 Spring Cloud
Spring Cloud
# Spring Cloud
# 为什么学分布式的东西?
tag:
腾讯count:11
as:springboot 和 springcloud 区别
SpringCloud 的整体架构
SpringCloudAlibab 的几大组件介绍一下
Springcloud 知道哪些组件
SpringCloud 解决的问题?
springCloud:
注册中心:Eureka。
远程调用:Feign。
负载均衡:Ribbon。
服务保护:Hystrix。
网关:Gateway。
springCloud alibaba:
注册中心:Nacos。
远程调用:Feign。
负载均衡:Ribbon。
服务保护:Sentinel。
网关:Gateway。
# CAP 和 BASE
CAP:
- 一致性(C):所有节点在同一时刻看到相同的数据。
- 可用性(A):每个请求不管成功或者失败,都需要返回响应。
- 分区容忍性(P):系统中任意信息的丢失或延迟都不会影响系统的继续运行。
分布式系统的节点都是通过网络连接的。所以一定会出现分区的问题(因为网络的问题)。因为分区的出现我们就不能同时满足可用性和一致性。
cp 为强一致性 (nacos 的非临时实例就是采用此模式),ap 为可用性 (eureka 和 nacos 的临时实例就是常用此模式)
BASE
- 基本可用(Basically Available):分布式出现故障的时候,允许损失部分的可用性,保证核心可用。
- 软状态(Soft state):允许出现中间状态。比如:临时不一致的情况。
- 最终一致性(Eventually consistent):在软状态结束后,保证最终的一致。
# Paxos、Raft、ZAB 各解决了什么,有什么缺点
tag:
腾讯count:1
as:
# Raft 和 ZAB 对比
# Raft 能当注册中心吗
# ZAB 集群当机部分节点后发生什么
# 能说下 HTTP 和 RPC 的区别吗?
严格来讲,HTTP 和 RPC 不是一个层面的东西
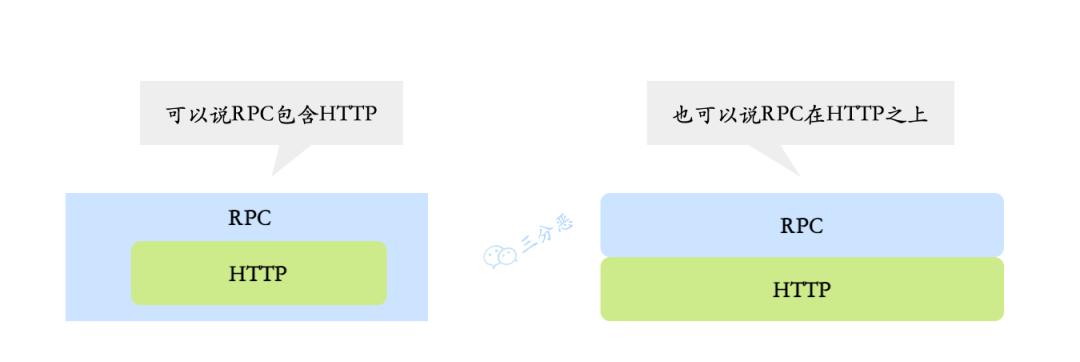
- HTTP(Hypertext Transfer Protocol):超文本传输协议是一种应用层协议,主要强调的是网络通信;
- RPC(Remote Procedure Call):远程过程调用是一种用于分布式系统之间通信的协议,强调的是服务之间的远程调用。
一些 RPC 框架比如 gRPC,底层传输协议其实也是用的 HTTP2,包括 Dubbo3,也兼容了 gRPC,使用了 HTTP2 作为传输层的一层协议
| HTTP | RPC | |
|---|---|---|
| 定义 | HTTP(超文本传输协议)是一种用于传输超文本的协议 | RPC(远程过程调用)是一种用于实现分布式系统中不同节点之间通信的协议 |
| 通信方式 | 基于请求 - 响应模型,客户端发送请求,服务器返回响应。 | 基于方法调用模型,客户端调用远程方法并等待结果。 |
| 传输协议 | 基于 TCP 协议,可使用其他传输层协议如 TLS/SSL 进行安全加密。 | 可以使用多种传输协议,如 TCP、UDP 等。 |
| 数据格式 | 基于文本,常用的数据格式有 JSON、XML 等。 | 可以使用各种数据格式,如二进制、JSON、Protocol Buffers 等。 |
| 接口定义 | 使用 RESTful 风格的接口进行定义,常用的方法有 GET、POST、PUT、DELETE 等。 | 使用 IDL(接口定义语言)进行接口定义,如 Protocol Buffers、Thrift 等。 |
| 跨语言性 | 支持跨语言通信,可以使用 HTTP 作为通信协议实现不同语言之间的通信。 | 支持跨语言通信,可以使用 IDL 生成不同语言的客户端和服务端代码。 |
| 灵活性 | 更加灵活,适用于不同类型的应用场景,如 Web 开发、API 调用等。 | 更加高效,适用于需要高性能和低延迟的分布式系统。 |
在微服务体系里,基于 HTTP 风格的远程调用通常使用框架如 Feign 来实现,基于 RPC 的远程调用通常使用框架如 Dubbo 来实现。
# 那 Feign 和 Dubbo 的区别呢?
| Feign | Dubbo | |
|---|---|---|
| 定义 | Feign 是一个声明式的 Web 服务客户端,用于简化 HTTP API 的调用。 | Dubbo 是一个分布式服务框架,用于构建面向服务的微服务架构。 |
| 通信方式 | 基于 HTTP 协议,使用 RESTful 风格的接口进行定义和调用。 | 基于 RPC 协议,支持多种序列化协议如 gRPC、Hessian 等。 |
| 服务发现 | 通常结合服务注册中心(如 Eureka、Consul)进行服务发现和负载均衡。 | 通过 ZooKeeper、Nacos 等进行服务注册和发现,并提供负载均衡功能。 |
| 服务治理 | 不直接提供服务治理功能,需要结合其他组件或框架进行服务治理。 | 提供服务注册与发现、负载均衡、容错机制、服务降级等服务治理功能。 |
| 跨语言性 | 支持跨语言通信,可以使用 HTTP 作为通信协议实现不同语言之间的通信。 | 支持跨语言通信,通过 Dubbo 的 IDL 生成不同语言的客户端和服务端代码。 |
| 生态系统 | 集成了 Spring Cloud 生态系统,与 Spring Boot 无缝集成。 | 拥有完整的生态系统,包括注册中心、配置中心、监控中心等组件。 |
| 适用场景 | 适用于构建 RESTful 风格的微服务架构,特别适合基于 HTTP 的微服务调用。 | 适用于构建面向服务的微服务架构,提供更全面的服务治理和容错机制。 |
需要注意的是,Feign 和 Dubbo 并不是互斥的关系。实际上,Dubbo 可以使用 HTTP 协议作为通信方式,而 Feign 也可以集成 RPC 协议进行远程调用。选择使用哪种远程调用方式取决于具体的业务需求和技术栈的选择。
