 常用的数据结构与算法
常用的数据结构与算法
# 常用数据结构与算法
# 数据结构
# 栈
栈(stack)又称堆栈,是一种运算受限的线性表。栈的限制是仅允许在表的一端进行插入和删除操作,被允许操作的一端被称为栈顶,另一端则被称为栈底,如图 8.1.1 所示。向一个栈中 插入新元素又称入栈或压栈,它把新元素放到栈顶元素的上面,使之成为新的栈顶元素。从一个 栈中删除元素又称出栈或退栈,它把栈顶元素删除,使其相邻的元素成为新的栈顶元素。由于堆 栈只允许在一端进行操作,所以遵循后进先出(Last In First Out,LIFO)的操作原则。
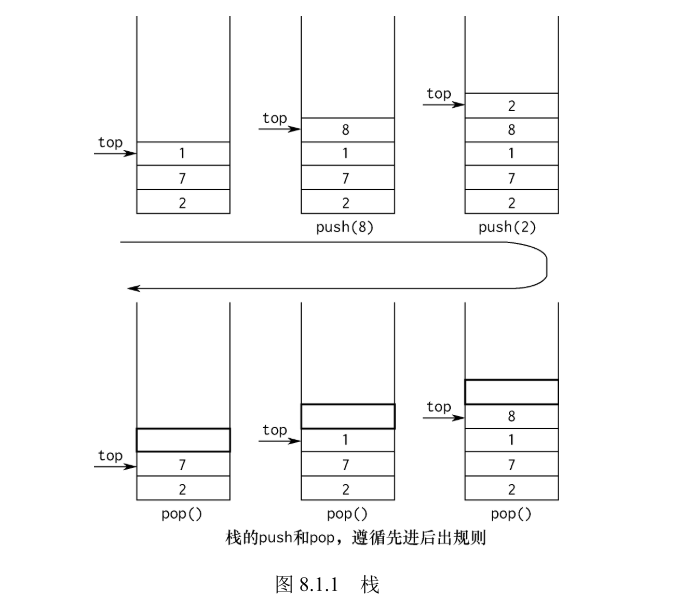
栈可以用数组实现,也可以用链表实现,这里用链表来实现栈。这里采用链表的头部插入法(头插法)、头部删除法来实现先进后出的效果。
stack.h
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct tag {
int val;
struct tag *pNext;
} Node_t, *pNode_t;
typedef struct {
pNode_t phead; //栈顶指针
int size; //栈中的元素个数
} Stack_t, *pStack_t;
void initStack(pStack_t stack);
//入栈
void push(pStack_t stack, int val);
//弹栈
void pop(pStack_t stack) ;
//查看栈顶
int top(pStack_t stack) ;
//查看栈大小
int size(pStack_t stack);
//判断栈是否为空
int empty(pStack_t stack);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
stack.h
#include "stack.h"
//初始化栈
void initStack(pStack_t stack) {
memset(stack, 0, sizeof(Stack_t));
}
//入栈
void push(pStack_t stack, int val) {
pNode_t pNew = (pNode_t)calloc(1, sizeof(Node_t));//为压栈的新结点申请空间
pNew->val = val;//将要压栈的值放入对应结点空间
pNew->pNext = stack->phead;//头插法
stack->phead = pNew;
stack->size++;//栈的元素加 1
}
//弹栈
void pop(pStack_t stack) {
pNode_t pCur;
if (!stack->size) {
printf("栈为空,无法进行弹栈");
}
pCur = stack->phead;
stack->phead = pCur->pNext;
free(pCur);
pCur = NULL;
}
//查看栈顶
int top(pStack_t stack) {
if (!stack->size) {
return -1;
}
//返回栈顶元素值
return stack->phead->val;
}
//查看栈大小
int size(pStack_t stack) {
return stack->size;
}
//判断栈是否为空
int empty(pStack_t stack) {
return !stack->size;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
main.c
#include "stack.h"
int main() {
Stack_t stack;
int ret;
initStack(&stack);
push(&stack, 10);
push(&stack, 8);
printf("%d\n",size(&stack));
