 Kafka
Kafka
# Kafka
# kafka 怎么保证一致性可靠性?
tag:
快手count:8
as:Kafka 如何保证数据的可靠性
kafka 如何保证消息不会丢失
kafka 的可靠性怎么保证的
kafka 保证数据不丢失机制
Kafka 的消息投递保证机制?
kafka 生产者确认机制
消息持久化
- 磁盘存储:Kafka 将所有消息存储在磁盘上,而不是仅存储在内存中。这样即使 Broker 突然宕机,消息也不会丢失。
- 日志段(Log Segments):Kafka 将消息组织成多个日志段(Log Segments),每个日志段是一个单独的文件。这样做可以提高数据的可管理性和性能,并且便于日志文件的清理和维护。
ack 设置
- 0: 不等待节点同步成功就发送下一条消息,消息发送失败就会直接丢失
- 1: 等待 leader 副本同步成功才发送下一条消息,如果 leader 在备份数据到 follow 前宕机就会丢失数据
- -1 : 等待 kafka 认为 follow 同步成功才发送下一条消息,不可能丢失数据。
kafka 支持 3 种消息投递语义
- At most once—— 最多一次,消息可能会丢失,但不会重复
- At least once—— 最少一次,消息不会丢失,可能会重复
- Exactly once—— 只且一次,消息不丢失不重复,只且消费一次
kafka 自己写 api 管理的情况下,ack 失败,导致重复消费,你自己怎么设计解决
幂等或者每消费一条消息都记录 offset,对于少数严格的场景可能需要把 offset 或唯一 ID, 例如订单 ID 和 下游状态更新放在同一个数据库里面做事务来保证精确的一次更新或者在下游数据表里面同时记录消费 offset,然后更新下游数据的时候用消费位点做乐观锁拒绝掉旧位点的数据更新。
# kafka 主片挂了,副本片怎么选举一个最优的副本片??
tag:
快手count:3
as:kafka 集群里面如何保证一个坏了以后消息不会丢失
kafka 高可用
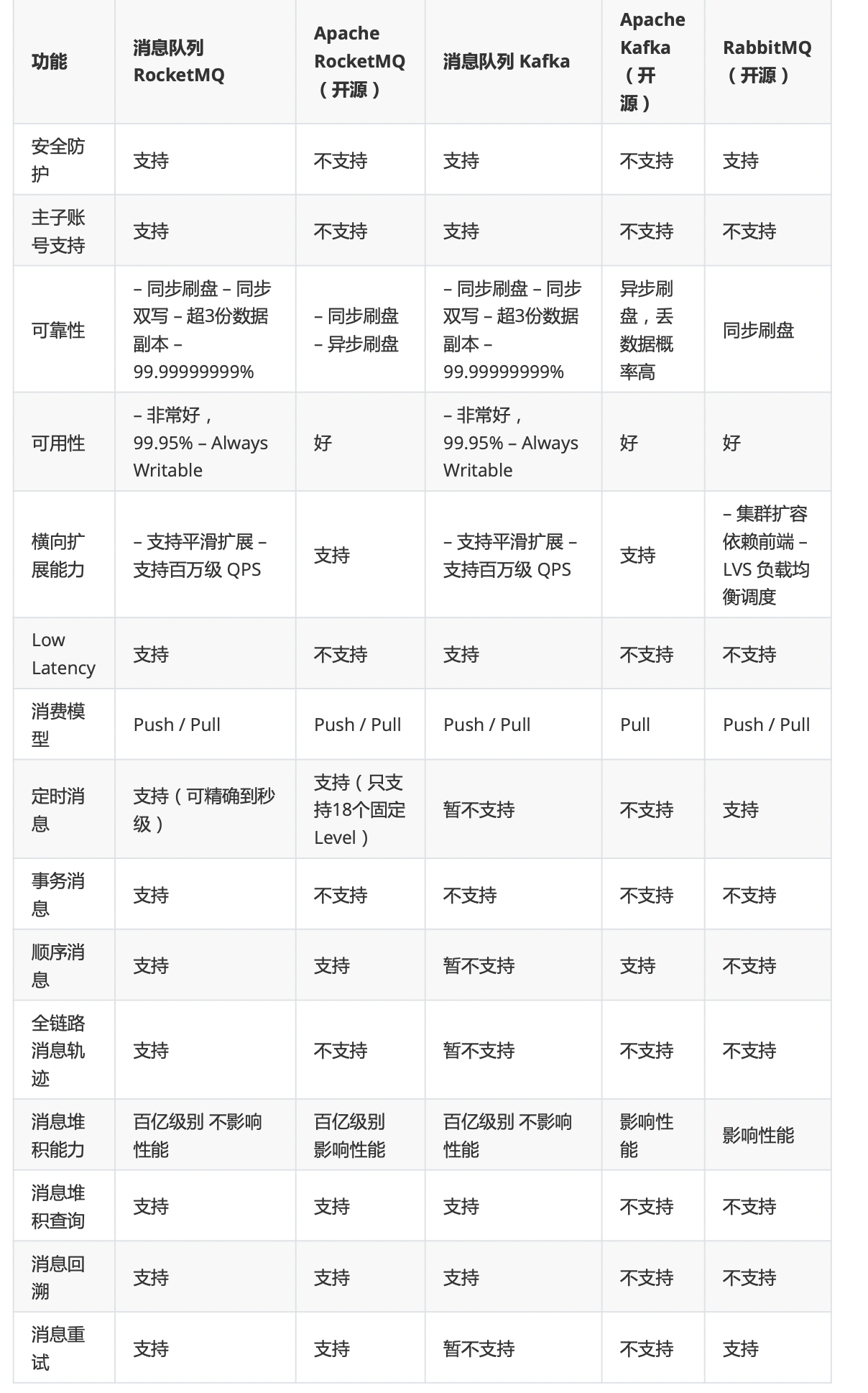
# rocketmq 和 kafka 的区别。
tag:
快手count:9
as:rabbitmq 和 Kafka 的区别
rabbitMQkafakrocketMQ 区别
为什么使用 kafka
- 数据可靠性:rocketmq 支持一步实时刷盘、同步刷盘、同步复制、异步复制,kafka 使用一步刷盘、异步复制、同步复制,rocketmq 不会因为操作系统 crash,导致数据丢失
- 分区:rocketmq 单分区完全顺序消费,kafka 多分区难保障
# Kafka 对于消息的通知 ,如何保证顺序性
tag:
美团、用友count:4
as:
Kafka 的主题(Topic)可以被划分为多个分区(Partition),每个分区内的消息是有序的。因此,如果你只需要保证某个主题内消息的顺序性,可以通过将主题设置为只有一个分区来实现这一目标。
为需要顺序性的消息设置相同的分区,通过 kafkaTemplate 在发送消息时进行设置。
为需要顺序性的消息设置相同的 key,通过 hash 函数计算到相同的位置,将信息散列到同一个分区中,通过 kafkaTemplate 在发送消息时进行设置。
# kafka 重复消费
tag:
count:4
as:kafka 重复消费了该怎么去重
kafka 重复消费问题,如何解决
kafka 的消息发送是否会有重复发送的问题(生产者)
消费者幂等性:消费者处理逻辑应该是幂等的,即多次执行同样的操作不会改变结果。这意味着即使同一条消息被多次消费,也应该得到相同的结果。这通常涉及到在业务逻辑中添加去重检查。
