 Flink 流处理 API
Flink 流处理 API
# Flink 流处理 API
# Hello Flink!
让我们写一个简单的例子来获得使用 DataStream API 编写流处理应用程序的粗浅印象。我们将使用这个简单的示例来展示一个 Flink 程序的基本结构,以及介绍一些 DataStream API 的重要特性。我们的示例程序摄取了一条(来自多个传感器的)温度测量数据流。
首先让我们看一下表示传感器读数的数据结构:
首先创建 传感器 SensorReading 类
package com.atguigu.day2
/**
* @author Iekr
* Date: 2022/11/30/0030 14:38
*/
// id:传感器id,timestamp:时间戳,temperature:温度值
case class SensorReading(id: String, timestamp: Long, temperature: Double)
2
3
4
5
6
7
8
9
10
public class SensorReading {
public String id;
public long timestamp;
public double temperature;
public SensorReading() { }
public SensorReading(String id, long timestamp, double temperature) {
this.id = id;
this.timestamp = timestamp;
this.temperature = temperature;
}
public String toString() {
return "(" + this.id + ", " + this.timestamp + ", " + this.temperature + ")";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// Make sure to add code blocks to your code group
然后我们创建一个自定义源继承 RichParallelSourceFunction 这个类重写 run 和 cancel 方法
package com.atguigu.day2
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
import org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}
import java.util.Calendar
import scala.util.Random
/**
* @author Iekr
* Date: 2022/11/30/0030 14:51
*/
// 泛型是SensorReading表明产生的流中的事件类型为SensorReading
class SensorSource extends RichParallelSourceFunction[SensorReading] {
// 表示数据源是否正常运行
var runtime: Boolean = true
// 剩上下文参数用来发出数据
override def run(sourceContext: SourceContext[SensorReading]): Unit = {
val rand = new Random
var curFTemp = (1 to 10).map(
// 使用高斯噪声产生随机温度值
i => ("sensor_" + i, (rand.nextGaussian() * 20))
)
//产生无限无限数据流
while (runtime) {
curFTemp = curFTemp.map(
t => (t._1, t._2 + (rand.nextGaussian() * 0.5))
)
// 产生ms为单位的时间戳
val curTime = Calendar.getInstance.getTimeInMillis
//使用sourceContext参数的collect方法发送传感器数据
curFTemp.foreach(t => sourceContext.collect(SensorReading(t._1, curTime, t._2)))
// 每隔100ms发送一条传感器数据
Thread.sleep(100)
}
}
// 定义当取消flink任务时,需要关闭数据源
override def cancel(): Unit = runtime = false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
public class AverageSensorReadings {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<SensorReading> sensorData = env.addSource(new SensorSource());
DataStream<T> avgTemp = sensorData
.map(r -> {
Double celsius = (r.temperature - 32) * (5.0 / 9.0);
return SensorReading(r.id, r.timestamp, celsius);
})
.keyBy(r -> r.id)
.timeWindow(Time.seconds(5))
.apply(new TemperatureAverager());
avgTemp.print();
env.execute("Compute average sensor temperature");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// Make sure to add code blocks to your code group
创建 ConsumeFormSensorSource 测试类消费我们的自定义数据源
package com.atguigu.day2
import org.apache.flink.streaming.api.scala._
/**
* @author Iekr
* Date: 2022/11/30/0030 15:01
*/
object ConsumeFormSensorSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
stream.print()
env.execute()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class AverageSensorReadings {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<SensorReading> sensorData = env.addSource(new SensorSource());
DataStream<T> avgTemp = sensorData
.map(r -> {
Double celsius = (r.temperature - 32) * (5.0 / 9.0);
return SensorReading(r.id, r.timestamp, celsius);
})
.keyBy(r -> r.id)
.timeWindow(Time.seconds(5))
.apply(new TemperatureAverager());
avgTemp.print();
env.execute("Compute average sensor temperature");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// Make sure to add code blocks to your code group