# 说一下 Fegin?
Feign 是一个声明式的 Web 服务客户端,它简化了使用基于 HTTP 的远程服务的开发。
Feign 是在 RestTemplate 和 Ribbon 的基础上进一步封装,使用 RestTemplate 实现 Http 调用,使用 Ribbon 实现负载均衡。
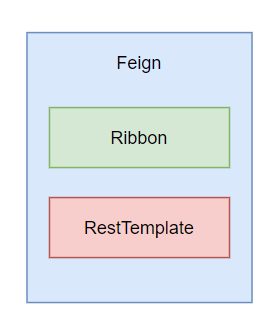
Feign 的主要特点和功能包括:
声明式 API:Feign 允许开发者使用简单的注解来定义和描述对远程服务的访问。通过使用注解,开发者可以轻松地指定 URL、HTTP 方法、请求参数、请求头等信息,使得远程调用变得非常直观和易于理解。
@FeignClient(name = "example", url = "https://api.example.com") public interface ExampleService { @GetMapping("/endpoint") String getEndpointData(); }1
2
3
4
5集成负载均衡:Feign 集成了 Ribbon 负载均衡器,可以自动实现客户端的负载均衡。它可以根据服务名和可用实例进行动态路由,并分发请求到不同的服务实例上,提高系统的可用性和可伸缩性。
容错机制:Feign 支持集成 Hystrix 容错框架,可以在调用远程服务时提供容错和断路器功能。当远程服务不可用或响应时间过长时,Feign 可以快速失败并返回预设的响应结果,避免对整个系统造成级联故障。
# Feign 怎么实现认证传递?
比较常见的一个做法是,使用拦截器传递认证信息。可以通过实现 RequestInterceptor 接口来定义拦截器,在拦截器里,把认证信息添加到请求头中,然后将其注册到 Feign 的配置中。
@Configuration
public class FeignClientConfig {
@Bean
public RequestInterceptor requestInterceptor() {
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate template) {
// 添加认证信息到请求头中
template.header("Authorization", "Bearer " + getToken());
}
};
}
private String getToken() {
// 获取认证信息的逻辑,可以从SecurityContext或其他地方获取
// 返回认证信息的字符串形式
return "your_token";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Fegin 怎么做负载均衡?Ribbon?
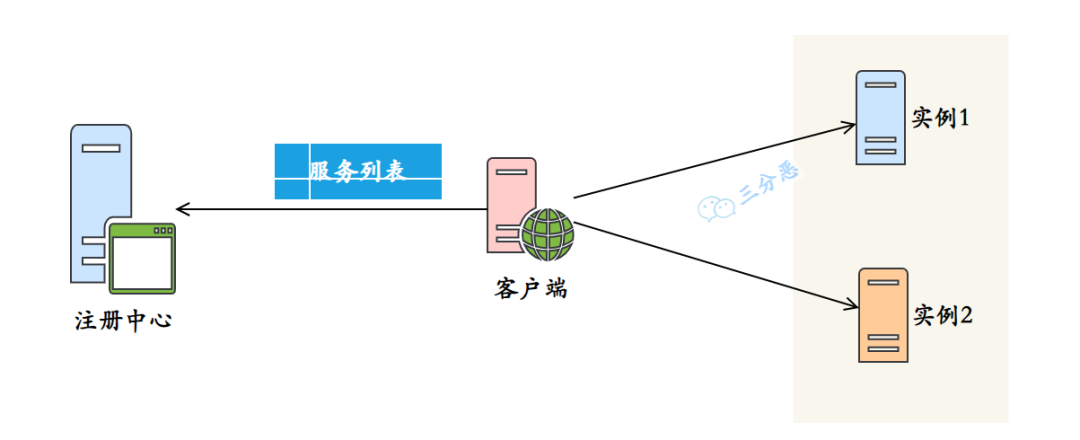
在 Feign 中,负载均衡是通过集成 Ribbon 来实现的。
Ribbon 是 Netflix 开源的一个客户端负载均衡器,可以与 Feign 无缝集成,为 Feign 提供负载均衡的能力。
Ribbon 通过从服务注册中心获取可用服务列表,并通过负载均衡算法选择合适的服务实例进行请求转发,实现客户端的负载均衡。
# 说说有哪些负载均衡算法?
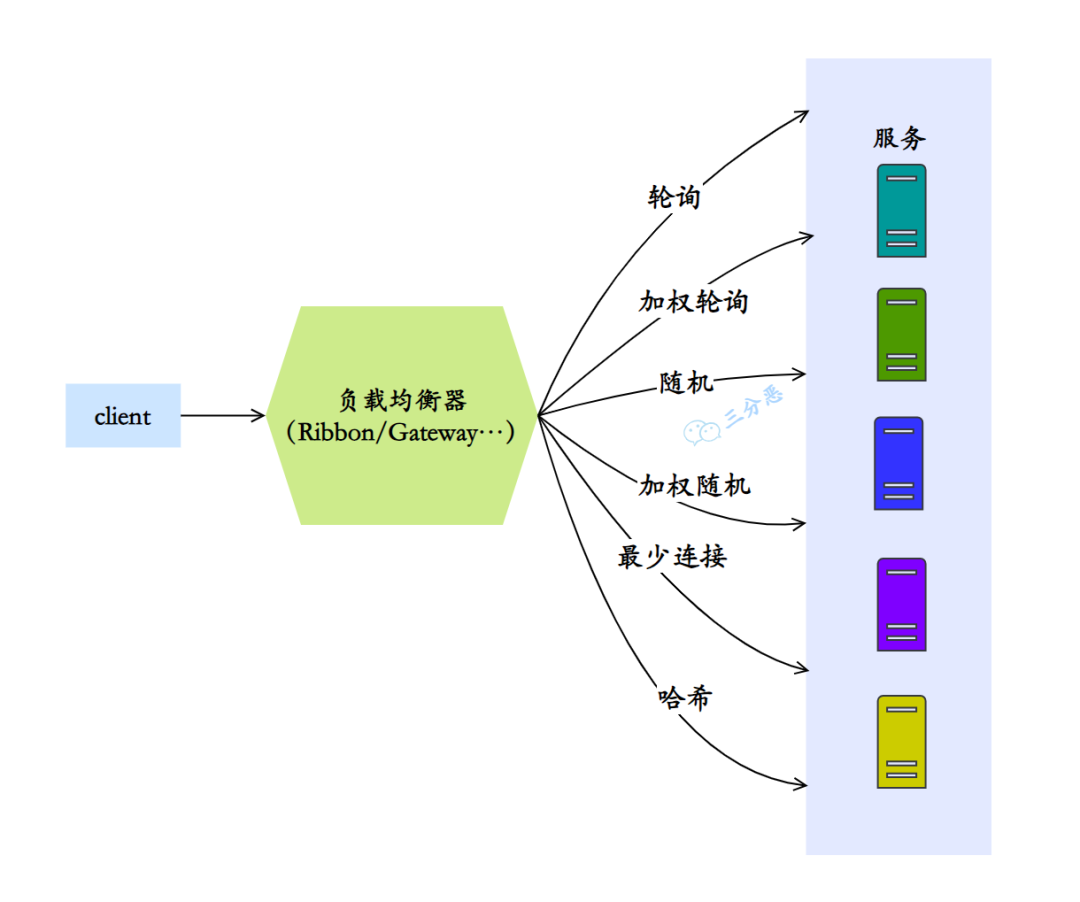
- 轮询算法(Round Robin):轮询算法是最简单的负载均衡算法之一。它按照顺序将请求依次分配给每个后端服务器,循环往复。当请求到达时,负载均衡器按照事先定义的顺序选择下一个服务器。轮询算法适用于后端服务器具有相同的处理能力和性能的场景。
- 加权轮询算法(Weighted Round Robin):加权轮询算法在轮询算法的基础上增加了权重的概念。每个后端服务器都被赋予一个权重值,权重值越高,被选中的概率就越大。这样可以根据服务器的处理能力和性能调整请求的分配比例,使得性能较高的服务器能够处理更多的请求。
- 随机算法(Random):随机算法将请求随机分配给后端服务器。每个后端服务器有相等的被选中概率,没有考虑服务器的实际负载情况。这种算法简单快速,适用于后端服务器性能相近且无需考虑请求处理能力的场景。
- 加权随机算法(Weighted Random):加权随机算法在随机算法的基础上引入了权重的概念。每个后端服务器被赋予一个权重值,权重值越高,被选中的概率就越大。这样可以根据服务器的处理能力和性能调整请求的分配比例。
- 最少连接算法(Least Connection):最少连接算法会根据后端服务器当前的连接数来决定请求的分配。负载均衡器会选择当前连接数最少的服务器进行请求分配,以保证后端服务器的负载均衡。这种算法适用于后端服务器的处理能力不同或者请求的处理时间不同的场景。
