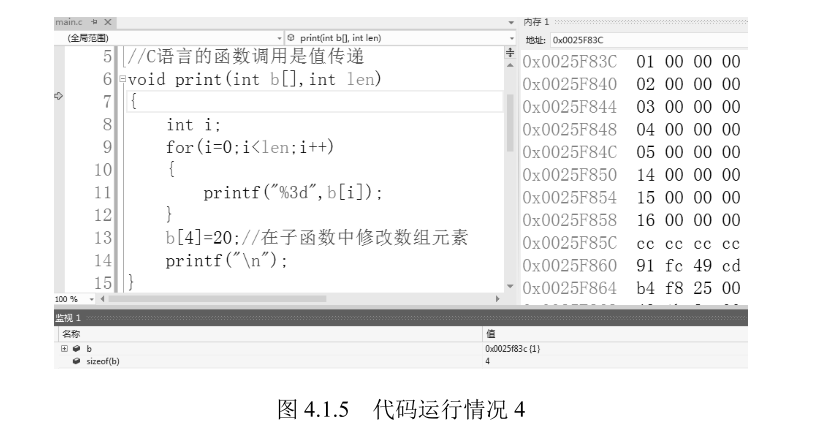
这时我们在 print 函数内修改元素 b [4]=20,可以看到数组 b 的起 始地址和 main 函数中数组 a 的起始地址相同,即二者在内存中位于同一位置,当函数执行结束 时,数组 a 中的元素 a [4] 就得到了修改。
# 栈空间和数组
Windows 操作系统中单个函数的栈空间大小是 1MB,Linux 操作系统中单个函数的栈空间大小是 10MB(Linux 操作系统下可以修改),单个函数的栈空间上限如例 4.1.2 所示。在 Windows 操作系统中,函数栈空间大小超出 1MB 后会出现什么情况?如例 4.1.3 所示,若将 N 设置为 250000,则这时运行没有任何异常,但若把 N 的值改为 260000,则执行时就会出现 Stack Overflow (栈空间溢出)错误,这是因为数组是定义在栈空间上的,当数组的大小为 260000 时就超出了单 个函数的栈空间,因此就会发生栈空间溢出,所以在使用栈空间时,尽量不要使用过大的数组。 如果需要使用大数组,那么使用堆空间
单个函数的栈空间上限。
#define N 250000
int main() {
int arr[N] = {0};
system("pause");
}
2
3
4
5

单个函数的栈空间访问越界。
#define N 260000 //超出了单个函数的栈空间限制
int main() {
int arr[N] = {0};
system("pause");
}
2
3
4
5
# 二维数组
二维数组定义的一般形式如下:
//类型说明符 数组名[常量表达式][常量表达式];
float a[3][4],b[5][10];
2
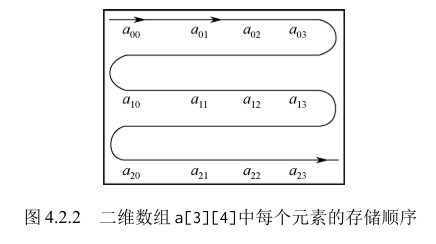
可以将二维数组视为一种特殊的一维数组:一个数组中的元素类型是一维数组的一维数组。
可以把二维数组 a [3][4] 视为一个一维数组,它有 3 个元素 a [0]、a [1] 和 a [2],每个元素又是一个包含 4 个元素的一维数组

二维数组中的元素在内存中的存储规则是按行存储,即先顺序存储第一行的元素,后顺序存储第二行的元素,数组元素的获取依次是从 a[0][0]到 a[0][1],直到最后一个元素 a[2][3] 。
# 二维数组的初始化及传递
分行给二维数组赋初值。例如
int a[3][4]={{1,2,3,4},{5,6,7,8},{9,10,11,12}};
将所有数据写在一个花括号内,按数组排列的顺序对各元素赋初值。例如,
int a[3][4]={1,2,3,4,5,6,7,8,9,10,11,12};
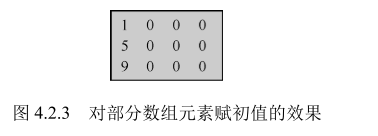
对部分数组元素赋初值。例如
int a[3][4]={{1},{5},{9}};
对部分数组元素赋初值的效果如下图所示
如果对全部元素赋初值,那么定义数组时可以不指定第一维的长度,但要指定第二维的 长度。例如
int a[3][4]={1,2,3,4,5,6,7,8,9,10,11,12};
//等价于
int a[][4]={1,2,3,4,5,6,7,8,9,10,11,12}; //两者等价
2
3
二维数组的存储与传递
//二维数组的首地址,赋值给 b
//行不能传递过去,列一定要写
void print(int b[][4], int row) {
int i, j;
for (i = 0; i < row; i++) { //外层循环为行
for (j = 0; j < sizeof(b[0]) / sizeof(int); j++) //内层循环为列 {
printf("%3d", b[i][j]);
}
printf("\n");
}