pop(&stack);
ret = top(&stack);
printf("%d\n", ret);
printf("%d\n",empty(&stack));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 队列
队列是先进先出(First-In-First-Out,FIFO)的线性表。在具体应用中,通常用链表或数组来实现队列。队列只允许在后端(称为 rear)进行插入操作,在前端(称为 front)进行删除操作。 通过对链表进行头部删除、尾部插入,可以实现每个元素先进先出的效果。
循环队列:如果通过链表实现,那么让链表尾指针的 pnext 指向头指针,即可用链表实现循 环队列。如果通过数组实现,那么对数组进行遍历,当 i 等于最后一个元素时,将 i 赋值为 0,就可重新回到数组元素的起始点。
squeue.h
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MaxSize 5
typedef int ElemType;
typedef struct {
ElemType data[MaxSize]; //数组,存储 MaxSize-1 个元素
int front,rear; //队列头、队列尾下标
}SqQueue_t;
//初始化队列
void initQueue(SqQueue_t *queue);
//入队列
void enQueue(SqQueue_t*,ElemType);
//出队列
void deQueue(SqQueue_t*,ElemType*);
//判空
int isEmpty(SqQueue_t*);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
squeue.c
#include "squeue.h"
//初始化队列
void initQueue(SqQueue_t *queue) {
//初始化队列时,让队列头和队列尾都指向数组的 0 号元素,数组下标从零开始
queue->front = queue->rear = 0;
}
//入队列
void enQueue(SqQueue_t *queue, ElemType x) {
/*
循环队列,Q->rear 指向的元素是我们将要放置的元素位置,为了能够区分头部与尾部,对
于循环队列我们需要空出一个元素作为分割,因此数组的长度为 5,实际可以放入的元素个
数为 4。因此,我们判断队列是否满的策略是,Q->rear 加 1 后,判断是否等于 Q->front,
因为要考虑到循环的问题,所以需要除以 MaxSize 得余数。
*/
if ((queue->rear + 1) % MaxSize == queue->front) {
printf("队列已满,无法入队");
return;
}
//尾插法
queue->data[queue->rear] = x;
//每放入一个元素,需要对 Q->rear 增 1,因为数组可以访问的最大下标为 4,为防止到达数组的末尾,需要对 MaxSize 取模
queue->rear = (queue->rear + 1) % MaxSize;
}
//出队列
void deQueue(SqQueue_t *queue, ElemType *x) {
//如果 front 与 rear 相等,那么代表循环队列为空,这时直接返回
if (queue->front == queue->rear) {
printf("队列为空,无法删除");
return;
}
//先进先出
*x = queue->data[queue->front];
//出队一个元素后,front 加 1
queue->front = (queue->front + 1) % MaxSize;
}
//判空
int isEmpty(SqQueue_t *queue) {
if (queue->rear == queue->front) {
