栈和队列
栈和队列
# 栈和队列
# 栈
# 栈的定义
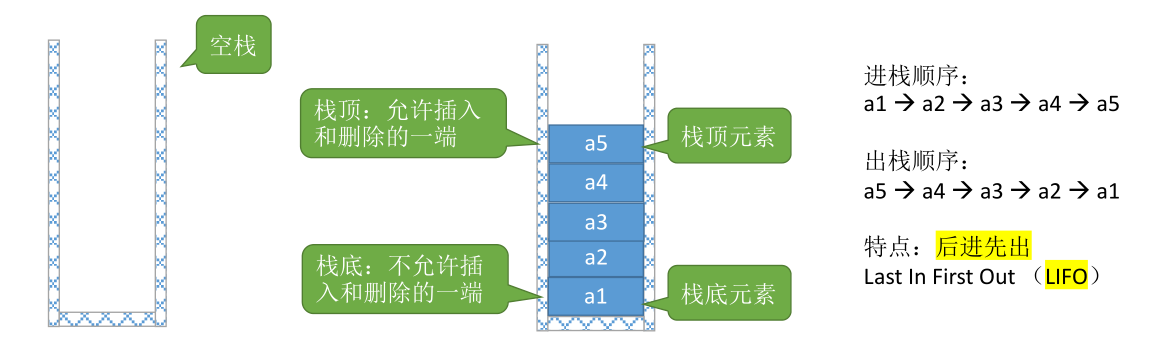
栈(Stack):是只允许在一端进行插入或删除操作的线性表
# 栈的基本操作
InitStack(&S):初始化栈。构造一个空栈 S,分配内存空间。DestroyStack(&S):销毁栈。销毁并释放栈 S 所占用的内存空间。Push(&S,x):进栈,若栈 S 未满,则将 x 加入使之成为新栈顶。Pop(&S,&x):出栈,若栈 S 非空,则弹出栈顶元素,并用 x 返回。GetTop(S, &x):读栈顶元素。若栈 S 非空,则用 x 返回栈顶元素
其他常用操作:
StackEmpty(S):判断一个栈 S 是否为空。若 S 为空,则返回 true,否则返回 false。
# 顺序栈
# 定义
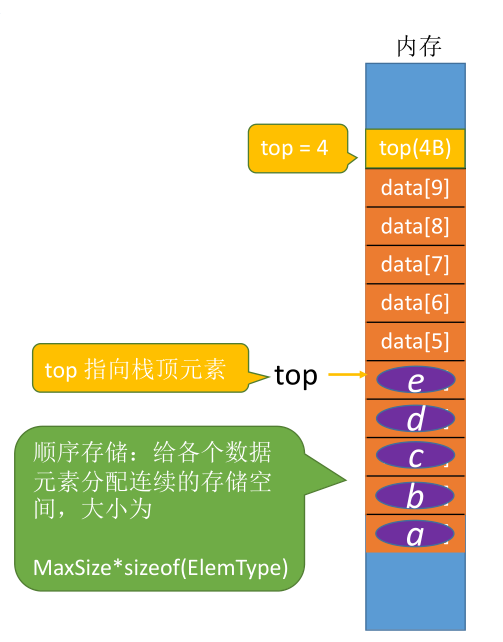
#define MaxSize 10
typedef struct {
ElemType data[MaxSize];
int top; //栈顶指针
} SqStack;
void initStack(SqStack &S) {
S.top = -1; //初始化栈顶指针
}
bool SqStackEmpty(SqStack S) {
if (S.top == -1) {
return true;
} else {
return false;
}
}
void testStack() {
SqStack S; //声明一个顺序栈(分配空间)
initStack(S);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 进栈
//入栈
bool Push(SqStack &S, ElemType x) {
if (S.top == MaxSize - 1) { //栈满,报错
return false;
}
S.top = S.top + 1; //指针先加1
S.data[S.top] = x; //新元素入栈
return true;
}
2
3
4
5
6
7
8
9
# 出栈
//出栈
bool Pop(SqStack &S, ElemType &x) {
if (S.top == -1) {
return false;
}
x = S.data[S.top]; //栈顶元素先出栈
S.top = S.top - 1; //指针再减1
return true;
}
2
3
4
5
6
7
8
9
# 查看栈顶
//查看栈顶
bool GetTop(SqStack S, ElemType &x) {
if (S.top == -1) {
return false;
}
x = S.data[S.top]; //x记录栈顶元素
return true;
}
2
3
4
5
6
7
8
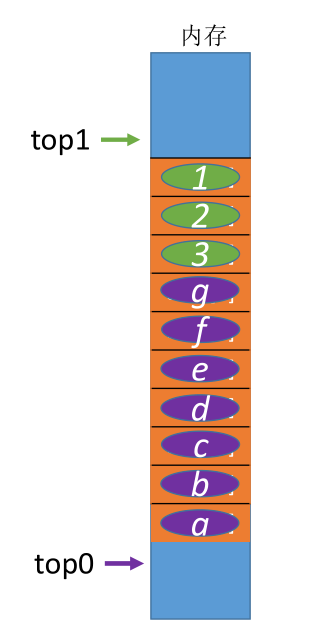
# 共享栈
两个栈共享同一片空间,0 号栈从下往上压栈,而 1 号栈从上往下压栈,两个栈从两边往中间增长。
#define MaxSize 10
typedef struct {
ElemType data[MaxSize];
int top0; //0号栈顶指针
int top1; //1号栈顶指针
} SqStack;
// 初始化栈
void initStack(SqStack &S) {
S.top0 = -1; //初始化栈顶指针
S.top1 = MaxSize;
}
//判定共享栈是否已经满
bool SqStackEmpty(SqStack S) {
if (S.top0 + 1 == S.top1) {
return true;
} else {
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 总结