public class IdempotentConsumerExample { private Map<String, Boolean> processedMessages = new ConcurrentHashMap<>(); public void consumeMessage(String message) { if (!processedMessages.containsKey(message)) { // 处理消息 System.out.println("Processing message: " + message); // 更新已处理的消息列表 processedMessages.put(message, true); } else { System.out.println("Message already processed: " + message); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15消息唯一标识:为每条消息添加一个唯一的标识符(例如,UUID 或者基于业务逻辑生成的唯一键),并在消费时检查是否已处理过这条消息。
public class UniqueKeyConsumerExample { private Set<String> uniqueKeys = new HashSet<>(); public void consumeMessage(String uniqueKey, String message) { if (!uniqueKeys.contains(uniqueKey)) { // 处理消息 System.out.println("Processing message with unique key: " + uniqueKey); // 添加到已处理的唯一键集合 uniqueKeys.add(uniqueKey); } else { System.out.println("Message with unique key already processed: " + uniqueKey); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15事务:Kafka 0.11 版本引入了事务支持,允许生产者和消费者在事务上下文中操作消息。事务可以确保消息的完整性和一致性,防止重复消费。
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.TransactionState; import org.apache.kafka.common.errors.TransactionCoordinatorFencedException; import org.apache.kafka.common.errors.TransactionCoordinatorNotAvailableException; import org.apache.kafka.common.utils.Time; import java.util.Properties; public class TransactionalProducerExample { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("transactional.id", "my-producer-id"); props.put("enable.idempotence", "true"); KafkaProducer<String, String> producer = new KafkaProducer<>(props); producer.initTransactions(); try { producer.beginTransaction(); ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value"); producer.send(record); producer.commitTransaction(); } catch (TransactionCoordinatorFencedException | TransactionCoordinatorNotAvailableException e) { producer.abortTransaction(); } finally { producer.close(); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39消费者自动提交偏移量:默认情况下,Kafka 消费者会自动提交偏移量。如果消费者在处理消息期间出现故障,可能会导致消息重复消费。可以通过手动提交偏移量来避免这种情况。