# 转换算子
一个流的转换操作将会应用在一个或者多个流上面,这些转换操作将流转换成一个或者多个输出流。编写一个 DataStream API 简单来说就是将这些转换算子组合在一起来构建一个数据流图,这个数据流图就实现了我们的业务逻辑。
大部分的流转换操作都基于用户自定义函数 UDF。UDF 函数打包了一些业务逻辑并定义了输入流的元素如何转换成输出流的元素。像 MapFunction 这样的函数,将会被定义为类,这个类实现了 Flink 针对特定的转换操作暴露出来的接口。
DataStream<String> sensorIds = filteredReadings
.map(r -> r.id);
2
函数接口定义了需要由用户实现的转换方法,例如上面例子中的 map() 方法。
大部分函数接口被设计为 Single Abstract Method (单独抽象方法)接口,并且接口可以使用 Java 8 匿名函数来实现。Scala DataStream API 也内置了对匿名函数的支持。当讲解 DataStream API 的转换算子时,我们展示了针对所有函数类的接口,但为了简洁,大部分接口的实现使用匿名函数而不是函数类的方式。
DataStream API 针对大多数数据转换操作提供了转换算子。如果你很熟悉批处理 API、函数式编程语言或者 SQL,那么你将会发现这些 API 很容易学习。我们会将 DataStream API 的转换算子分成四类:
- 基本转换算子:将会作用在数据流中的每一条单独的数据上。
- KeyedStream 转换算子:在数据有 key 的情况下,对数据应用转换算子。
- 多流转换算子:合并多条流为一条流或者将一条流分割为多条流。
- 分布式转换算子:将重新组织流里面的事件。
# 基本转换算子
基本转换算子会针对流中的每一个单独的事件做处理,也就是说每一个输入数据会产生一个输出数据。单值转换,数据的分割,数据的过滤,都是基本转换操作的典型例子。我们将解释这些算子的语义并提供示例代码。
# Map
map 算子通过调用 DataStream.map() 来指定。 map 算子的使用将会产生一条新的数据流。它会将每一个输入的事件传送到一个用户自定义的 mapper,这个 mapper 只返回一个输出事件,这个输出事件和输入事件的类型可能不一样。下图展示了一个 map 算子,这个 map 将每一个正方形转化成了圆形。

MapFunction 的类型与输入事件和输出事件的类型相关,可以通过实现 MapFunction 接口来定义。接口包含 map() 函数,这个函数将一个输入事件恰好转换为一个输出事件。
// T: the type of input elements
// O: the type of output elements
MapFunction[T, O]
> map(T): O
2
3
4
下面的代码实现了将 SensorReading 中的 id 字段抽取出来的功能。
package com.atguigu.day2
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
/**
* @author Iekr
* Date: 2022/11/30/0030 15:24
*/
object MapExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[SensorReading] = env.addSource(new SensorSource)
stream.map(r => r.id).print()
//自定义算子
stream.map(new MyMapFunction).print()
//匿名内部方式创建自定义算法
stream.map(new MapFunction[SensorReading, String] {
override def map(t: SensorReading) = t.id
}).print()
env.execute()
}
// 输入泛型:SensorReading,输出泛型:String 继承Flink给我们提供的算子函数
class MyMapFunction extends MapFunction[SensorReading, String] {
override def map(t: SensorReading): String = t.id
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<SensorReading> readings = env.addSource(new SensorSource());
DataStream<String> sensorIds = readings.map(new IdExtractor()).print();;
// 匿名函数的写法
DataStream<String> sensorIds = readings.map(r -> r.id).print();;
env.execute();
}
public static class IdExtractor implements MapFunction<SensorReading, String> {
@Override
public String map(SensorReading r) throws Exception {
return r.id;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// Make sure to add code blocks to your code group
# Filter
filter 转换算子通过在每个输入事件上对一个布尔条件进行求值来过滤掉一些元素,然后将剩下的元素继续发送。一个 true 的求值结果将会把输入事件保留下来并发送到输出,而如果求值结果为 false ,则输入事件会被抛弃掉。我们通过调用 DataStream.filter() 来指定流的 filter 算子, filter 操作将产生一条新的流,其类型和输入流中的事件类型是一样的。下图展示了只产生白色方框的 filter 操作。

布尔条件可以使用函数、FilterFunction 接口或者匿名函数来实现。FilterFunction 中的泛型是输入事件的类型。定义的 filter() 方法会作用在每一个输入元素上面,并返回一个布尔值。
// T: the type of elements
FilterFunction[T]
> filter(T): Boolean
2
3
下面的例子展示了如何使用 filter 来从传感器数据中过滤掉 id 不是 sensor_1 的数据。
package com.atguigu.day2
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala._
/**
* @author Iekr
* Date: 2022/11/30/0030 15:36
*/
object FilterExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
stream.filter(r => r.id.equals("sensor_1")).print()
// 自定义算子
stream.filter(new MyFilterFunction)
//匿名函数写法
stream.filter(new FilterFunction[SensorReading] {
override def filter(t: SensorReading) = t.id.equals("sensor_1")
}).print()
env.execute()
}
// 自定义算子 filter算子输入和输出类型都是一样的,所有只有一个泛型:SensorReading