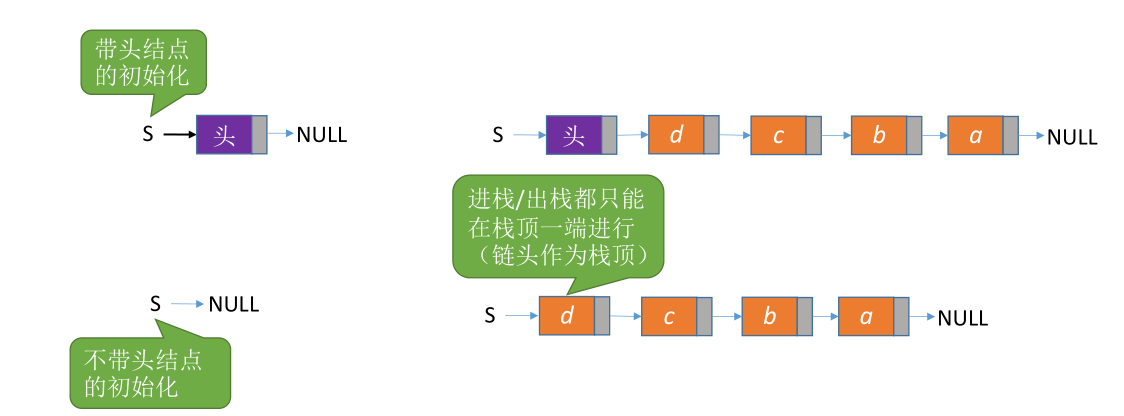
# 链栈
# 定义
typedef struct Linknode {
ElemType data;
struct Linknode *next; //指针域
}*LiStack; //栈类型定义
2
3
4
# 总结
# 队列
# 队列的定义
队列(Queue):是只允许在一端进行插入,在另一端删除的线性表。
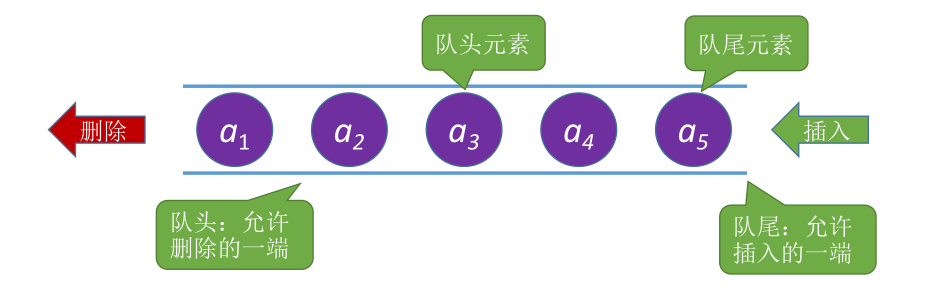
队列的特点:先进先出;First In First Out(FIFO)
# 队列的基本操作
InitQueue(&Q):初始化队列,构造一个空队列 Q。DestroyQueue(&Q):销毁队列。销毁并释放队列 Q 所占用的内存空间。EnQueue(&Q,x):入队,若队列 Q 未满,将 x 加入,使之成为新的队尾。DeQueue(&Q,&x):出队,若队列 Q 非空,删除队头元素,并用 x 返回。GetHead(Q,&x):读队头元素,若队列 Q 非空,则将队头元素赋值给 x。
其他常用操作:
QueueEmpty(Q):判队列空,若队列 Q 为空返回 true,否则返回 false。
# 队列的顺序实现
#define MaxSize 10
typedef struct {
ElemType data[MaxSize]; //用静态数组存放队列元素
int front, rear; //队头指针和队尾指针
} SqQueue;
//初始化队列
void initQueue(SqQueue &Q) {
//初始时 队头、队尾指针指向0
Q.rear = Q.front = 0;
}
//判断队列是否为空
bool QueueEmpty(SqQueue Q) {
if (Q.rear == Q.front) {
return true;
} else {
return false;
}
}
void testQueue() {
SqQueue Q;
initQueue(Q);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
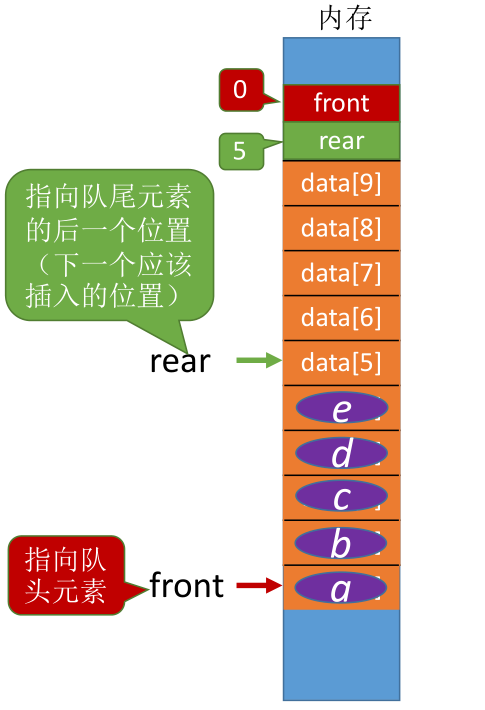
# 入队
//入队
bool EnQueue(SqQueue &Q, ElemType x) {
if ((Q.rear + 1) % MaxSize == Q.front) { //队满报错
return false;
}
Q.data[Q.rear] = x; //新元素插入队尾
Q.rear = (Q.rear + 1)%MaxSize; //队尾指针+1取模
}
2
3
4
5
6
7
8
# 循环队列
用模运算将存储空间在逻辑上变成了 “环状”
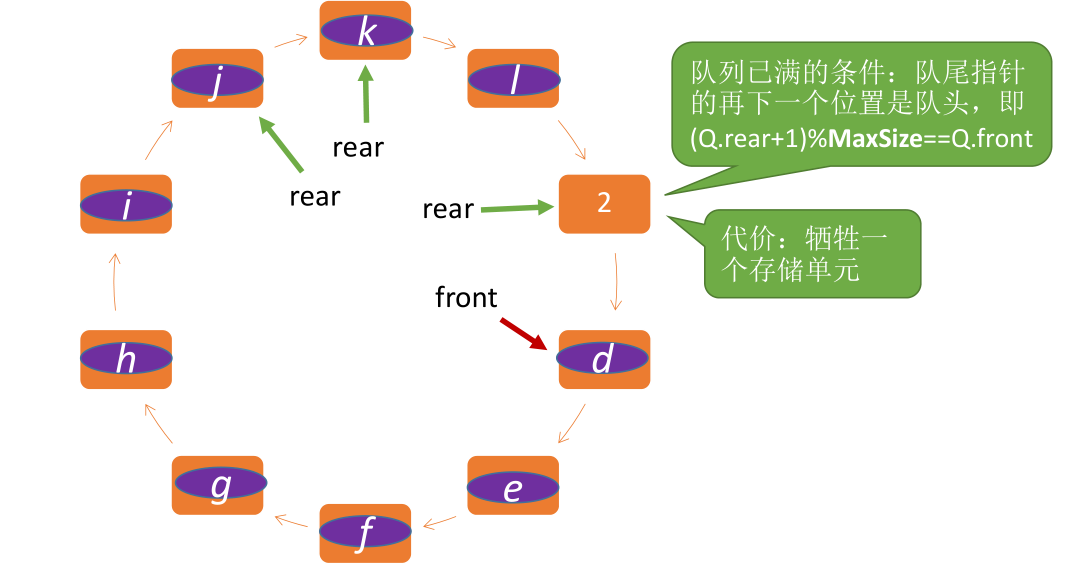
也就是说队列中始终有一个为空的位置
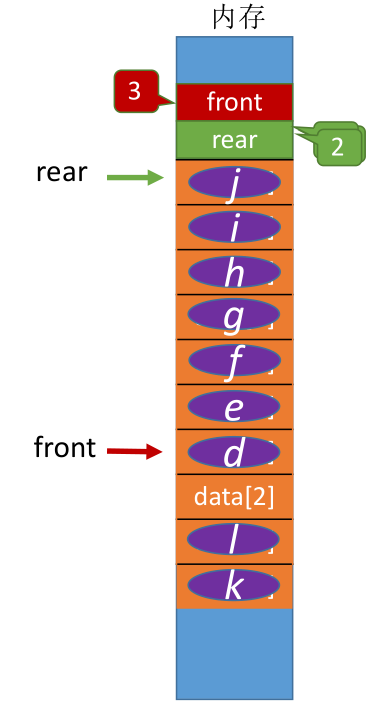
# 出队
//出队
bool DeQueue(SqQueue &Q, ElemType &x) {
if (Q.rear == Q.front) { //队列为空报错
return false;
}
x = Q.data[Q.front];
Q.front = (Q.front + 1)%MaxSize; //队头指针后移
return true;
}
2
3
4
5
6
7
8
9
# 查看队头
//查询队头
bool GetHead(SqQueue Q, ElemType &x) {
if (Q.rear == Q.front) { //队列为空报错
return false;
}
x = Q.data[Q.front]; //与出队一致,但不需要队头指针后移
return true;
}
2
3
4
5
6
7