//二维数组的存储结构
//二维数组的传递
int main() {
int a[3][4] = {1, 3, 5, 7, 2, 4, 6, 8, 9, 11, 13, 15};
print(a, 3);
printf("a[2][3]=%d\n", a[2][3]); //打印最后面的一个元素
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
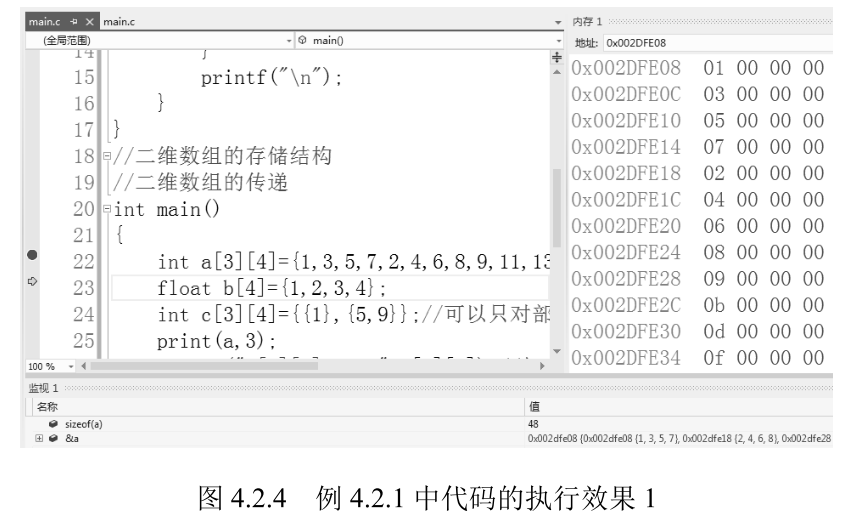
由图 4.2.4 可以看出,二维数组中的每个元素都按顺序存储,从低地址到高地址,大小为 sizeof (int)* 元素个数,元素个数为行乘以列,共 12 个元素,所以大小为 48 字节。
执行到 print 函数时,按 F11 键即可进入 print 函数。二维数组在传递时,列数一定要写,因为二维数组传递 时也是以指针变量形式传递的,列数要与主函数中二维数组 a 的列数相同。
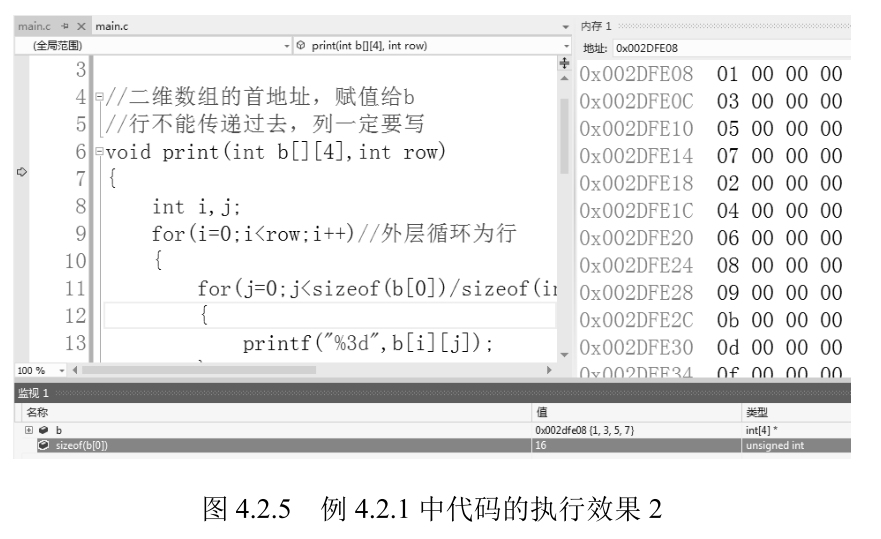
图 4.2.5 也显示了代 码的执行效果,从中可以看出 b 的地址值与 a 的相等,同时 sizeof (b [0]) 的值为 16,b [0] 代表 第一行,是一个一维数组,除以 sizeof (int) 就可以得到一行中元素的个数。
二维数组在打印时, 外层为行,内层为列,这样就可以以矩阵效果打印二维数组中的每个元素。
# 字符数组
字符数组的定义方法与前面介绍的一维数组、二维数组的类似。
char c[10];
c[0]='I';c[1]=' ';c[2]='a';c[3]='m';c[4]='';c[5]='h';c[6]='a';c[7]='p';c[8]='p';c[9]='y';
char c[10]={'I','a','m','h','a','p','p','y'}
2
3
但工作中一般不用以上两种初始化方式,因为字符数组一般用来存取字符串。通常采用的初始化方式是 char c[10]= "hello" 。
char c[10]= "hello
因为 C 语言规定字符串的结束标志为 '\0',而系统会对字符 串常量自动加一个 '\0',为了保证处理方法一致,一般会人为地在字符数组中添加 '\0',所以字 符数组存储的字符串长度必须比字符数组少 1 字节。例如,char c [10] 最长存储 9 个字符,剩余 的 1 个字符用来存储 '\0'。
# 字符数组初始化及传递。
#include <stdio.h>
#include <stdlib.h>
void print(char c[]) {
int i = 0;
while (c[i]) {
printf("%c", c[i]);
i++;
}
printf("\n");
}
//字符数组存储字符串,必须存储结束符'\0' //scanf 读取字符串时使用%s
int main() {
char c[5] = {'h', 'e', 'l', 'l', 'o'};
char d[5] = "how";
printf("%s----%s\n", c, d); //会发现打很多“烫”字
scanf("%s%s",c,d); //如果输入 how are 的话 scanf %s %d %f 默认忽略空格和\n
//他会认为输入了两段字符串 把how\0赋值给c 把are\0赋值给d
printf("%s----%s\n",c,d);
print(c);
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
上面代码的第一个 printf 的执行结果如下图所示

为什么对数组赋值 "hello" 却打印出很多 “烫” 字?这是因为 printf 通过 % s 打印字符串时,原理是依次输出每个字符,当读到结束符 '\0' 时, 结束打印;
