 深入浅出 HBase 实战| 青训营笔记
深入浅出 HBase 实战| 青训营笔记
# 深入浅出 HBase 实战| 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第 10 天
# HBase 适用场景
# 什么是 HBase?
HBase 基于 HDFS 实现存储计算分离架构的分布式表格存储服务。参考 Google BigTable 的设计,对稀疏表提供更高的存储空间使用率和读写效率。
HBase 是存储计算分离架构,以 HDFS 作为分布式存储底座。数据实际存储在 HDFS。
采用存储计算分离架构:
- 存储层基于 HDFS 存储数据,提供容错机制和高可靠性
- 计算层提供灵活快速的水平扩展、负载均衡和故障恢复能力
提供强一致语义,在 CAP 理论中属于 CP 系统。CAP 定理 (opens new window)
- Consistency,Availability,Partition Toleranc
# Hbase 和关系型数据库的区别
| HBase | Relational DB | |
|---|---|---|
| 数据结构 | 半结构化,无数据类型; 按列族稀疏存储,缺省数据不占用存储空间; 支持多版本数据; | 结构化,数据类型丰富; 按完整行存储,缺省的列需要存储占位符; 不支持多版本数据; |
| 读写模式 | 支持按需读写部分列 | 必须整行读取 |
| 事务支持 | 仅支持单行内原子性 | 支持完整的事务语义 |
| 数据规模 | 适用于 TB、PB 级海量数据,水平扩展快速平滑 | 仅适用于 GB、小量 TB 级,扩展过程较复杂 |
| 索引支持 | 仅支持 rowkey 主键索引 | 支持二级索引 |
# Hbase 数据模型
HBase 以列族 (column family)为单位存储数据,以行键(rowkey)索引数据。
- 列族需要在使用前预先创建,列名(column qualifier) 不需要预先声明,因此支持半结构化数据模型。
- 支持保留多个版本的数据,(行键 + 列族 + 列名+版本号)定位一个具体的值。
| 概念名称 | 概念用途 |
|---|---|
| 行键(rowkey) | 用于唯一索引一行数据的 “主键”,以字典序组织。一行可以包含多个列族。 |
| 列族(column family) | 用于组织一系列名,一个列族可以包含任意多个列名。每个列族的数据物理上相互独立地存储,以支持按列取部分数据。 |
| 列名(column qualifier) | 用于定义到一个具体的列,一个列名可以包含多个版本的数据。不需要预先定义列名,以支持半结构化的数据模型。 |
| 版本号(version) | 用于标识一个列内多个不同版本的数据,每个版本号对应一个值。 |
| 值(value) | 存储的一个具体的值。 |
# 逻辑结构
HBase 是半结构化存储。数据以行(row)组织,每行包括一到多个列簇(column family)。使用列簇前需要通过创建表或更新表操作预先声明 column family。
column family 是稀疏存储,如果某行数据未使用部分 column family 则不占用这部分存储空间。
每个 column family 由一到多个列(column qualifier)组成。column qualifier 不需要预先声明,可以使用任意值。
最小数据单元为 cell,支持存储多个版本的数据。由 rowkey + column family + column qualifier + version 指定一个 cell。
同一行同一列族的数据物理上连续存储,首先以 column qualifier 字典序排序,其次以 timestamp 时间戳倒序排序。
简单起见可以将 HBase 数据格式理解为如下结构:
// table名格式:"${namespace}:${table}"