class MyFilterFunction extends FilterFunction[SensorReading] {
override def filter(t: SensorReading) = t.id.equals("sensor_1")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# FlatMap
flatMap 算子和 map 算子很类似,不同之处在于针对每一个输入事件 flatMap 可以生成 0 个、1 个或者多个输出元素。事实上, flatMap 转换算子是 filter 和 map 的泛化。所以 flatMap 可以实现 map 和 filter 算子的功能。下图展示了 flatMap 如何根据输入事件的颜色来做不同的处理。如果输入事件是白色方框,则直接输出。输入元素是黑框,则复制输入。灰色方框会被过滤掉。

flatMap 算子将会应用在每一个输入事件上面。对应的 FlatMapFunction 定义了 flatMap() 方法,这个方法返回 0 个、1 个或者多个事件到一个 Collector 集合中,作为输出结果。
// T: the type of input elements
// O: the type of output elements
FlatMapFunction[T, O]
> flatMap(T, Collector[O]): Unit
2
3
4
下面通过几个元素作为例子来展示 flatMap 如何使用
package com.atguigu.day2
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
/**
* @author Iekr
* Date: 2022/11/30/0030 16:03
*/
object FlatMapExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.fromElements("white", "gray", "black")
// flatMap 针对流中的每一个元素,生成0个,1个,或者多个数据
stream.flatMap(new MyFlatMapFunction).print()
env.execute()
}
class MyFlatMapFunction extends FlatMapFunction[String, String] {
override def flatMap(t: String, collector: Collector[String]): Unit = {
if (t.equals("white")) {
collector.collect(t)
} else if (t.equals("black")) {
collector.collect(t)
collector.collect(t)
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
下面的例子展示了在数据分析教程中经常用到的例子,我们用 flatMap 来实现。使用 flatmap 来实现 map 以及 filter 实现。
package com.atguigu.day2
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
/**
* @author Iekr
* Date: 2022/11/30/0030 16:12
*/
object FlatMapImplementMapAndFilter {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
//使用flatMap实现map功能 将传感器的id抽取出来
stream.flatMap(new FlatMapFunction[SensorReading, String] {
override def flatMap(t: SensorReading, collector: Collector[String]): Unit = {
collector.collect(t.id)
}
}).print()
//使用flatMap实现filter 将sensor_1的数据过来出来
stream.flatMap(new FlatMapFunction[SensorReading, SensorReading] {
override def flatMap(t: SensorReading, collector: Collector[SensorReading]): Unit = {
if (t.id.equals("sensor_1")) {
collector.collect(t)
}
}
}).print()
env.execute()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 键控流转换算子
很多流处理程序的一个基本要求就是要能对数据进行分组,分组后的数据共享某一个相同的属性。DataStream API 提供了一个叫做 KeyedStream 的抽象,此抽象会从逻辑上对 DataStream 进行分区,分区后的数据拥有同样的 Key 值,分区后的流互不相关。
针对 KeyedStream 的状态转换操作可以读取数据或者写入数据到当前事件 Key 所对应的状态中。这表明拥有同样 Key 的所有事件都可以访问同样的状态,也就是说所以这些事件可以一起处理。
要小心使用状态转换操作和基于 Key 的聚合操作。如果 Key 的值越来越多,例如:Key 是订单 ID,我们必须及时清空 Key 所对应的状态,以免引起内存方面的问题。稍后我们会详细讲解。
KeyedStream 可以使用 map,flatMap 和 filter 算子来处理。接下来我们会使用 keyBy 算子来将 DataStream 转换成 KeyedStream,并讲解基于 key 的转换操作:滚动聚合和 reduce 算子。
# KeyBy
keyBy 通过指定 key 来将 DataStream 转换成 KeyedStream。基于不同的 key,流中的事件将被分配到不同的分区中去。所有具有相同 key 的事件将会在接下来的操作符的同一个子任务槽中进行处理。拥有不同 key 的事件可以在同一个任务中处理。但是算子只能访问当前事件的 key 所对应的状态。
如下图所示,把输入事件的颜色作为 key,黑色的事件输出到了一个分区,其他颜色输出到了另一个分区。
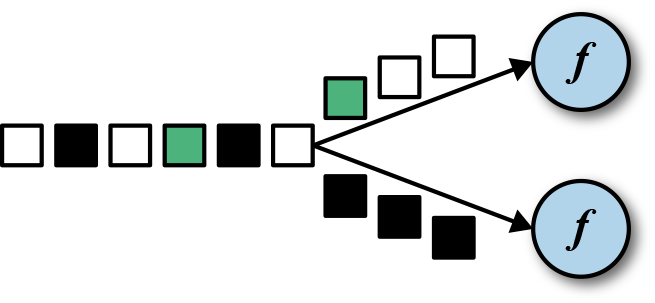
keyBy() 方法接收一个参数,这个参数指定了 key 或者 keys,有很多不同的方法来指定 key。我们将在后面讲解。下面的代码声明了 id 这个字段为 SensorReading 流的 key。
package com.atguigu.day2
import org.apache.flink.streaming.api.scala._
/**
* @author Iekr
* Date: 2022/11/30/0030 18:57
*/
object KeyedStreamExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
// 泛型变成两个,第二个泛型是key的类型
val keyed = stream.keyBy(_.id)
// 使用第三个字段来做滚动聚合,求流上每个传感器的最小温度
// 内部会保存一个最小值的状态 用来保存温度的最小值
// 滚动聚合以后,流的类型又变成了DataStream
val min: DataStream[SensorReading] = keyed.min(2)
min.print()
// reduce也会保存一个状态变量
val red: DataStream[SensorReading] = keyed.reduce((r1, r2) => SensorReading(r1.id, 0L, r1.temperature.min(r2.temperature)))