scanf 通过 % s 读取字符串,对 c 和 d 分别输入 "are" 和 "you"(中间加一个空格),scanf 在使用 % s 读取字符时,会忽略空格和回车。如代码块中第 18 行中描述一样。
我们通过 print 函数模拟实现 printf 的 % s 打印效果,如代码块中第 6 行的 while 表达式中条件 c[i] ,当 c [i] 为 '\0' 时, 其值是 0,循环结束,也可以写为 c [i]!='\0'。
# gets 函数与 puts 函数
gets 函数类似于 scanf 函数,用于读取标准输入。前面我们已经知道 scanf 函数在读取字符串时遇到空格就认为读取结束,所以当输入的字符串存在空格时,我们需要使用 gets 函数进 行读取。
gets 函数的格式如下:
char *gets(char *str);
gets 函数从 STDIN(标准输入)读取字符并把它们加载到 str(字符串)中,直到遇到换行符(\n)或到达 EOF。
int main(){
char c[50];
gets(c);
printf("%s\n",c);
puts(c); //如果使用puts(c) puts会自动帮我们打印\n 无需我们手动输入\n
}
2
3
4
5
6
我们输入 "how are you", 共 11 个字符,可以看到 gets 会读取空格,同时可以看到我们并未给数组进行初始化赋值,但是 最后有 '\0',这是因为 gets 遇到 \n 后,不会存储 \n,而是将其翻译为空字符 '\0'。
puts 函数类似于 printf 函数,用于输出标准输出。puts 函数的格式如下:
int puts(char *str);
函数 puts 把 str(字符串)写入 STDOU(标准输出)。puts 执行成功时返回非负值,执行失败时返回 EOF。
如果想要使用 gets 函数不断的获取字符串,需要判断是否传递地址,获取成功则返回字符数组的起始地址,获取失败返回 NULL
int main(){
char c[50];
while(gets(c) != NULL){
puts(c);
}
}
2
3
4
5
6
# fgets 接口实现标准输入
如果 gets 函数不能使用,可以使用 fgets 实现标准数,fgets 函数 会把 \n 也进行读取,然后放入我们的字符数组,如果读取失败返回 NULL
int main(){
char c[50];
fgets(c,sizeof(c),stdin);
puts(c);
}
2
3
4
5
# str 系列字符串操作函数
str 系列字符串操作函数主要包括 strlen、strcpy、strcmp、strcat 等,strlen 函数用于统计字符串长度,strcpy 函数用于 将某个字符串复制到字符数组中,strcmp 函数用于比较两个字符串的大小,strcat 函数用于将 两个字符串连接到一起。各个函数的具体格式如下所示:
#include <string.h>
size_t strlen(char *str);
char *strcpy(char *to, const char *from);
int strcmp(const char *str1, const char *str2);
char *strcat(char *str1, const char *str2);
2
3
4
5
对于传参类型 char*,直接放入字符数组的数组名即可。 接下来我们通过 str 系列字符串操作函数的使用来具体学习 str 系列字符串操作函数,掌握每个函数的内部实现。
str 系列字符串操作函数的使用:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int mystrlen(char c[]) {