// 例如:table = "default:test_table"
[
"rowKey1": { // rowkey定位一行数据
"cf1": { // column family需要预先定义到表结构
"cq_a": { // column qualifier无需定义,使用任意值
"timestamp3": "value3",
// row=rowKey1, column="cf1:cf_a", timestamp=timestamp2
// 定位一个cell
"timestamp2": "value2",
"timestamp1": "value1"
},
"cq_b": {
"timestamp2": "value2",
"timestamp1": "value1"
}
},
"cf3": {
"cq_m": {
"timestamp1": "value1"
},
"cq_n": {
"timestamp1": "value1"
}
},
},
"rowKey3": {
"cf2": { // 缺省column family不占用存储空间
"cq_x": {
"timestamp3": "value3",
"timestamp2": "value2",
"timestamp1": "value1"
},
"cq_y": {
"timestamp1": "value1"
}
},
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39

# 物理结构
物理数据结构最小单元是 KeyValue 结构:
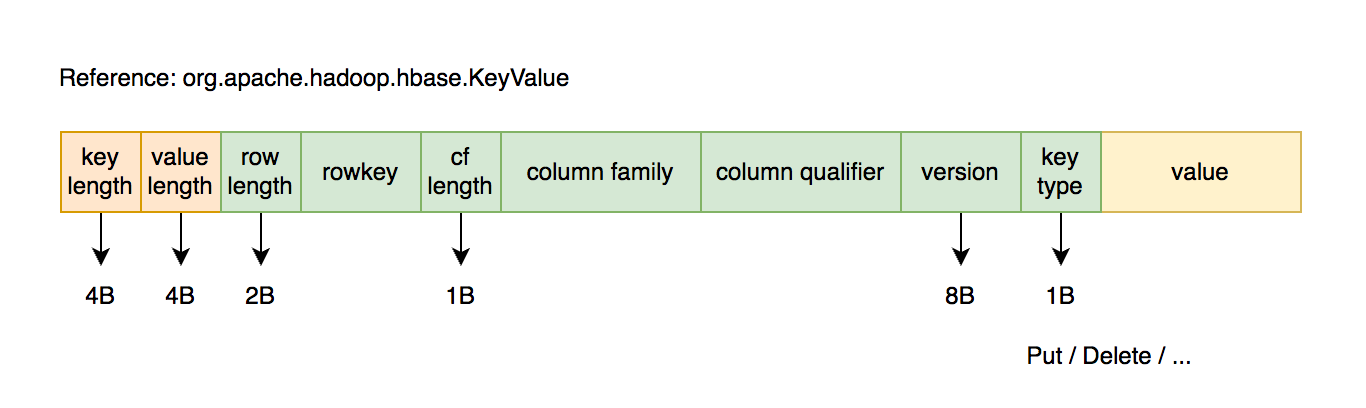
- 每个版本的数据都携带全部行列信息。
- 同一行,同一列族的数据物理上连续有序存储。
- 同列族内的 KeyValue 按 rowkey 字典序升序,column qualifier 升序,version 降序排列。
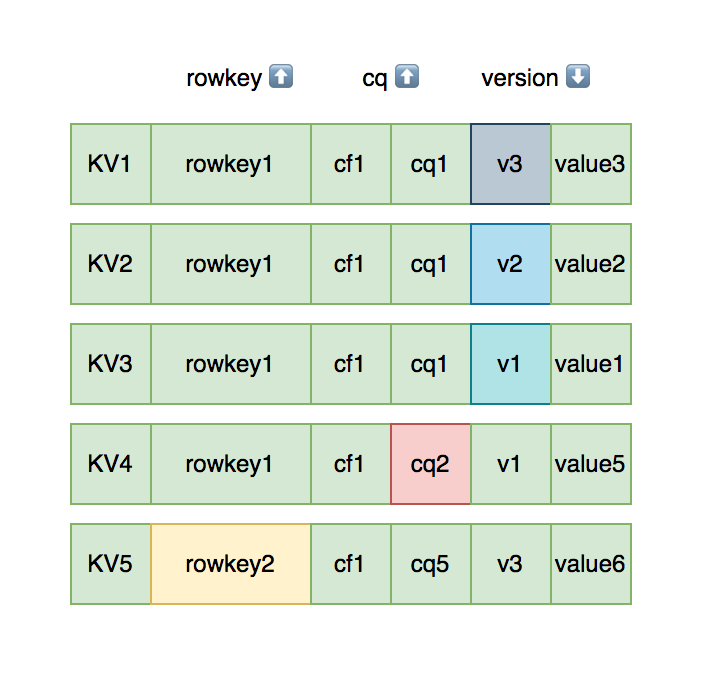
- 不同列族的数据存储在相互独立的物理文件,列族间不保证数据全局有序。
- 同列族下不同物理文件间不保证数据全局有序。
- 仅单个物理文件内有序。
# 使用场景
- “近在线” 的海量分布式 KV / 宽表存储,数据量级达到百 TB 级以上
- 写密集型应用,高吞吐,可接受一定的时延抖动
- 需要按行顺序扫描的能力,字典序主键索引、批量顺序扫描多行数据的场景
- 接入 Hadoop 大数据生态
- 半结构化数据模型,行列稀疏的数据分布,动态增减列名
- 敏捷平滑的水平扩展能力,快速响应数据体量、流量变化
# 典型应用
业务落地场景包括:
- 电商订单数据:抖音电商每日交易订单数据基于 HBase 存储,支持海量数据存储的同时满足稳定低延时的查询需求,并且只需相对很低的存储成本。通过多个列存储订单信息和处理进度,快速查询近期新增 / 待处理订单列表。同时也可将历史订单数据用于统计、用户行为分析等离线任务。
- 搜索推荐引擎:存储网络爬虫持续不断抓取并处理后的原始网页信息,通过 MapReduce、Flink、Spark 等大数据计算框架分析处理原始数据后产出粗选、精选、排序后的网页索引集,再存储到 HBase 以提供近实时的随机查询能力,为上层的多个字节跳动应用提供通用的搜索和推荐能力。
- 大数据生态:天生融入 Hadoop 大数据生态。对多种大数据组件、框架拥有良好的兼容性,工具链完善,快速打通大数据链路,提高系统构建落地效率,并借助 HDFS 提供可观的成本优势。敏捷平滑的水平扩展能力可以自如地应对数据体量和流量的快速增长。
- 广告数据流:存储广告触达、点击、转化等事件流,为广告分析系统提供快速的随机查询及批量读取能力,助力提升广告效果分析和统计效率。
- 用户交互数据:Facebook 曾使用 HBase 存储用户交互产生的数据,例如聊天、评论、帖子、点赞等数据,并利用 HBase 构建用户内容搜索功能。