return 1;
} else {
return 0;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
main.c
#include "squeue.h"
int main() {
SqQueue_t Q;
ElemType e;
initQueue(&Q);
enQueue(&Q, 10);
enQueue(&Q, 5);
printf("队列是否为空 =%d\n",isEmpty(&Q));
deQueue(&Q, &e);
printf("出队成功,元素值为 %d\n",e);
}
2
3
4
5
6
7
8
9
10
11
12
# 二叉树
二叉树是指每个结点最多有两个子树的树结构。一般来说,子树分为左子树(left subtree)和右子树(right subtree)。二叉树常被用来实现二叉查找树和二叉堆。
二叉树的每个结点至多有两棵子树(不存在度大于 2 的结点),二叉树的子树有左右之分,次序不能颠倒。
二叉树的第 i 层至多有
深度为 k 且有
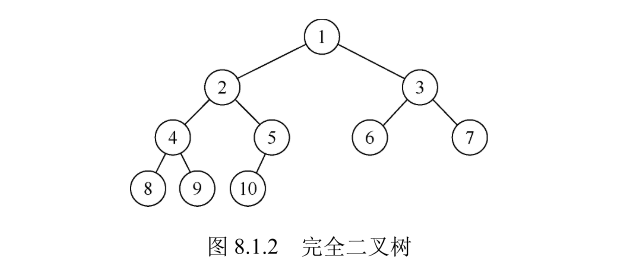
完全二叉树的特点如下:
- 只允许最后一层有空缺结点且空缺在右边,即叶子结点只能在层次最大的两层上出现。
- 对任意一个结点,如果其右子树的深度为 j ,那么其左子树的深度必为 j 或 j+1 ,即度为 1 的点只有 1 个或 0 个。
二叉树的存储可以是顺序存储(顺序存储将在介绍堆排序时学习),也可以是链式存储。下面以采链式存储实现二叉树的做例子。
tree.h
#include <stdio.h>
#include <stdlib.h>
typedef char ElemType;
typedef struct node_t{
ElemType c; //结点内存的元素类型
struct node_t *pleft; //指向左子结点的指针
struct node_t *pright; //指向右子结点的指针
}Node_t,*pNode_t;
//辅助队列数据结构,辅助队列中每个元素放的是树中元素结点的地址值,这样才能快速确定树中的结点
typedef struct queue_t{
pNode_t insertPos;
struct queue_t *pNext;
}Queue_t,*pQueue_t;
//前序遍历
void preOrder(pNode_t root);
//中序遍历
void midOrder(pNode_t root);
//后序遍历
void lastOrder(pNode_t root);
//链表构建二叉树
void buildBinaryTree(pNode_t *treeRoot,pQueue_t *queHead,pQueue_t *queTail,ElemType val);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
tree.c
#include "tree.h"
//前序遍历
void preOrder(pNode_t root) {
if (root == NULL) {
return;
}
putchar(root->c); //打印当前结点
preOrder(root->pleft); //打印左子结点
preOrder(root->pright); //打印右子结点
}
//中序遍历
void midOrder(pNode_t root) {
if (root == NULL) {
return;
}
midOrder(root->pleft);
putchar(root->c);
midOrder(root->pright);
}
//后序遍历
void lastOrder(pNode_t root) {
if (root == NULL) {
return;
}
lastOrder(root->pleft);
lastOrder(root->pright);
putchar(root->c);
}