- 哈希算法(Hash):哈希算法会根据请求的某个特定属性(如客户端 IP 地址、请求 URL 等)计算哈希值,然后根据哈希值选择相应的后端服务器。
常见的负载均衡器,比如 Ribbion、Gateway 等等,基本都支持这些负载均衡算法。
# 什么是服务雪崩?
在微服务中,假如一个或者多个服务出现故障,如果这时候,依赖的服务还在不断发起请求,或者重试,那么这些请求的压力会不断在下游堆积,导致下游服务的负载急剧增加。不断累计之下,可能会导致故障的进一步加剧,可能会导致级联式的失败,甚至导致整个系统崩溃,这就叫服务雪崩。
一般,为了防止服务雪崩,可以采用这些措施:
- 服务高可用部署:确保各个服务都具备高可用性,通过冗余部署、故障转移等方式来减少单点故障的影响。
- 限流和熔断:对服务之间的请求进行限流和熔断,以防止过多的请求涌入导致后端服务不可用。
- 缓存和降级:合理使用缓存来减轻后端服务的负载压力,并在必要时进行服务降级,保证核心功能的可用性。
# 什么是服务熔断?
服务熔断是微服务架构中的容错机制,用于保护系统免受服务故障或异常的影响。当某个服务出现故障或异常时,服务熔断可以快速隔离该服务,确保系统稳定可用。
它通过监控服务的调用情况,当错误率或响应时间超过阈值时,触发熔断机制,后续请求将返回默认值或错误信息,避免资源浪费和系统崩溃。
服务熔断还支持自动恢复,重新尝试对故障服务的请求,确保服务恢复正常后继续使用。
# 什么是服务降级?
服务降级是也是一种微服务架构中的容错机制,用于在系统资源紧张或服务故障时保证核心功能的可用性。
当系统出现异常情况时,服务降级会主动屏蔽一些非核心或可选的功能,而只提供最基本的功能,以确保系统的稳定运行。通过减少对资源的依赖,服务降级可以保证系统的可用性和性能。
它可以根据业务需求和系统状况来制定策略,例如替换耗时操作、返回默认响应、返回静态错误页面等。
目前常见的服务熔断降级实现方案有这么几种:
| 框架 | 实现方案 | 特点 |
|---|---|---|
| Spring Cloud | Netflix Hystrix | - 提供线程隔离、服务降级、请求缓存、请求合并等功能 - 可与 Spring Cloud 其他组件无缝集成 - 官方已宣布停止维护,推荐使用 Resilience4j 代替 |
| Spring Cloud | Resilience4j | - 轻量级服务熔断库 - 提供类似于 Hystrix 的功能 - 具有更好的性能和更简洁的 API - 可与 Spring Cloud 其他组件无缝集成 |
| Spring Cloud Alibaba | Sentinel | - 阿里巴巴开源的流量控制和熔断降级组件 - 提供实时监控、流量控制、熔断降级等功能 - 与 Spring Cloud Alibaba 生态系统紧密集成 |
| Dubbo | Dubbo 自带熔断降级机制 | - Dubbo 框架本身提供的熔断降级机制 - 可通过配置实现服务熔断和降级 - 与 Dubbo 的 RPC 框架紧密集成 |
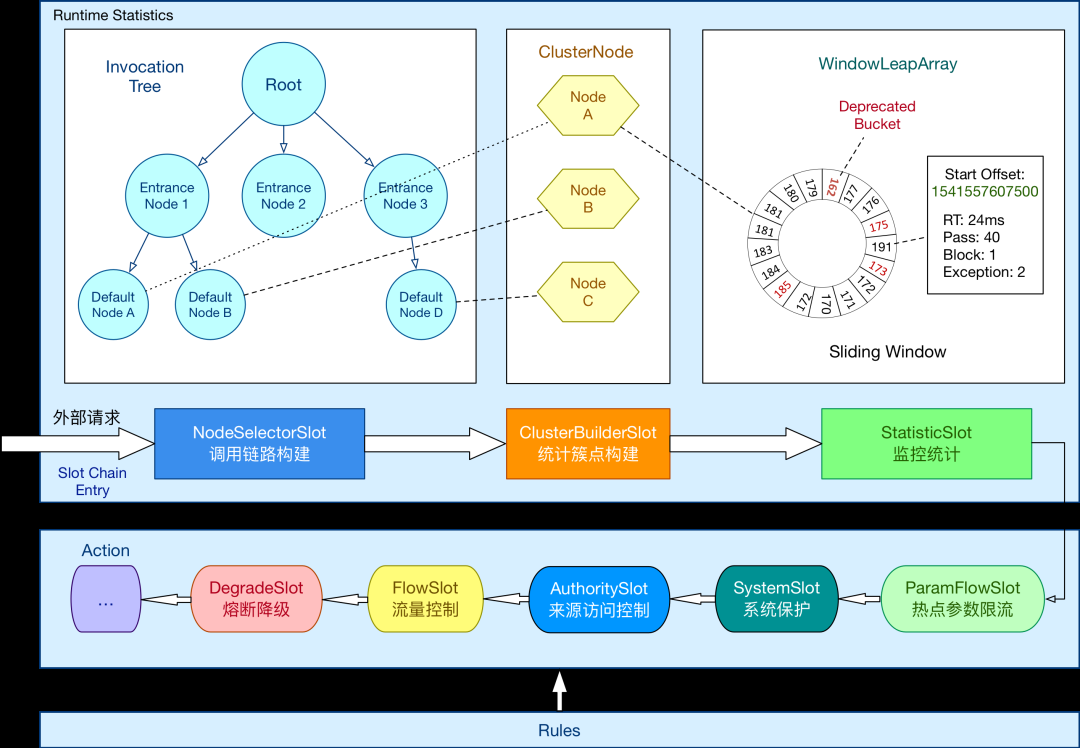
# Sentinel 怎么实现限流的?
# 定义资源
定义资源:在 Sentinel 中,资源可以是 URL、方法等,用于标识需要进行限流的请求。
// 原本的业务方法.
@SentinelResource(blockHandler = "blockHandlerForGetUser")
public User getUserById(String id) {
throw new RuntimeException("getUserById command failed");
}
// blockHandler 函数,原方法调用被限流/降级/系统保护的时候调用
public User blockHandlerForGetUser(String id, BlockException ex) {
return new User("admin");
}
2
3
4
5
6
7
8
9
10
# 配置限流规则
配置限流规则:在 Sentinel 的配置文件中定义资源的限流规则。规则可以包括资源名称、限流阈值、限流模式(令牌桶或漏桶)等。
private static void initFlowQpsRule() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule1 = new FlowRule();
rule1.setResource(resource);
// Set max qps to 20
rule1.setCount(20);
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule1.setLimitApp("default");