- 时序数据引擎:基于 HBase 构建适用于时序数据的存储引擎,例如日志、监控数据存储。例如 OpenTSDB(Open Time Series Database)是一个基于 HBase 的时序存储系统,适用于日志、监控打点数据的存储查询。
- 图存储引擎:基于 HBase 设计图结构的数据模型,如节点、边、属性等概念,作为图存储系统的存储引擎。例如 JanusGraph 可以基于 HBase 存储图数据。
# Hbase 数据模型的优缺点
| 优势 | 缺点 |
|---|---|
| 稀疏表友好,不存储缺省列,支持动态新增列类型 | 每条数据都要冗余存储行列信息 |
| 支持保存多版本数据 | 不支持二级索引,只能通过 rowkey 索引,查询效率依赖 rowkey 设计 |
| 支持只读取部分 column family 的数据,避免读取不必要的数据 | column family 数量较多时可能引发性能衰退 |
| 支持的数据规模相比传统关系型数据库更高,更易水平扩展 | 不支持数据类型,一律按字节数组存储 |
| 支持 rowkey 字典序批量扫描数据 | 仅支持单行内的原子性操作,无跨行事务保障 |
# 架构设计
主要组件包括:
- HMaster:元信息管理组件,以及集群调度、保活等功能。通常部署一个主节点和一到多个备节点,通过 Zookeeper 选主。
- RegionServer:提供数据读写服务,每个实例负责若干个互不重叠的 rowkey 区间内的数据。
- ThriftServer:提供 Thrift API 读写的代理层。
依赖组件包括:
- Zookeeper:分布式一致性共识协作管理,例如 HMaster 选主、任务分发、元数据变更管理等。
- HDFS:分布式文件系统,HBase 数据存储底座。
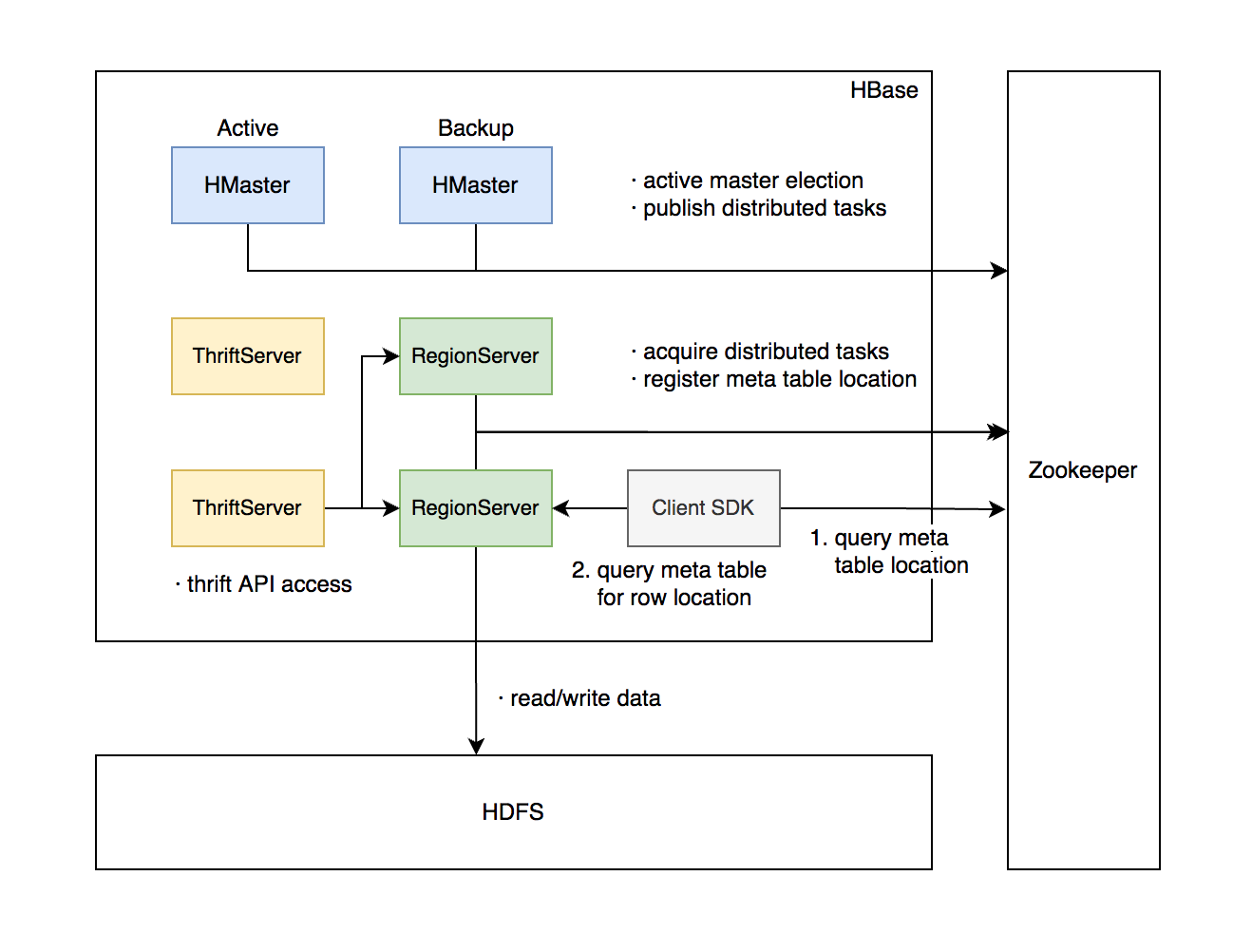
# HMaster 主要职责
- 管理 RegionServer 实例生命周期,保证服务可用性
- 协调 RegionServer 数据故障恢复,保证数据正确性
- 集中管理集群元数据,执行负载均衡等等护集群稳定性
- 定期巡检元数据,调整数据分布,清理废弃数据等
- 处理用户主动发起的元数据操作如建表、删表等
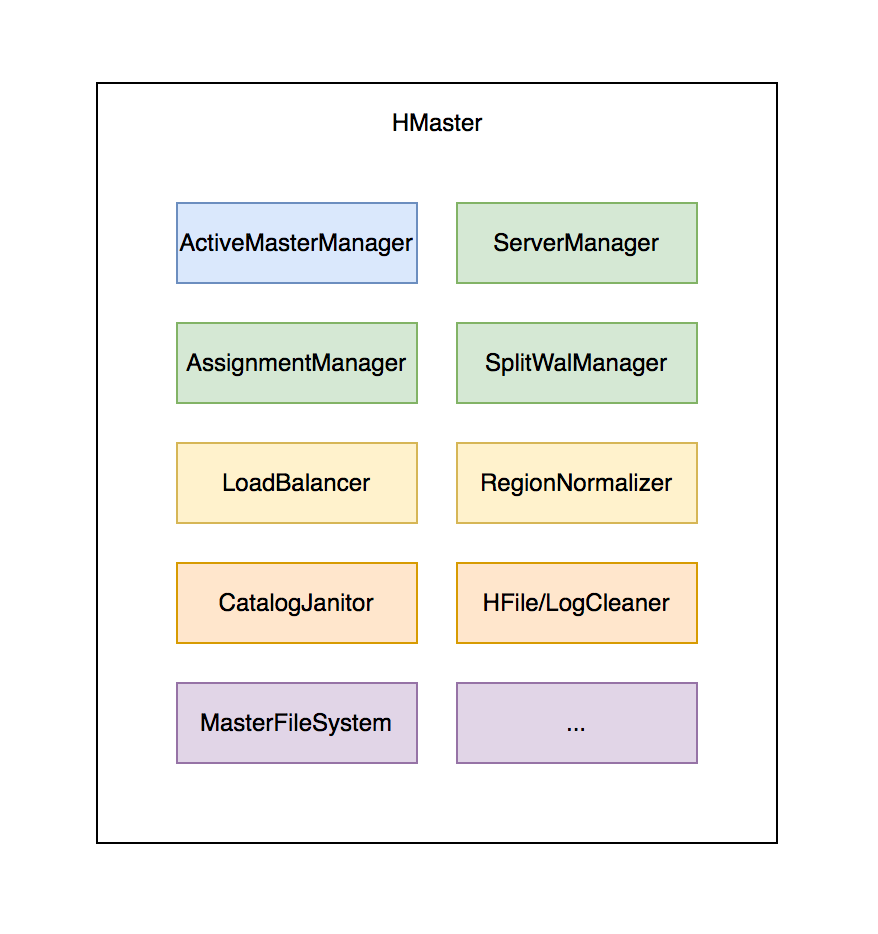
# Hmaster - 主要组件
- ActiveMasterManager:管理 HMaster 的 active/backup 状态
- ServerManager:管理集群内 RegionServer 的状态
- AssignmentManager:管理数据分片 (region)的状态
- SplitWalManager:负责故障数据恢复的 WAL 拆分工作
- LoadBalancer:定期巡检、调整集群负载状态
- RegionNormalizer:定期巡检并拆分热点、整合碎片
- CatalogJanitor:定期巡检、清理元数据
- Cleaners:定期清理废弃的 HFile / WAL 等文件 MasterFileSystem:封装访问 HDFS 的客户端 SDK
# RegionServer 主要职责
- 提供部分 rowkey 区间数据的读写服务
- 如果负责 meta 表,向客户端 SDK 提供 rowkey 位置信息
- 认领 HMaster 发布的故障恢复任务,帮助加速数据恢复过程
- 处理 HMaster 下达的元数据操作,如 region 打开 / 关闭 / 分裂 / 合并操作等
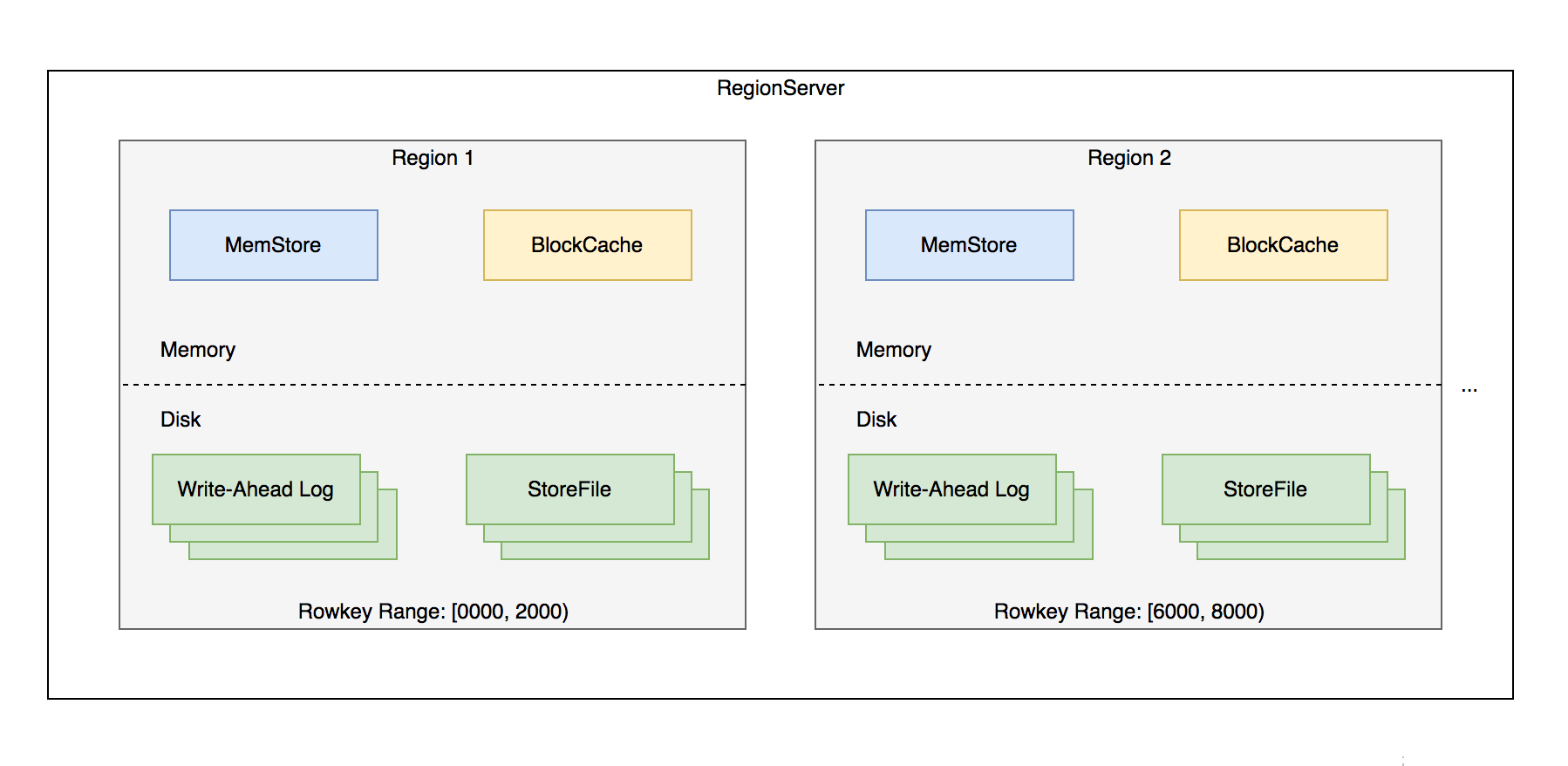
# RegionServer - 主要组件
- Memstore:基于 SkipList 数据结构实现的内存态存储,定期批量写入硬盘
- Wrrie-Ahead-Log:顺序记录写请求到持久化存储,用于故障恢复内存中丢失的数据