// 链表构建二叉树
void buildBinaryTree(pNode_t *treeRoot, pQueue_t *queHead, pQueue_t *queTail, ElemType val) {
//新节点
pNode_t treeNew = (pNode_t)calloc(1, sizeof(node_t));
//新队列
pQueue_t queNew = (pQueue_t)calloc(1, sizeof(queue_t));
//当前节点记录头队列
pQueue_t queCur = *queHead;
//为新节点赋值
treeNew->c = val;
//新队列添加新节点
queNew->insertPos = treeNew;
//当树为空时,新结点作为树根,同时新结点既作为队列头和队列尾
if (*treeRoot == NULL) {
//树为空新节点作为二叉树根节点
*treeRoot = treeNew;
//队列头节点
*queHead = queNew;
//队列尾节点
*queTail = queNew;
}
//树不为空时
else {
//新结点通过尾插法放入队列尾
(*queTail)->pNext = queNew;
//更新尾队列
*queTail = queNew;
//判断当前节点的左树是否为空
if (queCur->insertPos->pleft == NULL){
//为空时放置到当前节点的左树中
queCur->insertPos->pleft = treeNew;
}
//判断当前节点右树是否为空
else if (queCur->insertPos->pright ==NULL) {
//放置新节点
queCur->insertPos->pright = treeNew;
//当前节点左右树已经放满,队列头后移一个结点,删除原有头部
*queHead = queCur->pNext;
free(queCur);
queCur = NULL;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
main.c
#include "tree.h"
#define N 10
int main() {
//通过字符串和for循环来构建二叉树
ElemType c[] = "ABCDEFGHIJ";
pNode_t p[N];
int i, j = 0;
//通过 for 循环,为每个要进树的结点申请空间,并将结点值放入
for (i = 0; i <= N; i++) {
p[i] = (pNode_t)calloc(1, sizeof(Node_t)); //申请空间
p[i]->c = c[i]; //申请空间后,将对应的元素值填入即字符数组中的元素
}
//通过下标 i 控制要进入树的元素
for (i = 1; i < N; i++) {
//如果没有左子结点,就放入左子结点
if (p[j]->pleft == NULL) {
p[j]->pleft = p[i];
}
//否则放入右子结点
else if (p[j]->pright == NULL) {
p[j]->pright = p[i];
//放入右子结点后,当前结点左右已满,因此对 j 加 1,从而下次进树时,放置到下一个结点,我们通过下标 j 记录进树的位置
j++;
}
}
printf("前序遍历\n");
preOrder(p[0]);
printf("\n------------------------\n");
printf("中序遍历\n");
midOrder(p[0]);
printf("\n------------------------\n");
printf("后序遍历\n");
lastOrder(p[0]);
printf("\n------------------------\n");
ElemType val;
pNode_t treeRoot = NULL;