int i=0;
while(c[i++]);
return i-1;
}
void myStrcpyy(char to[],char form[]){
int i=0;
while(form[i]){
to[i]=from[i];
i++;
}
to[i]=from[i];
}
int main() {
int len; //用于存储字符串长度
char c[20];
char d[100]="world";
while(gets(c)!=NULL) {
puts(c);
len=strlen(c); //strlen 统计字符串长度
printf("len=%d\n",len);
len=mystrlen(c); //自定义方法实现 统计字符串长度
printf("mystrlen len=%d\n",len);
strcat(c,d); // 拼接两个字符串 str1的字符数组剩下长度必须大于等于str2长度 否则会越界写入
strcpy(d,c); //c 中的字符串复制给 d,strcpy会发生访问越界如果to字符数组小于from字符数组长度
myStrcpyy(d,c); //自定义方法实现 拷贝字符串
puts(d);
printf("c?d %d\n",strcmp(c,d)); //strcmp是逐个字符进行比较 如str1 小于 str2 则返回-1
//str1 等于 str2 返回0
//str1 大于 str2 返回1
puts(c);
}
system("pause");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
strcpy 函数用来将字符串中的字符逐个地赋值给目标字符数组。例中我们将 c 复制给 d,就是将 c 中的每个字符依次赋值给 d,也会将结束符赋值给 d。注意,目标数组一定要大于字符串 大小,即 sizeof (d)>strlen (c),否则会造成访问越界。
strcmp 函数用来比较两个字符串的大小,由于字符数组 c 中的字符串与 d 相等,所以这里的返回值为 0。如果 c 中的字符串大于 d,那么返回值为 1;如果 c 中的字符串小于 d,那么返回 值为−1。如何比较两个字符串的大小呢?具体操作是从头开始,比较相同位置字符的 ASCII 码值, 若发现不相等则直接返回,否则接着往后比较。例如,strcmp ("hello","how") 的返回值是−1, 即 "hello" 小于 "how",因为第一个字符 h 相等,接着比较第二个位置的字符,e 的 ASCII 码值小 于 o 的,然后返回−1。
strcat 函数用来将一个字符串接到另外一个字符串的末尾。例中字符数组 c 中存储的是 "hello",我们将 d 中的 "world" 与 c 拼接,最终结果为 "helloworld"。注意,目标数组必须大于 拼接后的字符串大小,即 sizeof (c)>strlen (“helloworld”)。
# strn 系列字符串操作函数
strn 系列字符串操作函数包括 strncpy 函数、strncmp 函数和 strncat 函数。只需要复制一部分原字符串中的字符时,使用 strncpy 函数;只需要比较两个字符串的一部分是否相等时,使 用 strncmp 函数;需要将一个字符串的部分字符拼接到另一个字符串时,使用 strncat 函数。下 面是这三个函数的用法。
char *strncpy(char *to, const char *from, size_t count);
功能:将字符串 from 中至多 count 个字符复制到字符串 to 中。如果字符串 from 的长度小于 count,那么其余部分用 '\0' 填补,返回处理完成的字符串。