import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.time.Duration; import java.util.Collections; import java.util.Properties; public class ManualOffsetCommitConsumerExample { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "my-consumer-group"); props.put("enable.auto.commit", "false"); // 关闭自动提交 props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Collections.singletonList("my-topic")); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); // 处理消息 try { // 模拟消息处理过程 Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 手动提交偏移量 consumer.commitSync(Collections.singletonMap(new TopicPartition(record.topic(), record.partition()), record.offset() + 1)); } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40检查点机制:在消费者处理完一批消息之后,可以记录一个检查点(Checkpoint),下次启动消费者时从检查点开始消费。这样可以避免在消费者重启后重新消费之前已经处理过的消息。
import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import java.time.Duration; import java.util.Collections; import java.util.Properties; public class CheckpointConsumerExample { private long checkpoint = 0L; // 记录检查点 public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "my-consumer-group"); props.put("enable.auto.commit", "false"); // 关闭自动提交 props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Collections.singletonList("my-topic")); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); // 处理消息 try { // 模拟消息处理过程 Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 更新检查点 checkpoint = record.offset() + 1; } // 手动提交偏移量 consumer.commitSync(Collections.singletonMap(new TopicPartition(record.topic(), record.partition()), checkpoint)); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# kafka 为什么这么快
tag:
count:19
as:kafka 为什么吞吐量那么高
Kafka 吞吐量,延迟级别
