 Flink
Flink
# Flink
# 时间语意
- 事件时间(Event Time),即事件实际发生的时间,生产时间;
- 注入时间(Ingestion Time),事件进入 Flink 流处理框架的时间;
- 处理时间(Processing Time),事件被处理的时间。
# 两阶段提交
请求阶段
1、协调者向所有参与者发送准备请求与事务内容,询问是否可以准备事务提交,并等待参与者的响应。
2、参与者执行事务中的包含操作,并记录 undo 日志(用于回滚)和 redo 日志(用于重放),但是不真正提交。
3、参与者向协调者返回事务才做的执行结果,执行成功返回 yes, 否则返回 no
提交阶段(分成成功和失败两种情况)
若所有的参与者都返回 yes, 说明事务可以提交。
1、协调者向所有参与者发送 commit 请求。
2、参与者收到 commit 请求后,将事务真正的提交上去,并释放占用的事务资源,并向协调者返回 ack。
3、协调者收到所有参与者 ack 消息,事务成功完成。
若有参与者返回 no 或者超时未返回,说明事务终端,需要回滚。
# 双流 join
基于时间的双流 join
- 基于间隔的 Join 会对两条流中拥有相同键值以及彼此之间时间戳不超过某一 指定间隔的事件进行 Join。
基于窗口做双流 join
顾名思义,基于窗口的 Join 需要用到 Flink 中的窗口机制。其原理是将两条 输入流中的元素分配到公共窗口中并在窗口完成时进行 Join (或 Cogroup)
- join/cogroup:实现 left/rightouterjoin 答案就是利用 coGroup () 算子。它的调用方式类似于 join () 算子, 也需要开窗,但是 CoGroupFunction 比 JoinFunction 更加灵活,可以按照用户指定的逻 辑匹配左流和 / 或右流的数据并输出。join () 和 coGroup () 都是基于窗口做关联的。但是在某些情况下,两条流的数据步调未必一致。例如,订单流的数据有可能在点击流的购买动作发生之后很久才被写入,如果用窗口来圈定,很容易 join 不上
- interval join:interval join 与 window join 不同,是两个 KeyedStream 之上的操作,并且需要调用 between () 方法指定偏移区间的上下界
3 流 join
- 可以双流 join 把数据落 redis,再次双流 join
# flink sql 执行原理
- 解析:将 sql 语句通过 calcite 解析成 AST (语法树)
- 校验:按照校验规则,检查 SQL 合法性,同时重写 AST
- 转换:将 sqlnode 转换为逻辑计划用 relnode 表示,再基于 flink 定制的一些 rules 去优化逻辑计划生成物理执行计划
- 执行:根据上一步生成算子并执行
# 水印
水印是一个标记的时间戳,是一个标记:意味着水印代表时间前的数据均已到达(人为的设定 —— 开发人员可以控制延迟和完整性之间的权衡),这一点水印保障了乱序问题的解决(这很重要,特别是多分区 kafka 消费)。因为在流处理中,面对乱序问题,你不可能一直等待数据的到达而不去对数据进行操作(尤其像是聚合操作这类操作)。故此面对超时到达的数据你必须进行处理,如何判断超时数据 —— 水印,你也可以设置一定的延迟时间
- 固定延迟生成水印也叫乱序(推荐):如名字所述,BoundedOutOfOrdernessTimestampExtractor 产生的时间 戳和水印是允许 “有界乱序” 的,构造它时传入的参数 maxOutOfOrderness 就是乱序区间的长度,而实际发射的水印为通过覆 写 extractTimestamp () 方法提取出来的时间戳减去乱序区间,相当于让水 印把步调 “放慢一点”。这是 Flink 为迟到数据提供的第一重保障。
- 周期性水印:顾名思义,使用 AssignerWithPeriodicWatermarks 时,水印是周期性产生的。 该周期默认为 200ms,也能通过 ExecutionConfig.setAutoWatermarkInterval () 方 法来指定新的周期。
- 打点水印:AssignerWithPeriodicWatermarks 周期性的生成 watermark,生成间隔可配置,根据数据的 eventTime 来更新 watermark 时间 AssignerWithPunctuatedWatermarks 不会周期性生成 watermark,只根据元素的 eventTime 来更新 watermark
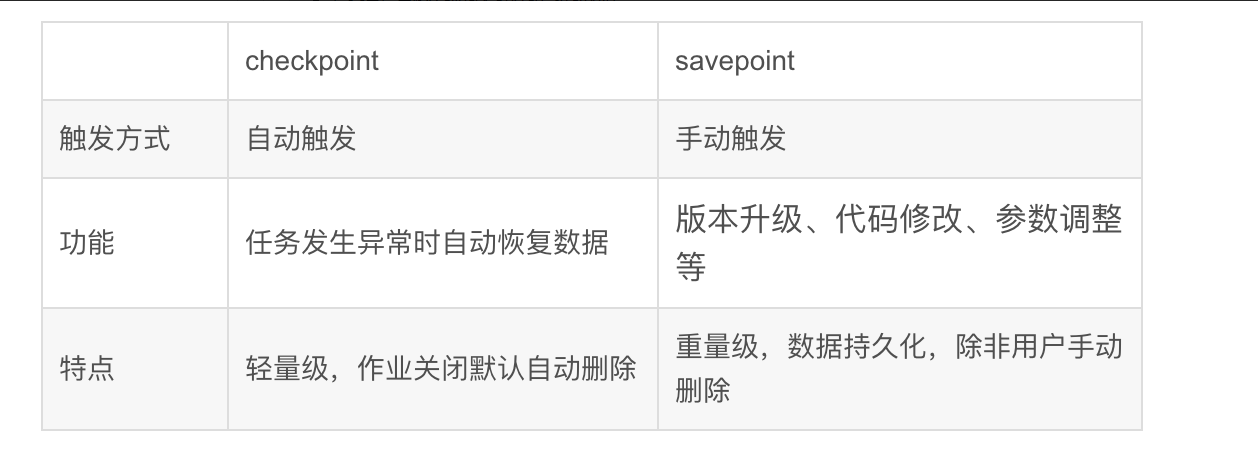
# savepoint\checkpoint 的区别
- checkpoint:checkpoint 是一种分布式快照,它在某个时刻,对一个 flink 任务的所有作业做一个快照,并将快照存储下来,这样在任务进行故障恢复的时候,就会从故障前最近一个检查点的状态恢复,从而保证数据的一致性。
- savepoint:savepoints 由用户创建,拥有和删除。他们的用例是 planned (计划) 的, manual backup ( 手动备份 ) 和 resume (恢复),savepoint 是基于检查点机制创建的作业执行状态的全局镜像,可用于 Flink 的重启、停止及升级等。它由两部分构成,一是在稳定存储中(如 hdfs、S3 等)保存了二进制文件的目录,二是元数据文件。这些文件表示了作业执行状态的镜像,其中元数据文件主要保存了以绝对路径表示的指针。
编辑 (opens new window)
上次更新: 2025/01/01, 10:09:39