red.print()
env.execute()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 滚动聚合算子(Rolling Aggregation)
滚动聚合算子由 KeyedStream 调用,并生成一个聚合以后的 DataStream,例如:sum,minimum,maximum。一个滚动聚合算子会为每一个观察到的 key 保存一个聚合的值。针对每一个输入事件,算子将会更新保存的聚合结果,并发送一个带有更新后的值的事件到下游算子。滚动聚合不需要用户自定义函数,但需要接受一个参数,这个参数指定了在哪一个字段上面做聚合操作。DataStream API 提供了以下滚动聚合方法。
滚动聚合算子只能用在滚动窗口,不能用在滑动窗口。
- sum ():在输入流上对指定的字段做滚动相加操作。
- min ():在输入流上对指定的字段求最小值。
- max ():在输入流上对指定的字段求最大值。
- minBy ():在输入流上针对指定字段求最小值,并返回包含当前观察到的最小值的事件。
- maxBy ():在输入流上针对指定字段求最大值,并返回包含当前观察到的最大值的事件。
滚动聚合算子无法组合起来使用,每次计算只能使用一个单独的滚动聚合算子。
下面的例子根据第一个字段来对类型为 Tuple3<Int, Int, Int> 的流做分流操作,然后针对第二个字段做滚动求和操作。
val inputStream = env.fromElements((1, 2, 2), (2, 3, 1), (2, 2, 4), (1, 5, 3))
val resultStream = inputStream.keyBy(0).sum(1)
2
3
在这个例子里面,输入流根据第一个字段来分流,然后在第二个字段上做计算。对于 key 1,输出结果是 (1,2,2),(1,7,2)。对于 key 2,输出结果是 (2,3,1),(2,5,1)。第一个字段是 key,第二个字段是求和的数值,第三个字段未定义。
滚动聚合操作会对每一个 key 都保存一个状态。因为状态从来不会被清空,所以我们在使用滚动聚合算子时只能使用在含有有限个 key 的流上面。
# Reduce
reduce 算子是滚动聚合的泛化实现。它将一个 ReduceFunction 应用到了一个 KeyedStream 上面去。reduce 算子将会把每一个输入事件和当前已经 reduce 出来的值做聚合计算。reduce 操作不会改变流的事件类型。输出流数据类型和输入流数据类型是一样的。
reduce 函数可以通过实现接口 ReduceFunction 来创建一个类。ReduceFunction 接口定义了 reduce() 方法,此方法接收两个输入事件,输入一个相同类型的事件。
// T: the element type
ReduceFunction[T]
> reduce(T, T): T
2
3
下面的例子,流根据传感器 ID 分流,然后计算每个传感器的当前最大温度值。
val maxTempPerSensor = keyed.reduce((r1, r2) => r1.temperature.max(r2.temperature))
reduce 作为滚动聚合的泛化实现,同样也要针对每一个 key 保存状态。因为状态从来不会清空,所以我们需要将 reduce 算子应用在一个有限 key 的流上。
# 多流转换算子
许多应用需要摄入多个流并将流合并处理,还可能需要将一条流分割成多条流然后针对每一条流应用不同的业务逻辑。接下来,我们将讨论 DataStream API 中提供的能够处理多条输入流或者发送多条输出流的操作算子。
# Union
DataStream.union() 方法将两条或者多条 DataStream 合并成一条具有与输入流相同类型的输出 DataStream。接下来的转换算子将会处理输入流中的所有元素。下图展示了 union 操作符如何将黑色和白色的事件流合并成一个单一输出流。
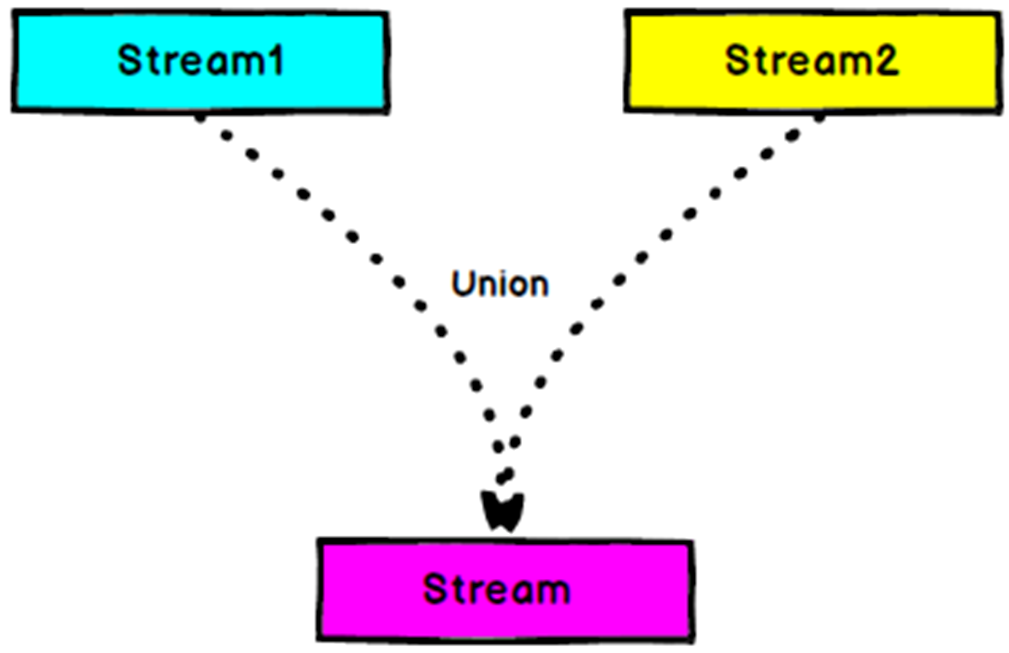
事件合流的方式为 FIFO 方式。操作符并不会产生一个特定顺序的事件流。union 操作符也不会进行去重。每一个输入事件都被发送到了下一个操作符。
下面的例子展示了如何将三条类型为 SensorReading 的数据流合并成一条流。
package com.atguigu.day2
import org.apache.flink.streaming.api.scala._
/**
* @author Iekr
* Date: 2022/11/30/0030 19:20
*/
object UnionExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val BJ = env.addSource(new SensorSource).filter(_.id.equals("sensor_1"))
val SH = env.addSource(new SensorSource).filter(_.id.equals("sensor_2"))
val SZ = env.addSource(new SensorSource).filter(_.id.equals("sensor_3"))
val union: DataStream[SensorReading] = BJ.union(SH, SZ)
union.print()
env.execute()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# Connect, CoMap 和 CoFlatMap
联合两条流的事件是非常常见的流处理需求。例如监控一片森林然后发出高危的火警警报。报警的 Application 接收两条流,一条是温度传感器传回来的数据,一条是烟雾传感器传回来的数据。当两条流都超过各自的阈值时,报警。
DataStream API 提供了 connect 操作来支持以上的应用场景。 DataStream.connect() 方法接收一条 DataStream ,然后返回一个 ConnectedStreams 类型的对象,这个对象表示了两条连接的流。
ConnectedStreams 提供了 map() 和 flatMap() 方法,分别需要接收类型为 CoMapFunction 和 CoFlatMapFunction 的参数。
以上两个函数里面的泛型是第一条流的事件类型和第二条流的事件类型,以及输出流的事件类型。还定义了两个方法,每一个方法针对一条流来调用。 map1() 和 flatMap1() 会调用在第一条流的元素上面, map2() 和 flatMap2() 会调用在第二条流的元素上面。
// IN1: 第一条流的事件类型
// IN2: 第二条流的事件类型
// OUT: 输出流的事件类型
CoMapFunction[IN1, IN2, OUT]
> map1(IN1): OUT
> map2(IN2): OUT
CoFlatMapFunction[IN1, IN2, OUT]
> flatMap1(IN1, Collector[OUT]): Unit
> flatMap2(IN2, Collector[OUT]): Unit
2
3
4
5
6
7
8
9
10
函数无法选择读某一条流。我们是无法控制函数中的两个方法的调用顺序的。当一条流中的元素到来时,将会调用相对应的方法。
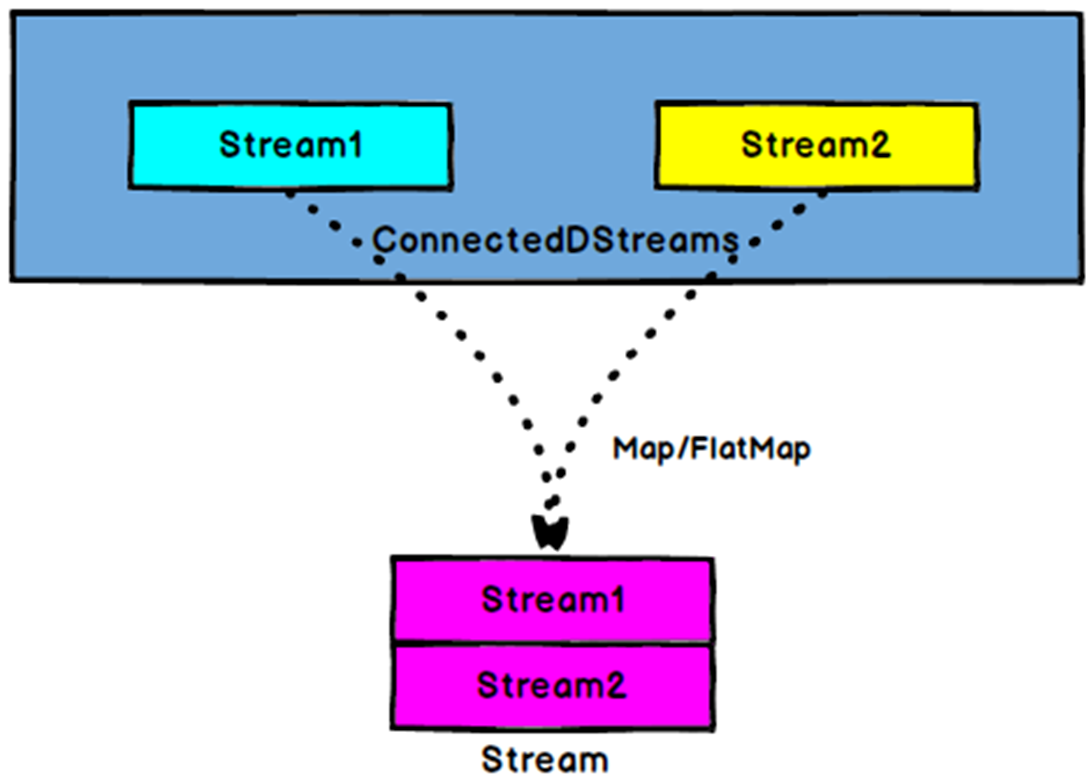
对两条流做连接查询通常需要这两条流基于某些条件被确定性的路由到操作符中相同的并行实例里面去。在默认情况下, connect() 操作将不会对两条流的事件建立任何关系,所以两条流的事件将会随机的被发送到下游的算子实例里面去。这样的行为会产生不确定性的计算结果,显然不是我们想要的。为了针对 ConnectedStreams 进行确定性的转换操作, connect() 方法可以和 keyBy() 或者 broadcast() 组合起来使用。我们首先看一下 keyBy() 的和 CoMap() 示例。
