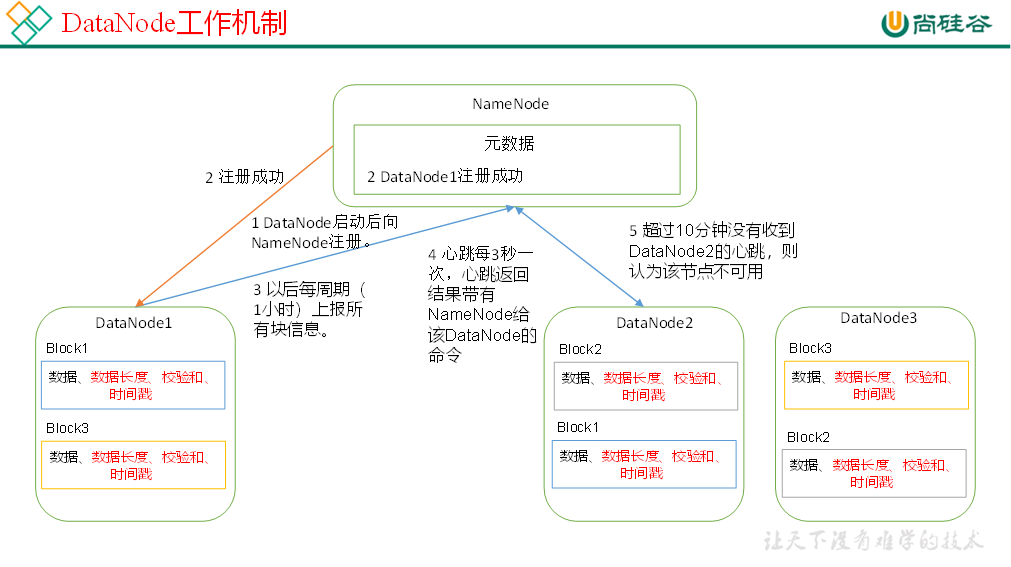
 DataNode
DataNode
# DataNode
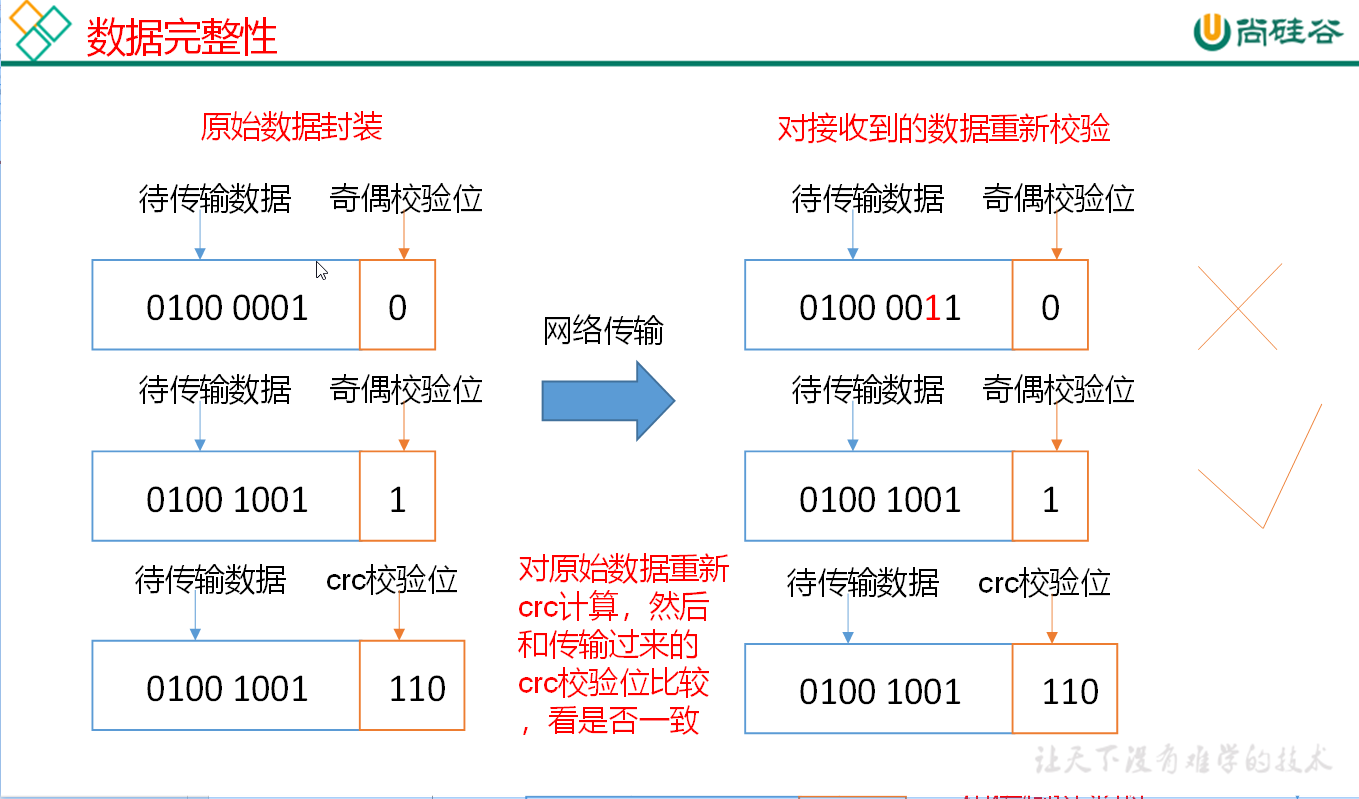
# 数据完整性
奇偶校验位 如果传输数据 1 为偶数个数则为 0 如果为奇数个 1 则为 1
如果原始数据与接收数据发生改变又恰好奇偶性一致 则这个现象我们称为校验碰撞
crc 校验位 32 位
md5 128 位
sha1 160 位
# 扩展集群
服役新数据节点
克隆 修改主机名 ip
#复制module文件夹 在其他集群中复制 和环境变量 sudo rsync -av /opt/module hadoop105:/opt sudo rsync -av /etc/profile.d hadoop105:/etc1
2
3#在扩展机中删除logs data 文件夹 cd /opt/module/hadoop-3.1.3/ rm -rf data logs source /etc/profile hadoop version1
2
3
4
5hdfs --daemon start datanode yarn --daemon start nodemanager jps1
2
3
此方式是手动启动 如果想要群启动则需要配置免密登陆
#在102中配置
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
1
2
2
追加上地址
hadoop105
1
同步所有集群
xsync /opt/module/hadoop-3.1.3/etc/hadoop/workers
1
# 添加黑 / 白名单
在 hadoop 文件夹下 新建 balcklist 和 whitelist
#主机上写 102
cd /opt/module/hadoop-3.1.3/etc/hadoop
touch balcklist
touch whitelist
1
2
3
4
2
3
4
添加白名单 一般 whitelist 内容和 workers 相同
vim whitelist
1
hadoop102
hadoop103
hadoop104
hadoop105
1
2
3
4
2
3
4
再编辑 hdfs-size.xml
vim hdfs-site.xml
1
添加以下内容
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/balcklist</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
重启集群
stop-dfs.sh
1
开启
start-dfs.sh
1
# 黑名单退役
编辑 balcklist 添加黑名单地址
vim balcklist
hdfs dfsadmin -refreshNodes #刷新节点
1
2
2
退役的机器 自动上传文件到服役中的其他主机中
关闭节点
hdfs --daemon stop datanode
1
# DateNode 多目录配置
DataNode 也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
vim hdfs-site.xml
1
多个目录之间逗号隔开
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
1
2
3
4
2
3
4
配置完成后重启
hdfs --daemon stop datanode
hdfs --daemon start datanode
1
2
2
编辑 (opens new window)
上次更新: 2023/12/06, 01:31:48