- Store:对应一个 Column Family 在一个 regon 下的数据集合,通常包含多个文件
- StoreFile:即 HFile,表示 HBase 在 HDFS 存储数据的文件格式,其内数据按 rowkey 字典序有序排列
- BlockCache:HBase 以数据块为单位读取数据并缓存在内存中以加速重复数据的读取
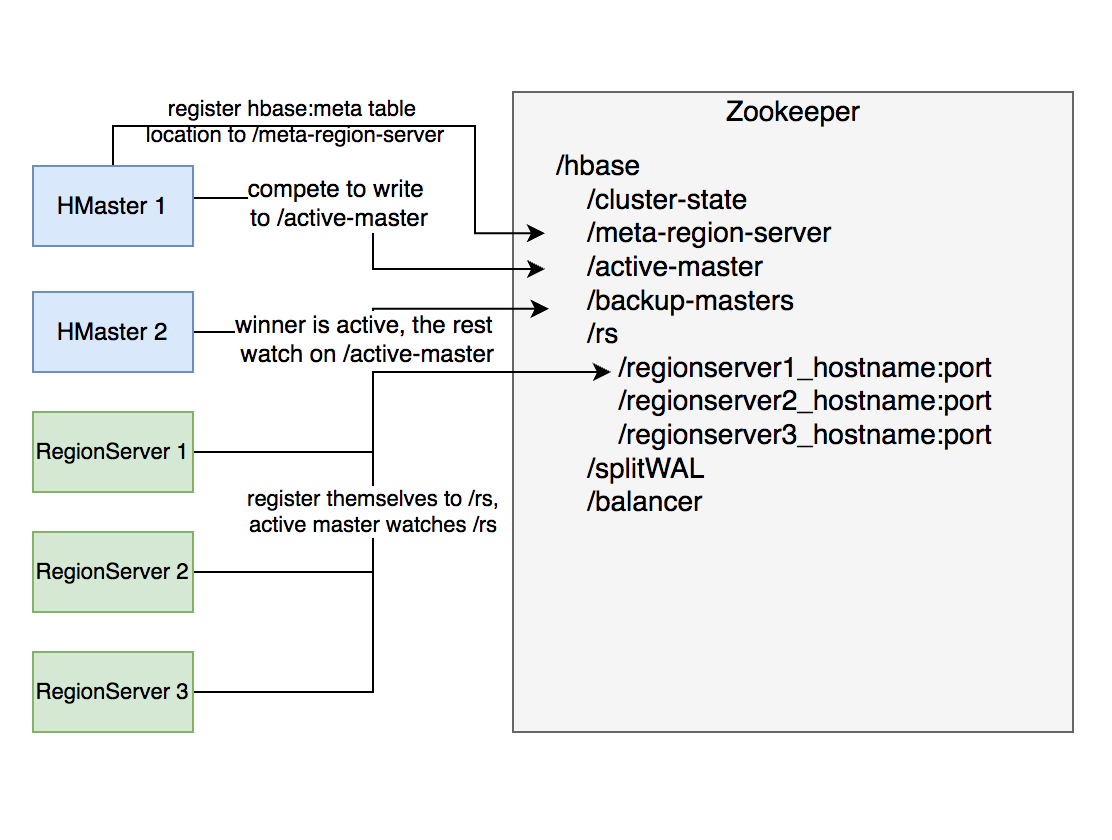
# ZooKeeper 主要职责
- HMaster 登记信息,对 active/backup 分工达成共识
- RegionServer 登记信息,失联时 HMaster 保活处理
- 登记 meta 表位置信息,供 SDK 查询读写位置信息
- 供 HMaster 和 RegionServer 协作处理分布式任务
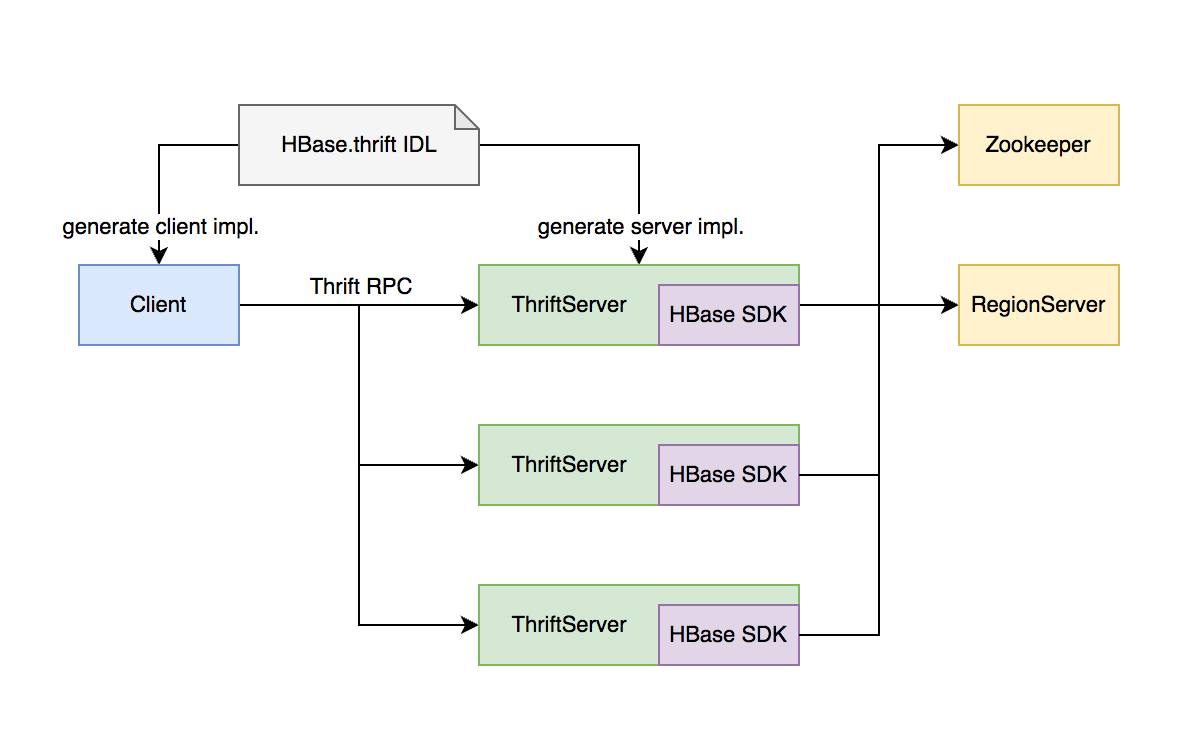
# ThriftServer 主要职责
- 实现 HBase 定义的 Thrift API,作为代理层向用户提供 RPC 读写服务
- 用户可根据 IDL 自行生成客户端实现
- 独立于 RegionServer 水平扩展,用户可访问任意 ThriftServer 实例 (scan 操作较特殊,需要同实例维护 scan 状态)
# 大数据支撑
# HBase 在大数据生态的定位
- 对 TB、PB 级海量数据支持强一致、近实时的读写性能,支持快速的 ad-hoc 分析查询任务;
- 支持字典序批量扫描大量数据,支持只读取部分列族的数据,灵活支持不同查询模式,避免读取不必要的数据;
- 存储大规模任务(例如 MapReduce,Spark, Flink)的中间 / 最终计算结果;
- 平滑快速的水平扩展能力,能够敏捷应对大数据场景高速增长的数据体量和大规模的并发访问;
- 精细化的资源成本控制,计算层和存储层分别按需扩展,避免资源浪费。
# 水平扩展能力
- 增加 RegionServer 实例,分配部分 region 到新实例。
- 扩展过程平滑,无需搬迁实际数据。
- 可用性影响时间很短,用户基本无感知。
# Region 热点切分
- 当某个 region 数据量过多,切分成两个独立的子 region 分摊负载。
- RegionServer 在特定时机 (flush、compaction)检查 region 是否应该切分,计算切分点并 RPC 上 HMaster,由 AssignmentManager 负责执行 RegionStateTransition
- 不搬迁实际数据,切分产生的新 region 数据目录下生成一个以原 region 文件信息命名的文件,内容是切分点对应的 rowkey,以及标识新 region 是上 / 下半部分的数据。
# 切分点选取
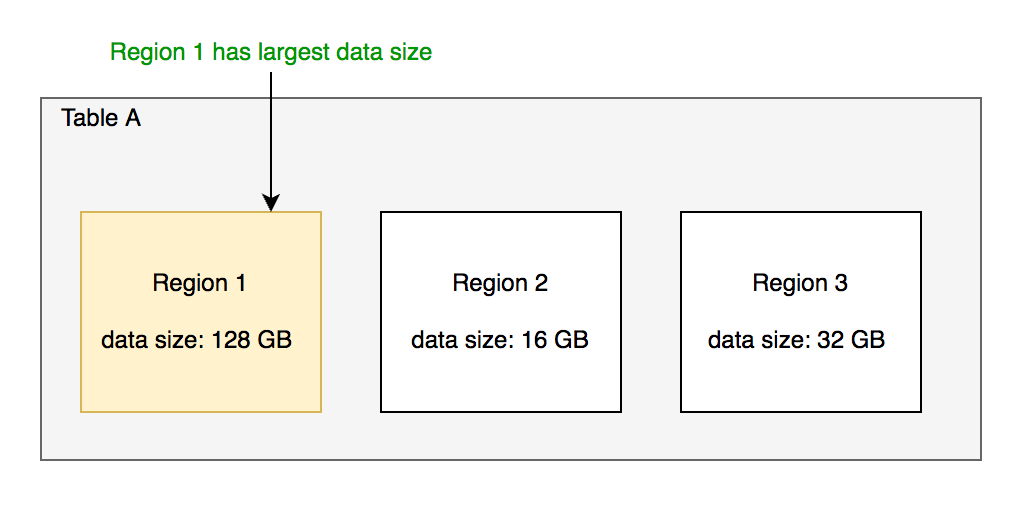
HBase 原生提供的多种切分策略使用相同的切分点选择策略。 目标:优先把最大的数据文件均匀切分。
切分点选择步骤:
找到该表中哪个 region 的数据大小最大
找到该 region 内哪个 column family 的数据大小最大
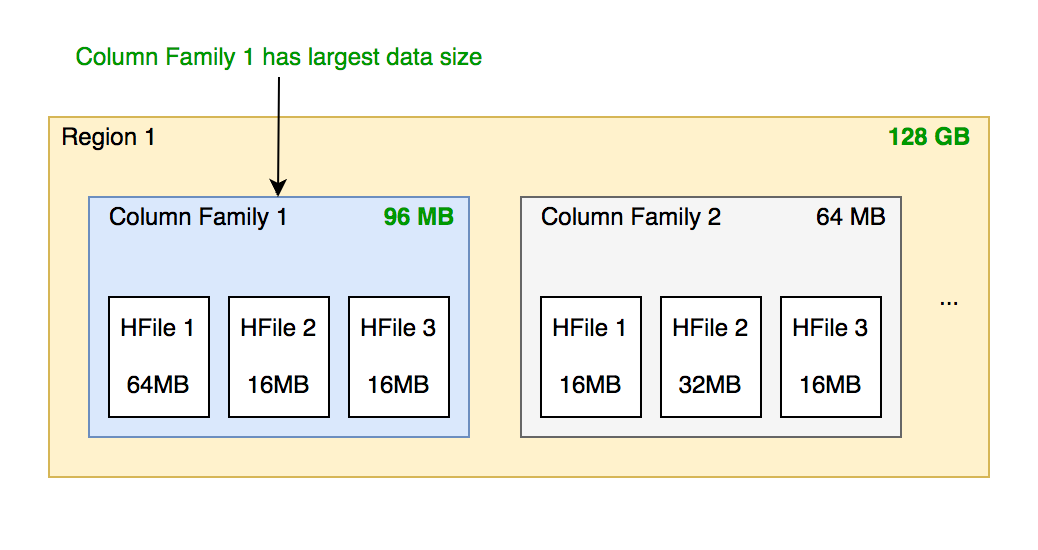
找到 column family 内哪个 HFile 的数据大小最大
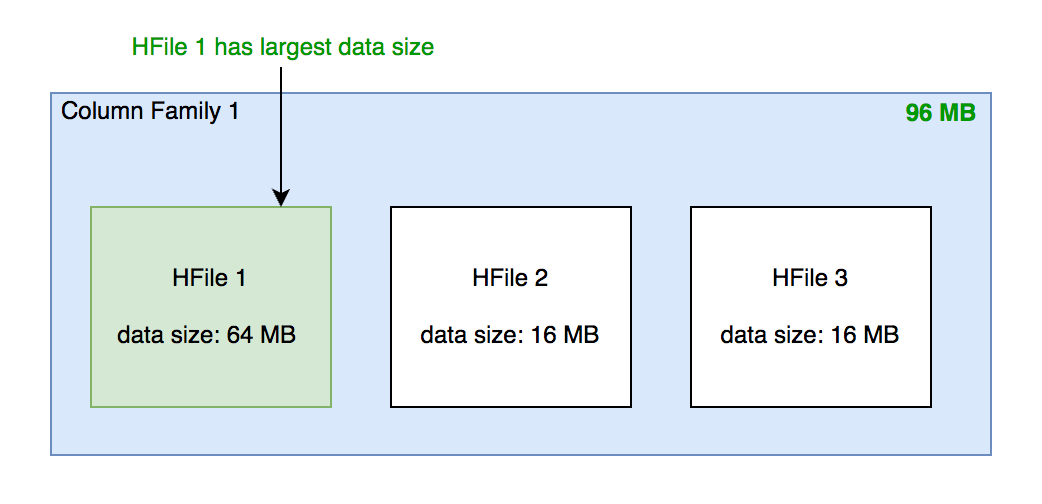
- 找到 HFile 里处于最中间位置的 Data Block
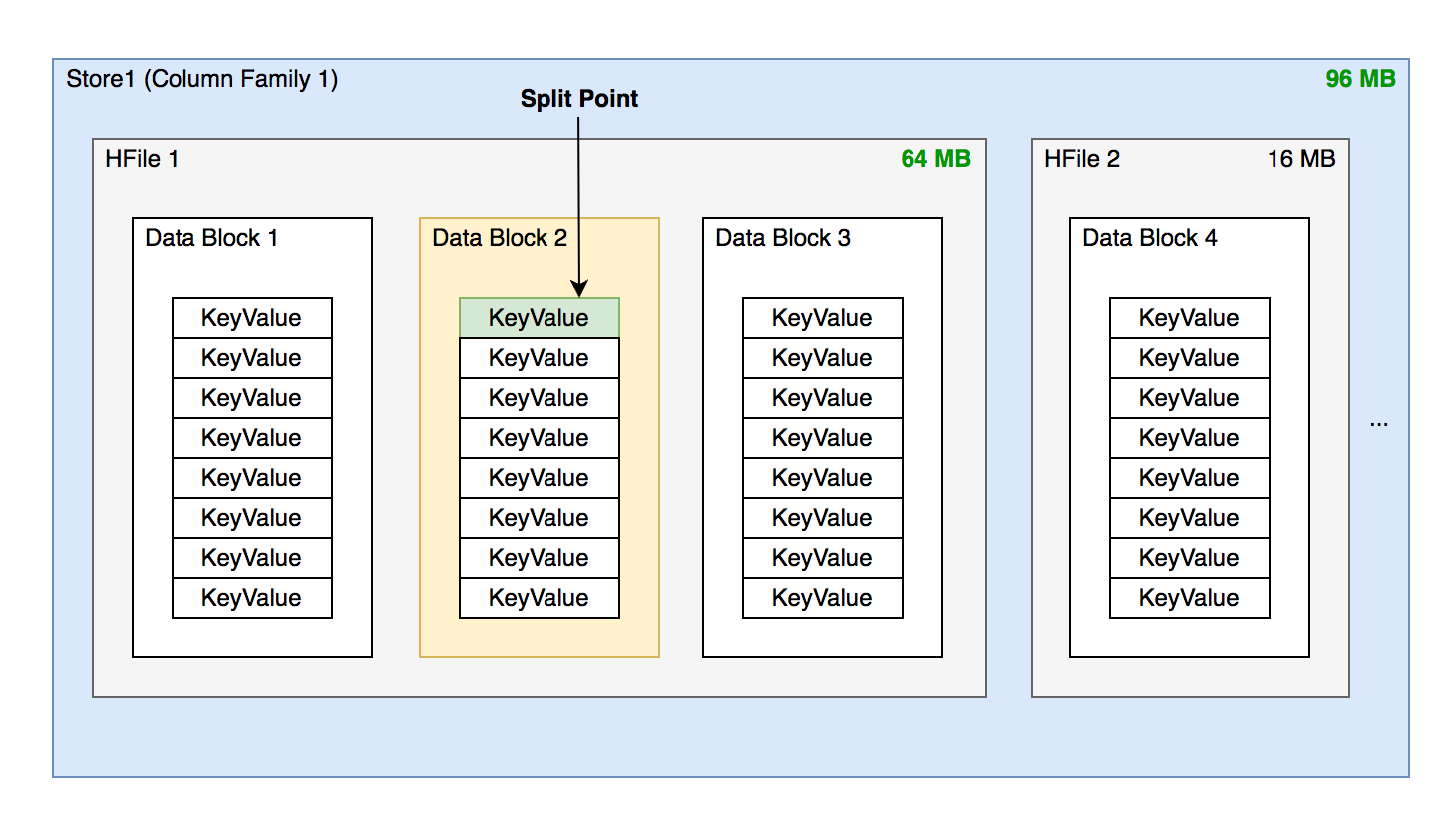
- 用这个 Data Block 的第一条 KeyValue 的 Rowkey 作为切分点。
- 找到 HFile 里处于最中间位置的 Data Block
# 切分过程
- 所有 Column Family 都按照统一的切分点来切分数据。