不要将两条流直接 connect 没有任何意义,像 join 表一样
package com.atguigu.day2
import org.apache.flink.streaming.api.functions.co.CoMapFunction
import org.apache.flink.streaming.api.scala._
/**
* @author Iekr
* Date: 2022/11/30/0030 19:35
*/
object CoMapExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream1: DataStream[(String, Int)] = env.fromElements(("zhangsan", 130), ("lisi", 150))
val stream2: DataStream[(String, Int)] = env.fromElements(("wangwu", 31), ("liuliu", 66))
//直接connect两条流没有任何意义
//必须要把相同key的流联合在一起处理,keyby后connect 和 connect后keyby都是可以
val connected: ConnectedStreams[(String, Int), (String, Int)] = stream1
.keyBy(_._1)
.connect(stream2.keyBy(_._1))
val printed: DataStream[String] = connected.map(new MyCoMapFunction)
printed.print()
env.execute()
}
class MyCoMapFunction extends CoMapFunction[(String, Int), (String, Int), String] {
// map1 处理来自第一条流的元素
override def map1(in1: (String, Int)) = {
in1._1 + "的体重是:" + in1._2 + "斤"
}
// map2 处理来自第二天流的元素
override def map2(in2: (String, Int)) = {
in2._1 + "的年龄是:" + in2._2 + "岁"
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
无论使用 keyBy() 算子操作 ConnectedStreams 还是使用 connect() 算子连接两条 KeyedStreams, connect() 算子会将两条流的含有相同 Key 的所有事件都发送到相同的算子实例。两条流的 key 必须是一样的类型和值,就像 SQL 中的 JOIN。在 connected 和 keyed stream 上面执行的算子有访问 keyed state 的权限。
下面是 CoFlatMap 例子
package com.atguigu.day2
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
/**
* @author Iekr
* Date: 2022/11/30/0030 19:51
*/
object CoFlatMapExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream1: DataStream[(String, Int)] = env.fromElements(("zhangsan", 130), ("lisi", 150))
val stream2: DataStream[(String, Int)] = env.fromElements(("wangwu", 31), ("liuliu", 66))
//直接connect两条流没有任何意义
//必须要把相同key的流联合在一起处理
val connected: ConnectedStreams[(String, Int), (String, Int)] = stream1
.keyBy(_._1)
.connect(stream2.keyBy(_._1))
val printed: DataStream[String] = connected.flatMap(new MyCoFlatMapFunction)
printed.print()
env.execute()
}
class MyCoFlatMapFunction extends CoFlatMapFunction[(String, Int), (String, Int), String] {
override def flatMap1(in1: (String, Int), collector: Collector[String]): Unit = {
collector.collect(in1._1 + "的体重是:" + in1._2 + "斤")
collector.collect(in1._1 + "的体重是:" + in1._2 + "斤")
}
override def flatMap2(in2: (String, Int), collector: Collector[String]): Unit = {
collector.collect(in2._1 + "的体重是:" + in2._2 + "斤")
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
下面的例子展示了如何连接一条 DataStream 和广播过的流。
监控一片森林然后发出高危的火警警报。报警的 Application 接收两条流,一条是温度传感器传回来的数据,一条是烟雾传感器传回来的数据。当两条流都超过各自的阈值时,报警。
object MultiStreamTransformations {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tempReadings = env.addSource(new SensorSource)
val smokeReadings = env
.addSource(new SmokeLevelSource)
.setParallelism(1)
val keyedTempReadings = tempReadings
.keyBy(r => r.id)
val alerts = keyedTempReadings
.connect(smokeReadings.broadcast())
.flatMap(new RaiseAlertFlatMap)
alerts.print()
env.execute("Multi-Stream Transformations Example")
}
class RaiseAlertFlatMap extends CoFlatMapFunction[SensorReading, SmokeLevel, Alert] {
private var smokeLevel = "LOW"
override def flatMap1(tempReading: SensorReading, out: Collector[Alert]) : Unit = {
if (smokeLevel == "HIGH" && tempReading.temperature > 100) {
out.collect(Alert("Risk of fire! " + tempReading, tempReading.timestamp))
}
}
override def flatMap2(sl: String, out: Collector[Alert]) : Unit = {