8
# 判断队列已满 / 已空
方案一:
队列元素个数: (rear+MaxSize-front)%MaxSize
队列已满的条件:队尾指针的再下一个位置是队头,即 (Q.rear+1)%MaxSize==Q.front
方案二:
如果出题人,不允许浪费队列中的存储,即不能有空元素
那么我们可以在结构体中添加一个 size 变量,我们入队出队都要对 size 变量进行增加减少操作。
#define MaxSize 10
typedef struct {
ElemType data[MaxSize]; //用静态数组存放队列元素
int front, rear; //队头指针和队尾指针
int size; //当前队列有多少元素
} SqQueue;
2
3
4
5
6
方案三:
在结构体中添加一个 tag 变量,标记最近进行的操作是删除函数插入,不难想象只有删除操作才能使队列为空,插入操作才能使队列满。
#define MaxSize 10
typedef struct {
ElemType data[MaxSize]; //用静态数组存放队列元素
int front, rear; //队头指针和队尾指针
int tag; //最近进行的操作是删除/插入
} SqQueue;
2
3
4
5
6
- 队满条件:
front==rear && tag == 1 - 队空条件:
front==rear && tag == 0
# 总结
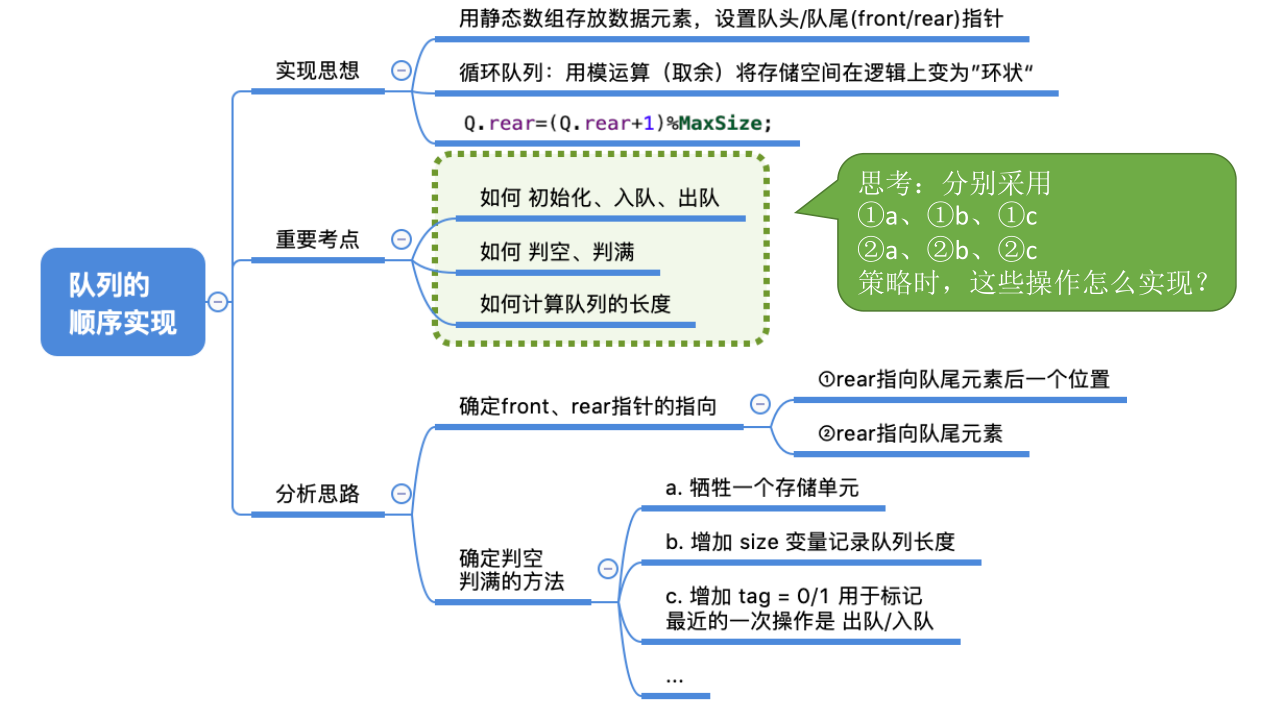
# 队列的链式实现
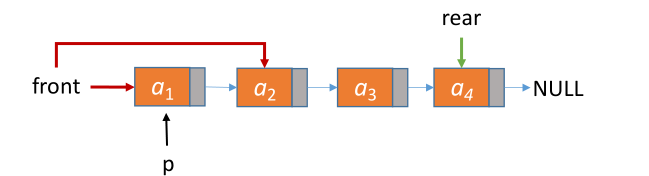
链队列 —— 链式存储实现的队列
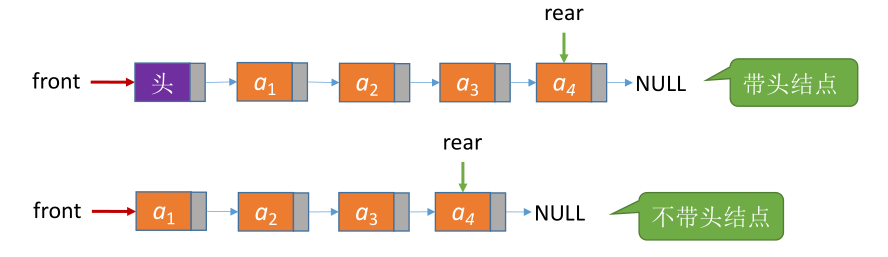
带头结点
typedef struct LinkNode { // 链式队列结点
ElemType data;
struct LinkNode *next;
} LinkNode;
typedef struct { //链式队列
LinkNode *front, *rear; //队列的队头和队尾指针
} *LinkQueue;
//初始化队列(带头结点)
void InitQueue(LinkQueue &Q) {
//初始化时 front、rear 都指向头结点
Q.front = Q.rear = (LinkNode *)malloc(sizeof(LinkNode));
Q.front->next = NULL;
}
//判断队列为空(带头结点)
bool IsEmpty(LinkQueue Q) {
if (Q.front == Q.rear) {
return true;
} else {
return false;
}
}
void testLinkQueue() {
LinkQueue Q;
initQueue(Q);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
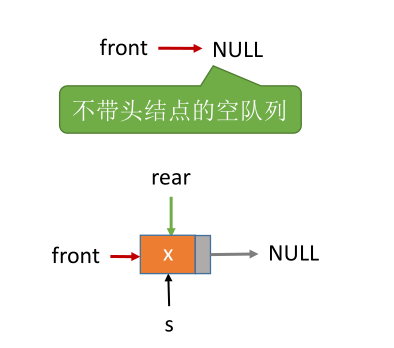
不带头结点
//初始化队列(不带头结点)
void InitQueue(LinkQueue &Q) {
//初始化时 front、rear 都指向NULL
Q.front = NULL;
Q.rear = NULL;
}
//判断队列为空(不带头结点)
bool IsEmpty(LinkQueue Q) {
if (Q.front == NULL) { //也可以判断rear是否为NULL
return true;
} else {
return false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 入队
带头结点
//入队(带头结点)
void EnQueue(LinkQueue &Q, ElemType x) {