int strncmp(const char *str1, const char *str2, size_t count);
功能:比较字符串 str1 和 str2 中至多 count 个字符,返回值如下图所示。
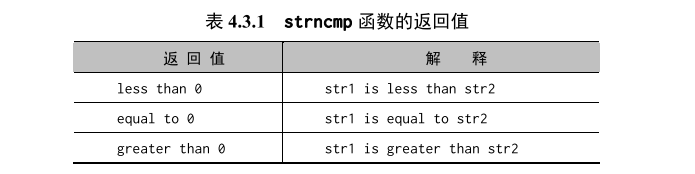
如果参数中任一字符串的长度小于 count,那么比较到第一个空值结束符时就结束处理。
char *strncat(char *str1, const char *str2, size_t count);
功能:将字符串 from 中至多 count 个字符连接到字符串 to 中,追加空值结束符并返回处理完成的字符串。
# mem 系列操作函数
虽然将 mem 系列函数放到字符数组这一章进行讲解,但是 mem 系列函数其实是任何类型的数组都可以进行操作的,无论是字符型数组、整型数组、浮点型数组,还是后续章节中要讲到的结 构体数组。mem 系列函数包括 memset 函数、memcpy 函数、memmove 函数、memcmp 函数等。
需要将一个数组的全部元素置为 0 时,要使用 memset 函数,具体格式如下:
void *memset(void *buffer, int ch, size_t count);
功能:函数将 ch 复制到 buffer 从头开始的 count 个字符中,并返回 buffer 指针。
memset 函数可以用于将一段内存初始化为某个值,例如:
memset(the_array, '\0', sizeof(the_array));
这是将一个数组的所有元素设置为 0 的便捷方法。注意,memset 函数将每个字节都设置为 ch。
需要将一个整型数组、浮点型数组的数据,或者某部分元素复制到另外一个数组时,不能使用 strcpy 函数,而要使用 memcpy 函数,其具体格式如下:
void *memcpy( void *to, const void *from, size_t count );
功能:函数从 from 中复制 count 个字符到 to 中,并返回 to 指针。如果 to 和 from 重叠,那么函数行为不确定。
memcpy 函数的使用。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//strcpy 不能用于整型数组、浮点型数组
int main() {
int a[5]={1,2,3,4,5};
int b[5];
int i;
memcpy(b,a,sizeof(a));
for(i=0;i<5;i++) {
printf("%3d",b[i]);
}
printf("\n");
system("pause");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
代码运行后可以得到内容与 a 数组一致的 b 数组,但是如果改用 strcpy 函数, 那么两个数组的内容就不会相同。
当复制的内容发生重叠时,需要用 memmove 函数而不能用 memcpy 函数,具体格式如下:
void *memmove(void *to, const void *from, size_t count);
功能:与 mencpy 函数相同,不同的是当 to 和 from 的内容有重叠时,函数仍能正常工作。
需要比较两个数组中的前若干字符时,要使用 memcmp 函数,具体格式如下:
int memcmp(const void *buffer1, const void *buffer2, size_t count);
功能:函数比较 buffer1 和 buffer2 的前 count 个字符,memcmp 函数可以比较任何类型的数组,主要比较两个数组是否相同,其内部原理实际上是逐个比较字节的大小,count 变量用来控制要比较的字节数量。