smokeLevel = sl
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
一条被广播过的流中的所有元素将会被复制然后发送到下游算子的所有并行实例中去。未被广播过的流仅仅向前发送。所以两条流的元素显然会被连接处理。
# Split 和 Select(1.10 已过时)
Split 是 Union 的反函数。Split 将输入的流分成两条或者多条流。每一个输入的元素都可以被路由到 0、1 或者多条流 中去。所以,split 可以用来过滤或者复制元素。下图展示了 split 操作符将所有的白色事件都路由到同一条流中去 了,剩下的元素去往另一条流。
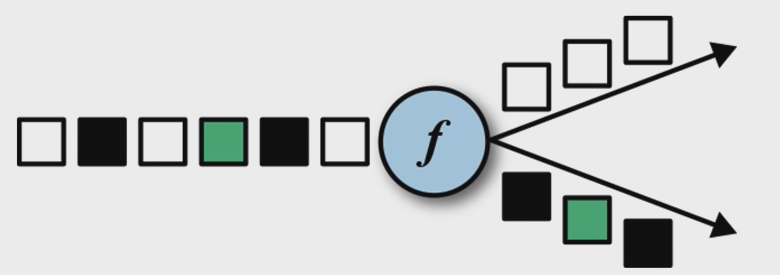
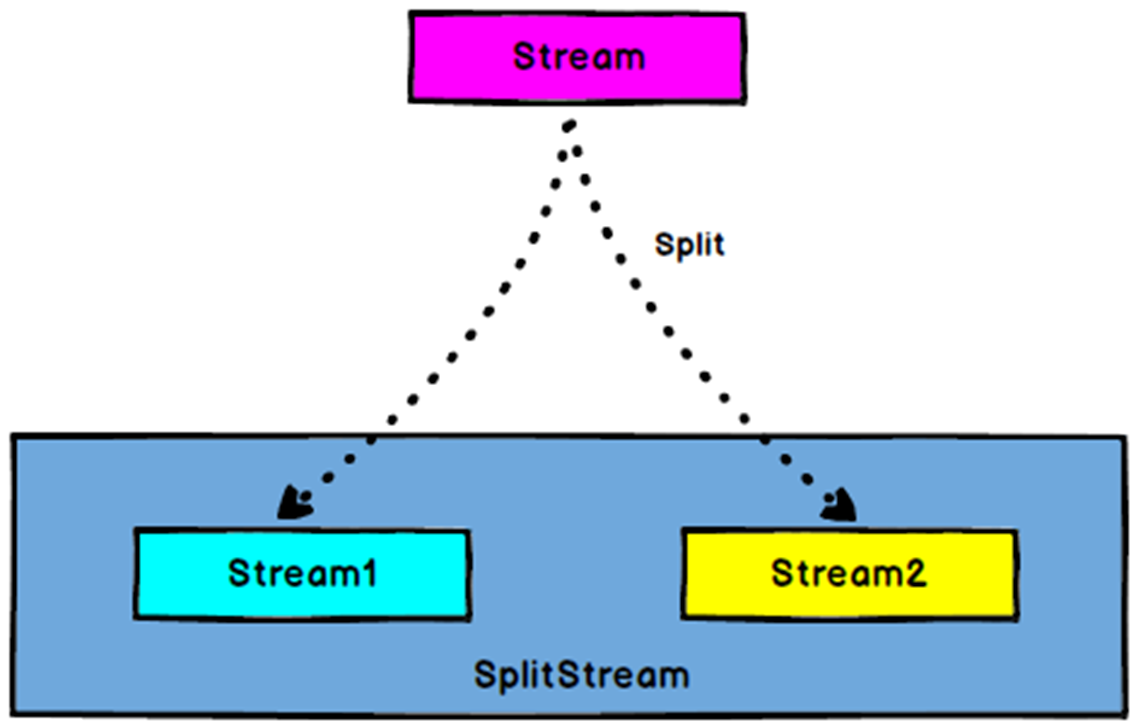
DataStream → SplitStream:根据某些特征把一个 DataStream 拆分成两个或者多个 DataStream。
DataStream.split() 方法接受 OutputSelector 类型,此类型定义了输入流中的元素被分配到哪个名字的流中去。OutputSelector 定义了 select() 方法,此方法将被每一个元素调用,并返回
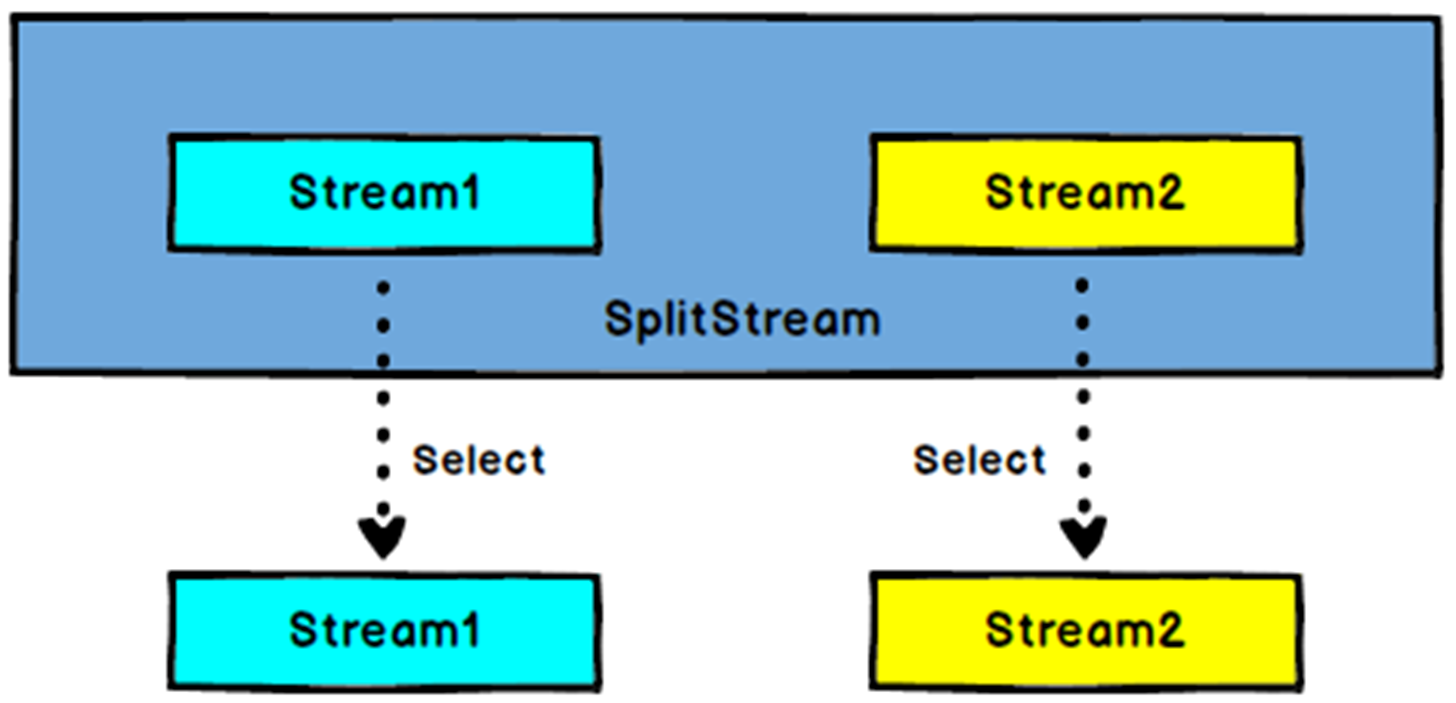
SplitStream→DataStream:从一个 SplitStream 中获取一个或者多个 DataStream。
DataStream.split() 方法返回 SplitStream 类型,此类型提供 select() 方法,可以根据分流后不同流的名字,将某个名字对应的流提取出来。
需求:传感器数据按照温度高低(以 30 度为界),拆分成两个流。
val splitStream = stream2
.split( sensorData => {
if (sensorData.temperature > 30) Seq("high") else Seq("low")
} )
val high = splitStream.select("high")
val low = splitStream.select("low")
val all = splitStream.select("high", "low")
2
3
4
5
6
7
8
不推荐使用 split 方法,推荐使用 Flink 的侧输出 (side-output) 特性。
# 分布式转换算子
分区操作对应于我们之前讲过的 “数据交换策略” 这一节。这些操作定义了事件如何分配到不同的任务中去。
当我们使用 DataStream API 来编写程序时,系统将自动的选择数据分区策略,然后根据操作符的语义和设置的并行度将数据路由到正确的地方去。有些时候,我们需要在应用程序的层面控制分区策略,或者自定义分区策略。
例如,如果我们知道会发生数据倾斜,那么我们想要针对数据流做负载均衡,将数据流平均发送到接下来的操作符中去。
又或者,应用程序的业务逻辑可能需要一个算子所有的并行任务都需要接收同样的数据。
再或者,我们需要自定义分区策略的时候。
在这一小节,我们将展示 DataStream 的一些方法,可以使我们来控制或者自定义数据分区策略。
keyBy () 方法不同于分布式转换算子。所有的分布式转换算子将产生 DataStream 数据类型。而 keyBy () 产生的类型是 KeyedStream,它拥有自己的 keyed state。
# Random
随机数据交换由 DataStream.shuffle() 方法实现。shuffle 方法将数据随机的分配到下游算子的并行任务中去。
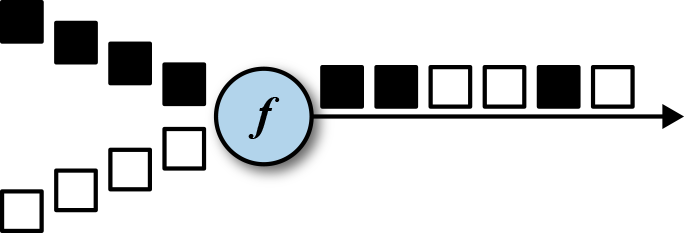
# Round-Robin
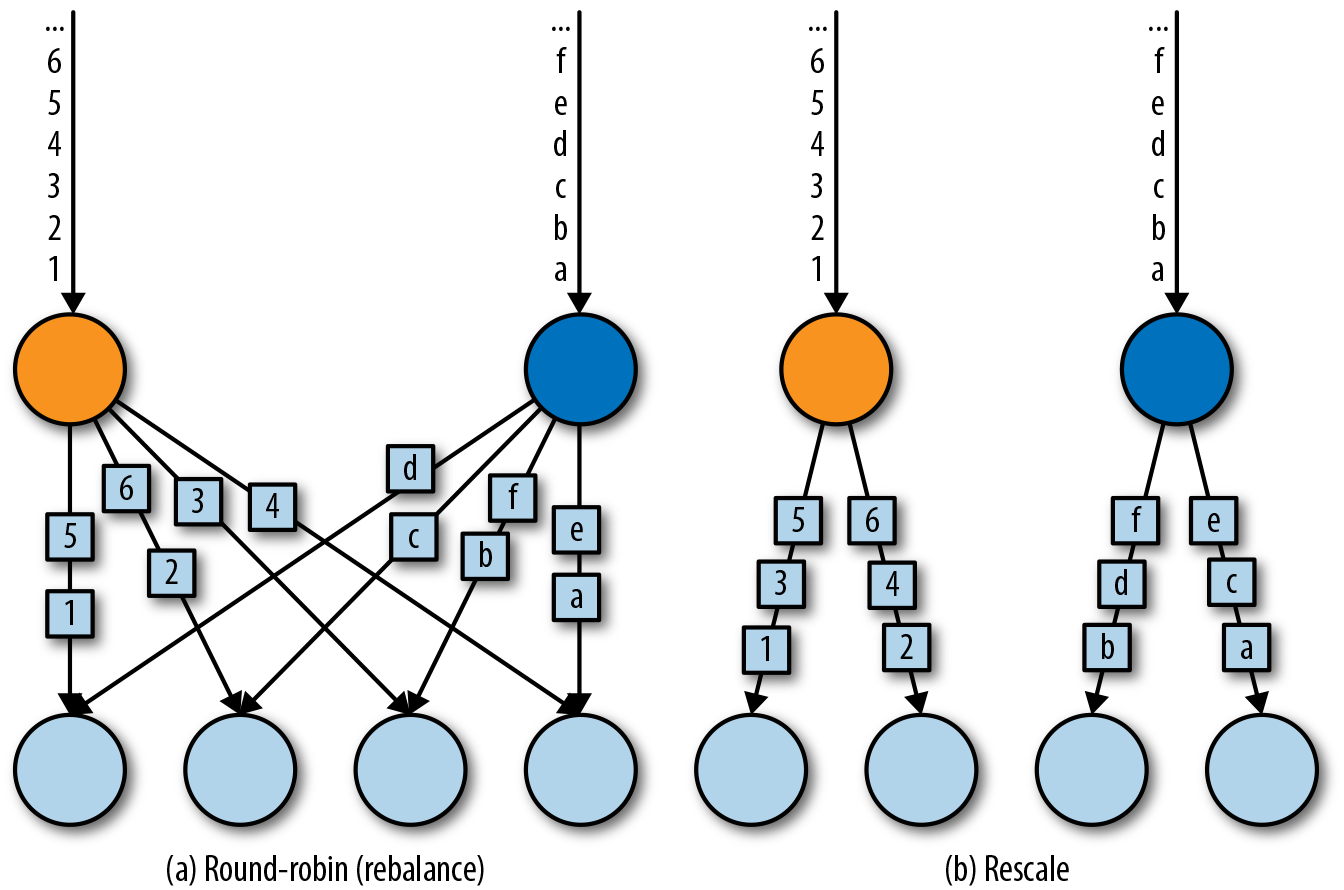
rebalance() 方法使用 Round-Robin 负载均衡算法将输入流平均分配到随后的并行运行的任务中去。下图 (a) 为 round-robin 分布式转换算子的示意图。
# Rescale
rescale() 方法使用的也是 round-robin 算法,但只会将数据发送到接下来的并行运行的任务中的一部分任务中。本质上,当发送者任务数量和接收者任务数量不一样时,rescale 分区策略提供了一种轻量级的负载均衡策略。如果接收者任务的数量是发送者任务的数量的倍数时,rescale 操作将会效率更高。
rebalance() 和 rescale() 的根本区别在于任务之间连接的机制不同。 rebalance() 将会针对所有发送者任务和所有接收者任务之间建立通信通道,而 rescale() 仅仅针对每一个任务和下游算子的一部分子并行任务之间建立通信通道。rescale 的下面示意图 (b)。
# Broadcast
broadcast() 方法将输入流的所有数据复制并发送到下游算子的所有并行任务中去。
# Global
global() 方法将所有的输入流数据都发送到下游算子的第一个并行任务中去。这个操作需要很谨慎,因为将所有数据发送到同一个 task,将会对应用程序造成很大的压力。
# Custom
当 Flink 提供的分区策略都不适用时,我们可以使用 partitionCustom() 方法来自定义分区策略。这个方法接收一个 Partitioner 对象,这个对象需要实现分区逻辑以及定义针对流的哪一个字段或者 key 来进行分区。
下面的例子将一条整数流做 partition,使得所有的负整数都发送到第一个任务中,剩下的数随机分配。
val numbers:DataStream[(Int)] = ...
numbers.partitionCustom(myPartitioner, 0)
object myPartitioner extends Partitioner[Int]{}
val r = scala.util.Random
override def partition(key: Int, numPartitions: Int): Int = {}
if (key < 0) 0 else r.nextInt(numPartitions)
}
}
2
3
4
5
6
7
8
9
# 设置并行度
Flink 应用程序在一个像集群这样的分布式环境中并行执行。当一个数据流程序提交到作业管理器执行时,系统将会创建一个数据流图,然后准备执行需要的操作符。每一个操作符将会并行化到一个或者多个任务中去。每个算子的并行任务都会处理这个算子的输入流中的一份子集。一个算子并行任务的个数叫做算子的并行度。它决定了算子执行的并行化程度,以及这个算子能处理多少数据量。
算子的并行度可以在执行环境这个层级来控制,也可以针对每个不同的算子设置不同的并行度。默认情况下,应用程序中所有算子的并行度都将设置为执行环境的并行度。执行环境的并行度(也就是所有算子的默认并行度)将在程序开始运行时自动初始化。如果应用程序在本地执行环境中运行,并行度将被设置为 CPU 的核数。当我们把应用程序提交到一个处于运行中的 Flink 集群时,执行环境的并行度将被设置为集群默认的并行度,除非我们在客户端提交应用程序时显式的设置好并行度。
通常情况下,将算子的并行度定义为和执行环境并行度相关的数值会是个好主意。这允许我们通过在客户端调整应用程序的并行度就可以将程序水平扩展了。我们可以使用以下代码来访问执行环境的默认并行度。
我们还可以重写执行环境的默认并行度,但这样的话我们将再也不能通过客户端来控制应用程序的并行度了。
算子默认的并行度也可以通过重写来明确指定。在下面的例子里面,数据源的操作符将会按照环境默认的并行度来并行执行,map 操作符的并行度将会是默认并行度的 2 倍,sink 操作符的并行度为 2。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment;
