 哈希
哈希
# 哈希
# 哈希值
哈希值 (哈希码值): 是 JDK 根据对象的地址或者属性值,算出来的 int 类型的整数
object 类中有一个方法可以获取对象的哈希值:
Student s1 =new Student();
int hash = s1.hashCode();
System.out.println(hash);
1
2
3
2
3
我们可以通过重写 hashCode 方法,通过对象的属性值来生成 hashcode
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
// 如果对象的值全部一致则hashcode也一致
return result;
}
1
2
3
4
5
6
7
2
3
4
5
6
7
# 哈希表
JDK8 之前,底层采用 数组 + 链表 实现
JDK8 以后,底层进行优化。由 数组 + 链表 + 红黑树 实现.
# HashSet 集合
特点:
- 底层数据结构是哈希表
- 不能保证存储和取出顺序完全一致
- 没有索引,不能使用普通 for 循环遍历
# 原理
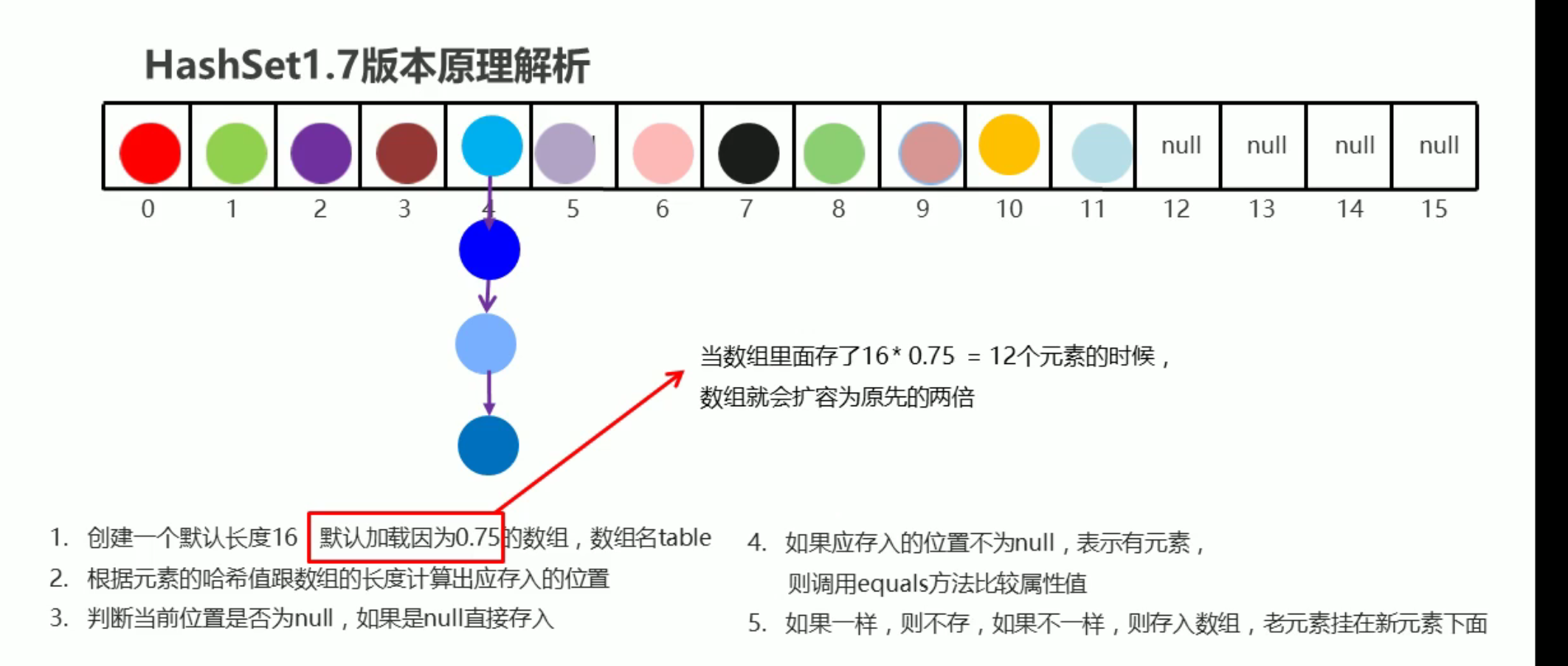