- 目的是优先均分最大的文件,不保证所有 ColumnFamily 的所有文件都被均分。
- HFile 1 作为最大的文件被均分,其他文件也必须以相同的 rowkey 切分以保证对齐新 region 的 rowkey 区间。
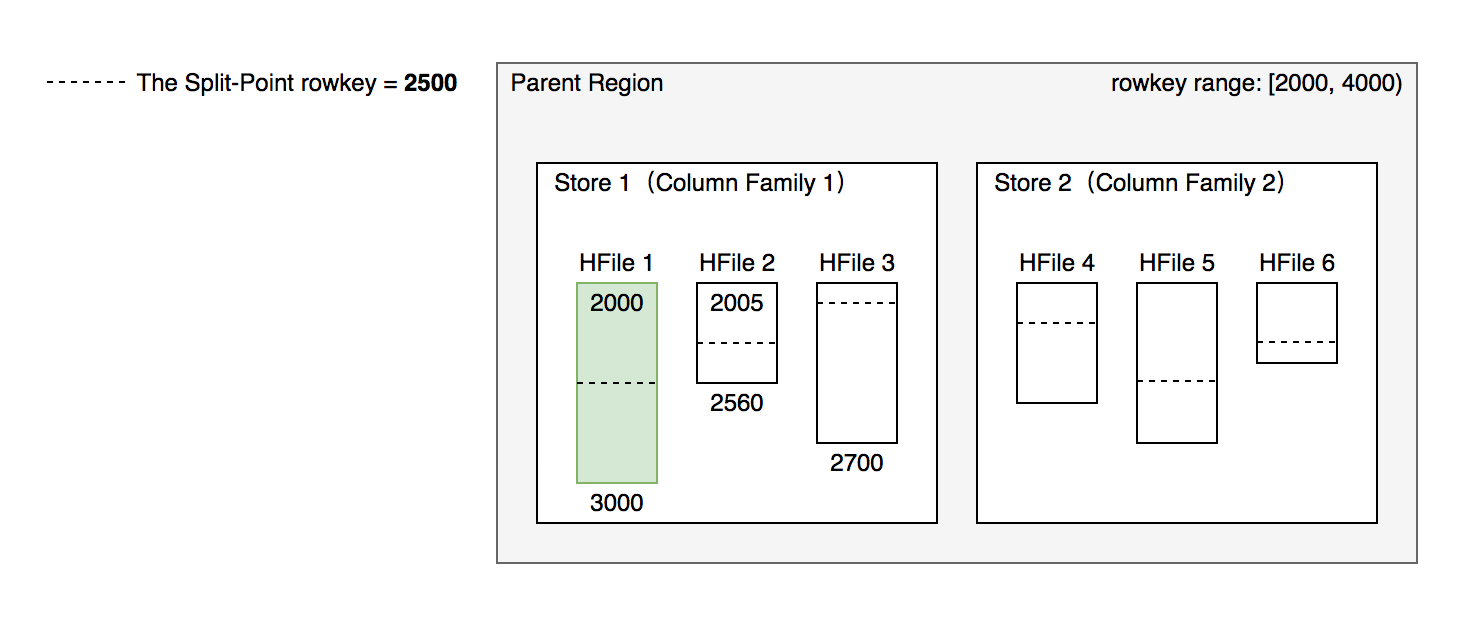
- 切分出的新 region 分别负责 rowkey 区间 [2000,2500) 和 [2500,4000)。
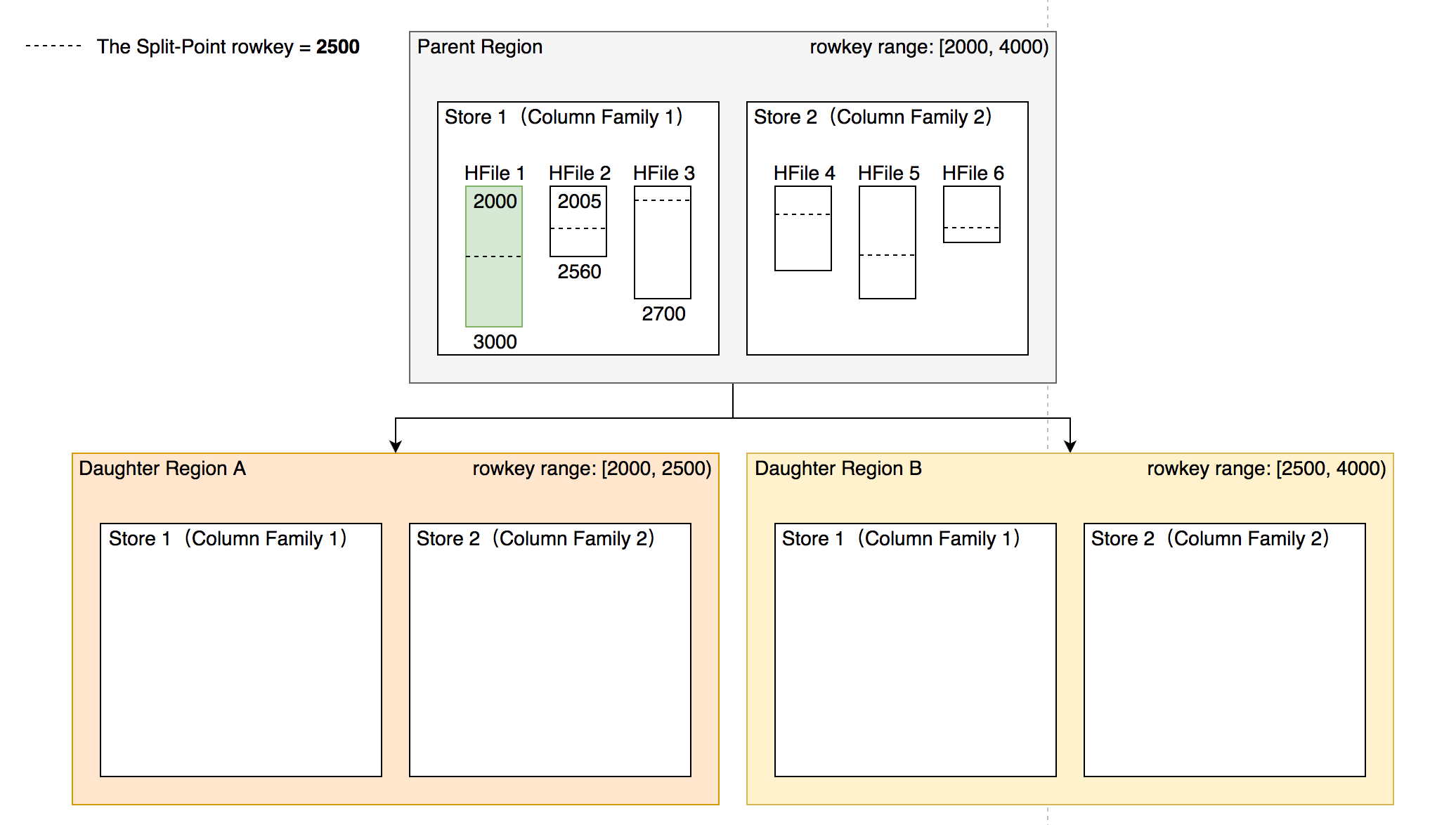
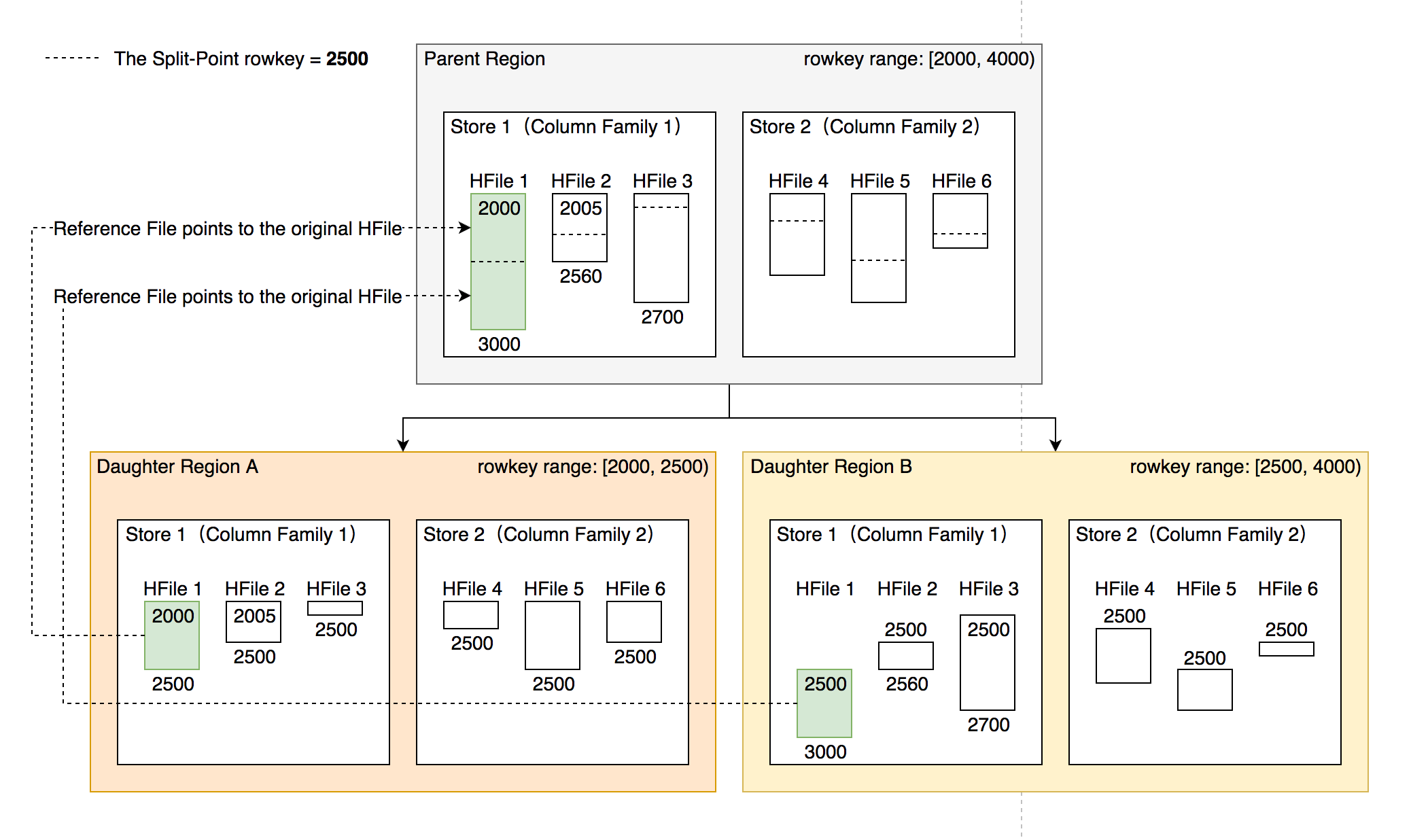
- 每个新 region 分别负责原 region 的上下下半部分 rowkey 区间的数据。
- 在 compaction 执行前不实际切分文件,新 region 下的文件通过 reference fle 指向原文件读取实际数据。
# 流程设计
AssianmentManaaer cluster、 table、reaion 的状态后,创建 SplitTableReaionProcedu 通过状态机实现执行切分过程
| 状态名称 | 执行操作 |
|---|---|
| SPLIT_TABLE_REGION_PREPARE | 检查是否满足切分条件 |
| SPLIT_TABLE_REGION_PRE_OPERATION | 调用相关 coprocessor 方法,检查 quota |
| SPLIT_TABLE_REGION_CLOSE_PARENT_REGION | 关闭待切分 region 并确认执行成功 |
| SPLIT_TABLE_REGION_CREATE_DAUGHTER_REGIONS | 创建切分目标 regions 临时目录,并行切分每个文件,创建 reference fle 和 regioninfo 元数据文件,最终移动到正式目录下。 |
| SPLIT_TABLE_REGION_WRITE_MAX_SEQUENCE_ID_FILE | 将原 region 的 maxSequencelD 写入新 regions |
| SPLIT_TABLE_REGION_UPDATE_META | 标记原新 region 状态为 SPLIT/SPLITTING_NEW,在 hbase:meta 表更新原 新 region 状态为 Offline/Closed |
| SPLIT_TABLE_REGION_OPEN_CHILD_REGIONS | 打开新 regions 正式提供读写服务 |
# Region 碎片整合
- 当某些 region 数据量过小、碎片化,合并相邻邻 region 整合优化数据分布。
- AssignmentManager 创建 MergeTableRegionsProcedure 执行整合操作。
- 不搬迁实际数据,通过 reference file 定位原 region 的文件,直到下次 compaction 时实际处理数据。
注意:只允许合并相邻 region,否则会打破 rowkey 空间连续且不重合的约定。
# 流程设计
类似于 region 切分,不立刻处理实际数据文件,而是通过创建 reference files 引 I 用到原文件,然后原子地更新元数据来完成碎片整合,后续靠 compaction 整合数据文件,靠 CatalogJanitor 异步巡检元数据处理遗留数据。
| 状态名称 | 执行操作 |
|---|---|
| MERGE_TABLE_REGIONS_PREPARE | 检查是否满足整合条件,清理上次整合余留的数据,设置 region 状态为 MERGING |
| MERGE_TABLE_REGIONS_CLOSE_REGIONS | 关闭待整合的 regions,确认成功完成 |