int defaultP = env.getParallelism;
env
.addSource(new CustomSource)
.map(new MyMapper)
.setParallelism(defaultP * 2)
.print()
.setParallelism(2);
2
3
4
5
6
7
8
当我们通过客户端将应用程序的并行度设置为 16 并提交执行时,source 操作符的并行度为 16,mapper 并行度为 32,sink 并行度为 2。
如果我们在本地环境运行应用程序的话,例如在 IDE 中运行,机器是 8 核,那么 source 任务将会并行执行在 8 个任务上面,mapper 运行在 16 个任务上面,sink 运行在 2 个任务上面。
并行度是动态概念,任务槽数量是静态概念。并行度 <= 任务槽数量。一个任务槽最多运行一个并行度。
# 类型
Flink 程序所处理的流中的事件一般是对象类型。操作符接收对象输出对象。所以 Flink 的内部机制需要能够处理事件的类型。在网络中传输数据,或者将数据写入到状态后端、检查点和保存点中,都需要我们对数据进行序列化和反序列化。为了高效的进行此类操作,Flink 需要流中事件类型的详细信息。Flink 使用了 Type Information 的概念来表达数据类型,这样就能针对不同的数据类型产生特定的序列化器,反序列化器和比较操作符。
类似于泛型
Flink 也能够通过分析输入数据和输出数据来自动获取数据的类型信息以及序列化器和反序列化器。尽管如此,在一些特定的情况下,例如匿名函数或者使用泛型的情况下,我们需要明确的提供数据的类型信息,来提高我们程序的性能。
在这一节中,我们将讨论 Flink 支持的类型,以及如何为数据类型创建相应的类型信息,还有就是在 Flink 无法推断函数返回类型的情况下,如何帮助 Flink 的类型系统去做类型推断。
# 支持的数据类型
Flink 支持 Java 和 Scala 提供的所有普通数据类型。最常用的数据类型可以做以下分类:
- Primitives(原始数据类型)
- Java 和 Scala 的 Tuples(元组)
- Scala 的样例类
- POJO 类型
- 一些特殊的类型
# Primitives(原始数据类型)
Java 和 Scala 提供的所有原始数据类型都支持,例如 Int (Java 的 Integer ),String,Double 等等。下面举一个例子:
DataStream[Long] numbers = env.fromElements(1L, 2L, 3L, 4L);
numbers.map(n -> n + 1);
2
# Tuples
元组是一种组合数据类型,由固定数量的元素组成。
Flink 为 Java 的 Tuple 提供了高效的实现。Flink 实现的 Java Tuple 最多可以有 25 个元素,根据元素数量的不同,Tuple 都被实现成了不同的类:Tuple1,Tuple2,一直到 Tuple25。Tuple 类是强类型。
DataStream<Tuple2<String, Integer>> persons = env
.fromElements(
Tuple2.of("Adam", 17),
Tuple2.of("Sarah", 23)
);
persons.filter(p -> p.f1 > 18);
2
3
4
5
6
7
Tuple 的元素可以通过它们的 public 属性访问 ——f0,f1,f2 等等。或者使用 getField(int pos) 方法来访问,元素下标从 0 开始:
import org.apache.flink.api.java.tuple.Tuple2
Tuple2<String, Integer> personTuple = Tuple2.of("Alex", 42);
Integer age = personTuple.getField(1); // age = 42
2
3
4
不同于 Scala 的 Tuple,Java 的 Tuple 是可变数据结构,而 Scala 的 Tuple 是不变数据结构,所以 Tuple 中的元素可以重新进行赋值。重复利用 Java 的 Tuple 可以减轻垃圾收集的压力。举个例子:
personTuple.f1 = 42; // set the 2nd field to 42
personTuple.setField(43, 1); // set the 2nd field to 43
2
# POJO
POJO 类的定义:
- 公有类
- 无参数的公有构造器
- 所有的字段都是公有的,可以通过 getters 和 setters 访问。
- 所有字段的数据类型都必须是 Flink 支持的数据类型。
举个例子:
public class Person {
public String name;
public int age;
public Person() {}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
DataStream<Person> persons = env.fromElements(
new Person("Alex", 42),
new Person("Wendy", 23)
);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
其他数据类型
- Array, ArrayList, HashMap, Enum
- Hadoop Writable types
- Either, Option, Try
# 为数据类型创建类型信息
Flink 类型系统的核心类是 TypeInformation 。它为系统在产生序列化器和比较操作符时,提供了必要的类型信息。例如,如果我们想使用某个 key 来做联结查询或者分组操作, TypeInformation 可以让 Flink 做更严格的类型检查。
Flink 针对 Java 和 Scala 分别提供了类来产生类型信息。在 Java 中,类是
org.apache.flink.api.common.typeinfo.Types
举个例子:
TypeInformation<Integer> intType = Types.INT;
TypeInformation<Tuple2<Long, String>> tupleType = Types
.TUPLE(Types.LONG, Types.STRING);
TypeInformation<Person> personType = Types
.POJO(Person.class);
2
3
4
5
6
7
在 Scala 中,类是 org.apache.flink.api.scala.typeutils.Types ,举个例子:
// TypeInformation for primitive types
val stringType:TypeInformation[String] = Types.STRING
// TypeInformation for Scala Tuples
val tupleType: TypeInformation[(Int,Long)] = Types.TUPLE[(Int,Long)]
// TypeInformation for case classes
val caseClassType: TypeInformation[Person] = Types.CASE_CLASS[Person]
2
3
4
5
6
别忘了导入隐式转换
import org.apache.flink.streaming.api.scala._
# 定义 Key 以及引用字段
在 Flink 中,我们必须明确指定输入流中的元素中的哪一个字段是 key。
# 使用字段位置进行 keyBy
val input: DataStream[(Int, String, Long)] = ...
val keyed = input.keyBy(1)