pQueue_t queHead = NULL, queTail = NULL;
while (scanf("%c", &val) != EOF) {
if (val == '\n') {
break;
}
buildBinaryTree(&treeRoot, &queHead, &queTail, val);
}
printf("前序遍历\n");
preOrder(treeRoot);
printf("\n------------------------\n");
printf("中序遍历\n");
midOrder(treeRoot);
printf("\n------------------------\n");
printf("后序遍历\n");
lastOrder(treeRoot);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# 红黑树
红黑树(Red-Black tree,简称 RB 树)是一种自平衡二叉查找树,是计算机科学中常见的一种数据结构,其典型用途是实现关联数组。红黑树的结构复杂,但其操作有着良好的最坏情况运行时间,且在实践中有着较高的效率:它可以在
红黑树(RB 树)是二叉树中重要的知识点,因为在操作系统的内核中、C++ 的 STL 和 Java 的数据结构中都大量使用了红黑树,红黑树的增删查改的复杂度均为
以 AVL 树为例,AVL 树是最早被发明的自平衡二叉查找树。在 AVL 树中,任意一个结点对应的两棵子树的最大高度差为 1,因此它也被称为高度平衡树,对其进行查找、插入和删除在平 均和最坏情况下的时间复杂度都是
红黑树相对于 AVL 树的时间复杂度是一样的,但优势是在插入或删除结点时,红黑树实际的调整次数更少,旋转次数更少,因此红黑树插入 / 删除的效率要高于 AVL 树。大量的中间件产 品中使用了红黑树。
红黑树相对于 AVL 树来说,牺牲了部分平衡性以换取插入 / 删除操作时少量的旋转操作,整体来说性能要优于 AVL 树。
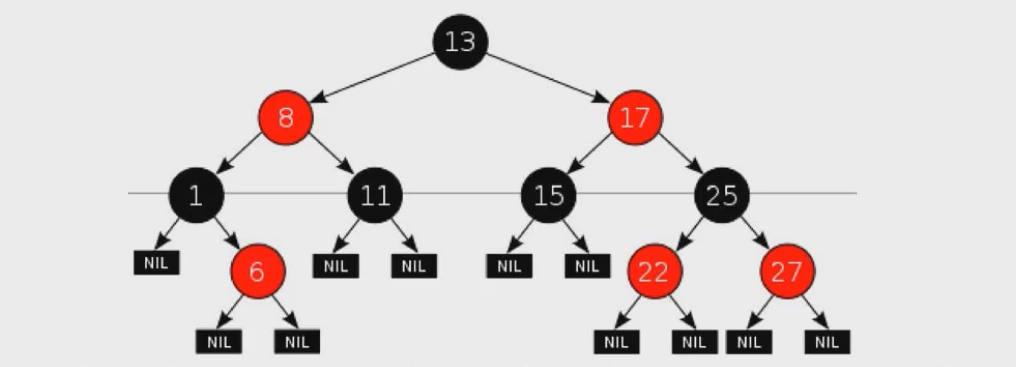
红黑树是每个结点都带有颜色属性的二叉查找树,颜色为红色或黑色。在二叉查找树的一般要求以外,对于任何有效的红黑树,我们额外增加了如下性质。
- 结点是红色的或黑色的。
- 根是黑色的。
- 所有叶子结点都是黑色的(叶子是 NIL 结点)。
- 每个红色结点必须有两个黑色的子结点(从每个叶子到根的所有路径上不能有两个连续的红色结点)。
- 从任意一个点到其每个叶子的所有简单路径都包含相同数量的黑色结点(即从根结点到每一个叶结点黑色节点数是相等的)。
如下图所示为一棵具体的红黑树(图中浅色圆圈代表红色,黑色圆圈代表黑色,如结点 13 是黑色的,结点 8 是红色的)。
# 算法
# 时间复杂度与空间复杂度
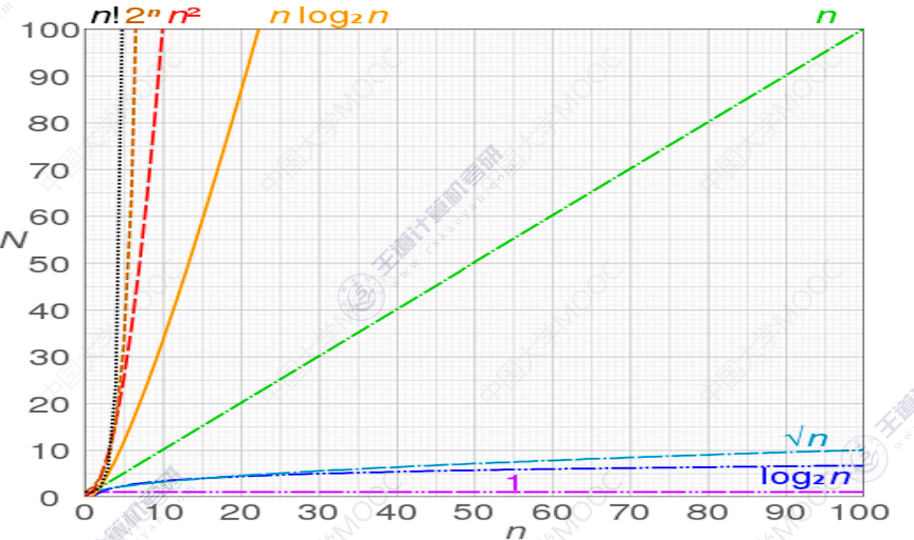
在计算机科学中,算法的时间复杂度是一个函数,它定量地描述了该算法的运行时间,这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大 O 符号表述,不包括这个函数的低阶项和首项系数(即取是最高阶并忽略常数)。使用这种方式时,时间复杂度被称为可渐近的,即考查输入值大小趋近无穷时的情况。
例如,如果一个算法对于任何大小为 n(必须比 n0 大)的输入,至多需要
相同大小的不同输入值仍可能造成算法的运行时间不同,因此我们通常使用算法的最坏情况复杂度,记为 T (n)。
若对于一个算法,T (n) 的上界与输入大小无关,则称其具有常数时间,记为 O (1)。
若算法的
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度(输入数据本身所占用的空间不计算),记为
# 排序算法
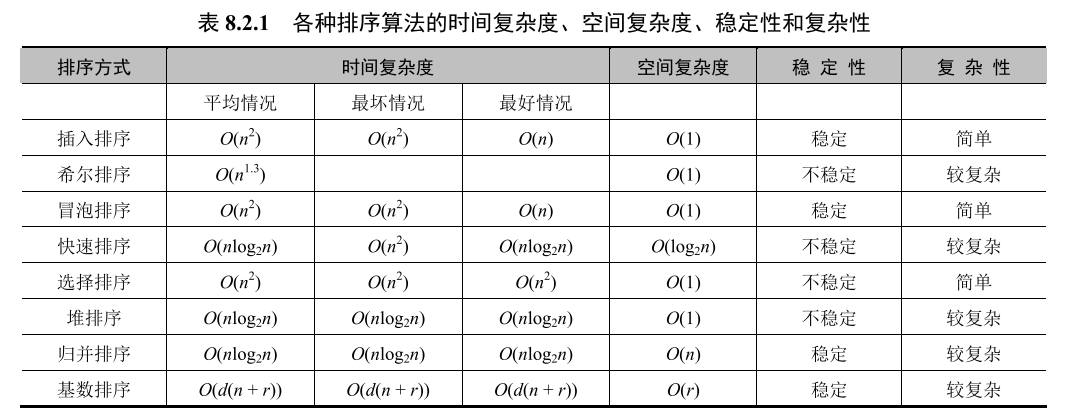
不稳定并不是指排序不成功,而是指相同大小的数字在排序后发生了位置交换(即相同大小时可能每次排序后的位置不确定),因此称为不稳定。