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}
2
3
4
5
6
7
8
9
10
11
# 监控流量
监控流量:Sentinel 会监控每个资源的流量情况,包括请求的 QPS(每秒请求数)、线程数、响应时间等。
# 限流控制
限流控制:当请求到达时,Sentinel 会根据资源的限流规则判断是否需要进行限流控制。如果请求超过了限流阈值,则可以进行限制、拒绝或进行其他降级处理。
# 有什么限流算法?
tag:
百度count:1
as:限流的例子
# 固定窗口计数器算法
固定窗口其实就是时间窗口,其原理是将时间划分为固定大小的窗口,在每个窗口内限制请求的数量或速率,即固定窗口计数器算法规定了系统单位时间处理的请求数量。
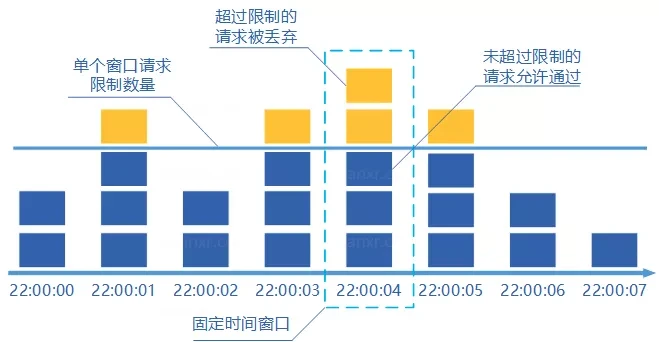
优点:实现简单,易于理解。
缺点:
- 限流不够平滑。例如,我们限制某个接口每分钟只能访问 30 次,假设前 30 秒就有 30 个请求到达的话,那后续 30 秒将无法处理请求,这是不可取的,用户体验极差!
- 无法保证限流速率,因而无法应对突然激增的流量。例如,我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
# 滑动窗口计数器算法
滑动窗口计数器算法 算的上是固定窗口计数器算法的升级版,限流的颗粒度更小。
滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:它把时间以一定比例分片 。
滑动窗口限流算法是一种基于时间窗口的限流算法。它将一段时间划分为多个时间窗口,并在每个时间窗口内统计请求的数量。通过动态地调整时间窗口的大小和滑动步长,可以更精确地控制请求的通过速率。
当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
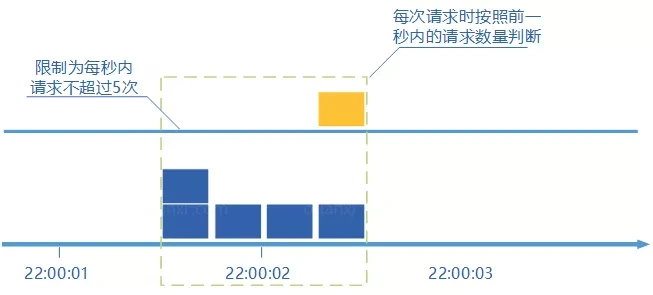
优点:
- 相比于固定窗口算法,滑动窗口计数器算法可以应对突然激增的流量。
- 相比于固定窗口算法,滑动窗口计数器算法的颗粒度更小,可以提供更精确的限流控制。
缺点:
- 与固定窗口计数器算法类似,滑动窗口计数器算法依然存在限流不够平滑的问题。
- 相比较于固定窗口计数器算法,滑动窗口计数器算法实现和理解起来更复杂一些。
Sentinel 使用滑动窗口限流算法来实现限流。
# 漏桶算法
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰 / 限流的思想是一样的)。
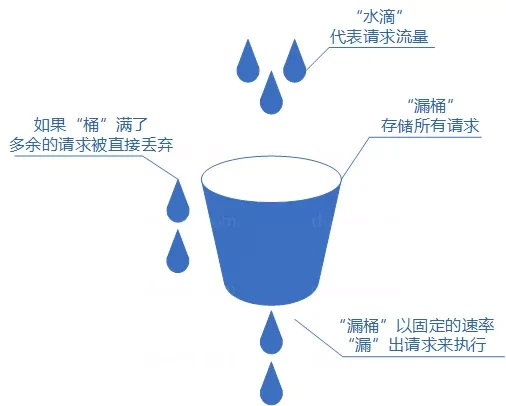
优点:
- 实现简单,易于理解。
- 可以控制限流速率,避免网络拥塞和系统过载。
缺点:
- 无法应对突然激增的流量,因为只能以固定的速率处理请求,对系统资源利用不够友好。
- 桶流入水(发请求)的速率如果一直大于桶流出水(处理请求)的速率的话,那么桶会一直是满的,一部分新的请求会被丢弃,导致服务质量下降。
实际业务场景中,基本不会使用漏桶算法。
# 令牌桶算法
令牌桶算法也比较简单。和漏桶算法算法一样,不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
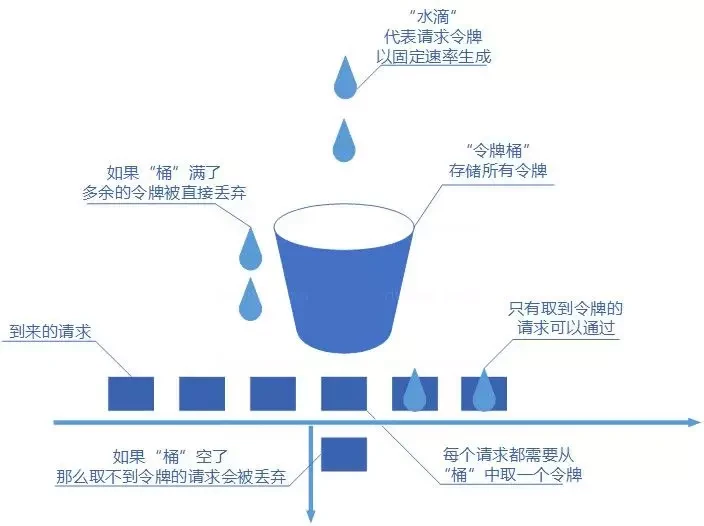
优点:
- 可以限制平均速率和应对突然激增的流量。
- 可以动态调整生成令牌的速率。
缺点:
- 如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
- 相比于其他限流算法,实现和理解起来更复杂一些。
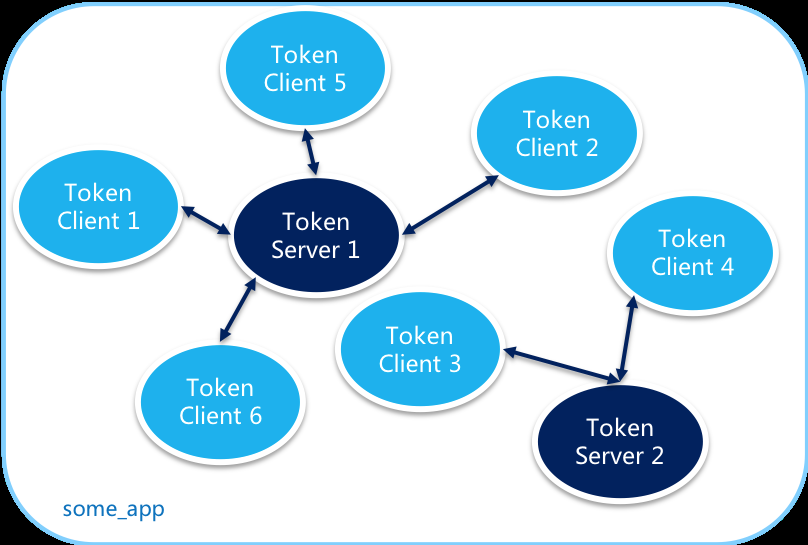
# Sentinel 怎么实现集群限流?
Sentinel 利用了 Token Server 和 Token Client 的机制来实现集群限流。
开启集群限流后,Client 向 Token Server 发送请求,Token Server 根据配置的规则决定是否限流。T
# 什么是 API 网关?
API 网关(API Gateway)是一种中间层服务器,用于集中管理、保护和路由对后端服务的访问。它充当了客户端与后端服务之间的入口点,提供了一组统一的接口来管理和控制 API 的访问。
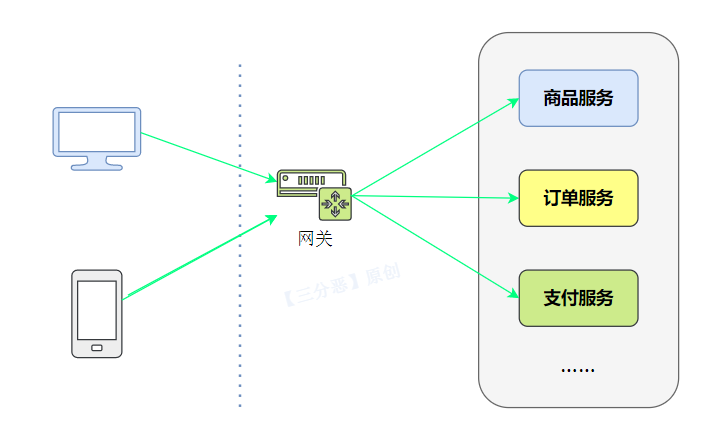
API 网关的主要功能包括:
- 路由转发:API 网关根据请求的 URL 路径或其他标识,将请求路由到相应的后端服务。通过配置路由规则,可以灵活地将请求分发给不同的后端服务。
- 负载均衡:API 网关可以在后端服务之间实现负载均衡,将请求平均分发到多个实例上,提高系统的吞吐量和可扩展性。
- 安全认证与授权:API 网关可以集中处理身份验证和授权,确保只有经过身份验证的客户端才能访问后端服务。它可以与身份提供者(如 OAuth、OpenID Connect)集成,进行用户认证和授权操作。
- 缓存:API 网关可以缓存后端服务的响应,减少对后端服务的请求次数,提高系统性能和响应速度。
- 监控与日志:API 网关可以收集和记录请求的指标和日志,提供实时监控和分析,帮助开发人员和运维人员进行故障排查和性能优化。
- 数据转换与协议转换:API 网关可以在客户端和后端服务之间进行数据格式转换和协议转换,如将请求从 HTTP 转换为 WebSocket,或将请求的参数进行格式转换,以满足后端服务的需求。
- API 版本管理:API 网关可以管理不同版本的 API,允许同时存在多个 API 版本,并通过路由规则将请求正确地路由到相应的 API 版本上。
通过使用 API 网关,可以简化前端与后端服务的交互,提供统一的接口和安全性保障,同时也方便了服务治理和监控。它是构建微服务架构和实现 API 管理的重要组件之一。
# Spring Cloud Gateway 核心概念?
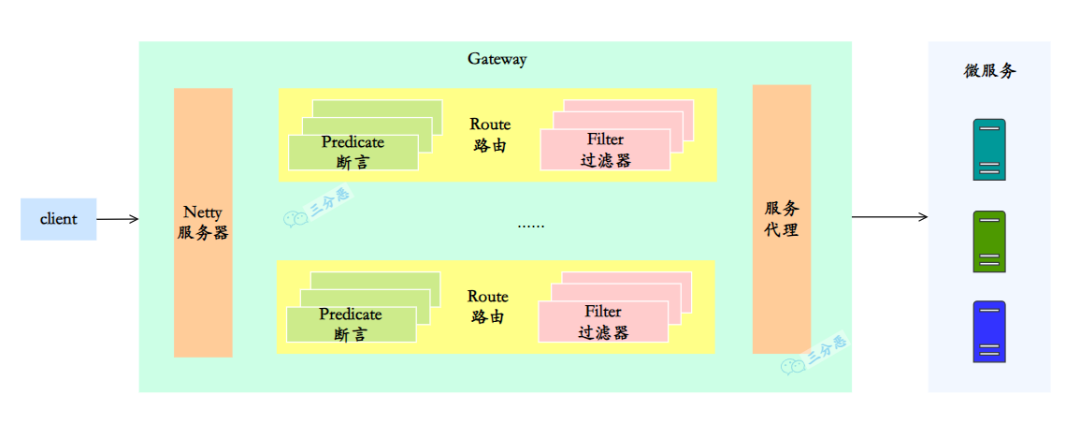
在 Spring Cloud Gateway 里,有三个关键组件:
- Route(路由):路由是 Spring Cloud Gateway 的基本构建块,它定义了请求的匹配规则和转发目标。通过配置路由,可以将请求映射到后端的服务实例或 URL 上。路由规则可以根据请求的路径、方法、请求头等条件进行匹配,并指定转发的目标 URI。
- Predicate(断言):断言用于匹配请求的条件,如果请求满足断言的条件,则会应用所配置的过滤器。Spring Cloud Gateway 提供了多种内置的断言,如 Path(路径匹配)、Method(请求方法匹配)、Header(请求头匹配)等,同时也支持自定义断言。
- Filter(过滤器):过滤器用于对请求进行处理和转换,可以修改请求、响应以及执行其他自定义逻辑。Spring Cloud Gateway 提供了多个内置的过滤器,如请求转发、请求重试、请求限流等。同时也支持自定义过滤器,可以根据需求编写自己的过滤器逻辑。
我们再来看下 Spring Cloud Gateway 的具体工作流程:
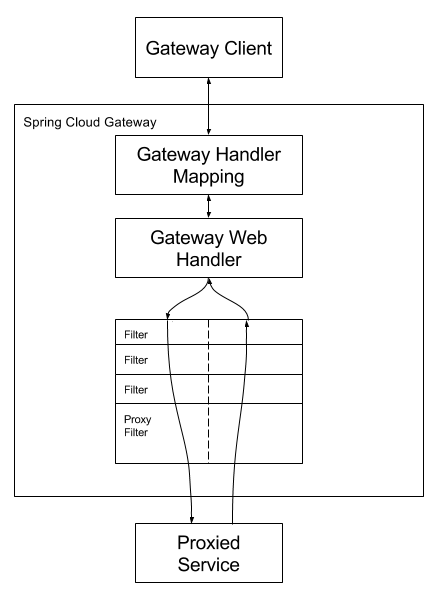
又有两个比较重要的概念:
- Gateway Handler(网关处理器):网关处理器是 Spring Cloud Gateway 的核心组件,负责将请求转发到匹配的路由上。它根据路由配置和断言条件进行路由匹配,选择合适的路由进行请求转发。网关处理器还会依次应用配置的过滤器链,对请求进行处理和转换。
- Gateway Filter Chain(网关过滤器链):网关过滤器链由一系列过滤器组成,按照配置的顺序依次执行。每个过滤器可以在请求前、请求后或请求发生错误时进行处理。过滤器链的执行过程可以修改请求、响应以及执行其他自定义逻辑。