2
DataStream<Tuple3<Int, String, Long>> input = ...
KeyedStream<Tuple3<Int, String, Long>, String> keyed = input.keyBy(1);
2
// Make sure to add code blocks to your code group
注意,要么明确写清楚类型注释,要么让 Scala 去做类型推断,不要用 IDEA 的类型推断功能。
如果我们想要用元组的第 2 个字段和第 3 个字段做 keyBy,可以看下面的例子。
val keyed2 = input.keyBy(1,2)
input.keyBy(1, 2);
// Make sure to add code blocks to your code group
# 使用字段表达式来进行 keyBy
对于样例类:
case class SensorReading(
id: String,
timestamp: Long,
temperature: Double
)
val sensorStream:DataStream[SensorReading] = ...
val keyedSensors = sensorStream.keyBy("id")
2
3
4
5
6
7
DataStream<SensorReading> sensorStream = ...
sensorStream.keyBy("id");
2
// Make sure to add code blocks to your code group
对于元组:
case class Address(
address: String,
zip: String,
country: String
)
case class Person(
name: String,
birthday: (Int, Int, Int),// year, month, day
address: Address
)
val persons: DataStream[Person] = ...
persons.keyBy("address.zip") // key by nested POJO field
persons.keyBy("birthday._1") // key by field of nested tuple
persons.keyBy("birthday._") // key by all fields of nested tuple
2
3
4
5
6
7
8
9
10
11
12
13
14
DataStream<Tuple3<Integer, String, Long>> javaInput = ...
javaInput.keyBy("f2") // key Java tuple by 3rd field
2
// Make sure to add code blocks to your code group
# Key 选择器
方法类型
KeySelector[IN, KEY]
> getKey(IN): KEY
2
两个例子
val sensorData = ...
val byId = sensorData.keyBy(r => r.id)
val input = ...
input.keyBy(value => math.max(value._1, value._2))
2
3
4
5
DataStream<SensorReading> sensorData = ...
KeyedStream<SensorReading, String> byId = sensorData.keyBy(r -> r.id);
DataStream<Tuple2<Int, Int>> input = ...
input.keyBy(value -> Math.max(value.f0, value.f1));
2
3
4
5
// Make sure to add code blocks to your code group
# 实现 UDF 函数 —— 更细粒度的控制流
# 富函数 (Rich Functions)
我们经常会有这样的需求:在函数处理数据之前,需要做一些初始化的工作;或者需要在处理数据时可以获得函数执行上下文的一些信息;以及在处理完数据时做一些清理工作。而 DataStream API 就提供了这样的机制。
DataStream API 提供的所有转换操作函数,都拥有它们的 “富” 版本,并且我们在使用常规函数或者匿名函数的地方来使用富函数。例如下面就是富函数的一些例子,可以看出,只需要在常规函数的前面加上 Rich 前缀就是富函数了。
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
- ...
我们使用富函数时,我们可以实现两个额外的方法:
open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter 被调用之前open()会被调用。open () 函数通常用来做一些只需要做一次即可的初始化工作。close()方法是生命周期中的最后一个调用的方法,通常用来做一些清理工作。
另外, getRuntimeContext() 方法提供了函数的 RuntimeContext 的一些信息,例如函数执行的并行度,当前子任务的索引,当前子任务的名字。同时还它还包含了访问分区状态的方法。下面看一个例子:
class MyFlatMap extends RichFlatMapFunction[Int, (Int, Int)] {
var subTaskIndex = 0
override def open(configuration: Configuration): Unit = {
subTaskIndex = getRuntimeContext.getIndexOfThisSubtask
// 以下可以做一些初始化工作,例如建立一个和HDFS的连接
println("生命周期开始了")
}
override def flatMap(in: Int, out: Collector[(Int, Int)]): Unit = {
if (in % 2 == subTaskIndex) {
out.collect((subTaskIndex, in))
}
}
override def close(): Unit = {
// 以下做一些清理工作,例如断开和HDFS的连接。
println("生命周期结束了")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public static class MyFlatMap extends RichFlatMapFunction<Integer, Tuple2<Integer, Integer>> {
private int subTaskIndex = 0;
@Override
public void open(Configuration configuration) {
int subTaskIndex = getRuntimeContext.getIndexOfThisSubtask;
// 做一些初始化工作
// 例如建立一个和HDFS的连接
}
@Override
public void flatMap(Integer in, Collector<Tuple2<Integer, Integer>> out) {
if (in % 2 == subTaskIndex) {
out.collect((subTaskIndex, in));
}
}
@Override
public void close() {
// 清理工作,断开和HDFS的连接。
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// Make sure to add code blocks to your code group