| MERGE_TABLE_REGIONS_CREATE_MERGED_REGiON | 在首个待整合 region 的目录下创建临时目录,记录待整合 regions 的所有文件路径的 reference file , 都成功后 move 临时目录内容到新 region 的正式目录下,新 region 状态标记为 MERGING_NEW |
| MERGE_TABLE_REGIONS_WRITE_MAX_SEQUENCE_ID_FILE | 遍历所有待整合 regions 找到最大的 sequencelD,记为新 region 的 sequencelD |
| MERGE_TABLE_REGIONS_UPDATE_META | 新 region 状态设为 MERGED,异步安全删除原 regions 目录,原子地更新 hbase:meta 表中新 region 为 Closed 状态,删除原 regions 记录 |
| MERGE_TABLE_REGIONS_OPEN_MERGED_REGION | 调度打开整合出的新 region,开始提供读写服务 |
# Region 负载均衡
定期巡检各 RegionServer 上的 region 数量,保持 region 的数量均匀分布在各个 RegionServer 上。
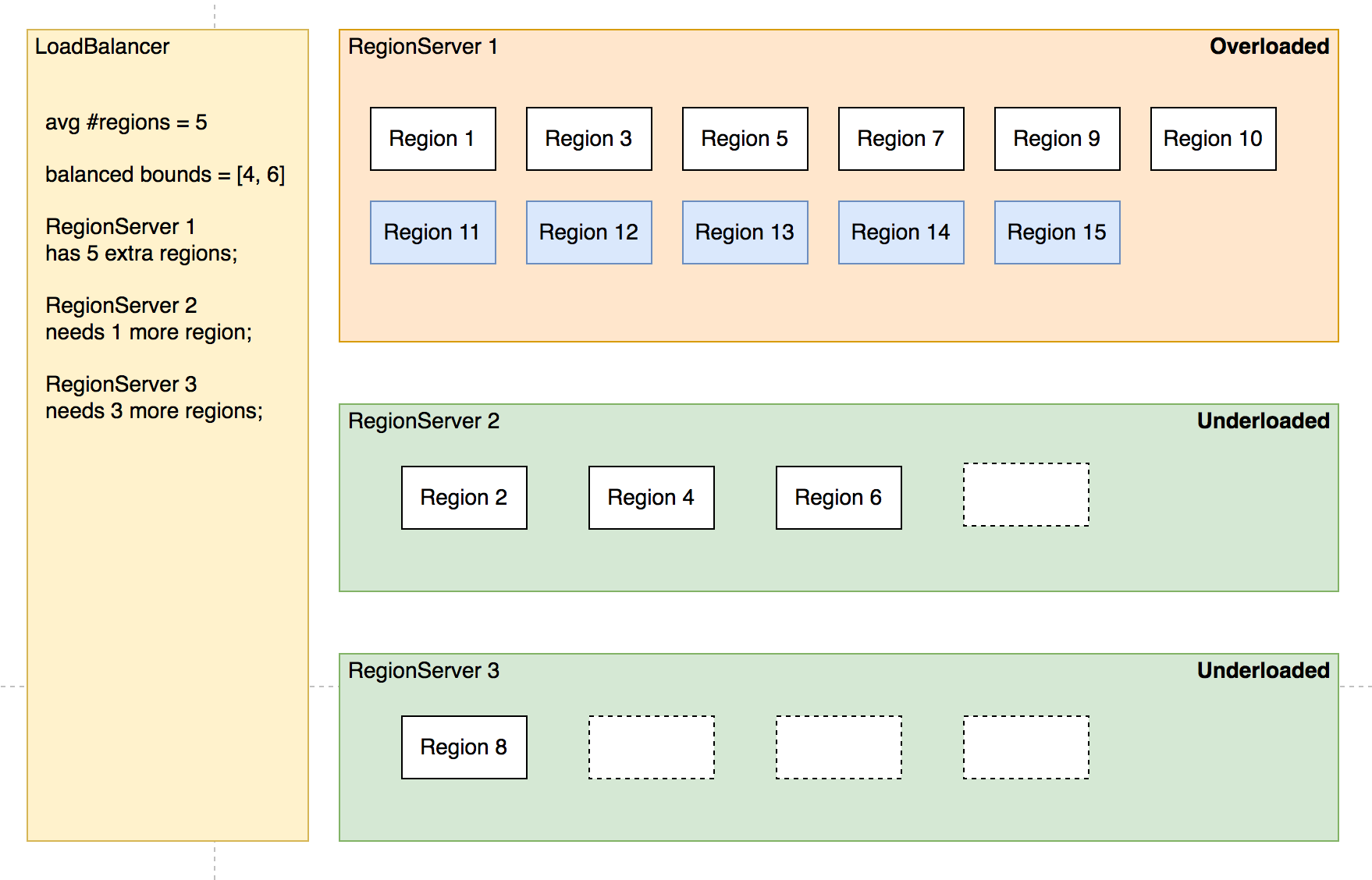
SimpleLoadBalancer 具体步骤:
- 根据总 region 数量和 RegionServer 数量计算平均 region 数,设定弹性上下界避免不必要的操作。例如默认 slop 为 0.2,平均 region 数为 5, 负载均衡的 RS 上 region 数量应该在 [4,6] 区间内。
- 将 RegionServer 按照 region 数量降序排序,对 region 数量超出上限的选取要迁出的 region 并按创建时间从新到老排序;
# 调度策略
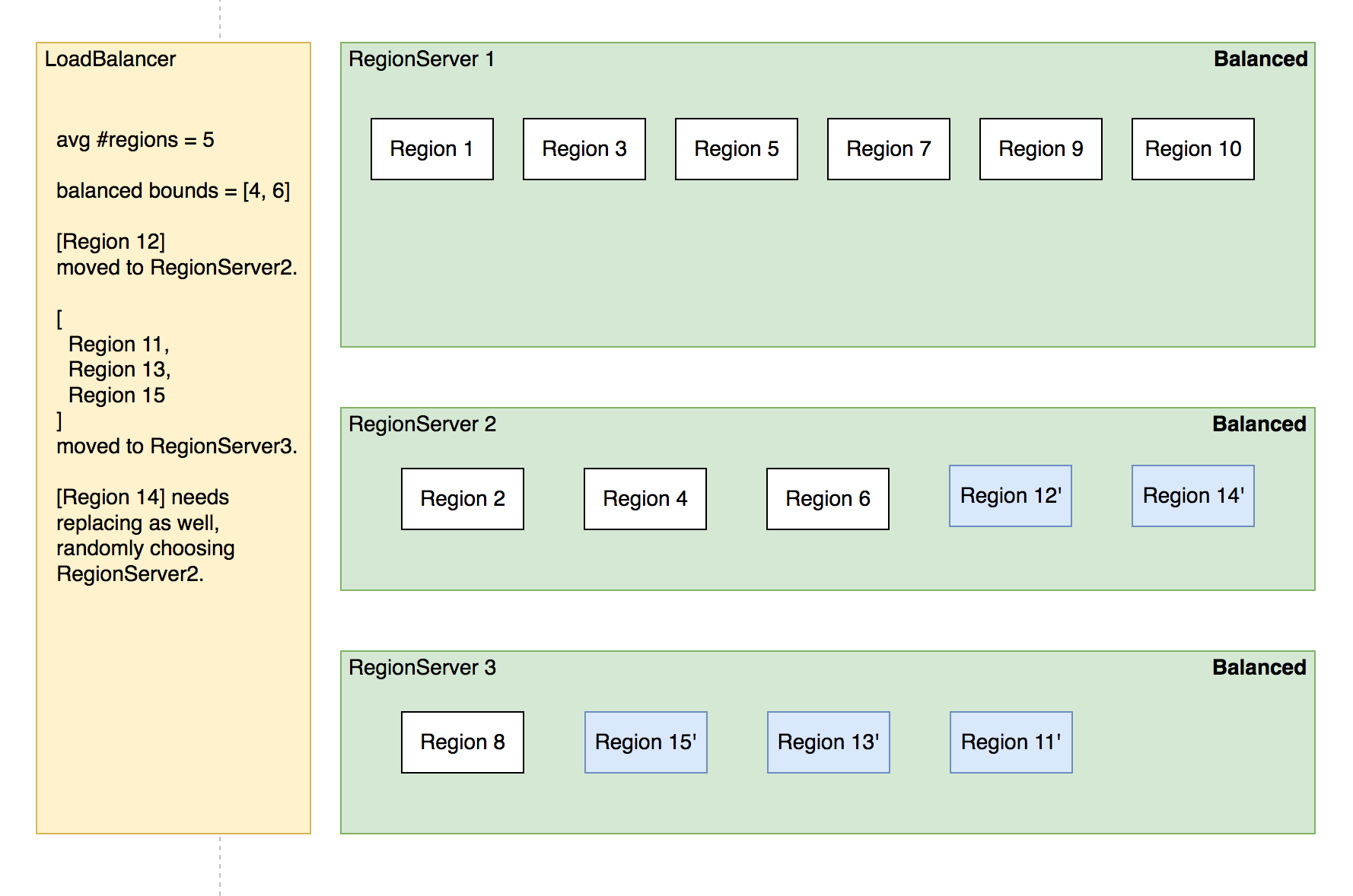
simpleLoadBalancer 具体步骤:
- 选取出 region 数量低于下限的 RegionServer 列表,round-robin 分配步骤 2 选取的 regions, 尽量使每个 RS 的 region 数量都不低于下限;
- 处理边界情况,无法满足所有 RS 的 region 数量都在合理范围内时,尽量保持 region 数量相近。
# 其他策略
StochasticLoadBalancer
- 随机尝试不 region 放直策略,根据提供的 cost function 计算不同策略的分值排名 (0 为最优策略,1 为最差策略);
- cost 计算将下列指标纳入统计:region 负载、表负载、数据本地性(本地访问 HDFS)、Memstore 大小、HFile 大小。
- 根据配置加权计算最终 cost,选择最优方案进行负载均衡;
FavoredNodeLoadBalancer
- 用于充分利用本地读写 HDFS 文件来优化读写性能。
- 每个 region 会指定优选的 3 个 RegionServer 地址 同时会告知 HDFS 在这些优选节点上放置该 region 的数据;
- 即使第一节点出现故障,HBase 也可以将第二节点提升为第一节点,保证稳定的读时延;
# 故障恢复机制 - HMaster
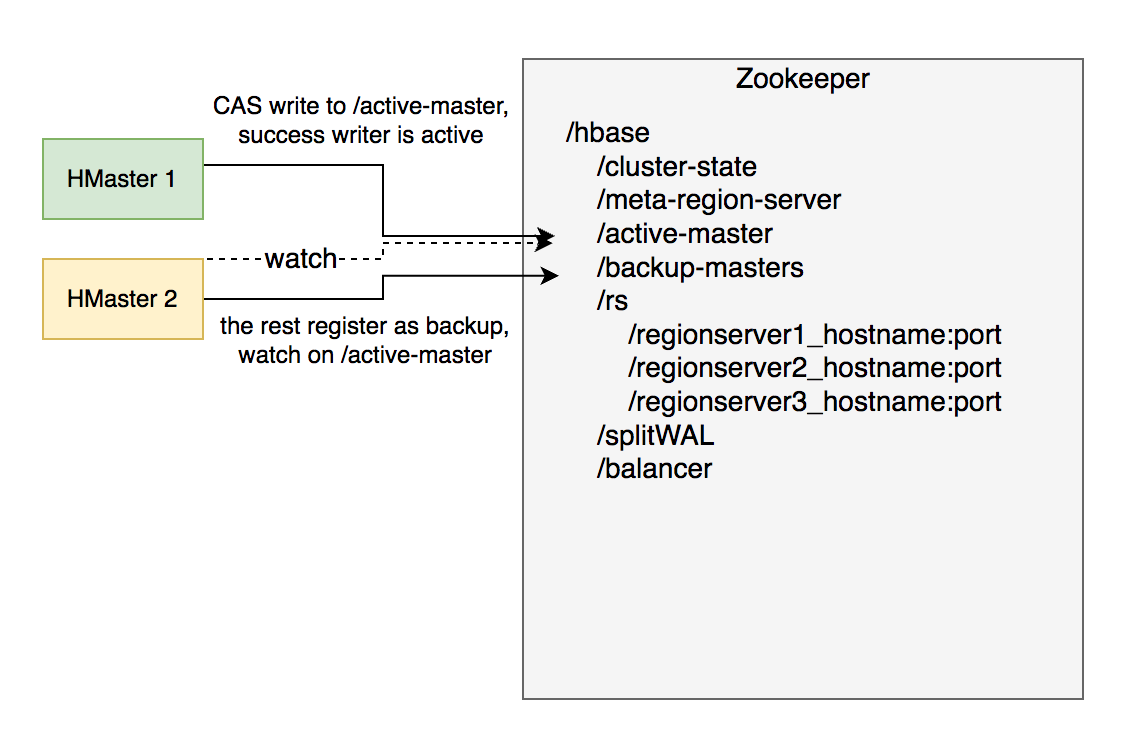
HMaster 通过多实例基于 Zookeeper 选主实现高可用性。
- 所有实例尝试向 Zookeeper 的
/hbase/active-master临时节点 CAS 地写入自身信息 - 写入成功表示成为主实例,失败即为从实例,通过 watch 监听
/hbase/active-master节点的变动。 - 主实例不可用时临时节点被删除,此时触发其他从实例重新尝试选主。
# HMaster 恢复流程
- HMaster 自身恢复流程:
- 监听到 /hbase/active-master 临时节点被删除的事件,触发选主逻辑;