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s->data = x;
s->next = NULL;
Q.rear->next = s; //新结点插入到rear之后
Q.rear = s; //修改表尾指针
}
2
3
4
5
6
7
8
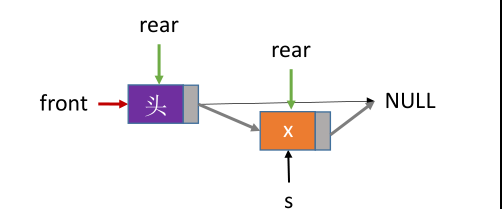
不带头结点
//入队(不带头结点)
void EnQueue(LinkQueue &Q, ElemType x) {
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s->data = x;
s->next = NULL;
if (Q.front == NULL) {
Q.front = s; //在空队列中插入第一个元素
Q.rear = s;//修改队头队尾指针
} else {
Q.rear->next = s; //新结点插入到rear之后
Q.rear = s; //修改表尾指针
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 出队
带头结点
//出队(带头结点)
bool DeQueue(LinkQueue &Q, ElemType &x) {
if (Q.front == Q.rear) { //空队列
return false;
}
LinkNode *p = Q.front->next;
x = p->data; //用变量x返回队头元素
Q.front->next = p->next; //修改头结点的next指针
if (Q.rear == p) { //此次是最后一个结点出队
Q.rear = Q.front; //修改rear指针
}
free(p);//释放结点
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14

不带头结点
//出队(不带头结点)
bool DeQueue(LinkQueue &Q, ElemType &x) {
if (Q.front == NULL) { //空队列
return false;
}
LinkNode *p = Q.front; //p指向此次出队的结点
x = p->data; //用变量x返回队头元素
Q.front = p->next; //修改头结点的next指针
if (Q.rear == p) { //此次是最后一个结点出队
Q.front = NULL; //修改front 指向NULL
Q.rear = NULL; //修改rear 指向NULL
}
free(p);//释放结点
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 总结
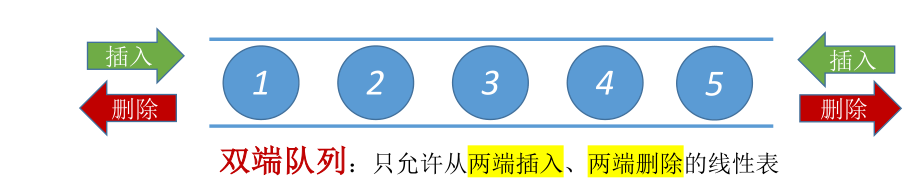
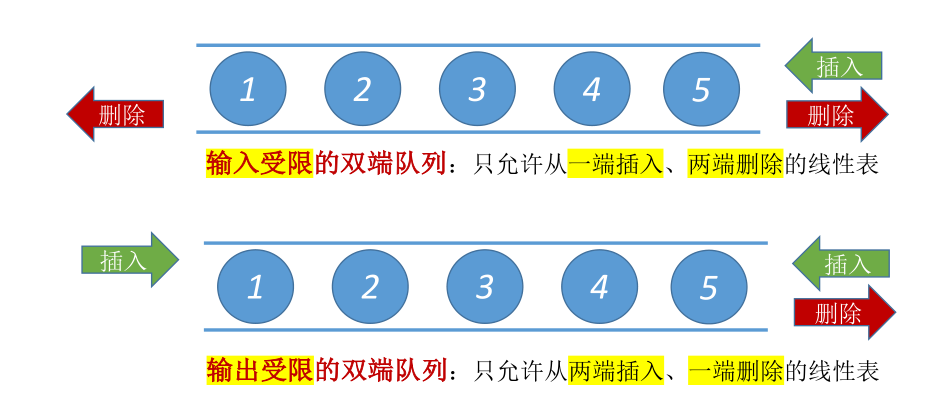
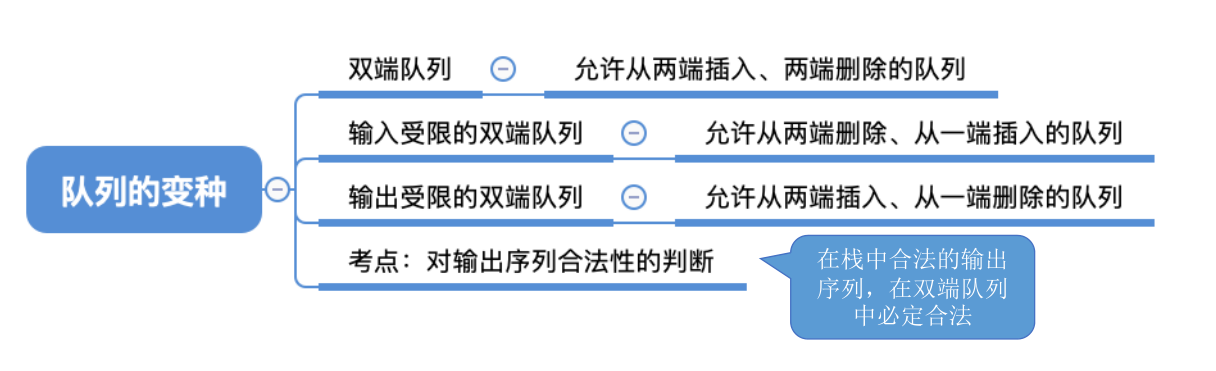
# 双端队列
# 总结
# 栈的应用
# 括号匹配问题
#include <stdio.h>
#include <stdlib.h>
#define MaxSize 10
typedef struct {
ElemType data[MaxSize];
int top; //栈顶指针
} SqStack;
void initStack(SqStack &S) {
S.top = -1; //初始化栈顶指针
}
//查看栈是否为空
bool SqStackEmpty(SqStack S) {
if (S.top == -1) {
return true;
} else {
return false;
}
}
//入栈