# 为什么要用微服务链路追踪?
在微服务中,有的山下游可能有十几个服务,如果某一环出了问题,排查起来非常困难,所以,就需要进行链路追踪,来帮助排查问题。
通过链路追踪,可以可视化地追踪请求从一个微服务到另一个微服务的调用情况。除了排查问题,链路追踪黑还可以帮助优化性能,可视化依赖关系、服务监控和告警。
# SpringCloud 可以选择哪些微服务链路追踪方案?
- Zipkin:Zipkin 是一个开源的分布式实时追踪系统,由 Twitter 开发并贡献给开源社区。Spring Cloud Sleuth 提供了与 Zipkin 的集成,可以通过在微服务中添加相应的依赖和配置,将追踪信息发送到 Zipkin 服务器,并通过 Zipkin UI 进行可视化展示和查询。
- Jaeger:Jaeger 是 Uber 开源的分布式追踪系统,也被纳入了 CNCF(云原生计算基金会)的维护。通过使用 Spring Cloud Sleuth 和 Jaeger 客户端库,可以将追踪信息发送到 Jaeger 并进行可视化展示和查询。
- SkyWalking:Apache SkyWalking 是一款开源的应用性能监控与分析系统,提供了对 Java、.NET 和 Node.js 等语言的支持。它可以与 Spring Cloud Sleuth 集成,将追踪数据发送到 SkyWalking 服务器进行可视化展示和分析。
- Pinpoint:Pinpoint 是 Naver 开源的分布式应用性能监控系统,支持 Java 和 .NET。它提供了与 Spring Cloud Sleuth 的集成,可以将追踪数据发送到 Pinpoint 服务器,并通过其 UI 进行分析和监控。
# 分布式事务了解多少
tag:
携程count:1
# Seata 支持哪些模式的分布式事务?
Seata 以下几种模式的分布式事务:
# AT(Atomikos)模式
AT(Atomikos)模式:AT 模式是 Seata 默认支持的模式,也是最常用的模式之一。在 AT 模式下,Seata 通过在业务代码中嵌入事务上下文,实现对分布式事务的管理。Seata 会拦截并解析业务代码中的 SQL 语句,通过对数据库连接进行拦截和代理,实现事务的管理和协调。最终一致性(ap),各个分支事务都会进行提交,当彼此结果不一样的时候就会通过 undo(回滚日志)进行逆操作,保证数据最终的一致性。
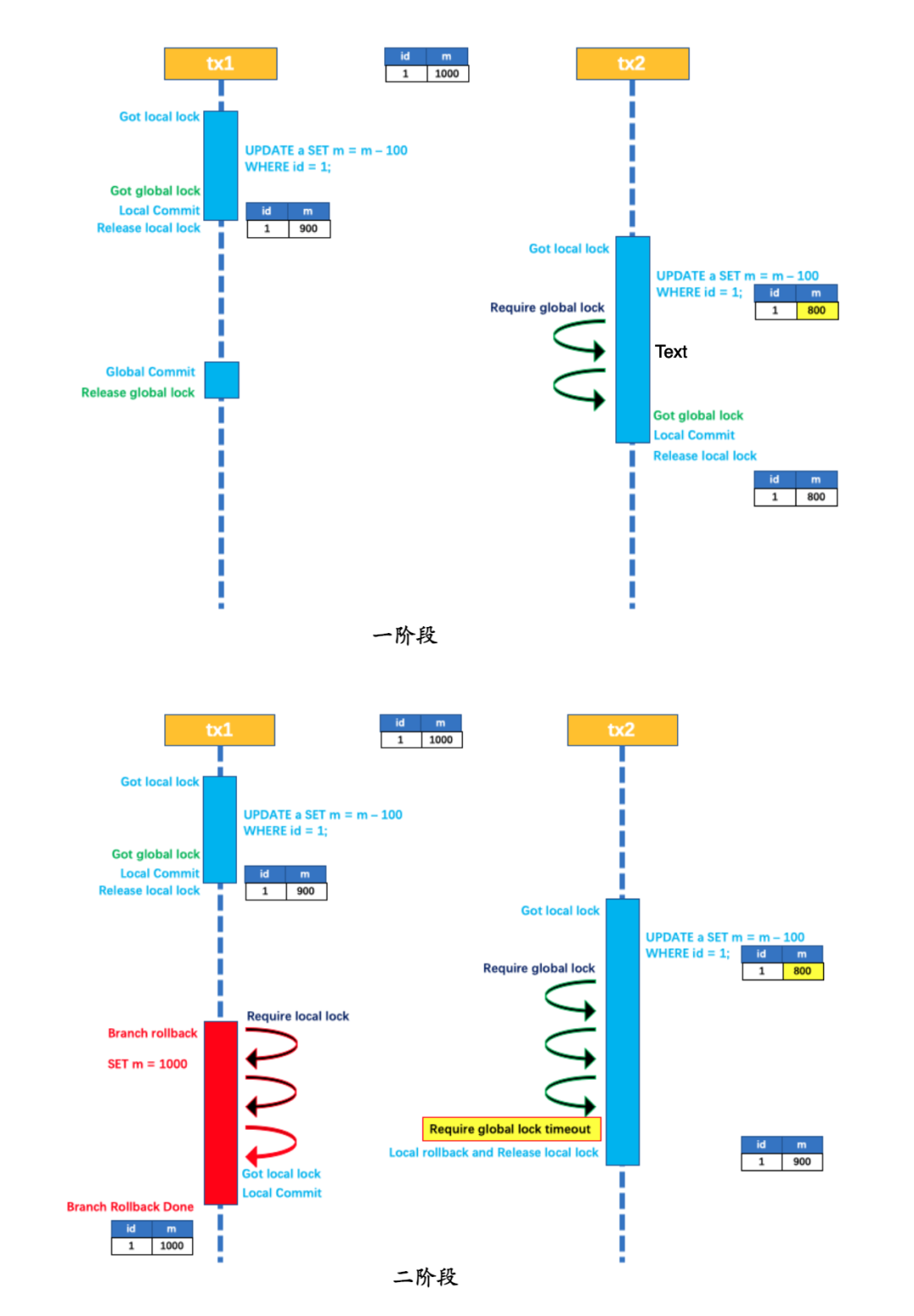
# TCC(Try-Confirm-Cancel)模式
TCC(Try-Confirm-Cancel)模式:TCC 模式是一种基于补偿机制的分布式事务模式。在 TCC 模式中,业务逻辑需要实现 Try、Confirm 和 Cancel 三个阶段的操作。Seata 通过调用业务代码中的 Try、Confirm 和 Cancel 方法,并在每个阶段记录相关的操作日志,来实现分布式事务的一致性。最终一致性,类是 TA 模式,性能比较好。但是需要人工编码,耦合度比较高。