- 选主成功后执行 HMaster 启动流程,从持久化存储读取未完成的 procedures 从之前状态继续执行;
- 故障 HMaster 实例恢复后发现主节点已存在,继续监听 /hbase/active-master。
- 调度 RegionServer 的故障恢复流程:
- AssignmentManager 从 procedure 列表中找出 Region-In-Transition 状态的 region 继续调度过程;
- RegionServerTracker 从 Zookeeper 梳理 online 状态的 RegionServer 列表,结合 ServerCrashProcedure 列表、HDFS 中 WAL 目录里 alive /splitting 状态的 RegionServer 记录,获取掉线 RegionServer 的列表,分别创建 ServerCrashProcedure 执行恢复流程。
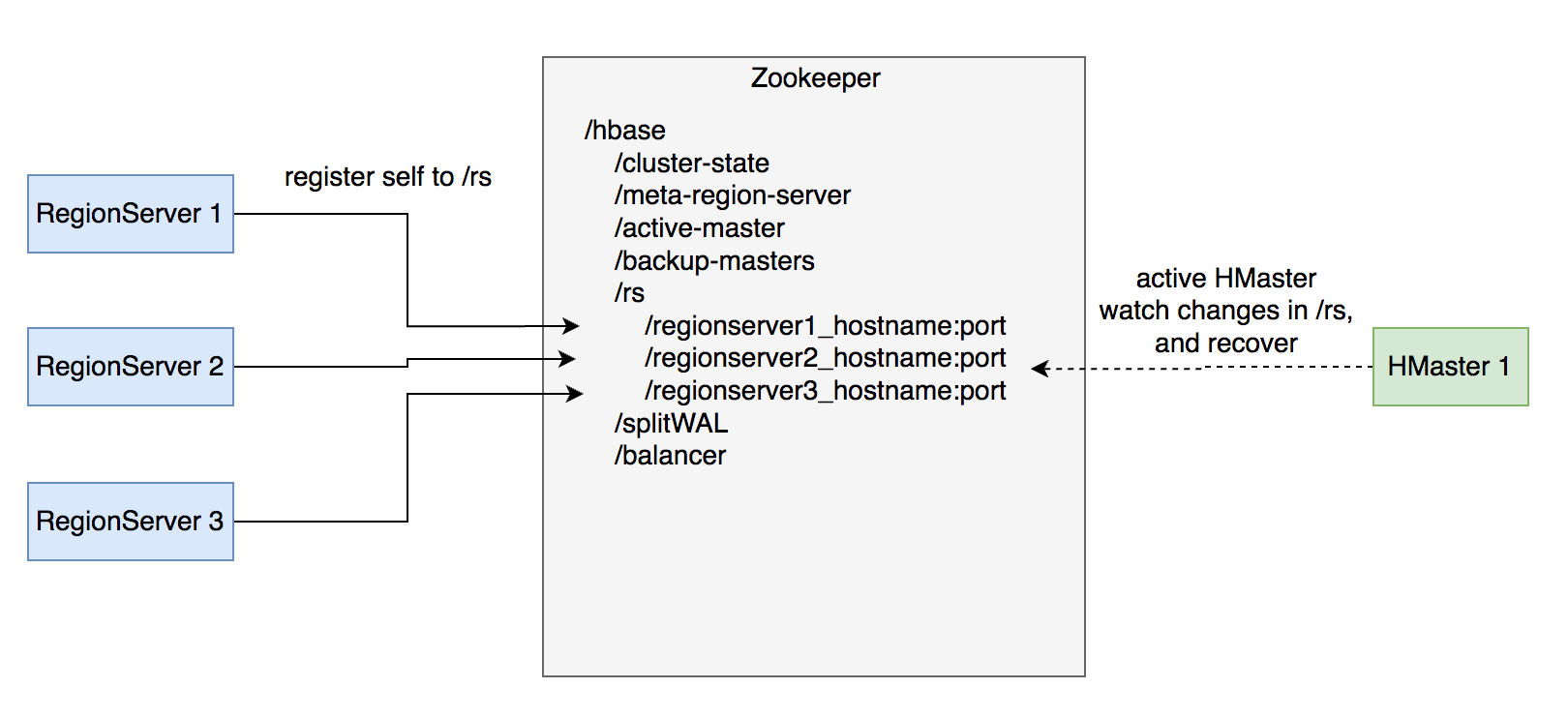
# 故障恢复机制 - RegionServer
- 每个 RegionServer 实例启动时都会往 Zookeeper 的 /hbase/rs 路径下创建对应的临时节点。
- HMaster 通过监听 RegionServer 在 Zookeeper 的临时节点状态,监控数据读写服务的可用性,及时调度恢复不可用的 regions。
- RegionServer 的故障恢复需要将内存中丢失的数据从 WAL 中恢复,HMaster 利用 Zookeeper 配合所有 RegionServer 实例,分布式地处理 WAL 数据,提升恢复速度。
# RegionServer 恢复流程
启动流程:
- 启动时去 Zookeeper 登记自身信息,告知主 HMaster 实例有新 RS 实例接入集群
- 接收和执行来自 HMaster 的 region 调度命令
- 打开 region 前先从 HDFS 读取该 region 的 recovered.edits 目录下的 WAL 记录,回放恢复数据
- 恢复完成,认领 Zookeeper 上发布的分布式任务(如 WAL 切分)帮助其他数据恢复
# Distributed Log Split 原理
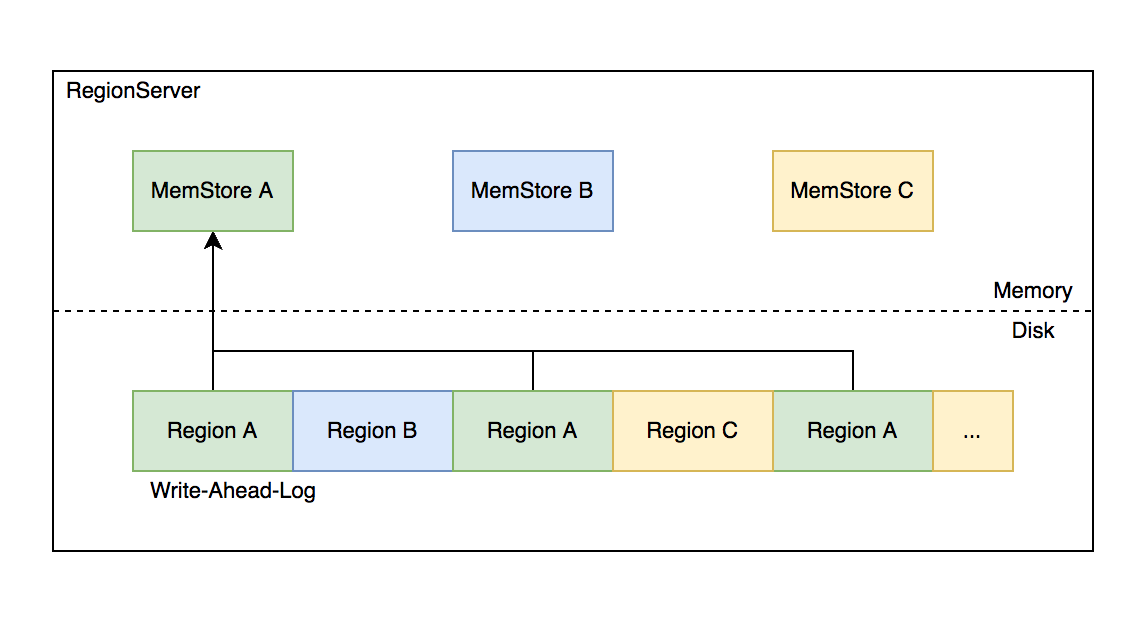
背景:
- 写入 HBase 的数据首先顺序持久化到 Write-Ahead-Log,然后写入内存态的 MemStore 即完成,不立即写盘,RegionServer 故障会导致内存中的数据丢失,需要回放 WAL 来恢复;
- 同 RegionServer 的所有 region 复用 WAL,因此不同 region 的数据交错穿插,RegionServer 故障后重新分配 region 前需要先按 region 维度折分 WAL。
# 具体流程
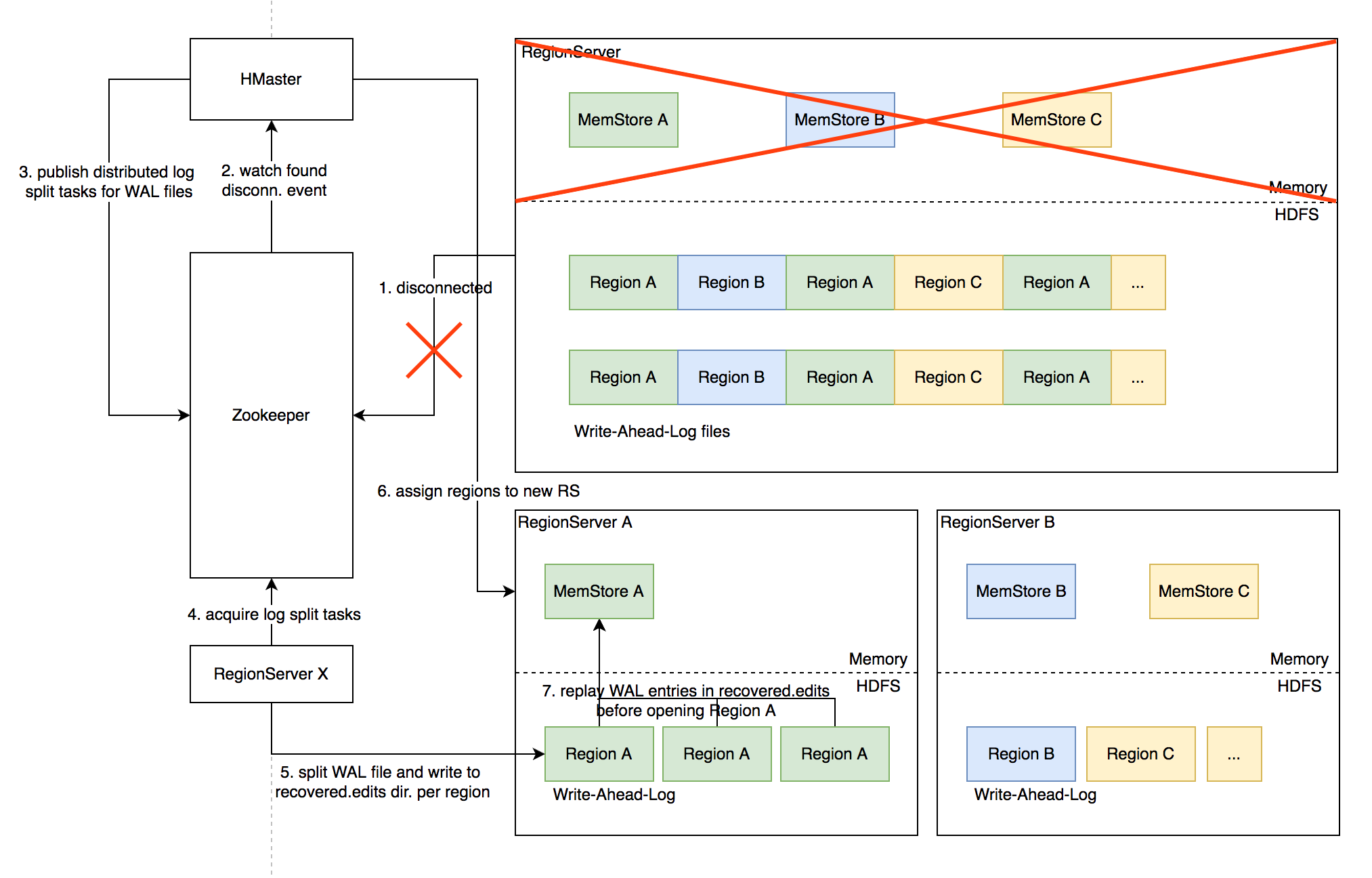
- RegionServer 故障,Zookeeper 检测到心跳超时或连接断开,删除对应的临时节点并通知监听该节点的客户端
- active HMaster 监听到 RS 临时节点删除事件,从 HDFS 梳理出该 RS 负责的 WAL 文件列表
- HMaster 为每个 WAL 文件发布一个 log split task 到 ZK
- 其他在线的 RS 监听到新任务,分别认领
- 将 WAL entries 按 region 折分,分别写入 HDFS 上该 region 的 recovered.edits 目录
- HMaster 监听到 log split 任务完成,调度 region 到其他 RS
- RS 打开 region 前在 HDFS 找到先回放 recovered.edits 目录下的 WAL 文件将数据恢复到 Memstore 里,再打开 region 恢复读写服务