bool Push(SqStack &S, ElemType x) {
if (S.top == MaxSize - 1) { //栈满,报错
return false;
}
S.top = S.top + 1; //指针先加1
S.data[S.top] = x; //新元素入栈
return true;
}
//出栈
bool Pop(SqStack &S, ElemType &x) {
if (S.top == -1) {
return false;
}
x = S.data[S.top]; //栈顶元素先出栈
S.top = S.top - 1; //指针再减1
return true;
}
bool bracketCheck(char str[], int length) {
SqStack S;
initStack(S); // 初始化栈
for (int i = 0; i < length; i++)
{
if (str[i] == '(' || str[i] == '[' || str[i] == '{') {
Push(S, str[i]); // 扫描到左括号入栈
} else {
if (SqStackEmpty(S)) { //扫描到右括号,如果当前栈为空直接返回false
return false;
}
char topElem;
Pop(S, topElem); //栈顶元素出栈
if (str[i] == ')' && topElem != '(') {
return false;
}
if (str[i] == ']' && topElem != '[') {
return false;
}
if (str[i] == '}' && topElem != '{') {
return false;
}
}
}
return SqStackEmpty(S); //检索完全版括号后,栈空说明匹配成功
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
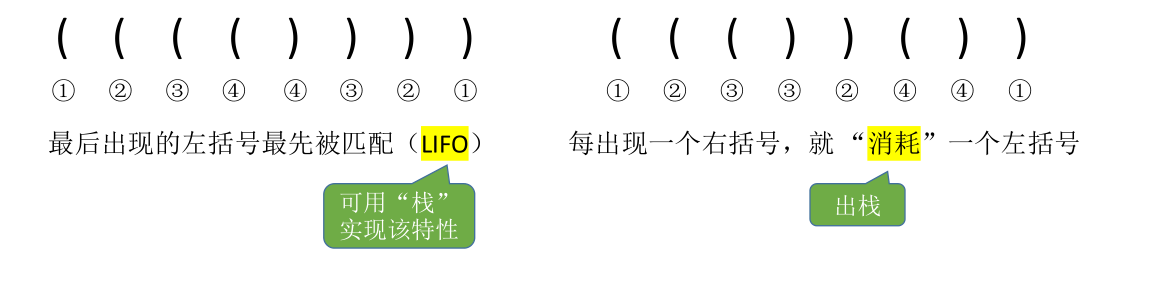
用栈实现括号匹配:依次扫描所有字符,遇到左括号入栈,遇到右括号则弹出栈顶元素检查是否匹配。
匹配失败情况:
- 左括号单身
- 右括号单身
- 左右括号不匹配
# 表达式求值
大家平时写的算数表达式是中缀表达式

由三个部分组成:操作数、运算符、界限符 界限符是必不可少的,反映了计算的先后顺序
有没有可以不用界限符,也能无歧义地表达运算顺序。答案是有:下面我们讲述波兰表达式
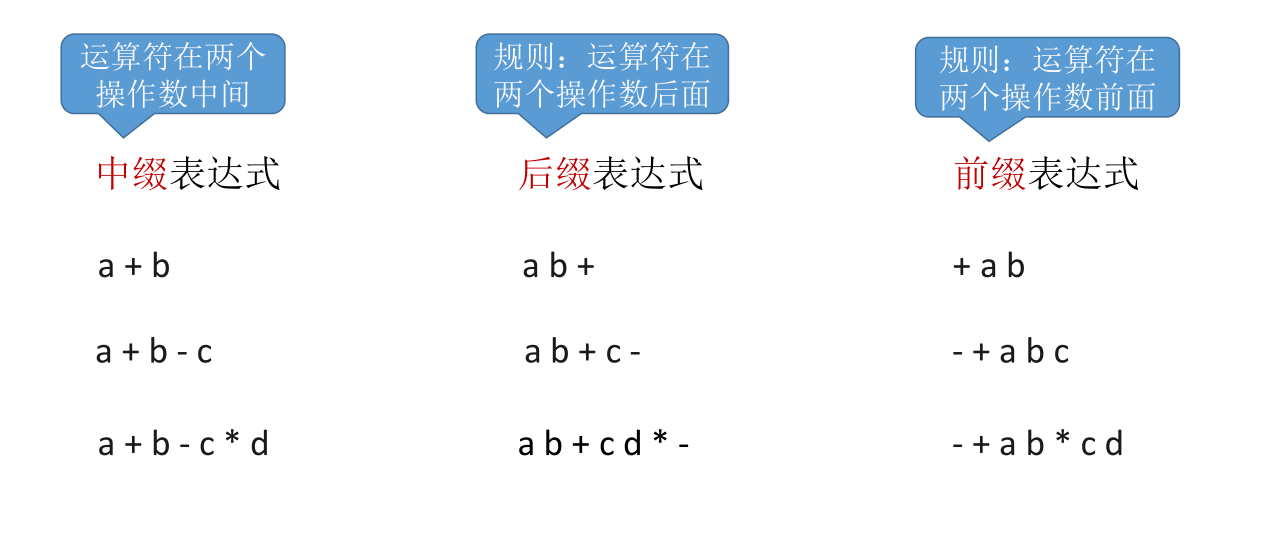
# 中缀、后缀、前缀表达式
- Reverse Polish notation(逆波兰表达式 = 后缀表达式)
- Polish notation(波兰表达式 = 前缀表达式)
# 中缀表达式转后缀表达式(手算)
中缀转后缀的手算方法:
- 确定中缀表达式中各个运算符的运算顺序
- 选择下一个运算符,按照 **「左操作数 右操作数 运算符」** 的方式组合成一个新的操作数
- 如果还有运算符没被处理,就继续执行步骤 2
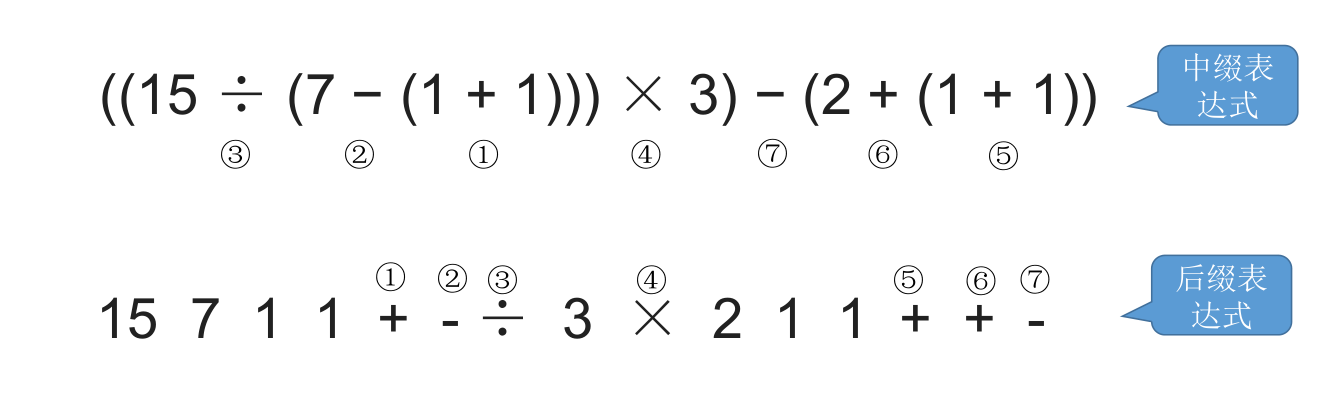
通过上面的简单案例我们发现中缀表达式的运算符出现次序,和后缀表达式的出现次序是一致的。
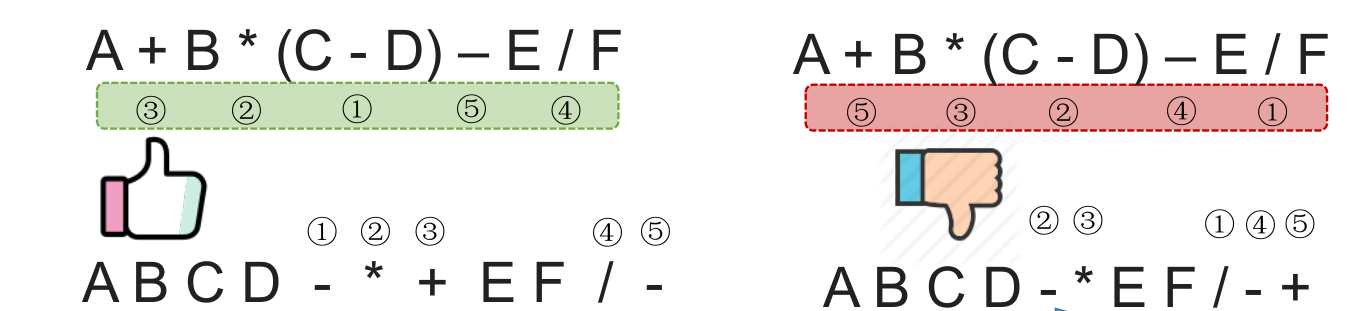
运算顺序不唯一,因此对应的,后缀表达式也不唯一。上述例子客观来看两种都正确,只是 “机算” 结果是前者。
我们中缀转后缀时要遵循 “左优先” 原则:只要左边的运算符能先计算,就优先算左边的。保证手算和机算结果相同,可保证运算顺序唯一。
下面通过一个例子来看看左优先原则怎么执行:
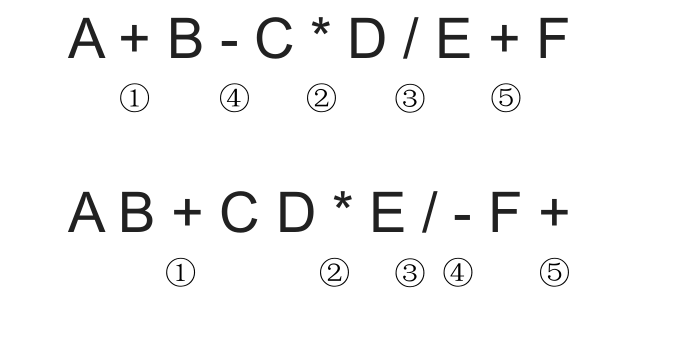