kafka 是基于磁盘存储,为什么高性能
kafka 的文件存储??或者说 kafka 为什么高吞吐低延时?
Kafka 零拷贝原理
batch 传输,压缩算法,零拷贝,磁盘顺序写入;索引文件(时间戳、偏移量),日志存在磁盘,基于 offset、索引啥的,然后又有删除策略,三种 ack 机制。
kafka 的组成部分
Kafka 的结构
kafka 的底层架构说一下
kafka 中 broker、分区、topic 的概念
kafka 介绍,什么是 Kafka broker、Topic、Partition、 Group
kafka 的基本结构
kafka 结构,消息时间顺序
Zk 在 kafka 里的作用?
介绍一下 Kafka 有哪些组成部分
kafka 的 topic 和 partition 机制
消息分区:消息不再局限于存储到单个服务器上。可以处理更多的数据。
顺序读写:磁盘采用顺序读写,速度更快。
页缓存:把磁盘数据先缓存到内存中,在读取数据时将磁盘读取变为内存读取,速度更快。
零拷贝:减少数据的拷贝,加快速度。原本的:系统资源 -> 页缓存 ->kafka->socket 缓存区 -> 网卡最终发送给消费者此时为四次拷贝,新的:系统资源 -> 页缓存 -> 网卡最终发送给消费者,新的拷贝比原来少两次。速度更快。
消息压缩:减少磁盘 io 和网络 io。
分批发送:将消息打包批量发送,减少网络开销。
# 零拷贝
传统拷贝过程
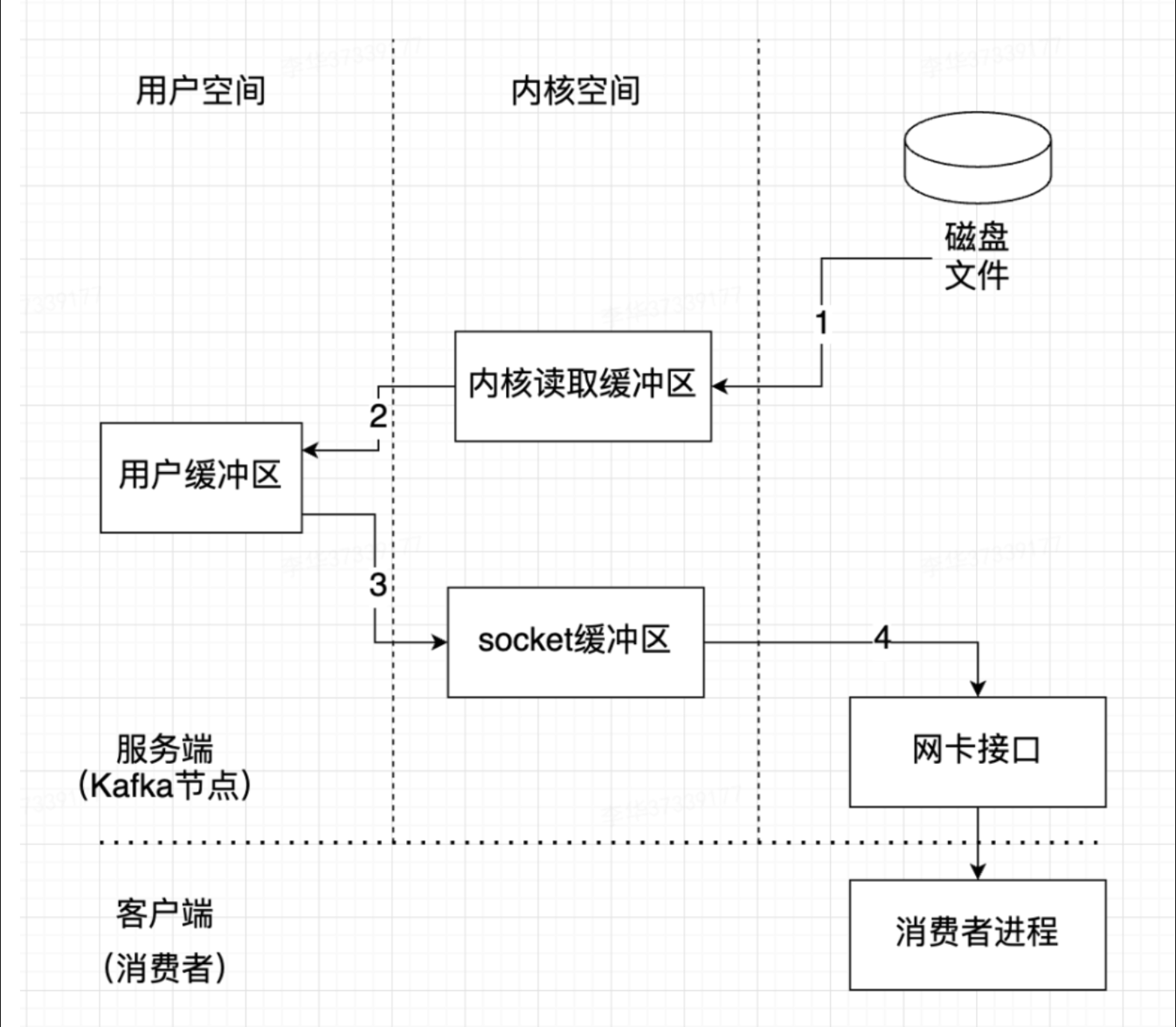
- 操作系统将数据从磁盘文件中读取到内核空间的页面缓存;
- 应用程序将数据从内核空间读入用户空间缓冲区;
- 应用程序将读到数据写回内核空间并放入 socket 缓冲区;
- 操作系统将数据从 socket 缓冲区复制到网卡接口,此时数据才能通过网络发送,这个过程涉及到 4 次上下文切换以及 4 次数据的复制,并且有两次复制操作是由 CPU 完成。但是这个过程中,数据完全没有进行变化,仅仅是从磁盘复制到网卡缓冲区
零拷贝减少用户空间与内核空间之间的切换,即去掉 2 和 3 流程,比传统性能高。这样子首先数据被从磁盘读取到 Read Buffer 中,然后再发送到 Socket Buffer,最后才发送到网卡。虽然减少了用户空间和内核空间之间的数据交换,但依然存在多次数据复制。
# 多分区
Kafka 可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要 如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡 和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力。
# kafka 消息堆积
tag:
count:2
as:如果消息堆积,怎么处理
Kafka 如何批量拉取消息
在 Kafka 消费者中,有几个重要的配置参数用于控制批量拉取的行为:
max.poll.records:每次调用poll()方法时最多可以拉取的消息数量,默认值为 500。你可以根据实际需求调整这个值,以适应不同的场景。fetch.max.bytes:每次从 Kafka Broker 拉取的最大字节数,默认值为 1MB(1048576 字节)。这个值决定了每次拉取的最大数据量,可以根据网络带宽和消息大小进行调整。max.partition.fetch.bytes:每次从 Kafka Broker 拉取的每分区的最大字节数,默认值为 1MB(1048576 字节)。这个值可以控制每个分区的最大拉取量,以避免过大的数据量导致内存溢出等问题。
解决方案有:
- 增加消费者数量:如果当前消费者数量不足,可以增加消费者数量来分散消息处理任务。这可以通过水平扩展消费者实例来实现。
- 异步处理:使用异步处理方式,提高消息处理速度。
- 批处理:批量处理消息,减少 I/O 操作次数,提高效率。
- 多线程处理:使用多线程来处理消息,充分利用 CPU 资源。
- 调整消费者配置,增加拉取消息数量。
- 死信队列处理:配置消息重试机制,将死信队列中的消息重发到正常的队列中进行处理。