# 优化空间
进一步优化:Distributed Log Replay
- HMaster 先将故障 RegionServer 上的所有 region 以 Recovering 状态调度分配到其他正常 RS 上;
- 再进行类似 Distributed Log Split 的 WAL 日志按 region 维度切分;
- 切分后不写入 HDFS,而是直接回放,通过 SDK 写流程将 WAL 记录写到对应的新 RS;
- Recovering 状态的 region 接受写请求但不提供读服务,直到 WAL 回放数据恢复完成。
# 最佳实践
# Rowkey 设计策略
场景分类:
- 不需要顺序扫描批量连续 rowkey
- 对原始 rowkey 做哈希(如 MD5),作为真实 rowkey 的前缀。建议取适当长度的子串,避免过多占用存储空间。
- 需要顺序扫描批量连续 rowkey
- 首先用 grouplD/applD/userlD 前缀避免数据热点,然后加上定义顺序的信息(如时间戳等) ID 前缀也建议哈希处理,避免非预期的热点。e.g. MD5 (grouplD):grouplD:timestamp:…
- rowkey 长度尽量保持较短,因为会冗余存储到每个 KeyValue 中。
避免用时间戳直接作为 rowkey 前缀,会导致最新的数据始终集中在单个 RegionServer 上,造成热点瓶颈,无法通过水平扩容缓解。
# Column Family 设计策略
- Column family 数量过多容易影响性能,建议尽量少,不超过 5 个。
- 需要同时读取的数据尽量放在相同列族,反之尽量放在不同列族,读取时尽量只读取必需的列族,避免读不必要的列族。
- 列族(以及 column qualifier)名称尽量短,因为会冗余存储到每个 KeyValue 中。
# 参数调优
| 参数名称 | 参数作用 | 建议值 |
|---|---|---|
| hbase.regionserver.handler.count | 处理 RPC 请求的线程数量 | 2*CPU 核数 |
| hfile.block.cache.size | RegionServer 的 block cache 大小上限,为最大堆大小的比例 | 读多写少的场景可以适当调高 |
| hbase.hstore.blockingStoreFiles | 单列族下 HFile 文件数量上限,超过会阻塞写请求,直到 compaction 使数量下降 | 设置较大的值例如 100, 避免频繁阻塞写入的情况 |
| hbase.rpc.timeout | RPC 请求超时时间 | 建议调大到 5min,因为集群异常状态下 RPC 耗时可能很高,超时太短会导致故障恢复相关 RPC 频繁超时无法恢复 |
| hbase.regionserver.wal.max.splitters | 切分 WAL 的线程数 | 建议设置为最大 WAL 文件数量(默认 32) |
| hbase.regionserver.hlog.splitlog.writer.threads | 将切分后的 WAL 批量写盘的线程数 | 建议调大到 50 来加速故障恢复 |
| hbase.master.executor.openregion.threads | HMaster 用于 openRegion 操作的线程数 | 2 * CPU 核数 |
| hbase.regionserver.executor.openregion.threads | RegionServer 打开 region 的线程数 | 2*CPU 核数 |
| hbase.regionserver.metahandler.count | 处理元数据操作的线程数 | 建议调大为 5*CPU 核数或 400 |
| -XX:+UseG1GC | JVM 垃圾回收器类型 | 堆大于 8GB 建议用 G1GC,反之用 CMS |