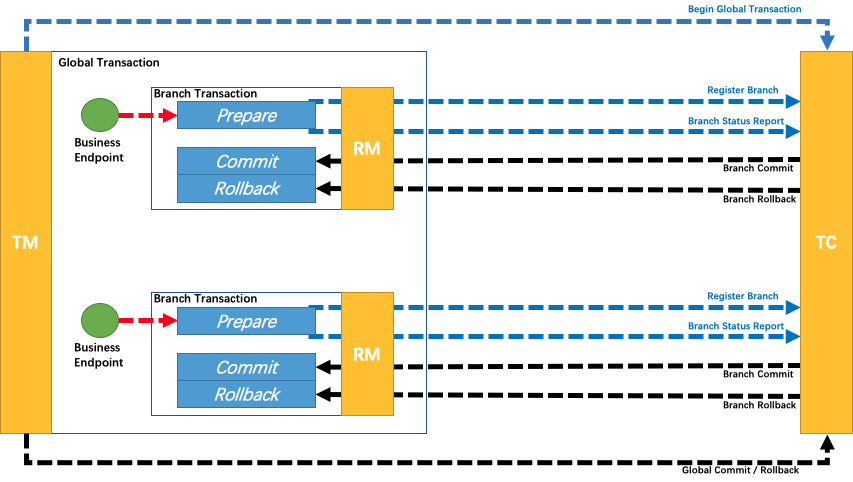
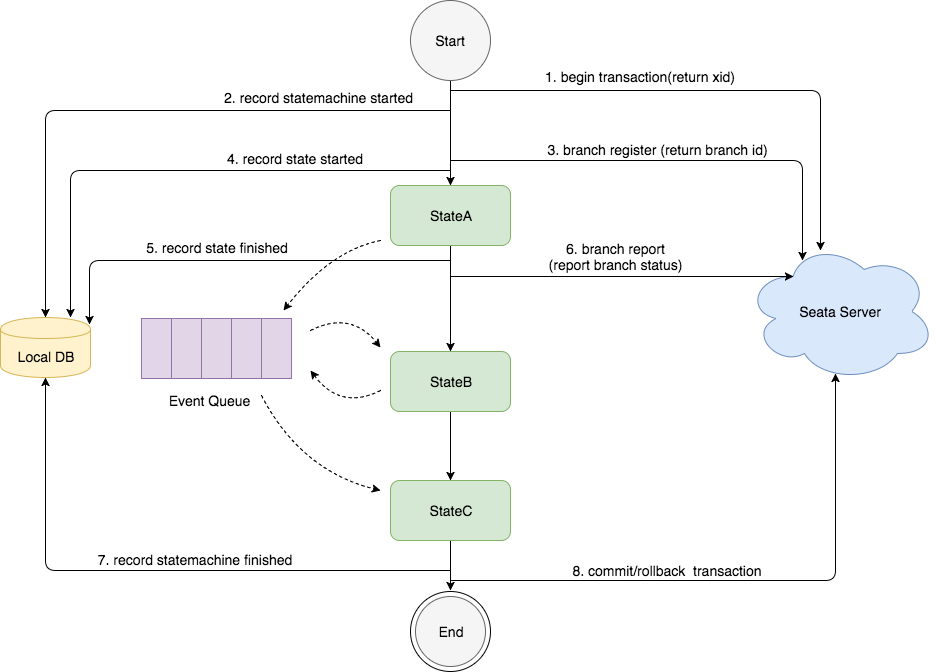
# SAGA 模式
SAGA 模式:SAGA 模式是一种基于事件驱动的分布式事务模式。在 SAGA 模式中,每个服务都可以发布和订阅事件,通过事件的传递和处理来实现分布式事务的一致性。Seata 提供了与 SAGA 模式兼容的 Saga 框架,用于管理和协调分布式事务的各个阶段。
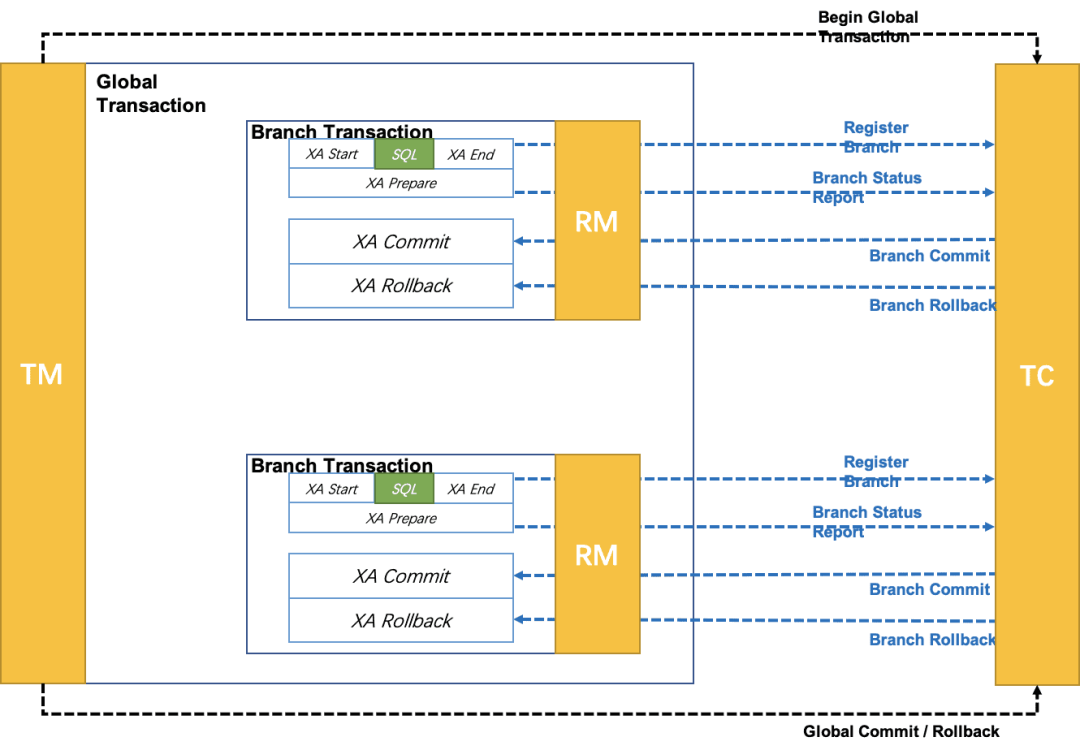
# XA 模式
XA 模式:XA 模式是一种基于两阶段提交(Two-Phase Commit)协议的分布式事务模式。强一致性(cp),各个分支事务不会提交事务,都在等待彼此的结果,最终一起提交或回滚。
在 XA 模式中,Seata 通过与数据库的 XA 事务协议进行交互,实现对分布式事务的管理和协调。XA 模式需要数据库本身支持 XA 事务,并且需要在应用程序中配置相应的 XA 数据源。
# Seata 的实现原理
Seata 的实现原理主要包括三个核心组件:事务协调器(Transaction Coordinator)、事务管理器(Transaction Manager)和资源管理器(Resource Manager)。
- 事务协调器(Transaction Coordinator):事务协调器负责协调和管理分布式事务的整个过程。它接收事务的开始和结束请求,并根据事务的状态进行协调和处理。事务协调器还负责记录和管理事务的全局事务 ID(Global Transaction ID)和分支事务 ID(Branch Transaction ID)。
- 事务管理器(Transaction Manager):事务管理器负责全局事务的管理和控制。它协调各个分支事务的提交或回滚,并保证分布式事务的一致性和隔离性。事务管理器还负责与事务协调器进行通信,并将事务的状态变更进行持久化。
- 资源管理器(Resource Manager):资源管理器负责管理和控制各个参与者(Participant)的事务操作。它与事务管理器进行通信,并根据事务管理器的指令执行相应的事务操作,包括提交和回滚。
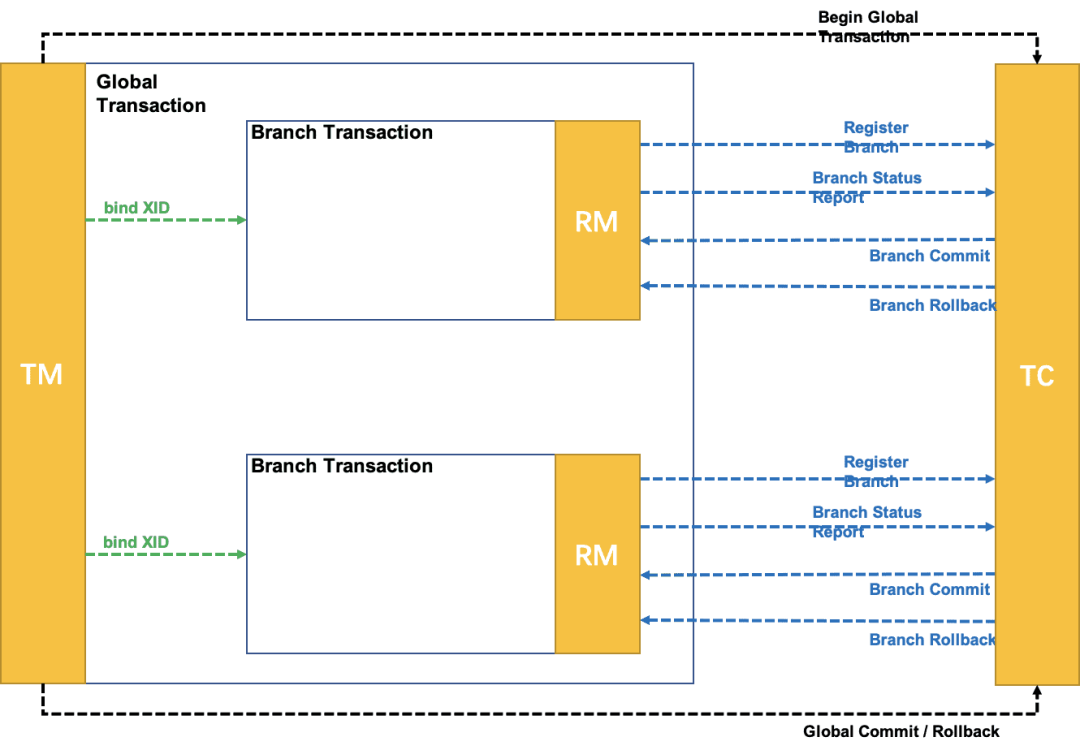
Seata 的实现原理基于两阶段提交(Two-Phase Commit)协议,具体的机制如下:
一阶段:在事务提交的过程中,首先进行预提交阶段。事务协调器向各个资源管理器发送预提交请求,资源管理器执行相应的事务操作并返回执行结果。在此阶段,业务数据和回滚日志记录在同一个本地事务中提交,并释放本地锁和连接资源。
二阶段:在预提交阶段成功后,进入真正的提交阶段。此阶段主要包括提交异步化和回滚反向补偿两个步骤:
- 提交异步化:事务协调器发出真正的提交请求,各个资源管理器执行最终的提交操作。这个阶段的操作是非常快速的,以确保事务的提交效率。
- 回滚反向补偿:如果在预提交阶段中有任何一个资源管理器返回失败结果,事务协调器发出回滚请求,各个资源管理器执行回滚操作,利用一阶段的回滚日志进行反向补偿。
# Seata 的事务执行流程是什么样的?
Seata 事务的执行流程可以简要概括为以下几个步骤:
- 事务发起方(Transaction Starter)发起全局事务:事务发起方是指发起分布式事务的应用程序或服务。它向 Seata 的事务协调器发送全局事务的开始请求,生成全局事务 ID(Global Transaction ID)。
- 事务协调器创建全局事务记录:事务协调器接收到全局事务的开始请求后,会为该事务创建相应的全局事务记录,并生成分支事务 ID(Branch Transaction ID)。
- 分支事务注册:事务发起方将全局事务 ID 和分支事务 ID 发送给各个参与者(Participant),即资源管理器。参与者将分支事务 ID 注册到本地事务管理器,并将事务的执行结果反馈给事务协调器。
- 执行业务逻辑:在分布式事务的上下文中,各个参与者执行各自的本地事务,即执行业务逻辑和数据库操作。
- 预提交阶段:事务发起方向事务协调器发送预提交请求,事务协调器将预提交请求发送给各个参与者。
- 执行本地事务确认:参与者接收到预提交请求后,执行本地事务的确认操作,并将本地事务的执行结果反馈给事务协调器。
- 全局事务提交或回滚:事务协调器根据参与者反馈的结果进行判断,如果所有参与者的本地事务都执行成功,事务协调器发送真正的提交请求给参与者,参与者执行最终的提交操作;如果有任何一个参与者的本地事务执行失败,事务协调器发送回滚请求给参与者,参与者执行回滚操作。
- 完成全局事务:事务协调器接收到参与者的提交或回滚结果后,根据结果更新全局事务的状态,并通知事务发起方全局事务的最终结果。
# 全局事务 ID 和分支事务 ID 是怎么传递的?
全局事务 ID 和分支事务 ID 在分布式事务中通过上下文传递的方式进行传递。常见的传递方式包括参数传递、线程上下文传递和消息中间件传递。具体的传递方式可以根据业务场景和技术选型进行选择和调整。
# Seata 的事务回滚是怎么实现的?
Seata 的事务回滚是通过回滚日志实现的。每个参与者在执行本地事务期间生成回滚日志,记录了对数据的修改操作。
当需要回滚事务时,事务协调器向参与者发送回滚请求,参与者根据回滚日志中的信息执行撤销操作,将数据恢复到事务开始前的状态。
回滚日志的管理和存储是 Seata 的核心机制,可以选择将日志存储在不同的介质中。通过回滚日志的持久化和恢复,Seata 确保了事务的一致性和恢复性。
# 你们的服务怎么做监控和告警?
我们使用 Prometheus 和 Grafana 来实现整个微服务集群的监控和告警:
- Prometheus:Prometheus 是一个开源的监控系统,具有灵活的数据模型和强大的查询语言,能够收集和存储时间序列数据。它可以通过 HTTP 协议定期拉取微服务的指标数据,并提供可扩展的存储和查询功能。
- Grafana:Grafana 是一个开源的可视化仪表板工具,可以与 Prometheus 结合使用,创建实时和历史数据的仪表板。Grafana 提供了丰富的图表和可视化选项,可以帮助用户更好地理解和分析微服务的性能和状态。
# 你们的服务怎么做日志收集?
日志收集有很多种方案,我们用的是 ELK :
- Elasticsearch:Elasticsearch 是一个分布式搜索和分析引擎,用于存储和索引大量的日志数据。它提供了快速的搜索和聚合功能,可以高效地处理大规模的日志数据。
- Logstash:Logstash 是一个用于收集、过滤和转发日志数据的工具。它可以从各种来源(如文件、网络、消息队列等)收集日志数据,并对数据进行处理和转换,然后将其发送到 Elasticsearch 进行存储和索引。
- Kibana:Kibana 是一个用于日志数据可视化和分析的工具。它提供了丰富的图表、仪表盘和搜索功能,可以帮助用户实时监控和分析日志数据,发现潜在的问题和趋势。
简单说,这三者里 Elasticsearch 提供数据存储和检索能力,Logstash 负责将日志收集到 ES,Kibana 负责日志数据的可视化分析。
使用 ELK 进行微服务日志收集的一般流程如下:

- 在每个微服务中配置日志输出:将微服务的日志输出到标准输出(stdout)或日志文件。
- 使用 Logstash 收集日志:配置 Logstash 收集器,通过配置输入插件(如文件输入、网络输入等)监听微服务的日志输出,并进行过滤和处理。
- 将日志数据发送到 Elasticsearch:配置 Logstash 的输出插件,将经过处理的日志数据发送到 Elasticsearch 进行存储和索引。
- 使用 Kibana 进行可视化和分析:通过 Kibana 连接到 Elasticsearch,创建仪表盘、图表和搜索查询,实时监控和分析微服务的日志数据。
除了应用最广泛的 ELK,还有一些其它的方案比如 Fluentd 、 Graylog 、 Loki 、 Filebeat ,一些云厂商也提供了付费方案,比如阿里云的 sls 。
# 分布式结构,怎么保证数据一致性
- 规避分布式事务 —— 业务整合
- 经典方案 - eBay 模式
# xxl-job 与 quartz 定时任务有什么区别 / 优势
xxl-job 的路由策略有哪些?
轮询:轮流被选择。
故障转移:通过心跳机制,找到第一个健康实例。
分片广播:通过广播触发触发定时任务。适用于任务数量多的时候。在我们的物流项目中定时任务就是使用分片广播。(引导面试官到你的项目中)
xxl-job 任务执行失败怎么解决?
故障转移策略 + 设置重试次数 + 在设置邮箱告警。
如果大量的任务需要被执行,怎么解决?
使用分片广播,在代码编写上我们可以获取当前 xxl-job 节点的索引和节点的总数。通过取总数模来确定执行任务的节点。
在我们的计算运力模块中,司机执行运力计算时就需要执行定时任务。通过去模的方式选择对应的节点来执行计算运力。那再这个过程中我们为了保证用户的体验,我们需要给在计算运力的时候添加分布式锁,保证同一个用户的商品尽可能的在同一辆车上。