# 后缀表达式的计算(手算)
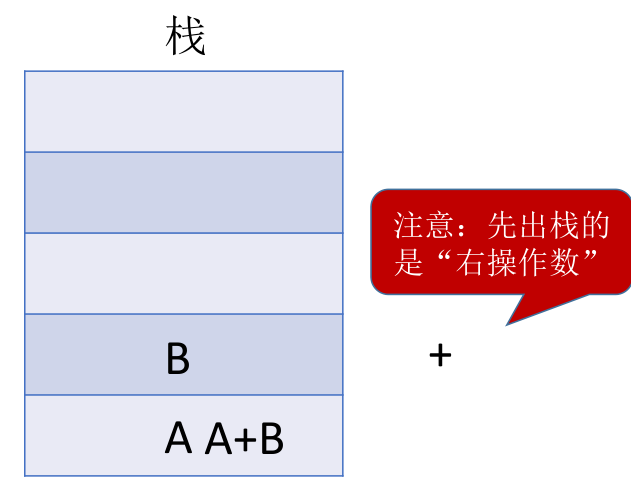
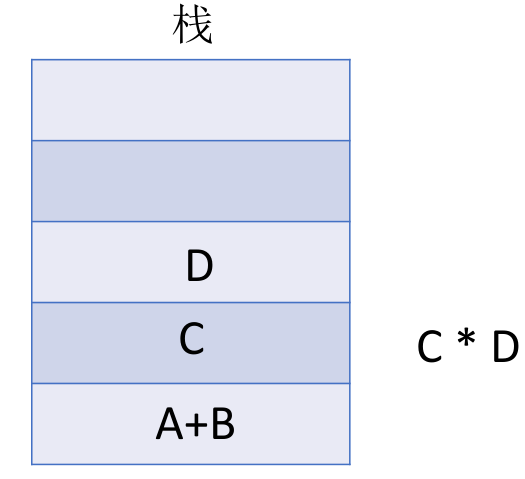
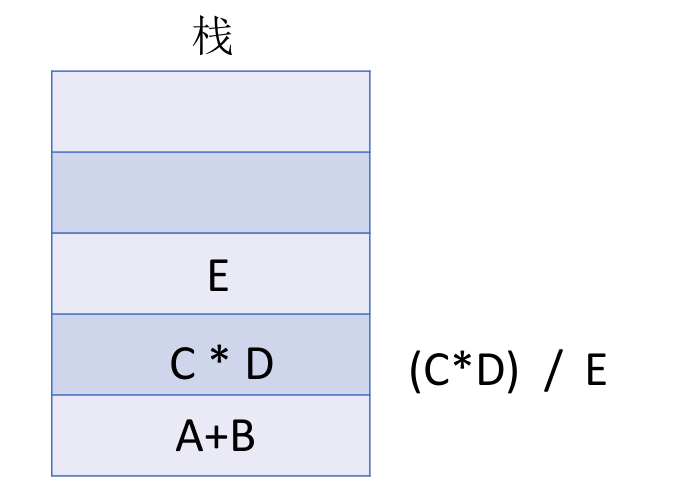
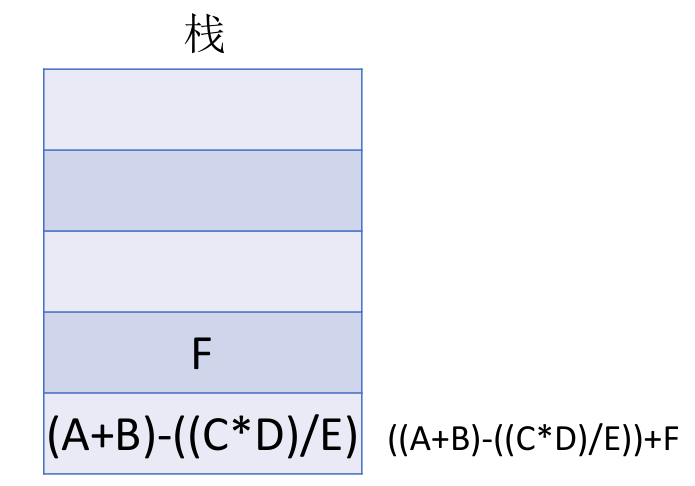
后缀表达式的手算方法: 从左往右扫描,每遇到一个运算符,就让运算符前面最近的两个操作数执行对应运算,合体为一个操作数。注意:两个操作数的左右顺序。

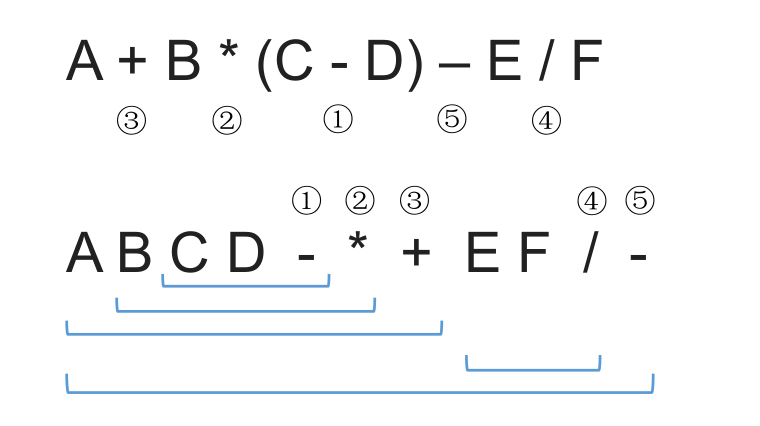
特点:最后出现的操作数先被运算。这就符合 LIFO(后进先出)也就是栈结构。
# 后缀表达式的计算(机算)
用栈实现后缀表达式的计算:
- 从左往右扫描下一个元素,直到处理完所有元素
- 若扫描到操作数则压入栈,并回到 1 ;否则执行 3
- 若扫描到运算符,则弹出两个栈顶元素,执行相应运算,运算结果压回栈顶,回到 1

# 中缀表达式转前缀表达式(手算)
中缀转前缀的手算方法:
- 确定中缀表达式中各个运算符的运算顺序
- 选择 下一个运算符,按照 **「运算符 左操作数 右操作数」** 的方式组合成一个新的操作数
- 如果还有运算符没被处理,就继续 2
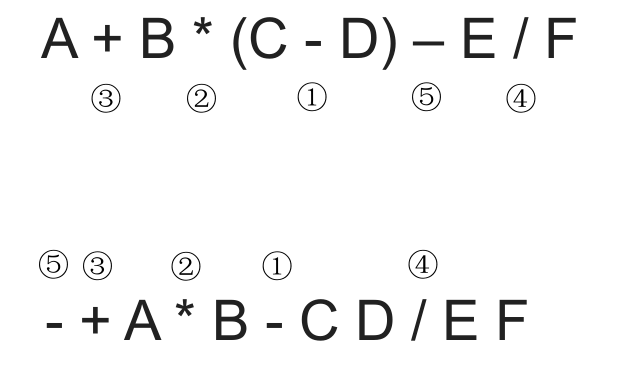
右优先原则:只要右边的运算符能先计算,就优先算 右边 的
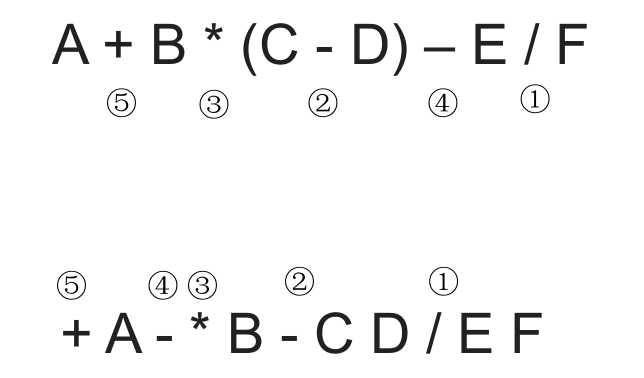
中缀转后缀 与 中缀转前缀 相比较:
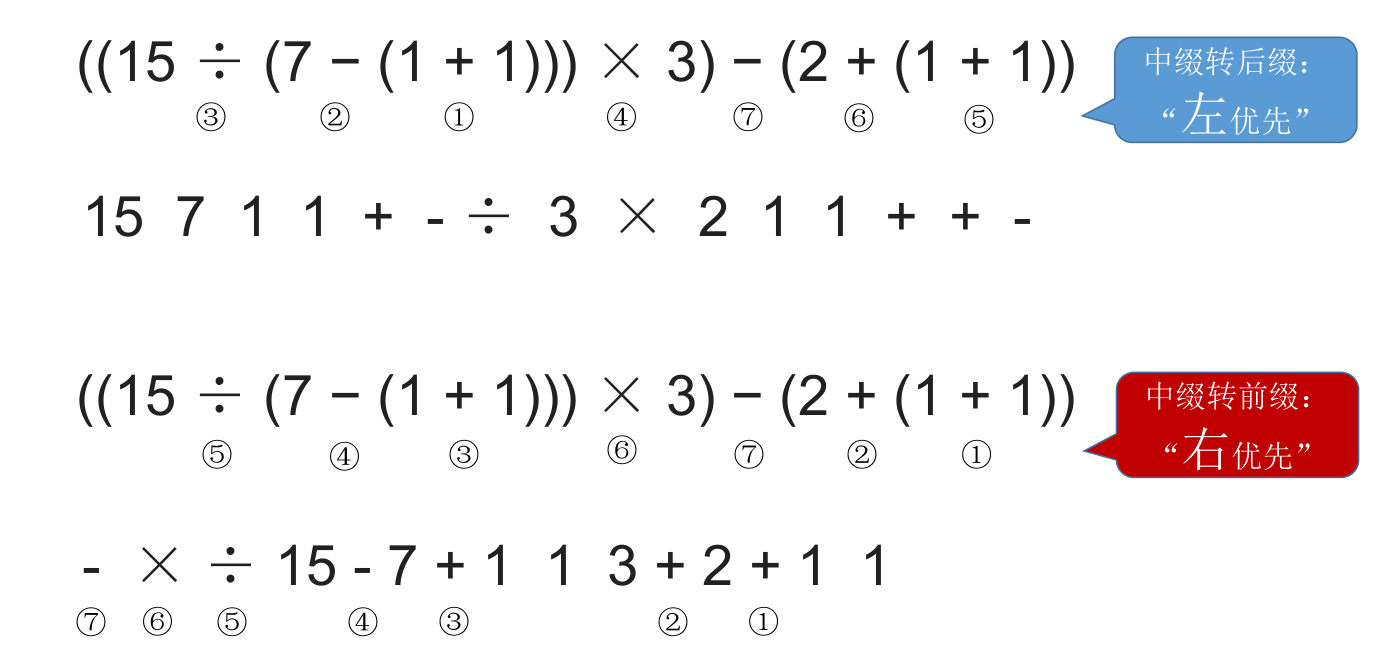
# 前缀表达式的计算
用栈实现前缀表达式的计算:
- 从右往左扫描下一个元素,直到处理完所有元素
- 若扫描到操作数则压入栈,并回到 1 ;否则执行 3
- 若扫描到运算符,则弹出两个栈顶元素,执行相应运算,运算结果压回栈顶,回到 1;注意:先出栈的是 “左操作数”
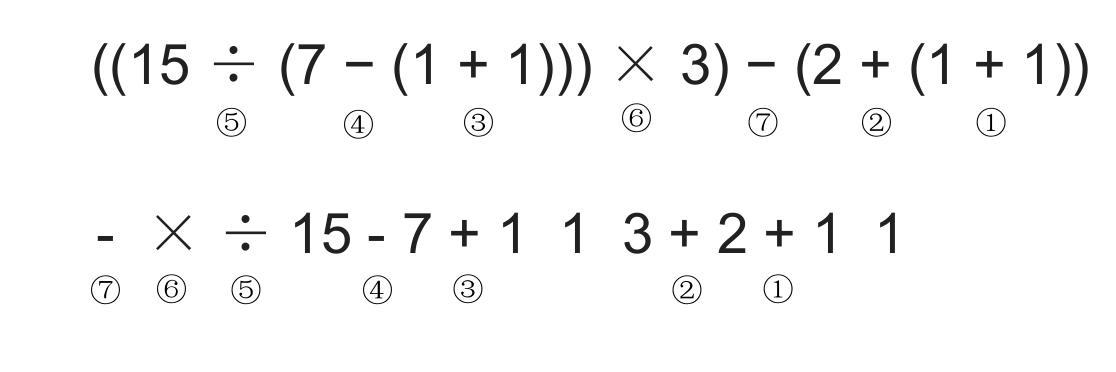
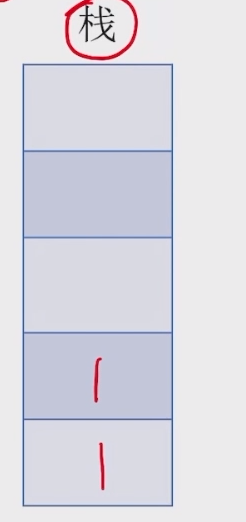
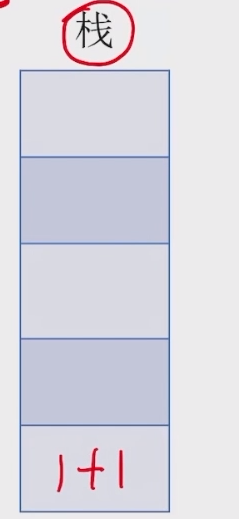
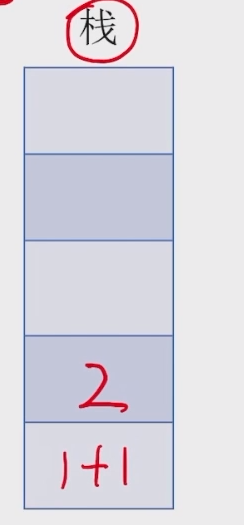
注意:先出栈的是 “左操作数”,切记不要弄反,如果是除法运算则顺序会影响结果。
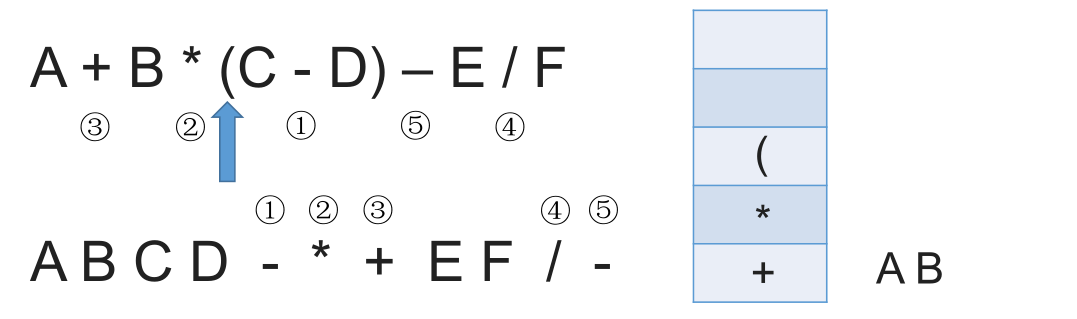
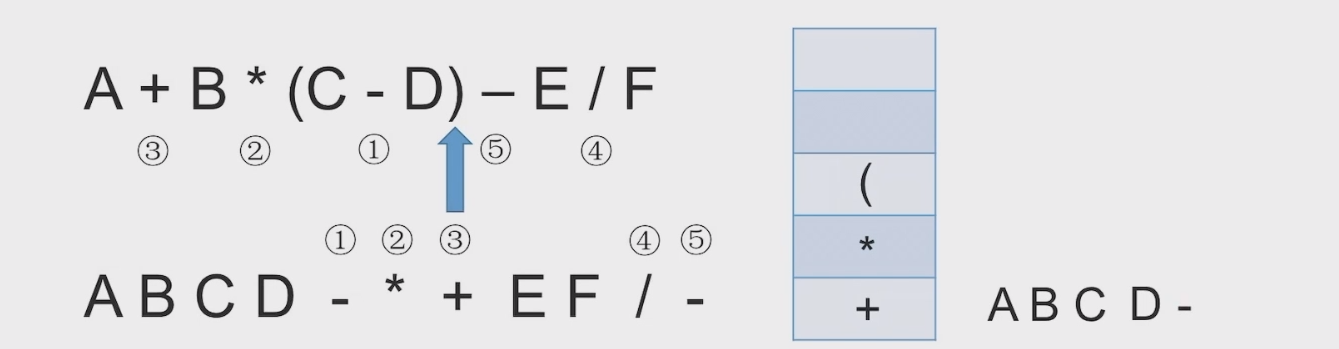
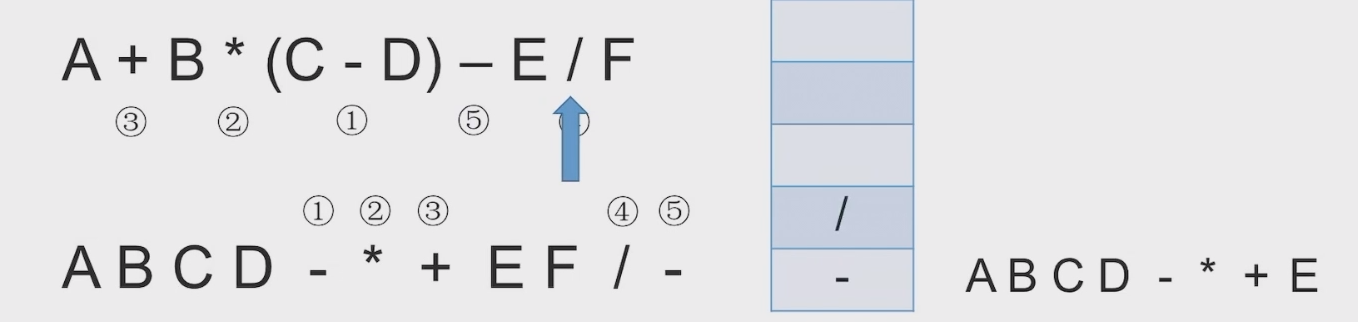
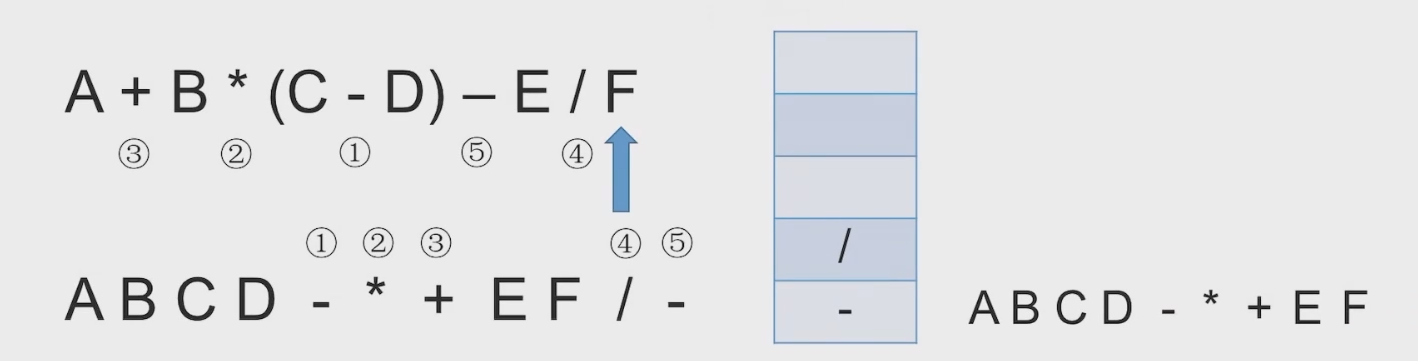
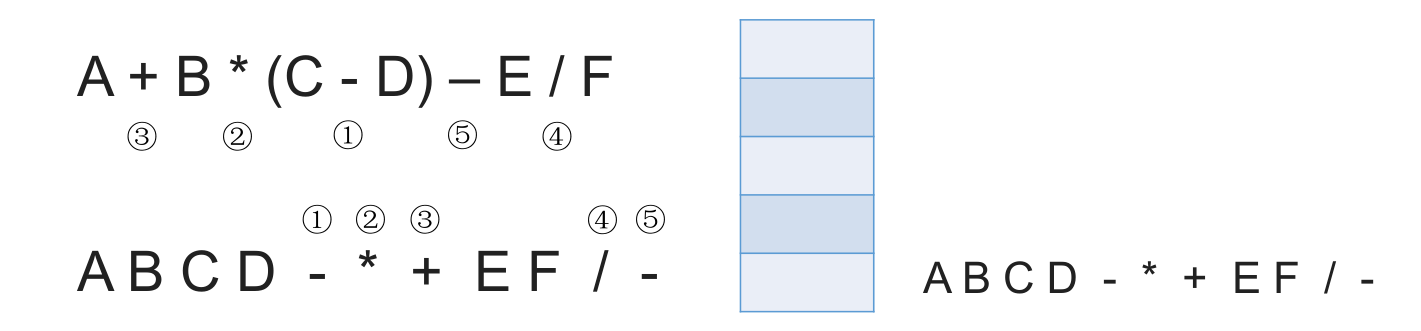
# 中缀表达式转后缀表达式(机算)
初始化一个栈,用于保存暂时还不能确定运算顺序的运算符。
从左到右处理各个元素,直到末尾。可能遇到三种情况:
- 遇到操作数。直接加入后缀表达式。
- 遇到界限符。遇到 “(” 直接入栈;遇到 “)” 则依次弹出栈内运算符并加入后缀表达式,直到弹出 “(” 为止。注意:“(” 不加入后缀表达式。
- 遇到运算符。依次弹出栈中优先级高于或等于当前运算符的所有运算符,并加入后缀表达式,若碰到 “(” 或栈空则停止。之后再把当前运算符入栈。
按上述方法处理完所有字符后,将栈中剩余运算符依次弹出,并加入后缀表达式。
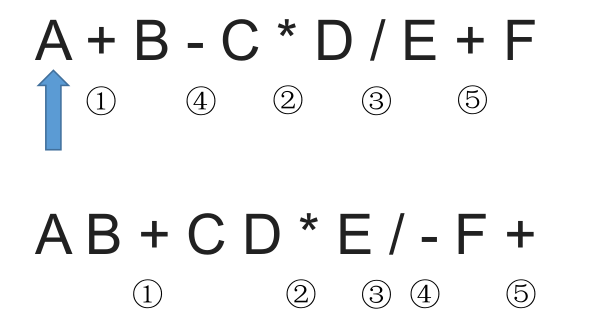
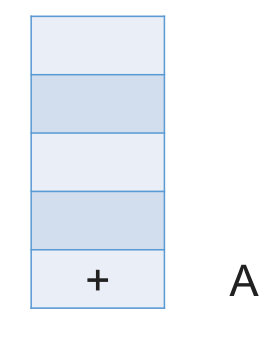
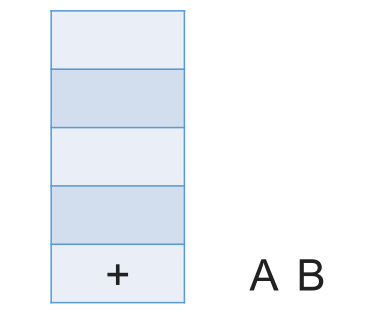