# 1.7 版本原理
底层为哈希表 用数组 + 链表实现
- 创建一个默认长度 16, 默认加载因 0.75 的数组,数组名为 table
- 加载因:当数组存了 16*0.75=12 个元素时,数组会扩容为原先的两倍
- 根据元素的哈希值跟数组的长度计算出应存入的位置
- 判断当前位置是否为 null, 如果是 null 直接存入
- 如果不为 null, 则代表已有元素,则调用 equals 方法比较属性值
- 如不一致,则存入数组,老元素挂在新元素下面 (链表)
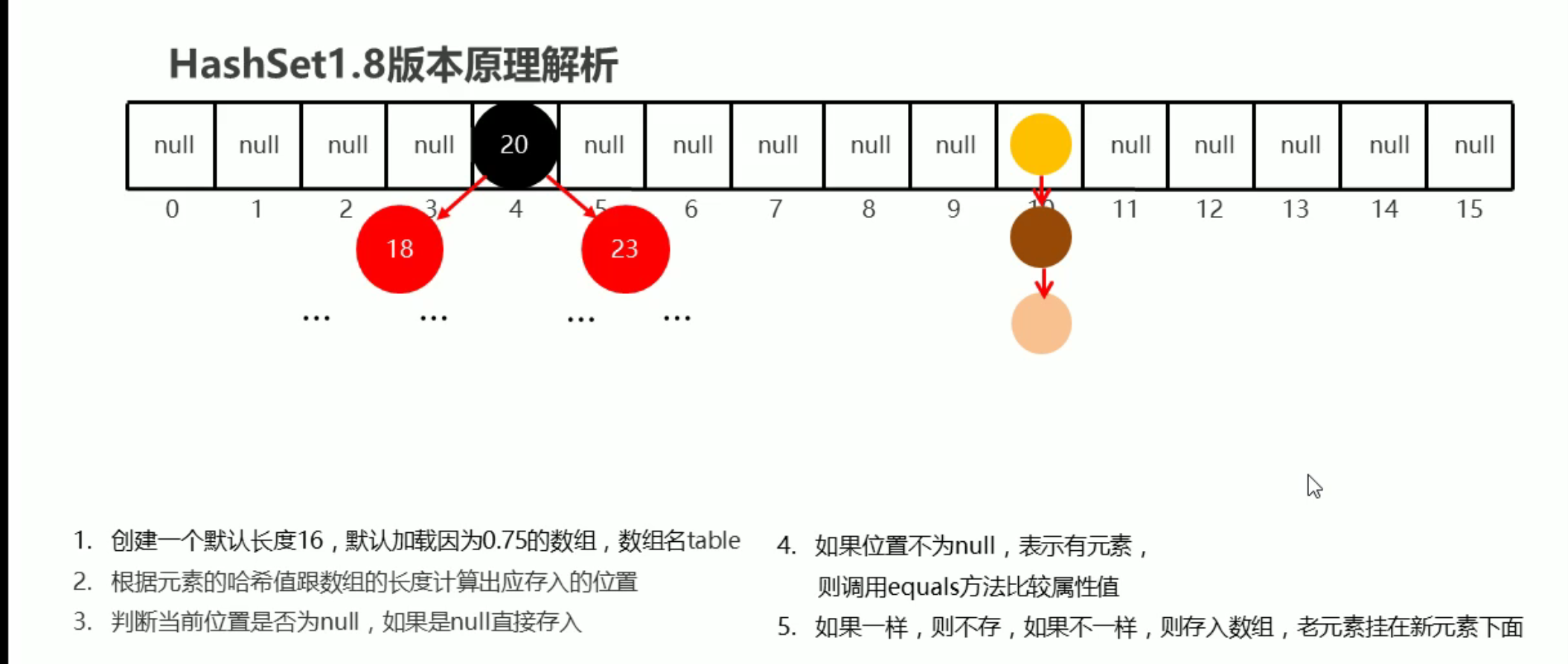
# 1.8 版本 原理
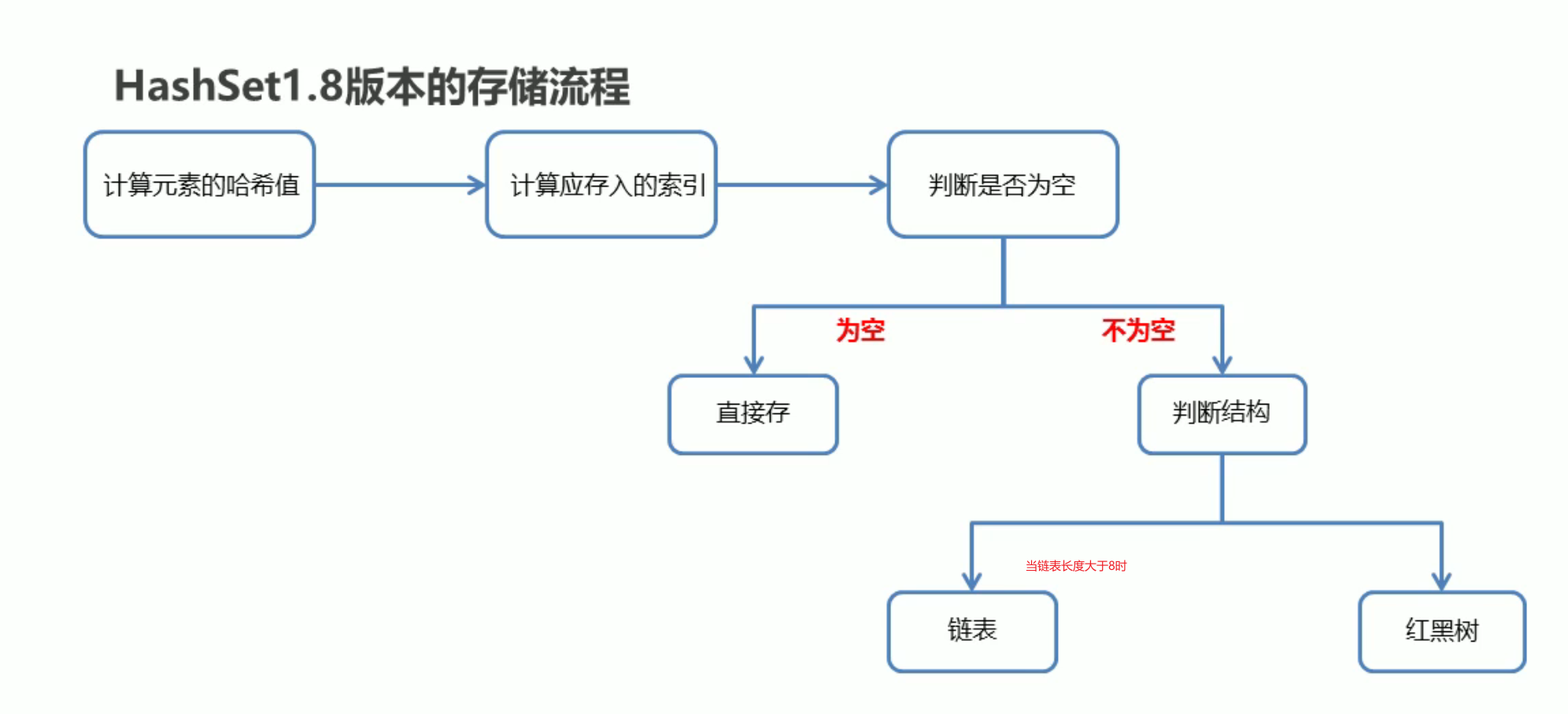
底层结构为:哈希表 底层为数组、链表和红黑树的结合体
1.8 版本优化了,当存放位置一致时,链表过长 需要对链表每个元素进行比较 当链表长度过长效率不太理想
所以在链表中添加红黑树来进行优化,当链表长度为 8 时,(> 8) 再添加会自动转成为红黑树
流程图
# Map 集合
Map 中 key value 为一对,必须存储为键值对
Map 中的 put 方法,如果此 key 已经有值,则会替换此 key 中值,并返回旧值
# 遍历 map
# keySet
通过 keySet () 获取所有 key
Set<String> strings = map.keySet();
for (String string : strings) {
System.out.println(map.get(string));
}
1
2
3
4
2
3
4
# entrySet
通过 entrySet 获取所有键值对
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getValue());
System.out.println(entry.getKey());
}
1
2
3
4
5
2
3
4
5
# forEach
map.forEach((String key, String value) -> {
System.out.println(key+" "+value);
});
1
2
3
2
3
# HashSet 原理
与 HashSet 一致
# TreeMap 原理
与 TreeSet 差不多
节点存储的为键值对,并且只对键进排序,值不影响
编辑 (opens new window)
上次更新: 2023/12/06, 01:31:48