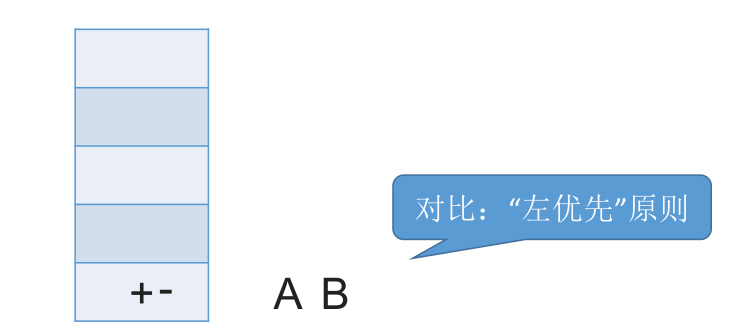
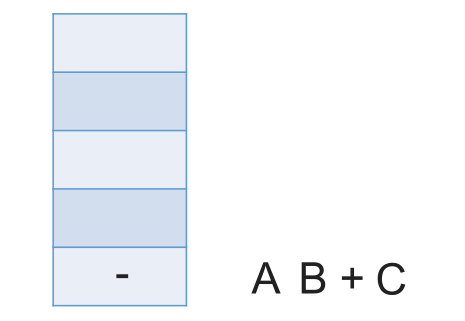
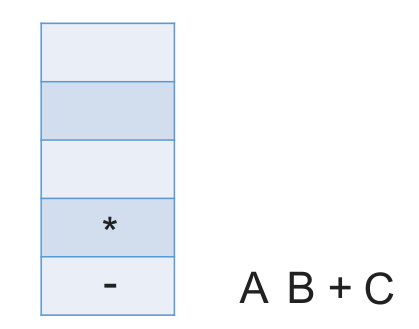
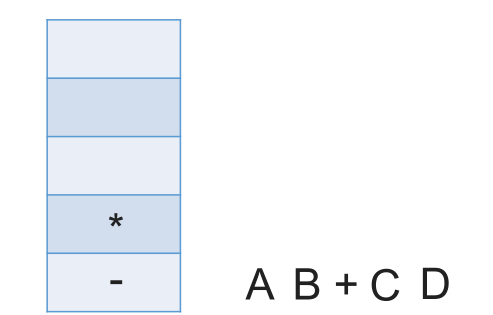
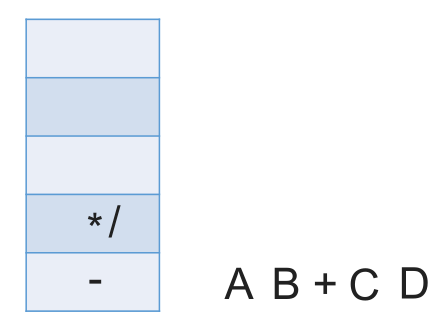
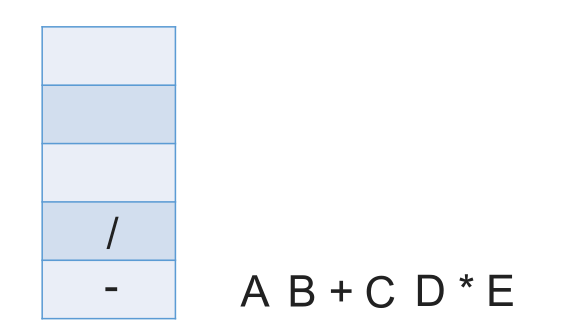
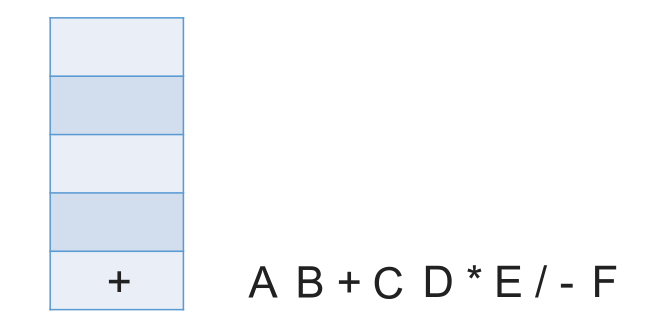
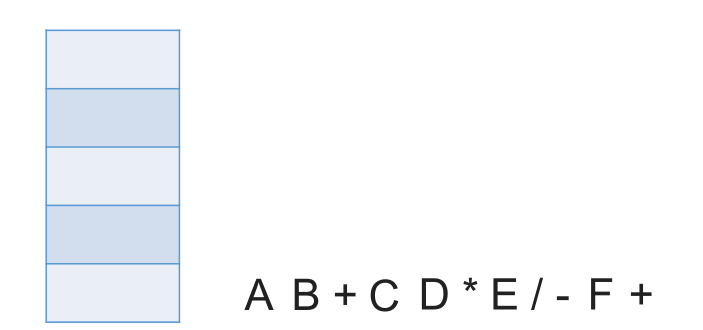
# 带括号情况
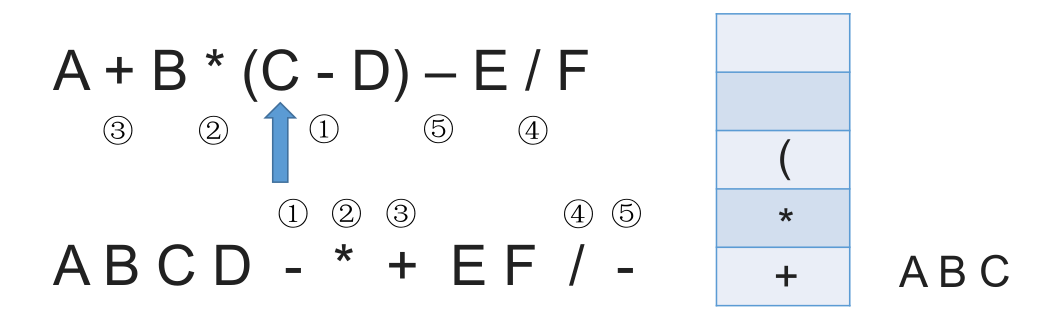
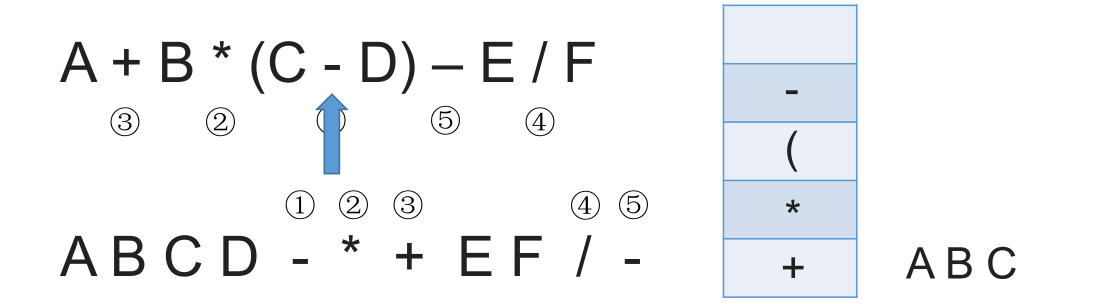
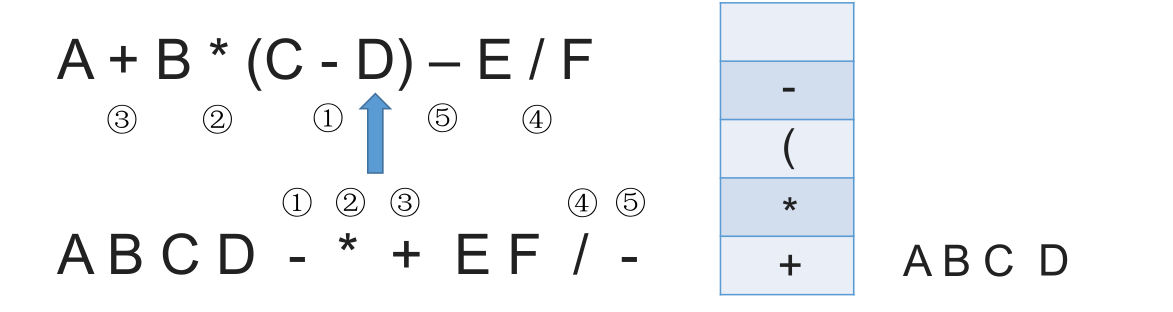
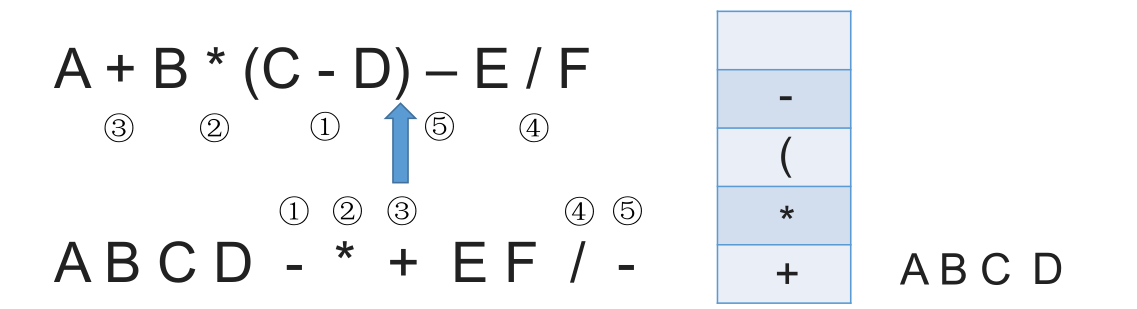


# 中缀表达式的计算(用栈实现)
用栈实现中缀表达式的计算: 初始化两个栈,操作数栈和运算符栈
- 若扫描到操作数,压入操作数栈
- 若扫描到运算符或界限符,则按照 “中缀转后缀” 相同的逻辑压入运算符栈(期间也会弹出运算符,每当弹出一个运算符时,就需要再弹出两个操作数栈的栈顶元素并执行相应运算,运算结果再压回操作数栈)
# 总结
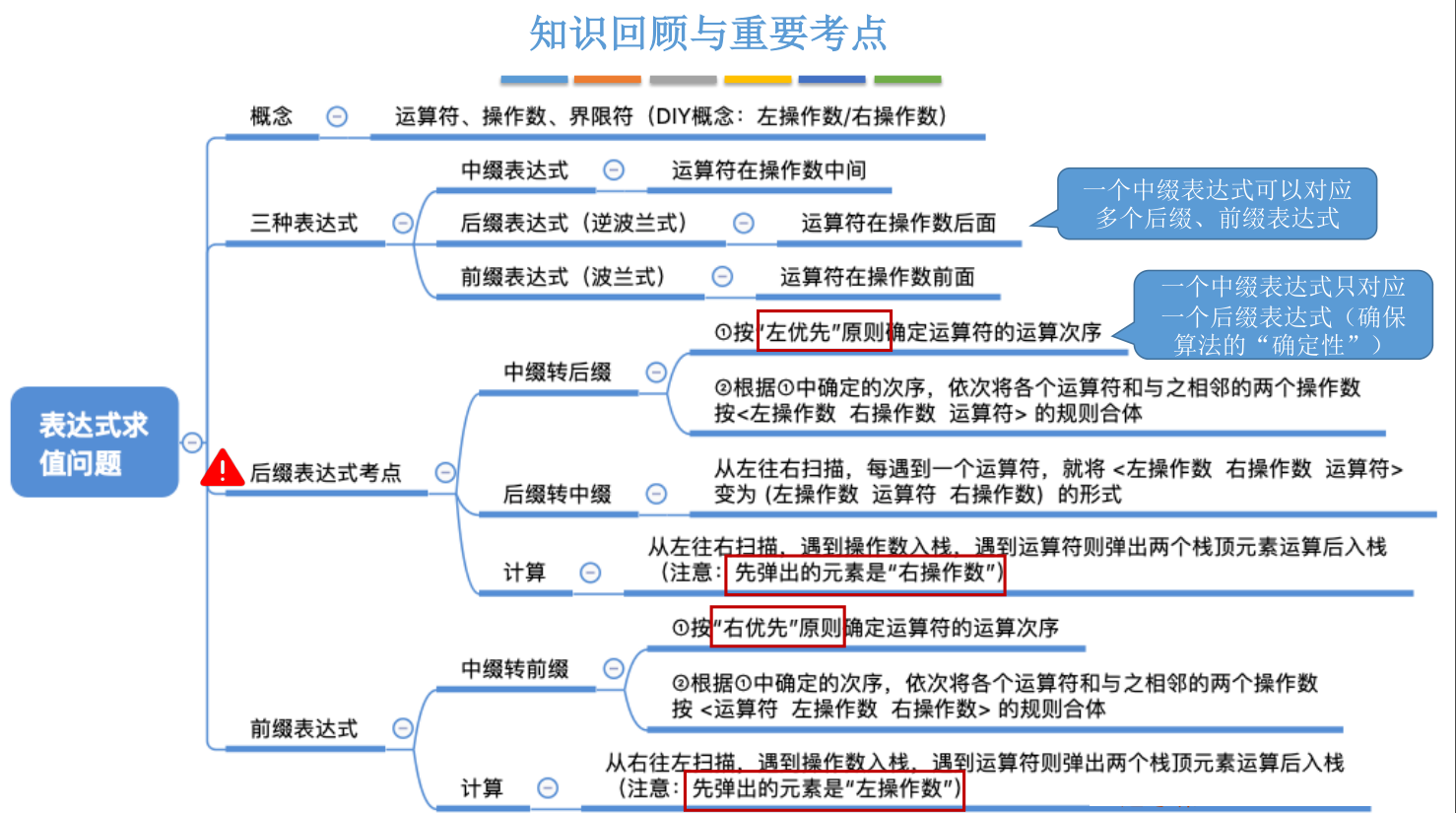

# 递归

函数调用的特点:最后被调用的函数最先执行结束(LIFO)
函数调用时,需要用一个栈存储:
- 调用返回地址
- 实参
- 局部变量
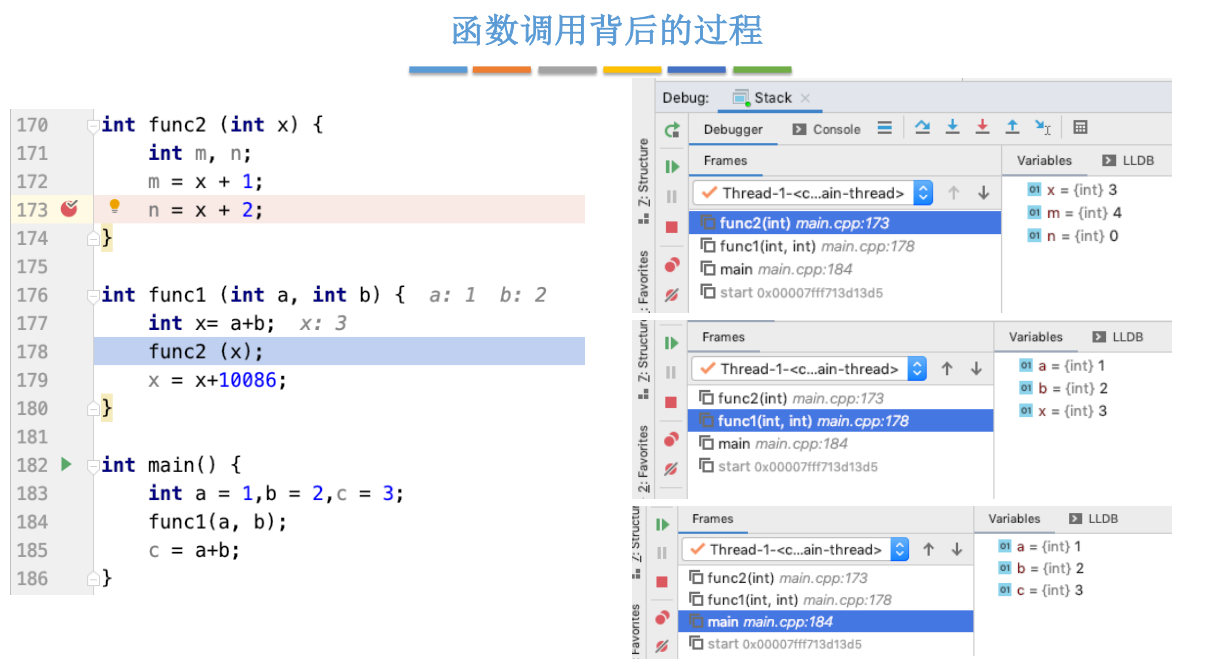
# 栈在递归中的应用
适合用 “递归” 算法解决:可以把原始问题转换为属性相同,但规模较小的问题
计算正整数的阶乘


递归调用时,函数调用栈可称为 “递归工作栈”
每进入一层递归,就将递归调用所需信息压入栈顶
每退出一层递归,就从栈顶弹出相应信息
缺点:太多层递归可能会导致栈溢出
求斐波那契数列

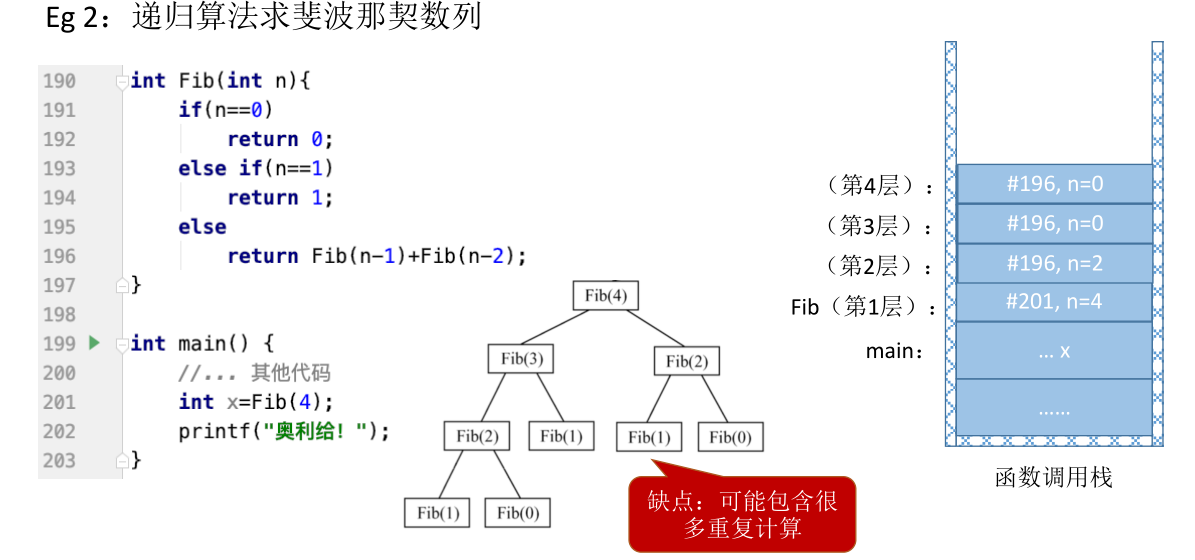
# 队列的应用
# 树的层次遍历
广度优选遍历 BFS
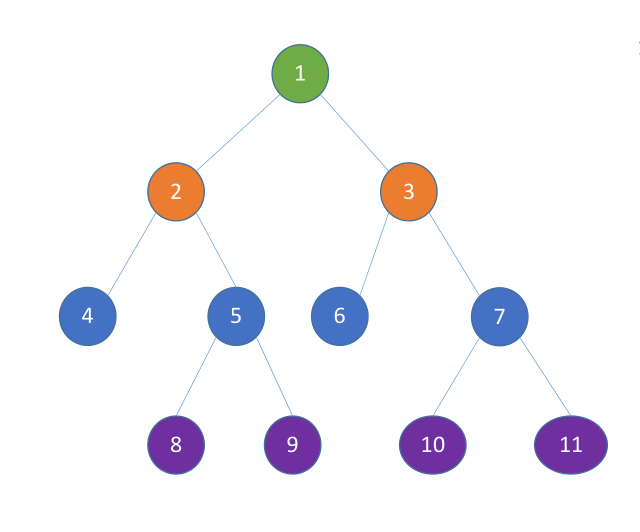
# 图的广度优先遍历
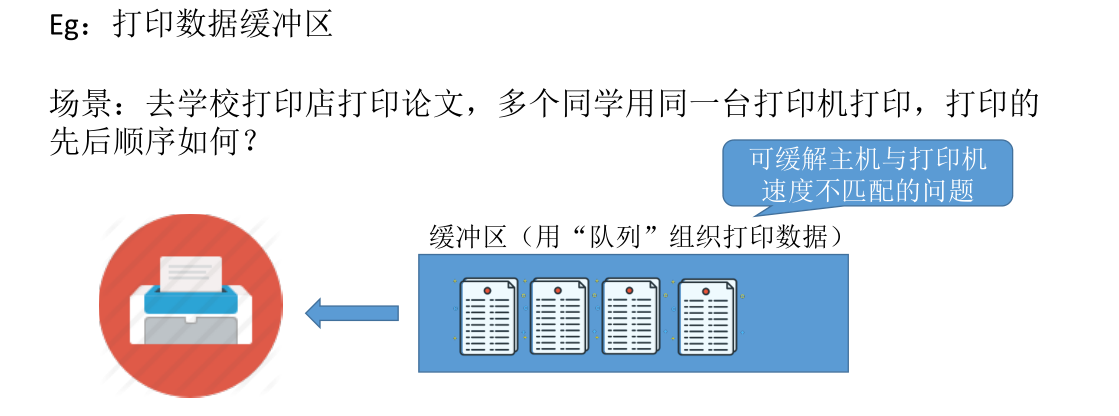
# 队列在操作系统中的应用
多个进程争抢着使用有限的系统资源时,FCFS(First Come First Service,先来先服务)是一种常用策略。

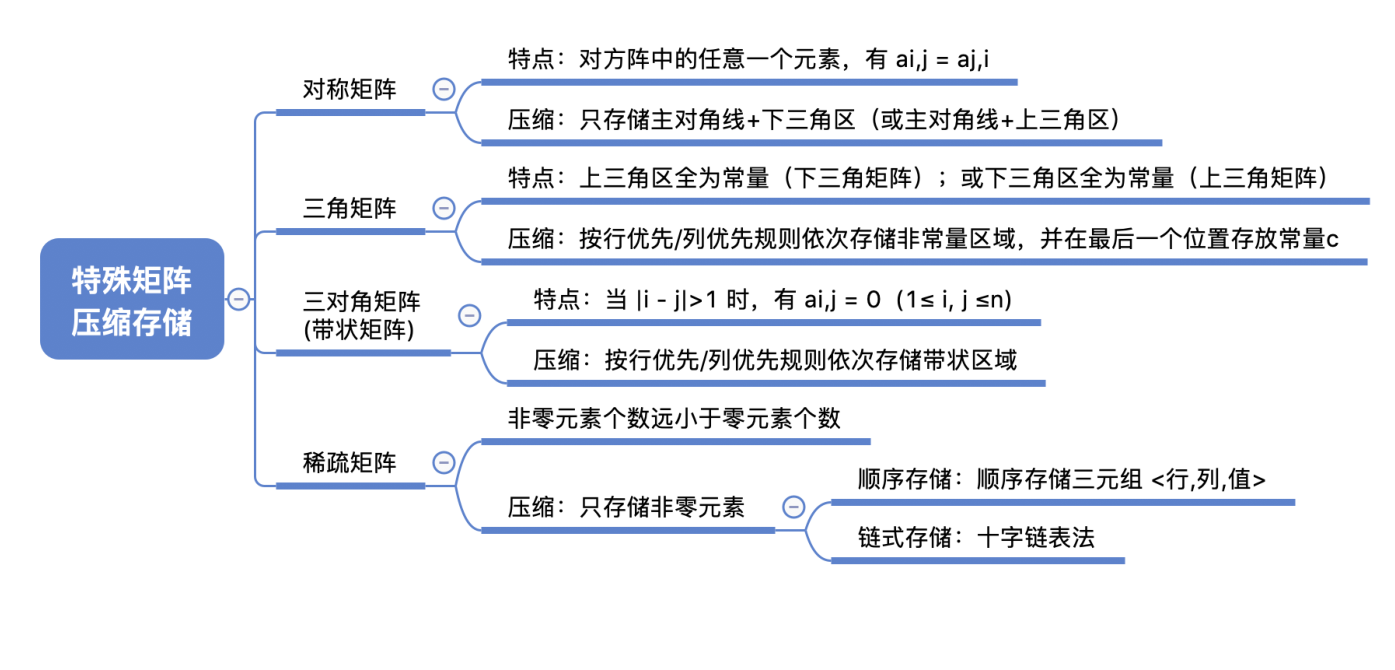
# 特殊矩阵的压缩存储
# 数组的存储结构
# 一维数组的存储结构

各数组元素大小相同,且物理上连续存放。
数组元素
注:除非题目特别说明,否则数组下标默认从 0 开始
# 二维数组的存储结构

- M 行 N 列的二维数组 b [M][N] 中,若按行优先存储,则
- M 行 N 列的二维数组 b [M][N] 中,若按列优先存储,则
# 特殊矩阵
# 对称矩阵的压缩存储
若
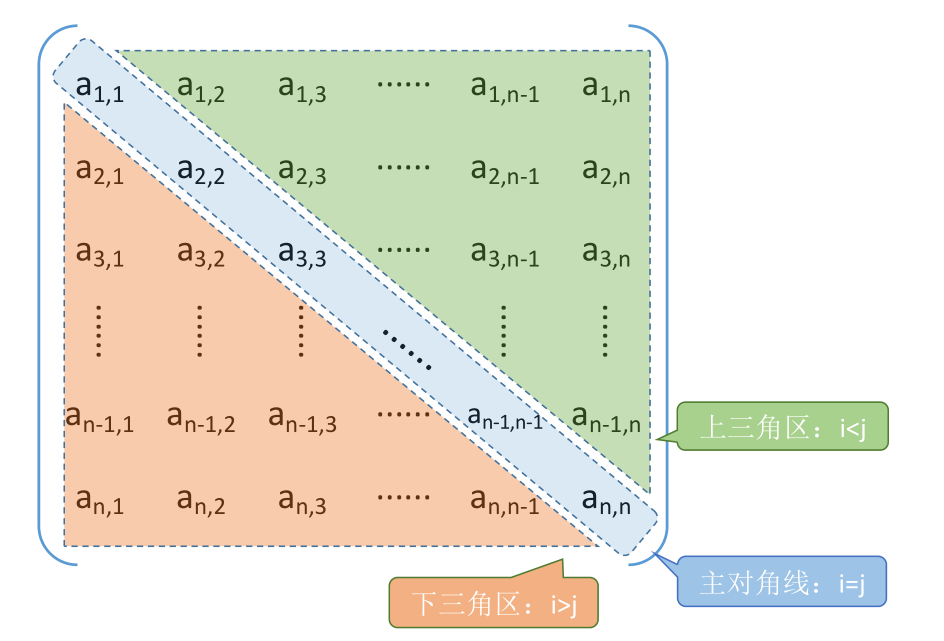
普通存储:
压缩存储策略:只存储主对角线 + 下三角区(或主对角线 + 上三角区)
策略:只存储主对角线 + 下三角区
按行优先原则将各元素存入一维数组中。
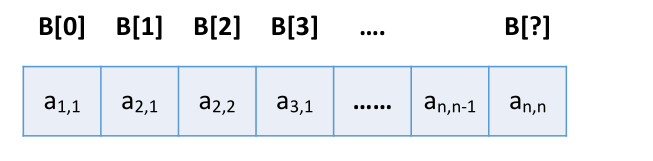
数组大小:
如何进行遍历?
可以实现一个 “映射” 函数矩阵下标 → 一维数组下标
Key:按 行优先 的原则,
如果想访问上三角区的元素?
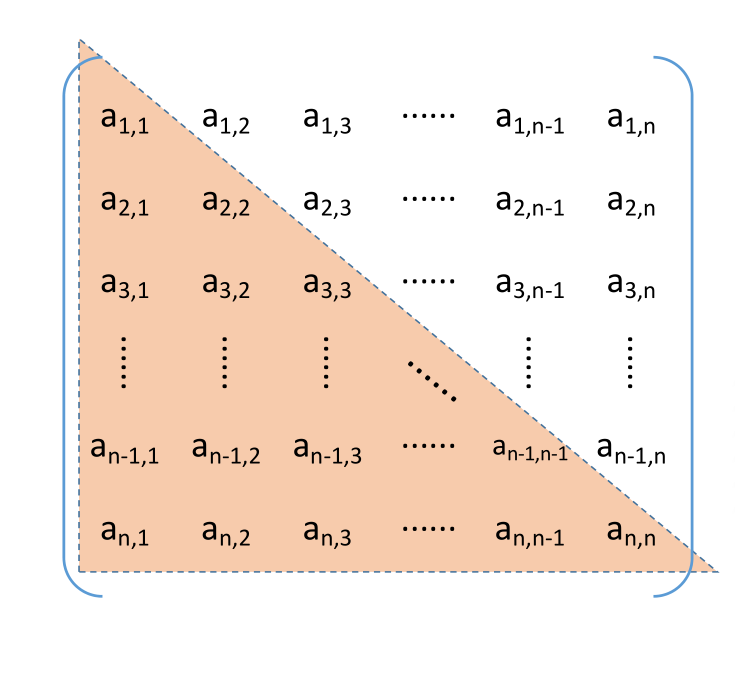
# 三角矩阵的压缩存储
下三角矩阵:除了主对角线和下三角区,其余的元素都相同
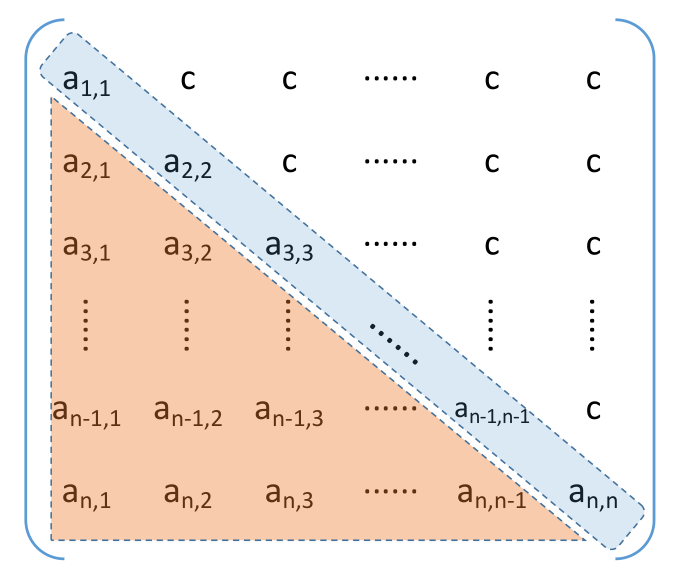
压缩存储策略:按行优先原则将橙色区元素存入一维数组中。并在最后一个位置存储常 量 c
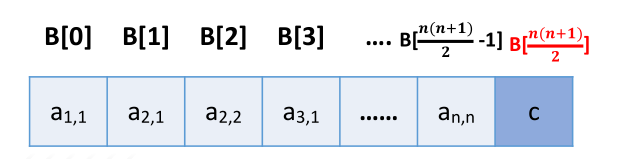
Key:按 行优先 的原则,
上三角矩阵:除了主对角线和上三角区,其余的元素都相同
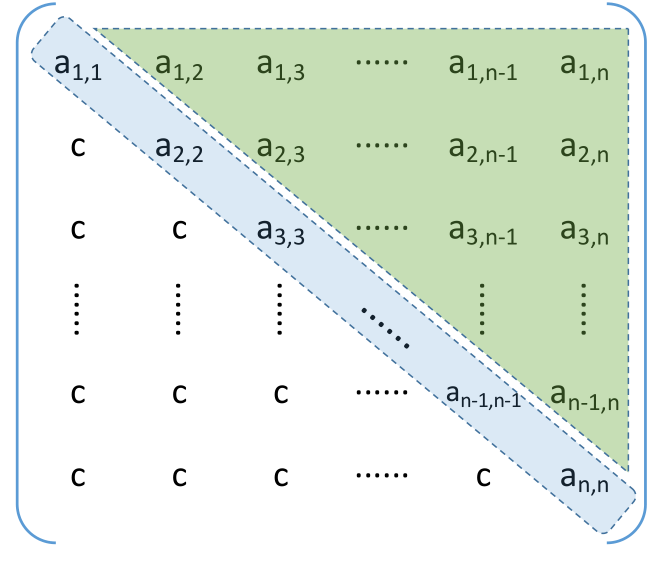
压缩存储策略:按行优先原则将绿色区元素存入一维数组中。并在最后一个位置存储常 量 c
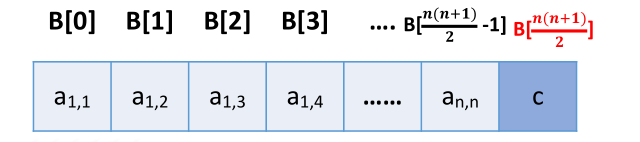
Key:按 行优先 的原则,
# 三对角矩阵的压缩存储
三对角矩阵,又称带状矩阵:
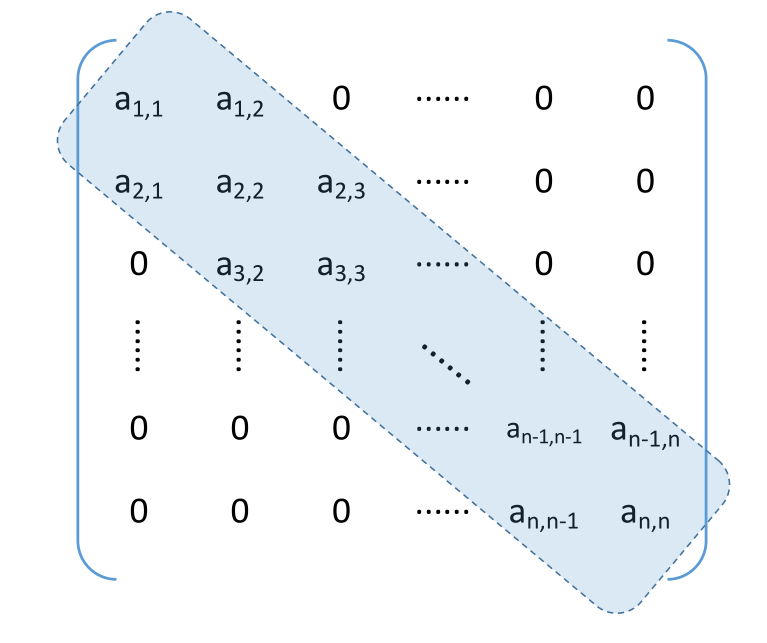
压缩存储策略:按行优先(或列优先)原则,只存储带状部分
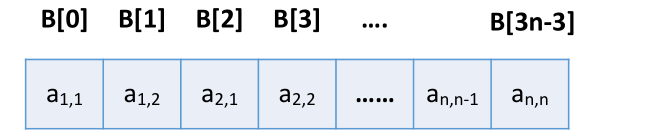
Key:按 行优先 的原则,
前
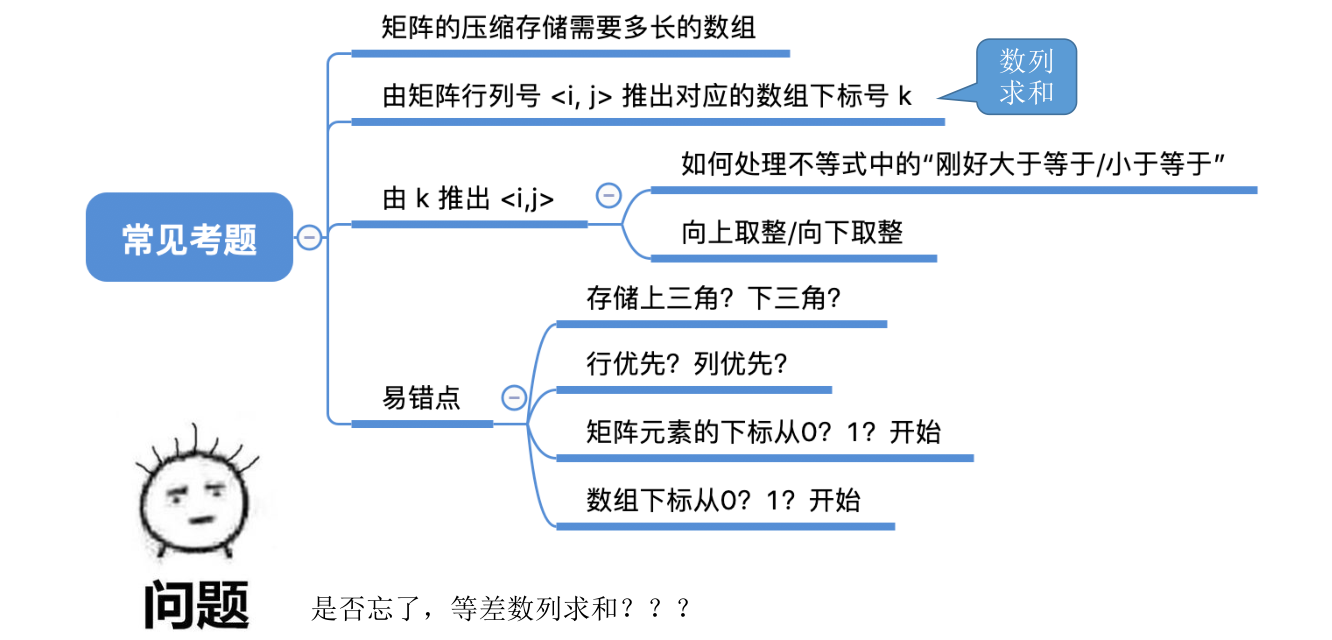
若已知数组下标 k,如何得到 i, j ?第 k+1 个元素,在第几行?第几列?
前
前
显然,$ 3 (i-1)-1 < k+1 ≤ 3i-1$
得出结论:
由
# 稀疏矩阵的压缩存储
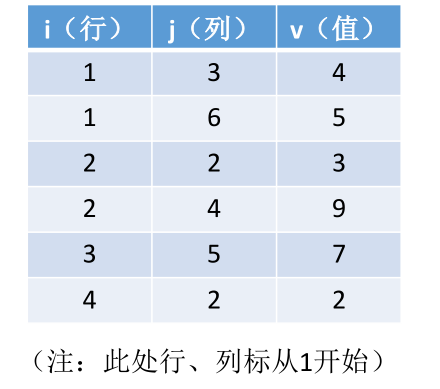
稀疏矩阵:非零元素远远少于矩阵元素的个数
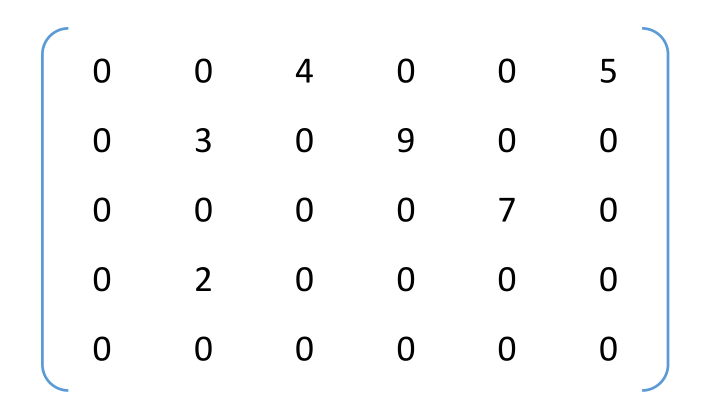
压缩存储策略:顺序存储 —— 三元组 <行,列,值>
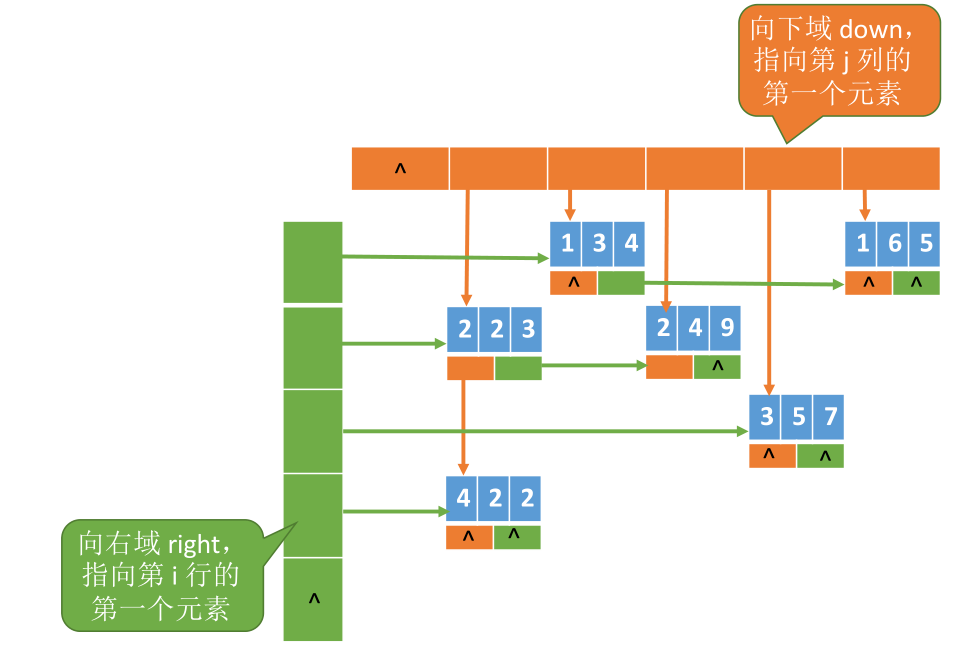
压缩存储策略二:链式存储 —— 十字链表法
定义一个特殊的结点

# 总结